Hadoop详解(09) - Hadoop新特性
Hadoop详解(09) - Hadoop新特性
Hadoop2.x新特性
远程主机之间的文件复制
- scp实现两个远程主机之间的文件复制
推 push:scp -r hello.txt root@hadoop103:/user/atguigu/hello.txt
拉 pull:scp -r root@hadoop103:/user/atguigu/hello.txt hello.txt
是通过本地主机:
通过本地主机中转实现两个远程主机的文件复制;如果在两个远程主机之间ssh没有配置的情况下可以使用该方式。
scp -r root@hadoop103:/user/atguigu/hello.txt root@hadoop104:/user/atguigu //是通过本地主机中转实现两个远程主机的文件复制;如果在两个远程主机之间ssh没有配置的情况下可以使用该方式。
- 采用distcp命令实现两个Hadoop集群之间的递归数据复制
[hadoop@hadoop102 hadoop-3.1.3]$ bin/hadoop distcp hdfs://hadoop102:9820/user/hadoop/hello.txt hdfs://hadoop105:9820/user/hadoop/hello.txt
小文件存档
- HDFS存储小文件弊端
每个文件均按块存储,每个块的元数据存储在NameNode的内存中,因此HDFS存储小文件会非常低效。因为大量的小文件会耗尽NameNode中的大部分内存。但注意,存储小文件所需要的磁盘容量和数据块的大小无关。例如,一个1MB的文件设置为128MB的块存储,实际使用的是1MB的磁盘空间,而不是128MB。
- 解决存储小文件办法之一
HDFS存档文件或HAR文件,是一个更高效的文件存档工具,它将文件存入HDFS块,在减少NameNode内存使用的同时,允许对文件进行透明的访问。具体说来,HDFS存档文件对内还是一个一个独立文件,对NameNode而言却是一个整体,减少了NameNode的内存。
- 案例实操
需要启动YARN进程
start-yarn.sh
归档文件
把/user/hadoop/input目录里面的所有文件归档成一个叫input.har的归档文件,并把归档后文件存储到/user/hadoop/output路径下。
hadoop archive -archiveName input.har -p /user/hadoop/input /user/hadoop/output
查看归档
hadoop fs -ls /user/hadoop/output/input.har
hadoop fs -ls har:///user/hadoop/output/input.har
解归档文件
hadoop fs -cp har:///user/hadoop/output/input.har/* /user/hadoop
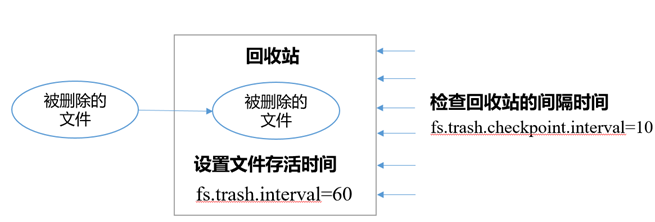
回收站
开启回收站功能,可以将删除的文件在不超时的情况下,恢复原数据,起到防止误删除、备份等作用。
1)回收站参数设置及工作机制
- 开启回收站功能参数说明:
1、默认值fs.trash.interval=0,0表示禁用回收站;其他值表示设置文件的存活时间。
2、默认值fs.trash.checkpoint.interval=0,检查回收站的间隔时间。如果该值为0,则该值设置和fs.trash.interval的参数值相等。
3、要求fs.trash.checkpoint.interval<=fs.trash.interval。
- 回收站的工作机制
- 启用回收站
修改core-site.xml,配置垃圾回收时间为1分钟。
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>1</value>
</property>
- 查看回收站
回收站目录在hdfs集群中的路径:/user/hadoop/.Trash/….
- 通过程序删除的文件不会经过回收站,需要调用moveToTrash()才进入回收站
Trash trash = New Trash(conf);
trash.moveToTrash(path);
- 通过网页上直接删除的文件也不会走回收站。
- 只有在命令行利用hadoop fs -rm命令删除的文件才会走回收站。
hadoop fs -rm -r /user/hadoop/input
2020-07-14 16:13:42,643 INFO fs.TrashPolicyDefault: Moved: 'hdfs://hadoop102:9820/user/hadoop/input' to trash at: hdfs://hadoop102:9820/user/hadoop/.Trash/Current/user/hadoop/input
- 恢复回收站数据
hadoop fs –mv /user/hadoop/.Trash/Current/user/hadoop/input /user/hadoop/input
Hadoop3.x新特性
多NN的HA架构
HDFS NameNode高可用性的初始实现为单个活动NameNode和单个备用NameNode,将edits复制到三个JournalNode。该体系结构能够容忍系统中一个NN或一个JN的故障。
但是,某些部署需要更高程度的容错能力。Hadoop3.x允许用户运行多个备用NameNode。例如,通过配置三个NameNode和五个JournalNode,群集能够容忍两个节点而不是一个节点的故障。
纠删码
HDFS中的默认3副本方案在存储空间和其他资源(例如,网络带宽)中具有200%的开销。但是,对于I/O活动相对较低暖和冷数据集,在正常操作期间很少访问其他块副本,但仍会消耗与第一个副本相同的资源量。纠删码(Erasure Coding)能够在不到50% 的数据冗余情况下提供和3副本相同的容错能力,因此,使用纠删码作为副本机制的改进是自然而然的。
查看集群支持的纠删码策略:hdfs ec -listPolicies
Hadoop详解(09) - Hadoop新特性的更多相关文章
- 详解Hadoop3.x新特性功能-HDFS纠删码
文章首发于微信公众号:五分钟学大数据 EC介绍 Erasure Coding 简称EC,中文名:纠删码 EC(纠删码)是一种编码技术,在HDFS之前,这种编码技术在廉价磁盘冗余阵列(RAID)中应用 ...
