neo4j批量导入neo4j-import
neo4j数据批量导入
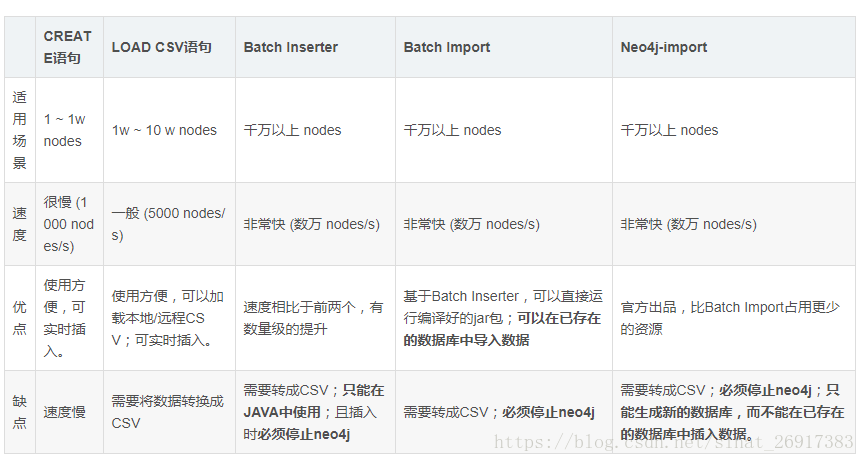
目前主要有以下几种数据插入方式:(转自:如何将大规模数据导入Neo4j)
Cypher CREATE 语句,为每一条数据写一个CREATE
Cypher LOAD CSV 语句,将数据转成CSV格式,通过LOAD CSV读取数据。
官方提供的Java API —— Batch Inserter
大牛编写的 Batch Import 工具
官方提供的 neo4j-import 工具
这边重点来说一下官方最快的neo4j-import,使用的前提条件:
- graph.db需要清空;
- neo4j需要停掉;
- 接受CSV导入,而且格式较为固定;
- 试用场景:首次导入
- 节点名字需要唯一
比较适用:
首次导入,无法迭代更新
来看一下官方案例:Use the Import tool
1 neo4j基本参数
1.1 启动与关闭:
bin\neo4j start
bin\neo4j stop
bin\neo4j restart
bin\neo4j status
1.2 neo4j-admin的参数:控制内存
来源:10.5. Memory recommendations
1.2.1 memrec 是查看参考内存设置
neo4j-admin memrec [--memory=<memory dedicated to Neo4j>] [--database=<name>]
| Option | Default | Description |
|---|---|---|
| –memory | The memory capacity of the machine | The amount of memory to allocate to Neo4j. Valid units are: k, K, m, M, g, G. |
| –database | graph.db | The name of the database. This option will generate numbers for Lucene indexes, and for data volume and native indexes in the database. These can be used as an input into more detailed memory analysis. |
参考:
$neo4j-home> bin/neo4j-admin memrec --memory=16g
- 1
1.2.2 指定缓存–pagecache
还有--pagecache单条命令指定缓存:
bin/neo4j-admin backup --from=192.168.1.34 --backup-dir=/mnt/backup --name=graph.db-backup --pagecache=4G
- 1
指的是,再该条导入数据的指令下,缓存设置。
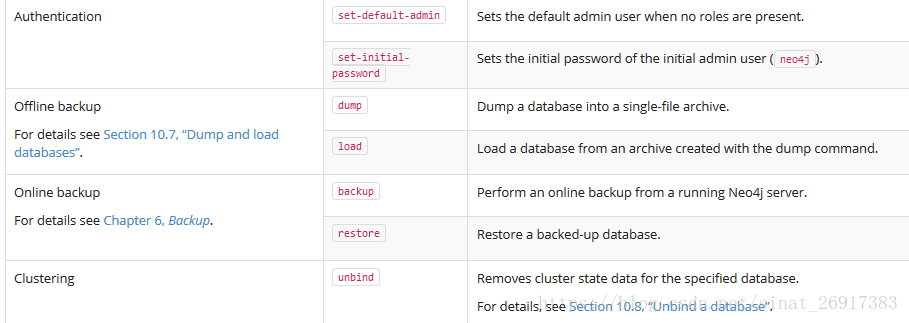
1.3 neo4j-admin的参数:Dump and load databases - 线下备份
执行该两步操作,需要关闭数据库。参考:10.7. Dump and load databases
dump过程:把graph.db转存到.dump
需要关闭数据库
$neo4j-home> bin/neo4j-admin dump --database=graph.db --to=/backups/graph.db/2016-10-02.dump
$neo4j-home> ls /backups/graph.db
$neo4j-home> 2016-10-02.dump
load过程:把.dumpload进来
好像可以不用关闭
$neo4j-home> bin/neo4j stop
Stopping Neo4j.. stopped
$neo4j-home> bin/neo4j-admin load --from=/backups/graph.db/2016-10-02.dump --database=graph.db --force
如果带--force,那么load之后,会更新所有的存在着的.db(any existing database gets overwritten. )
1.4 neo4j-admin的参数:backup and restore - 在线备份
在线备份backup :
$neo4j-home> export HEAP_SIZE=2G
$neo4j-home> mkdir /mnt/backup
$neo4j-home> bin/neo4j-admin backup --from=192.168.1.34 --backup-dir=/mnt/backup --name=graph.db-backup --pagecache=4G
backup 进临时文件夹之中。
追加备份:
$neo4j-home> export HEAP_SIZE=2G
$neo4j-home> bin/neo4j-admin backup --from=192.168.1.34 --backup-dir=/mnt/backup --name=graph.db-backup --fallback-to-full=true --check-consistency=true --pagecache=4G
