python之路:day3
内容
- 变量的创建过程
- 身份运算和None
- 数据类型
一、 变量创建过程
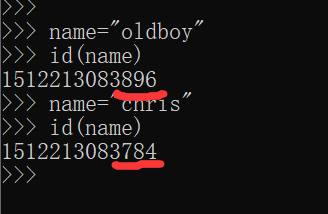
首先,当我们定义了一个变量name = ‘oldboy’的时候,在内存中其实是做了这样一件事:
程序开辟了一块内存空间,将‘oldboy’存储进去,再让变量名name指向‘oldboy’所在的内存地址。如下图所示:

我们可以通过id()方法查看这个变量在内存中的地址
1 >>> name = "oldboy"
2 >>> id(name)
3 4317182304
变量的修改
一般我们认为修改一个变量就是用新值把旧值覆盖掉, 可python是这样实现的么?
1 >>> name = "oldboy"
2 >>> id(name)
3 4317182304
4 >>>
5 >>> name = "alex"
6 >>> id(name) # 如果只是在原有地址上修改,那么修改后内存地址不应该变化呀。
7 4317182360
实际的原理什么样的呢? 程序先申请了一块内存空间来存储‘oldboy’,让name变量名指向这块内存空间
执行到name=‘alex’之后又申请了另一块内存空间来存储‘alex’,并让原本指向‘oldboy’内存的链接断开,让name再指向‘alex’。

变量的指向关系
提问:下面这段代码为何出现这样的现象?
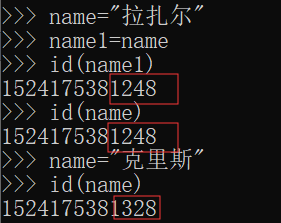
1 >>> name1 = 'oldboy'
2 >>> name2 = name1 # 把name1赋值给name2,这样name2的值也是oldboy了
3 >>> print(name1,name2)
4 oldboy oldboy
5 >>>
6 >>> name1 = 'alex'
7 >>> print(name1,name2) #改了name1后,name2为何没跟着改?
8 alex oldboy
要想知道上面问题的结果是为什么,首先要了解在内存中两个变量的存储情况

从上面的示意图中我们可以知道,当执行name2=name1这句话的时候,事实上是让name2指向了‘oldboy’所在的内存地址。
修改name1的值,相当于断开了name1到‘oldboy’的链接,重新建立name1和‘alex’之间的链接。在这个过程中,始终没有影响到name2和‘oldboy‘之间的关系,因此name2还是‘oldboy’,而name1变成了‘alex’。
二、身份运算和None
python 中有很多种数据类型, 查看一个数据的类型的方法是type().
>>> name="克里斯"
>>> age = 29
>>>
>>> name
'克里斯'
>>>
>>> type(name),type(age)
(<class 'str'="">, <class 'int'="">)
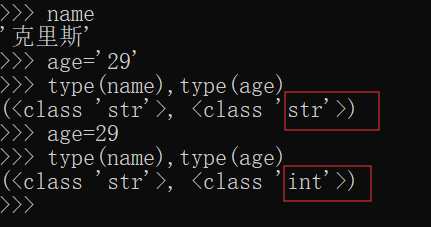
判断一个数据类型是不是str, or int等,可以用身份运算符is

>>> type(name) is str
True
>>>
>>> type(name) is not int
True

空值None
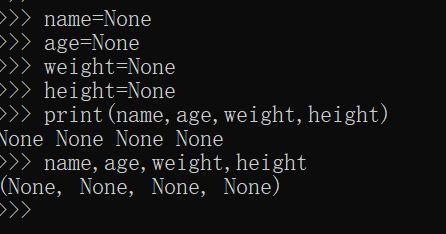
代表什么都没有的意思,一般用在哪呢? 比如玩游戏,你要初始化一个女朋友, 需要填上姓名、年龄、身高、体重等信息, 这些信息是让玩家填的,在填之前,你要先把变量定义好,那就得存个值 ,这个值用0,1来占位不合适 ,用True,False也不合适 ,用None最合适
>>> name=None
>>> age=None
>>> height=None
>>> weight=None
>>>
>>> name,age,height,weight
(None, None, None, None)
>>>
此时可用is 运算符来判断变量是不是None
1 >>> if name is None:
2 ... print("你的女朋友还没起名字呢.")
