Solr4.8.0源码分析(25)之SolrCloud的Split流程
Solr4.8.0源码分析(25)之SolrCloud的Split流程(一)
题记:昨天有位网友问我SolrCloud的split的机制是如何的,这个还真不知道,所以今天抽空去看了Split的原理,大致也了解split的原理了,所以也就有了这篇文章。本系列有两篇文章,第一篇为core split,第二篇为collection split。
1. 简介
这里首先需要介绍一个比较容易混淆的概念,其实Solr的HTTP API 和 SolrCloud的HTTP API是不一样,如果接受到的是Solr的HTTP API,比如"http://localhost:8983/solr/admin/cores?action=SPLIT&core=core0&targetCore=core1&targetCore=core2",该方法对应的是CoreAdminHandler 。而"http://localhost:8983/solr/admin/collections?action=SPLITSHARD&collection=core0&shard=shard1",该方法对应的是CollectionsHandler.所以发送不同的HTTP 命令效果是不一样的。两个命令的代码分支是在以下SolrDispatchFilter中形成的:
// Check for the core admin page
if( path.equals( cores.getAdminPath() ) ) {
handler = cores.getMultiCoreHandler();
solrReq = SolrRequestParsers.DEFAULT.parse(null,path, req);
handleAdminRequest(req, response, handler, solrReq);
return;
}
boolean usingAliases = false;
List<String> collectionsList = null;
// Check for the core admin collections url
if( path.equals( "/admin/collections" ) ) {
handler = cores.getCollectionsHandler();
solrReq = SolrRequestParsers.DEFAULT.parse(null,path, req);
handleAdminRequest(req, response, handler, solrReq);
return;
}
2. Core的Split
讲过了core api 和collection的api,那么我们开始来讲core的split。core的split命令在第一小节中已经讲到,如下所示:"cores?action=SPLIT&core=core0&targetCore=core1&targetCore=core2" ,以上命令的意思是将core0切分成core1和core2(core0还是继续保留并对外提供服务的)。除了上述命令,还有以下几个配置参数:
- path,path是指core0索引最后切分好后存放的路径,它支持多个,比如cores?action=SPLIT&core=core0&path=path1&path=path2。