.
2 简单demo
movies.csv.
movieId:ID,title,year:int,:LABEL
tt0133093,"The Matrix",1999,Movie
tt0234215,"The Matrix Reloaded",2003,Movie;Sequel
tt0242653,"The Matrix Revolutions",2003,Movie;Sequel
其中,title是属性,注意此时需要有双引号;year:int也是属性,只不过该属性是数值型的;
:LABEL与:ID一样生成了一个新节点,也就是一套数据可以通过:生成双节点
actors.csv.
personId:ID,name,:LABEL
keanu,"Keanu Reeves",Actor
laurence,"Laurence Fishburne",Actor
carrieanne,"Carrie-Anne Moss",Actor
roles.csv.
其中,:LABEL非常有意思,是节点的附属属性,其中personId:ID一定是唯一的,:LABEL可以不唯一。
而且,载入之后,:LABEL单独会成为新的节点,而且是去重的。
:START_ID,role,:END_ID,:TYPE
keanu,"Neo",tt0133093,ACTED_IN
keanu,"Neo",tt0234215,ACTED_IN
keanu,"Neo",tt0242653,ACTED_IN
laurence,"Morpheus",tt0133093,ACTED_IN
laurence,"Morpheus",tt0234215,ACTED_IN
laurence,"Morpheus",tt0242653,ACTED_IN
carrieanne,"Trinity",tt0133093,ACTED_IN
carrieanne,"Trinity",tt0234215,ACTED_IN
carrieanne,"Trinity",tt0242653,ACTED_IN
其中,这个节点的属性,role没有标注:,role是属性,可以加双引号,也可以不加。最好是指定一下格式,譬如:int为数值型,还有字符型roles:string[]
linux执行:
neo4j_home$ bin/neo4j-admin import --nodes import/movies.csv --nodes import/actors.csv --relationships import/roles.csv
其中,之前老版本批量导入是:neo4j-import,现在批量导入是:neo4j-admin。
window执行:
neo4j-import.bat --into ../data/databases/graph.db --id-type string --nodes:attribute ../import/node_attribute.csv --relationships ../import/product_SecondLeaf.csv --relationships ../import/scene_isDemond.csv
--into,是指定存入名字,在不同的尝试,可以修改名字。--nodes:attribute,其中,nodes:后面是用来指定节点大类的名称的--id-type string,,The –id-type string is indicating that all :ID columns contain alphanumeric values (there is an optimization for numeric-only id’s).之前节点ID只能由数字组成,现在允许字符+数字共同定义。
linux最后启动:
./bin/neo4j start
window 最后启动:
neo4j.bat console
执行时候错误信息解析:
1 报错信息留存在bad.log
\data\databases\graph.db\bad.log
global id space的报错为节点未定义,或者节点重复
2 如果节点不唯一,直接报错:
global id space,同时后续的内容中端上传,需要删除data/database /graph.db,重新操作一遍
3 其他导入情况列举
主要来源于:B.2. Use the Import tool
3.1 不同分隔符导入
如果导入的节点信息为:
:START_ID;role;:END_ID;:TYPE
keanu;'Neo';tt0133093;ACTED_IN
keanu;'Neo';tt0234215;ACTED_IN
那么可以通过--delimiter来进行指定。
neo4j_home$ bin/neo4j-admin import --nodes import/movies2.csv --nodes import/actors2.csv --relationships import/roles2.csv --delimiter ";" --array-delimiter "|" --quote "'"
3.2 不同数据集定义相同节点
movies5a.csv.