3 ...
4 你的女朋友还没起名字呢.

其实用==判断也行,但是不符合开发规范
>>> name == None
True
三元运算
显的很NB的代码写法。
1 name = "Eva"
2 sex = None
3 # 普通写法
4 if name == "Eva":
5 sex = "Female"
6 else:
7 sex = "Male"
8 # 用三元运算来写
9 sex = "Female" if name == "Eva" else "Male"
三、数据类型
列表
定义:[]内以逗号分隔,按照索引,存放各种数据类型,每个位置代表一个元素
再回顾下列表的特点:
1.可存放多个值
2.按照从左到右的顺序定义列表元素,下标从0开始顺序访问,有序

3.可修改指定索引位置对应的值,可变
列表增加操作
- 追加,数据会追加到尾部
>>> names
['alex', 'jack']
>>> names.append("rain")
>>> names.append("eva")
>>>
>>> names
['alex', 'jack', 'rain', 'eva']
- 插入,可插入任何位置
>>> names.insert(2,"黑姑娘")
>>> names
['alex', 'jack', '黑姑娘', 'rain', 'eva']
>>>
- 合并,可以把另一外列表的值合并进来
>>> n2 = ["狗蛋","绿毛","鸡头"]
>>> names
['alex', 'jack', '黑姑娘', 'rain', 'eva']
>>> names.extend(n2)
>>> names
['alex', 'jack', '黑姑娘', 'rain', 'eva', '狗蛋', '绿毛', '鸡头']
- 列表嵌套
>>> names.insert(2,[1,2,3])
>>> names
['alex', 'jack', [1, 2, 3], '黑姑娘', 'rain', 'eva', '狗蛋', '绿毛', '鸡头']
>>> names[2][1]
2
删除操作
- del 直接删
>>> names
['alex', 'jack', [1, 2, 3], '黑姑娘', 'rain', 'eva', '狗蛋', '绿毛', '鸡头']
>>> del names[2]
>>> names
['alex', 'jack', '黑姑娘', 'rain', 'eva', '狗蛋', '绿毛', '鸡头'] - pop 删
>>> names
['alex', 'jack', '黑姑娘', 'rain', 'eva', '狗蛋', '绿毛', '鸡头']
>>> names.pop() #默认删除最后一个元素并返回被删除的值
'鸡头'
>>> names
['alex', 'jack', '黑姑娘', 'rain', 'eva', '狗蛋', '绿毛']
>>> help(names.pop)
>>> names.pop(1) #删除指定元素
'jack'
- clear 清空
>>> n2
['狗蛋', '绿毛', '鸡头']
>>> n2.clear()
>>> n2
[]
修改操作
>>> names
['alex', '黑姑娘', 'rain', 'eva', '狗蛋', '绿毛']
>>> names[0] = "金角大王"
>>> names[-1] = "银角大王"
>>> names
['金角大王', '黑姑娘', 'rain', 'eva', '狗蛋', '银角大王']
查操作
>>> names
['金角大王', '黑姑娘', 'rain', 'eva', '狗蛋', '银角大王', 'eva']
>>>
>>> names.index("eva") #返回从左开始匹配到的第一个eva的索引
3
>>> names.count("eva") #返回eva的个数
2
切片
切片就像切面包,可以同时取出元素的多个值
names[start:end]
>>> names
['金角大王', '黑姑娘', 'rain', 'eva', '狗蛋', '银角大王', 'eva']
>>> names[1:4] #不包含下标4的元素
['黑姑娘', 'rain', 'eva']
*切片的特性是顾头不顾尾,即start的元素会被包含,end-1是实际取出来的值
倒着切
>>> names[-5:-1]
['rain', 'eva', '狗蛋', '银角大王']
但其实我想要的是后5个,只打印了4个,’eva’这个值没出来,为什么,因为上面提到的顾头不顾尾
可是想把后5个全取出来如何做呢?