- targetCore,就是将core0索引切分好后放入targetCore中(targetCore必须已经建立),它同样支持多个,请注意path和targetCore两个参数必须至少存在一个。
split.key, 根据该key进行切分,默认为unique_id.
- ranges, 哈希区间,默认按切分个数进行均分。
- 由此可见Core的Split api是较底层的借口,它可以实现将一个core分成任意数量的索引(或者core)。
接下来我们来了解下Core的Split的源码,流程图如下:
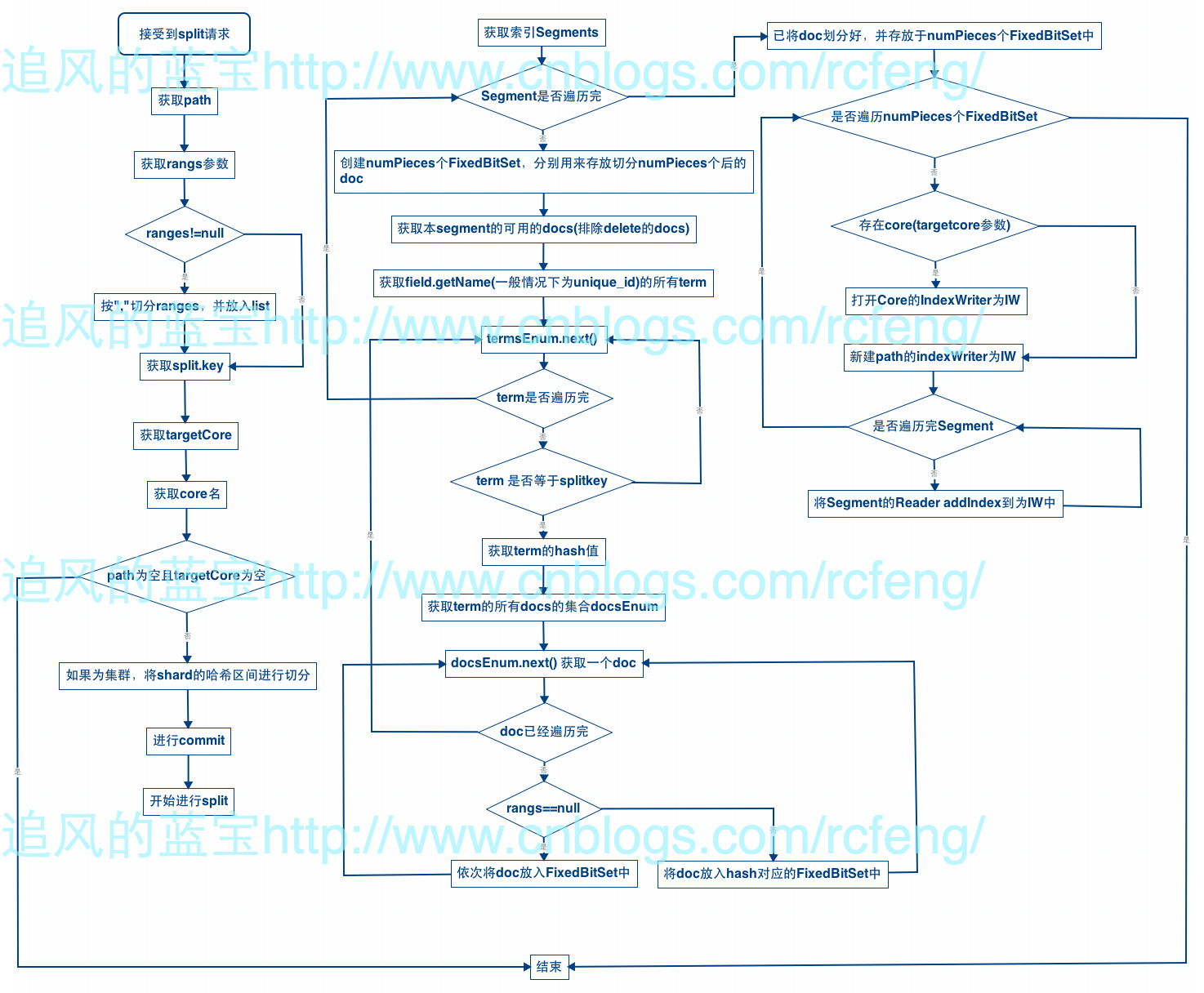
由于代码较多,这里就不贴出来了,可以查看SolrIndexSplitter.java和CoreAdminHandle.java,DirectUpdateHandle2.java对照着比较下,剩下的要补充几点:
1. Core Split是底层的实现接口,它在进行Split的时候不会去对原core的数据进行任何操作,所以即使过程中出现任何问题都不会影响原数据,且在split过程中原core一直在服务的。
2. Core Split可以实现一个core split为多个core,它即支持单机模式下的split也支持集群模式下对一个shard进行split,Collection的split底层就是调用该接口的。
3. 上图流程图中我分成了三列,分别对应三个步骤:
- 解析split请求(最左),主要是确立好hash区间。
- 对Segment中的docs进行切分(中间),切分好的数据是存放在FixedBitSet里面,FixedBitSet是Solr存放的doc id的集合,通过特定的格式进行存储,这在后文中将会具体介绍。
- 将切分好的数据addindex到新的core或者path下,addIndex本质上是进行merge。但是在进行addIndex时候需要注意,addindex传入多少个segment它就会将这些Segment合并成一个Segment,所以如果一下子传入大量的Segment,最后会合并成一个很大的segment,这过程中符合很大。而Split中是每一次传入一个Segment,这样的结果就是出现很多个较小的Segment。
- 最后Split是按新的core或者path依次来的,split完成之后并不会立马就可见,需要人为的进行一下reload操作。
总结:
本文介绍了Core Split的流程以及原理,为Collection Split的介绍做了个奠基。
Solr4.8.0源码分析(25)之SolrCloud的Split流程的更多相关文章
- Solr4.8.0源码分析(24)之SolrCloud的Recovery策略(五)
Solr4.8.0源码分析(24)之SolrCloud的Recovery策略(五) 题记:关于SolrCloud的Recovery策略已经写了四篇了,这篇应该是系统介绍Recovery策略的最后一篇了 ...
- Solr4.8.0源码分析(23)之SolrCloud的Recovery策略(四)
Solr4.8.0源码分析(23)之SolrCloud的Recovery策略(四) 题记:本来计划的SolrCloud的Recovery策略的文章是3篇的,但是没想到Recovery的内容蛮多的,前面 ...