movieId:ID,title,year:int
tt0133093,"The Matrix",1999
sequels5a.csv.
movieId:ID,title,year:int
tt0234215,"The Matrix Reloaded",2003
tt0242653,"The Matrix Revolutions",2003
actors5a.csv.
personId:ID,name
keanu,"Keanu Reeves"
laurence,"Laurence Fishburne"
carrieanne,"Carrie-Anne Moss"
执行语句:
neo4j_home$ bin/neo4j-admin import --nodes:Movie import/movies5a.csv --nodes:Movie:Sequel import/sequels5a.csv --nodes:Actor import/actors5a.csv
执行的时候,把movies5a.csv定义一个节点名字nodes:Movie;
在sequels5a.csv定义节点名字有两个::Movie:Sequel。
3.3 定义关系名称以及关系属性
roles5b.csv.
:START_ID,role,:END_ID
keanu,"Neo",tt0133093
keanu,"Neo",tt0234215
keanu,"Neo",tt0242653
laurence,"Morpheus",tt0133093
laurence,"Morpheus",tt0234215
laurence,"Morpheus",tt0242653
carrieanne,"Trinity",tt0133093
执行内容:
neo4j_home$ bin/neo4j-admin import --relationships:ACTED_IN import/roles5b.csv
其中,:ACTED_IN将关系名称定义为ACTED_IN;同时定义关系的属性也有role
3.4 拆分数据集上传提高效率
节点数据集,标题:movies4-header.csv.
movieId:ID,title,year:int,:LABEL
节点数据集,内容模块1:movies4-part1.csv.
tt0133093,"The Matrix",1999,Movie
tt0234215,"The Matrix Reloaded",2003,Movie;Sequel
节点数据集,内容模块2:movies4-part2.csv.
tt0242653,"The Matrix Revolutions",2003,Movie;Sequel
关系数据集,标题:roles4-header.csv.
:START_ID,role,:END_ID,:TYPE
关系数据集,内容1:roles4-part1.csv.
keanu,"Neo",tt0133093,ACTED_IN
keanu,"Neo",tt0234215,ACTED_IN
关系数据集,内容2:roles4-part2.csv.
laurence,"Morpheus",tt0242653,ACTED_IN
carrieanne,"Trinity",tt0133093,ACTED_IN
执行:
neo4j_home$ bin/neo4j-admin import --nodes "import/movies4-header.csv,import/movies4-part1.csv,import/movies4-part2.csv" --relationships "import/roles4-header.csv,import/roles4-part1.csv,import/roles4-part2.csv"
标题与内容单独分开,然后由:标题,内容模块1,内容模块2,分块导入。
3.5 两个节点集拥有相同的字段
这个会比较经常出现,两个节点集合中,拥有相同字段,如果不设置,就会出现报错。
movies7.csv.
movieId:ID(Movie-ID),title,year:int,:LABEL
1,"The Matrix",1999,Movie
2,"The Matrix Reloaded",2003,Movie;Sequel
3,"The Matrix Revolutions",2003,Movie;Sequel
其中,(Movie-ID),是将ID进行标记
actors7.csv.
personId:ID(Actor-ID),name,:LABEL
1,"Keanu Reeves",Actor
2,"Laurence Fishburne",Actor
3,"Carrie-Anne Moss",Actor
roles7.csv.