>>> names[-5:]
['rain', 'eva', '狗蛋', '银角大王', 'eva']
如果取前几个值 ,一样可以把:号左边的省掉
>>> names
['金角大王', '黑姑娘', 'rain', 'eva', '狗蛋', '银角大王', 'eva']
>>> names[0:3]
['金角大王', '黑姑娘', 'rain']
>>> names[:3] #跟上面一样的效果
['金角大王', '黑姑娘', 'rain']
步长, 允许跳着取值
names[start:end:step] #step 默认是1
>>> a
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> a[0:7:2] #设置步长为2
[0, 2, 4, 6]
>>> a
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>>
>>> a[::3] #按步长3打印列表,第1个:是省略掉的start:end
[0, 3, 6, 9]
列表反转
>>> a[::-1] #通过把步长设置成负值,可达到列表返转的效果
[9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
>>> a[::-2]
[9, 7, 5, 3, 1]
排序&反转
排序
>>> a = [83,4,2,4,6,19,33,21]
>>> a.sort()
>>> a
[2, 4, 4, 6, 19, 21, 33, 83]
下面的排序结果为何如何解释?
>>> names=['金角大王', 'rain', '@', '黑姑娘', '狗蛋', "","#",'银角大王', 'eva']
>>> names.sort()
>>> names
['#', '', '@', 'eva', 'rain', '狗蛋', '金角大王', '银角大王', '黑姑娘']
答案全在这张表上,虽然后面我们会讲,但现在先知道,排序的优化级规则是按这张表来的

反转
>>> names
['#', '', '@', 'eva', 'rain', '狗蛋', '金角大王', '银角大王', '黑姑娘']
>>> names.reverse()
>>> names
['黑姑娘', '银角大王', '金角大王', '狗蛋', 'rain', 'eva', '@', '', '#']
循环列表
>>> for i in names:
... print(i)
...
黑姑娘
银角大王
金角大王
狗蛋
rain
eva
@
4
#
编程练习-购物车程序开发
根据以下数据结构:
goods = [
{"name": "电脑", "price": 1999},
{"name": "鼠标", "price": 10},
{"name": "游艇", "price": 20},
{"name": "美女", "price": 998},
......
]
实现功能要求:
1、启动程序后,让用户输入工资,然后进入循环,打印商品列表和编号
2、允许用户根据商品编号选择商品
3、用户选择商品后,检测余额是否够,够就直接扣款,并加入购物车, 不够就提醒余额不足
4、可随时退出,退出时,打印已购买商品和余额
元组
有些时候我们的列表数据不想被人修改时怎么办? 就可以用元组存放,元组又被称为只读列表,不能修改。
定义:与列表类似,只不过[]改成()
特性:
1.可存放多个值
2.不可变
3.按照从左到右的顺序定义元组元素,下标从0开始顺序访问,有序
创建
ages = (11, 22, 33, 44, 55)
#或
ages = tuple((11, 22, 33, 44, 55))
常用操作
#索引
>>> ages = (11, 22, 33, 44, 55)
>>> ages[0]
11
>>> ages[3]
44
>>> ages[-1]
55
#切片:同list
#循环
>>> for age in ages:
print(age)
11
22
33
44
55
#长度
>>> len(ages)
5
#包含
>>> 11 in ages
True
>>> 66 in ages
False
>>> 11 not in ages
False
注意:元组本身不可变,如果元组中还包含其他可变元素,这些可变元素可以改变
>>> data
(99, 88, 77, ['Alex', 'Jack'], 33)
>>> data[3][0] = '金角大王'
>>> data
(99, 88, 77, ['金角大王', 'Jack'], 33)
为啥呢? 因为元组只是存每个元素的内存地址,上面[‘金角大王’, ‘Jack’]这个列表本身的内存地址存在元组里确实不可变,但是这个列表包含的元素的内存地址是存在另外一块空间里的,是可变的。

字符串
定义
字符串是一个有序的字符的集合,用于存储和表示基本的文本信息,’ ‘或’’ ‘’或’’’ ‘’’中间包含的内容称之为字符串
创建:
s = 'Hello,Eva!How are you?'