- Solr4.8.0源码分析(22)之SolrCloud的Recovery策略(三)
Solr4.8.0源码分析(22)之SolrCloud的Recovery策略(三) 本文是SolrCloud的Recovery策略系列的第三篇文章,前面两篇主要介绍了Recovery的总体流程,以及P ...
- Solr4.8.0源码分析(21)之SolrCloud的Recovery策略(二)
Solr4.8.0源码分析(21)之SolrCloud的Recovery策略(二) 题记: 前文<Solr4.8.0源码分析(20)之SolrCloud的Recovery策略(一)>中提 ...
- Solr4.8.0源码分析(20)之SolrCloud的Recovery策略(一)
Solr4.8.0源码分析(20)之SolrCloud的Recovery策略(一) 题记: 我们在使用SolrCloud中会经常发现会有备份的shard出现状态Recoverying,这就表明Solr ...
- Solr4.8.0源码分析(14)之SolrCloud索引深入(1)
Solr4.8.0源码分析(14) 之 SolrCloud索引深入(1) 上一章节<Solr In Action 笔记(4) 之 SolrCloud分布式索引基础>简要学习了SolrClo ...
- Solr4.8.0源码分析(15) 之 SolrCloud索引深入(2)
Solr4.8.0源码分析(15) 之 SolrCloud索引深入(2) 上一节主要介绍了SolrCloud分布式索引的整体流程图以及索引链的实现,那么本节开始将分别介绍三个索引过程即LogUpdat ...
- Solr4.8.0源码分析(17)之SolrCloud索引深入(4)
Solr4.8.0源码分析(17)之SolrCloud索引深入(4) 前面几节以add为例已经介绍了solrcloud索引链建索引的三步过程,delete以及deletebyquery跟add过程大同 ...
- Solr4.8.0源码分析(16)之SolrCloud索引深入(3)
Solr4.8.0源码分析(16)之SolrCloud索引深入(3) 前面两节学习了SolrCloud索引过程以及索引链的前两步,LogUpdateProcessorFactory和Distribut ...
随机推荐
- [RxJS] Filtering operators: takeUntil, takeWhile
take(), takeLast(), first(), last(), those opreators all take number or no param. takeUtil and takeW ...
- 第三篇:python基础之编码问题
python基础之编码问题 python基础之编码问题 本节内容 字符串编码问题由来 字符串编码解决方案 1.字符串编码问题由来 由于字符串编码是从ascii--->unicode---&g ...
- hibernate通过判断参数动态组合Hql语句,生成基本通用查询
// public List find(Station entity) { List reuslt = null; // 字符串辅助类 StringBuffer hql = new StringBuf ...
- 解决c#处理excel时故障 找不到可安装的 isam
直接拷贝的以前代码,但因软件版本,系统环境的变化,导致提示“找不到可安装的 isam”. 我目前新的软件环境:win8.1+office2010+vs2013 解决办法是修改连接字符串: 处理exce ...
- oracle 导出导入数据
在window的运行中输出cmd,然后执行下面的一行代码, imp blmp/blmp@orcl full=y file=D:\blmp.dmp OK,问题解决.如果报找不到该blmp.dmp文件,就 ...
- Struts2默认拦截器配置
http://blog.csdn.net/axin66ok/article/details/7321430
- PDF在线预览
1.所需插件jquery.media.js或者pdfobject.js 代码: <html> <head> <style type="text/css" ...
- wordpress 当前栏目名,当前栏目的分类名
wordpress在设计主题和做模板时经常会用到调用当前分类栏目名称,常见的有当前栏目页.文章页,详情代码如下: 1.分类名称与链接 <?php the_category(); ?> 2. ...
- MySQL的C++简单封装
/* *介绍:MySQL的简单封装,支持流操作输入输出MySQL语句,然而并没有什么软用,大二学生自娱自乐,有不足求指点 *作者:MrEO *日期:2016.3.26 */ 头文件 my_sql.h ...
- 【转载】【树状数组区间第K大/小】
原帖:http://www.cnblogs.com/zgmf_x20a/archive/2008/11/15/1334109.html 回顾树状数组的定义,注意到有如下两条性质: 一,c[ans]=s ...