- linux useradd(adduser)命令参数及用法详解(linux创建新用户命令)
linux useradd(adduser)命令参数及用法详解(linux创建新用户命令) useradd可用来建立用户帐号.帐号建好之后,再用passwd设定帐号的密码.而可用userdel删除帐号 ...
- 小甲鱼PE详解之输入表(导出表)详解(PE详解09)
小甲鱼PE详解之输出表(导出表)详解(PE详解09) 当PE 文件被执行的时候,Windows 加载器将文件装入内存并将导入表(Export Table) 登记的动态链接库(一般是DLL 格式)文件一 ...
- Java精通并发-自旋对于synchronized关键字的底层意义与价值分析以及互斥锁属性详解与Monitor对象特性解说【纯理论】
自旋对于synchronized关键字的底层意义与价值分析: 对于synchronized关键字的底层意义和价值分析,下面用纯理论的方式来对它进行阐述,自旋这个概念就会应运而生,还是很重要的,下面阐述 ...
- 【图文详解】Hadoop集群搭建(CentOs6.3)
本文主要详细地描述了hadoop集群的搭建以及一些配置文件的说明,用于自己复习以及供新人学习,若有错误之处还请指出. 前期准备 先给出我的集群架构: 到hadoop官网下载好hadoop安装包http ...
- [Big Data]Hadoop详解一
从数据爆炸开始... 一. 第三次工业革命 第一次:18世纪60年代,手工工厂向机器大生产过渡,以蒸汽机的发明和使用为标志. 第二次:19世纪70年代,各种新技术新发明不断被应 ...
- Hadoop详解一:Hadoop简介
从数据爆炸开始... 一. 第三次工业革命 第一次:18世纪60年代,手工工厂向机器大生产过渡,以蒸汽机的发明和使用为标志. 第二次:19世纪70年代,各种新技术新发明不断被应 ...
- Js apply方法与call方法详解 附ES6新写法
我在一开始看到javascript的函数apply和call时,非常的模糊,看也看不懂,最近在网上看到一些文章对apply方法和call的一些示例,总算是看的有点眉目了,在这里我做如下笔记,希望和大家 ...
- FFmpeg开发笔记(五):ffmpeg解码的基本流程详解(ffmpeg3新解码api)
若该文为原创文章,未经允许不得转载原博主博客地址:https://blog.csdn.net/qq21497936原博主博客导航:https://blog.csdn.net/qq21497936/ar ...
- APNS推送服务证书制作 图文详解教程(新)
iOS消息推送的工作机制可以简单的用下图来概括: Provider是指某个iPhone软件的Push服务器,APNS是Apple Push Notification Service的缩写,是苹果的服务 ...
随机推荐
- 怎么在线预览.doc,.docx,.ofd,.pdf,.wps,.cad文件以及Office文档的在线解析方式。
前言 Office文件在线预览是目前移动化办公的一种新趋势.Office在线预览指的是Office系列的文件在线查看而不依附域客户端的存在.在浏览器或者浏览器控件中可以预览查看Word.PDF.Exc ...
- JSON parse error: Cannot deserialize value of type `java.lang.Integer` from Boolean value
问题原因所在:前端Vue传输的数据字段类型和后端实体类字段不一致. 我的实体类字段是int类型.前端传输的数据是布尔类型. 文章目录 1.后端方法 2.实体类字段 2.前端传输的数据 1.后端方法 @ ...
- 微服务组件--限流框架Spring Cloud Hystrix分析
Hystrix的介绍 [1]Hystrix是springCloud的组件之一,Hystrix 可以让我们在分布式系统中对服务间的调用进行控制加入一些调用延迟或者依赖故障的容错机制. [2]Hystri ...
- NLP之基于词嵌入(WordVec)的嵌入矩阵生成并可视化
词嵌入 @ 目录 词嵌入 1.理论 1.1 为什么使用词嵌入? 1.2 词嵌入的类比推理 1.3 学习词嵌入 1.4 Word2Vec & Skip-Gram(跳字模型) 1.5 分级& ...
- python用ffmpeg进行视频处理
1.下载及安装 在ffmpeg官网https://ffmpeg.zeranoe.com/builds/可以下载到需要的版本,然后解压到D盘,添加环境变量(如D:\ffmpeg\bin) 在cmd输入f ...
- 基于数组或链表的学生信息管理系统(小学期C语言程序实训)
1.基于数组的学生信息管理系统 实验内容: 编写并调试程序,实现学校各专业班级学生信息的管理.定义学生信息的结构体类型,包括:学号.姓名.专业.班级.3门成绩. 实验要求: (1) main函数:以菜 ...
- 7.websocket收发消息
客户端主动向服务端发起websocket连接,服务端接收到连接后通过(握手) 客户端 websocket socket = new WebSocket('ws://127.0.0.1/ws/'); 服 ...
- 基于SqlSugar的开发框架循序渐进介绍(17)-- 基于CSRedis实现缓存的处理
在一个应用系统的开发框架中,往往很多地方需要用到缓存的处理,有些地方是为了便于记录用户的数据,有些地方是为了提高系统的响应速度,如有时候我们在发送一个短信验证码的时候,可以在缓存中设置几分钟的过期时间 ...
- Django开发汇总
基本配置 # 设置数据库为使用的mysql DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'libr ...
- 关于图计算&图学习的基础知识概览:前置知识点学习(Paddle Graph Learning (PGL))
关于图计算&图学习的基础知识概览:前置知识点学习(Paddle Graph Learning (PGL)) 欢迎fork本项目原始链接:关于图计算&图学习的基础知识概览:前置知识点学习 ...