特性:
- 按照从左到右的顺序定义字符集合,下标从0开始顺序访问,有序

- 可以进行切片操作
- 不可变,字符串是不可变的,不能像列表一样修改其中某个元素,所有对字符串的修改操作其实都是相当于生成了一份新数据。
补充:
1.字符串的单引号和双引号都无法取消特殊字符的含义,如果想让引号内所有字符均取消特殊意义,在引号前面加r,如name=r’l\thf’
字符串的常用操作
字符串操作方法有非常多,但有些不常用 ,我们只讲重要的一些给大家,其它100年都用不上的有兴趣可以自己研究

def capitalize(self):
首字母大写
def casefold(self):
把字符串全变小写
>> > c = 'Alex Li'
>> > c.casefold()
'alex li'
def center(self, width, fillchar=None):
>> > c.center(50, "-")
'---------------------Alex Li----------------------'
def count(self, sub, start=None, end=None):
"""
S.count(sub[, start[, end]]) -> int
>>> s = "welcome to apeland"
>>> s.count('e')
3
>>> s.count('e',3)
2
>>> s.count('e',3,-1)
2
def encode(self, encoding='utf-8', errors='strict'):
"""
编码,日后讲
def endswith(self, suffix, start=None, end=None):
>> > s = "welcome to apeland"
>> > s.endswith("land") 判断以什么结尾
True
def find(self, sub, start=None, end=None):
"""
S.find(sub[, start[, end]]) -> int
Return the lowest index in S where substring sub is found,
such that sub is contained within S[start:end]. Optional
arguments start and end are interpreted as in slice notation.
Return -1 on failure.
"""
return 0
def format(self, *args, **kwargs): # known special case of str.format
>> > s = "Welcome {0} to Apeland,you are No.{1} user."
>> > s.format("Eva", 9999)
'Welcome Eva to Apeland,you are No.9999 user.'
>> > s1 = "Welcome {name} to Apeland,you are No.{user_num} user."
>> > s1.format(name="Alex", user_num=999)
'Welcome Alex to Apeland,you are No.999 user.'
def format_map(self, mapping):
"""
S.format_map(mapping) -> str
Return a formatted version of S, using substitutions from mapping.
The substitutions are identified by braces ('{' and '}').
"""
讲完dict再讲这个
def index(self, sub, start=None, end=None):
"""
S.index(sub[, start[, end]]) -> int
Return the lowest index in S where substring sub is found,
such that sub is contained within S[start:end]. Optional
arguments start and end are interpreted as in slice notation.
Raises ValueError when the substring is not found.
"""
def isdigit(self):
"""
S.isdigit() -> bool
Return True if all characters in S are digits
and there is at least one character in S, False otherwise.
"""
return False
def islower(self):
"""
S.islower() -> bool
Return True if all cased characters in S are lowercase and there is
at least one cased character in S, False otherwise.
"""
def isspace(self):
"""
S.isspace() -> bool
Return True if all characters in S are whitespace
and there is at least one character in S, False otherwise.
"""
def isupper(self):
"""
S.isupper() -> bool
Return True if all cased characters in S are uppercase and there is
at least one cased character in S, False otherwise.
"""
def join(self, iterable):
"""
S.join(iterable) -> str
Return a string which is the concatenation of the strings in the
iterable. The separator between elements is S.
"""
>>> n = ['alex','jack','rain']
>>> '|'.join(n)
'alex|jack|rain'
def ljust(self, width, fillchar=None):
"""
S.ljust(width[, fillchar]) -> str
Return S left-justified in a Unicode string of length width. Padding is
done using the specified fill character (default is a space).
"""
return ""
def lower(self):
"""
S.lower() -> str
Return a copy of the string S converted to lowercase.
"""
return ""
def lstrip(self, chars=None):
"""
S.lstrip([chars]) -> str
Return a copy of the string S with leading whitespace removed.
If chars is given and not None, remove characters in chars instead.
"""
return ""
def replace(self, old, new, count=None):
"""
S.replace(old, new[, count]) -> str
Return a copy of S with all occurrences of substring
old replaced by new. If the optional argument count is
given, only the first count occurrences are replaced.
"""
return ""
def rjust(self, width, fillchar=None):
"""
S.rjust(width[, fillchar]) -> str
Return S right-justified in a string of length width. Padding is
done using the specified fill character (default is a space).
"""
return ""
def rsplit(self, sep=None, maxsplit=-1):
"""
S.rsplit(sep=None, maxsplit=-1) -> list of strings
Return a list of the words in S, using sep as the
delimiter string, starting at the end of the string and
working to the front. If maxsplit is given, at most maxsplit
splits are done. If sep is not specified, any whitespace string
is a separator.
"""
return []
def rstrip(self, chars=None):
"""
S.rstrip([chars]) -> str
Return a copy of the string S with trailing whitespace removed.
If chars is given and not None, remove characters in chars instead.
"""
return ""
def split(self, sep=None, maxsplit=-1):
"""
S.split(sep=None, maxsplit=-1) -> list of strings
Return a list of the words in S, using sep as the
delimiter string. If maxsplit is given, at most maxsplit
splits are done. If sep is not specified or is None, any
whitespace string is a separator and empty strings are
removed from the result.
"""
return []
def startswith(self, prefix, start=None, end=None):
"""
S.startswith(prefix[, start[, end]]) -> bool
Return True if S starts with the specified prefix, False otherwise.
With optional start, test S beginning at that position.
With optional end, stop comparing S at that position.
prefix can also be a tuple of strings to try.
"""
return False
def strip(self, chars=None):
"""
S.strip([chars]) -> str
Return a copy of the string S with leading and trailing
whitespace removed.
If chars is given and not None, remove characters in chars instead.
"""
return ""
def swapcase(self):
"""
S.swapcase() -> str
Return a copy of S with uppercase characters converted to lowercase
and vice versa.
"""
return ""
def upper(self):
"""
S.upper() -> str
Return a copy of S converted to uppercase.
"""
return ""
def zfill(self, width):
"""
S.zfill(width) -> str
Pad a numeric string S with zeros on the left, to fill a field
of the specified width. The string S is never truncated.
"""
return ""
字典
引子
我们学了列表 , 现在有个需求, 把你们公司每个员工的姓名、年龄、职务、工资存到列表里,你怎么存?
staff_list = [
["Alex",23,"CEO",66000],
["黑姑娘",24,"行政",4000],
["佩奇",26,"讲师",40000],
# [xxx,xx,xx,xxx]
# [xxx,xx,xx,xxx]
# [xxx,xx,xx,xxx]
]
这样存没问题,不过你要查一个人的工资的话, 是不是得把列表遍历一遍
for i in staff_list:if i[0] == '黑姑娘':print(i)break
但假如你公司有2万人,如果你要找的黑姑娘正好在列表末尾,那意味着你要遍历2万次,才能找到这个信息。列表越大,查找速度越慢。
好了,现在福音来了, 接下来学要的字典可以 查询数据又快、操作又方便,是日后开发中必备神器。
字典是Python语言中唯一的映射类型。
定义:
{key1:value1,key2:value2}
1、键与值用冒号“:”分开;2、项与项用逗号“,”分开;
示例:
info = {"name":"小猿圈","mission": "帮一千万极客高效学编程","website": "http://apeland.com"}
特性:
- key-value结构
- key必须为不可变数据类型、必须唯一
- 可存放任意多个value、可修改、可以不唯一
- 无序
- 查询速度快,且不受dict的大小影响,至于为何快?我们学完hash再解释。
创建操作
>>>person = {"name": "alex", 'age': 20}
#或
>>>person = dict(name='seven', age=20)
#或
>>>person = dict({"name": "egon", 'age': 20})
#或
>>> {}.fromkeys([1,2,3,4,5,6,7,8],100)
{1: 100, 2: 100, 3: 100, 4: 100, 5: 100, 6: 100, 7: 100, 8: 100}
增加操作
names = {
"alex": [23, "CEO", 66000],
"黑姑娘": [24, "行政", 4000],
}
# 新增k
names["佩奇"] = [26, "讲师", 40000]
names.setdefault("oldboy",[50,"boss",100000]) # D.setdefault(k[,d]) -> D.get(k,d), also set D[k]=d if k not in D
删除操作
names.pop("alex") # 删除指定key
names.popitem() # 随便删除1个key
del names["oldboy"] # 删除指定key,同pop方法
names.clear() # 清空dict
修改操作
dic['key'] = 'new_value',如果key在字典中存在,'new_value'将会替代原来的value值;
dic.update(dic2) 将字典dic2的键值对添加到字典dic中
查操作
dic['key'] #返回字典中key对应的值,若key不存在字典中,则报错;
dic.get(key, default = None)#返回字典中key对应的值,若key不存在字典中,则返回default的值(default默认为None)
'key' in dic #若存在则返回True,没有则返回False
dic.keys() 返回一个包含字典所有KEY的列表;
dic.values() 返回一个包含字典所有value的列表;
dic.items() 返回一个包含所有(键,值)元组的列表;
循环
1、for k in dic.keys()
2、for k,v in dic.items()
3、for k in dic # 推荐用这种,效率速度最快
info = {
"name":"小猿圈",
"mission": "帮一千万极客高效学编程",
"website": "http://apeland.com"
}
for k in info:
print(k,info[k])
输出
name 小猿圈
mission 帮一千万极客高效学编程
website http://apeland.com
求长度
len(dic)
练习题
- 用你能想到的最少的代码生成一个包含100个key的字典,每个value的值不能一样
- {‘k0’: 0, ‘k1’: 1, ‘k2’: 2, ‘k3’: 3, ‘k4’: 4, ‘k5’: 5, ‘k6’: 6, ‘k7’: 7, ‘k8’: 8, ‘k9’: 9} 请把这个dict中key大于5的值value打印出来。
- 把题2中value是偶数的统一改成-1
- 请设计一个dict, 存储你们公司每个人的信息, 信息包含至少姓名、年龄、电话、职位、工资,并提供一个简单的查找接口,用户按你的要求输入要查找的人,你的程序把查到的信息打印出来
集合
定义
集合跟我们学的列表有点像,也是可以存一堆数据,不过它有几个独特的特点,令其在整个Python语言中占有一席之地,
- 里面的元素不可变,代表你不能存一个list、dict 在集合里,字符串、数字、元组等不可变类型可以存
- 天生去重,在集合里没办法存重复的元素
- 无序,不像列表一样通过索引来标记在列表中的位置 ,元素是无序的,集合中的元素没有先后之分,如集合{3,4,5}和{3,5,4}算作同一个集合
基于上面的特性,我们可以用集合来干2件事,去重和关系运算
语法
创建集合
>>> a = {1,2,3,4,2,'alex',3,'rain','alex'}
>>> a
{1, 2, 3, 4, 'alex', 'rain'}
由于它是天生去重的,重复的值你根本存不进去
帮列表去重
帮列表去重最快速的办法是什么? 就是把它转成集合,去重完,再转回列表
>>> b
[1, 2, 3, 4, 2, 'alex', 3, 'rain', 'alex']
>>> set(b)
{1, 2, 3, 4, 'alex', 'rain'}
>>>
>>> b = list(set(b)) #一句代码搞定
>>> b
[1, 2, 3, 4, 'alex', 'rain']
增删改查
>>> a
{1, 2, 3, 4, 'alex', 'rain'}
#新增
>>> a.add('黑姑娘')
#删除discard
>>> a
{2, 3, '黑姑娘', 'alex', 'rain'}
>>> a.discard('rain') #删除一个存在的值
>>> a.discard('rain2') #如果这个值不存在,do nothing.
>>> a
{2, 3, '黑姑娘', 'alex'}
>>>
#随机删除,少用,或特定场景用
>>> a.pop() #删除并返回
1
#删除remove
>>> a.remove(4)
#查
>>> a
{2, 3, '黑姑娘', 'alex', 'rain'}
>>> 'alex' in a
True
#改
呵呵,不能改。。。
关系运算
s_1024 = {"佩奇","老男孩","海峰","马JJ","老村长","黑姑娘","Alex"}
s_pornhub = {"Alex","Egon","Rain","马JJ","Nick","Jack"}
print(s_1024 & s_pornhub) # 交集, elements in both set
print(s_1024 | s_pornhub) # 并集 or 合集
print(s_1024 - s_pornhub) # 差集 , only in 1024
print(s_pornhub - s_1024) # 差集, only in pornhub
print(s_1024 ^ s_pornhub) # 对称差集, 把脚踩2只船的人T出去
两个集合之间一般有三种关系,相交、包含、不相交。在Python中分别用下面的方法判断:
print(s_1024.isdisjoint(s_pornhub)) # 判断2个集合是不是不相交,返回True or False
print(s_1024.issubset(s_pornhub)) # 判断s_1024是不是s_pornhub的子集,返回True or False
print(s_1024.issuperset(s_pornhub)) # 判断s_1024是不是s_pornhub的父集,返回True or False
python之路:day3的更多相关文章
- Python之路,Day3 - Python基础3
一.文件操作 对文件操作流程 打开文件,得到文件句柄并赋值给一个变量 通过句柄对文件进行操作 关闭文件 现有文件如下 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ...
- Python之路 day3 高阶函数
#!/usr/bin/env python # -*- coding:utf-8 -*- #Author:ersa """ 变量可以指向函数,函数的参数能接收变量, 那么 ...
- Python之路 day3 递归函数
#!/usr/bin/env python # -*- coding:utf-8 -*- #Author:ersa """ 在函数内部,可以调用其他函数.如果一个函数在内 ...
- Python之路 day3 全局变量、局部变量
#!/usr/bin/env python # -*- coding:utf-8 -*- #Author:ersa """ 全局与局部变量 在子程序中定义的变量称为局部变 ...
- Python之路 day3 函数定义 *args及**kwargs
#!/usr/bin/env python # -*- coding:utf-8 -*- #Author:ersa import time # def logger(): # time_format ...
- python之路-Day3
字典 dic{key:value} 元组与列表相似,唯一就是不能修改dic = {'name':'alex','age':18}查询print(dic['name']) #会报错get方法查询,查询之 ...
- Python之路Day3
摘要: 复习day2内容 介绍set()-->归档到day2了... collections模块常用类 深浅copy的区别 自定义函数 文件操作 常用内建函数介绍 一.深浅copy的区别 #! ...
- 小白的Python之路 day3 函数式编程,高阶函数
函数式编程介绍 函数是Python内建支持的一种封装,我们通过把大段代码拆成函数,通过一层一层的函数调用,就可以把复杂任务分解成简单的任务,这种分解可以称之为面向过程的程序设计.函数就是面向过程的 ...
- 小白的Python之路 day3 函数
1.函数基本语法及特性 背景提要 现在老板让你写一个监控程序,监控服务器的系统状况,当cpu\memory\disk等指标的使用量超过阀值时即发邮件报警,你掏空了所有的知识量,写出了以下代码 1 2 ...
- Python之路
Python学习之路 第一天 Python之路,Day1 - Python基础1介绍.基本语法.流程控制 第一天作业第二天 Python之路,Day2 - Pytho ...
随机推荐
- $loj6043$ [雅礼集训 $2017\ Day7$] 蛐蛐国的修墙方案 搜索
正解:搜索 解题报告: 传送门$QwQ$ 首先由$p_i$是一个序列得,每个点的度数为2.且一定形成若干个环. 考虑先对每个环做,发现若要有解必须是偶环,且一定是隔一条边选一条边的,所以对每个环其实只 ...
- [MySQL实践] 实践记录
[MySQL实践] 实践记录 版权2019.5.17更新 MySQL MySQL各版本区别 一.选择的版本 1. MySQL Community Server 社区版本,开源免费,但不提供官方技术支持 ...
- 关于Springboot找不到mapper.xml问题
今天在写springboot项目时报错org.apache.ibatis.binding.BindingException: Invalid bound statement (not found),找 ...
- 【tf.keras】Linux 非 root 用户安装 CUDA 和 cuDNN
TensorFlow 2.0 for Linux 使用时报错:(cuDNN 版本低了) E tensorflow/stream_executor/cuda/cuda_dnn.cc:319] Loade ...
- i3s 一种开源的三维地理数据规范 简单解读
i3s,esri主推到ogc的一种三维开源GIS数据标准. 版权声明:原创.博客园/B站/小专栏/知乎/CSDN @秋意正寒 转载请标注原地址并声明转载: https://www.cnblogs.co ...
- .Net Core 导出Html到PDF
前言 最近由于项目的需求问题,涉及到了在.Net Core中导出PDF的一个问题,最后选择方式是后端拼接到Html页面然后再通过Html导出到PDF.中间也尝试了许多的NuGet包.但是并不如意,可用 ...
- 集合下篇—Map和Set 源码分析
Map Map不同于Collection集合,Map存放的是键值对,且键不能重复 1 .HashMap (底层是哈希表,Java中用链表的数组实现,存取顺序不一致) 这篇博客主要讲集合的,哈希表这样的 ...
- cogs 826. [Tyvj Feb11] GF打dota 次短路详细原创讲解! dijkstra
826. [Tyvj Feb11] GF打dota ★★☆ 输入文件:dota.in 输出文件:dota.out 简单对比时间限制:1 s 内存限制:128 MB 众所周知,GF同学喜 ...
- 第三篇python用户登录程序实现
需求: 1.通过注册输入用户名和密码 2.能够验证用户名和密码是否正确 3.限制输入一定错误次数后退出程序 4.利用格式化输出方式输出信息 分析: 使用username=input()和passwor ...
- 单调队列优化 dp
The only difference between easy and hard versions is the constraints. Vova likes pictures with kitt ...