:START_ID(Actor-ID),role,:END_ID(Movie-ID)
1,"Neo",1
1,"Neo",2
1,"Neo",3
2,"Morpheus",1
2,"Morpheus",2
2,"Morpheus",3
3,"Trinity",1
3,"Trinity",2
3,"Trinity",3
执行:
neo4j_home$ bin/neo4j-admin import --nodes import/movies7.csv --nodes import/actors7.csv --relationships:ACTED_IN import/roles7.csv
在关联表中定义::START_ID(Actor-ID)与:END_ID(Movie-ID),来指定相应的ID。
3.6 错误信息跳过:错误的节点
错误的关系出现:
roles8a.csv.
:START_ID,role,:END_ID,:TYPE
carrieanne,"Trinity",tt0242653,ACTED_IN
emil,"Emil",tt0133093,ACTED_IN
譬如多出了节点,emil
此时执行:
neo4j_home$ bin/neo4j-admin import --nodes import/movies8a.csv --nodes import/actors8a.csv --relationships import/roles8a.csv --ignore-missing-nodes
其中的--ignore-missing-nodes就是跳过报错的节点,其中,错误信息会记录在bad.log之中:
InputRelationship:
source: roles8a.csv:11
properties: [role, Emil]
startNode: emil (global id space)
endNode: tt0133093 (global id space)
type: ACTED_IN
referring to missing node emil
3.7 错误信息跳过:重复节点
actors8b.csv.
personId:ID,name,:LABEL
keanu,"Keanu Reeves",Actor
laurence,"Laurence Fishburne",Actor
carrieanne,"Carrie-Anne Moss",Actor
laurence,"Laurence Harvey",Actor
在节点数据集actors8b.csv. 中,由重复的节点:laurence
需要执行:
neo4j_home$ bin/neo4j-admin import --nodes import/actors8b.csv --ignore-duplicate-nodes
其中,–ignore-duplicate-nodes就是重复节点忽略
会在bad.log之中显示报错:
Id 'laurence' is defined more than once in global id space, at least at actors8b.csv:3 and actors8b.csv:5
vv
neo4j批量导入neo4j-import的更多相关文章
- neo4j批量导入数据的两种解决方案
neo4j批量导入数据有两种方法,第一种是使用cypher语法中的LOAD CSV,第二种是使用neo4j自带的工具neo4j-admin import. LOAD CSV 导入的文件必须是csv文件 ...
- ASP.NET MVC NPOI导入Excel DataTable批量导入到数据库
使用NPOI导入Excel 首先在MVC项目中导入NPOI 查询NPOI安装,排序依据,选择:最高下载量,选择第一个. 在控制器中创建ExcelController 在Index视图中写入代码: @u ...
- 使用neo4j图数据库的import工具导入数据 -方法和注意事项
背景 最近我在尝试存储知识图谱的过程中,接触到了Neo4j图数据库,这里我摘取了一段Neo4j的简介: Neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中.它是一个嵌 ...
- Neo4j批量插入(Batch Insertion)
新建一个maven工程,这里不赘述如何新建maven工程. 添加Neo4j jar到你的工程 有两种方式: 上网站官网下载jar包,根据自己的系统下载不同的压缩包,详细过程不描述,请自行搜索其他博客 ...
- neo4j数据库迁移---------Neo4j数据库导入导出的方法
Neo4j数据进行备份.还原.迁移的操作时,首先要关闭neo4j; /usr/share/neo4j/bin neo4j stop 如果出现 Neo4j not running 出现这种情况, Neo ...
- [Django]网页中利用ajax实现批量导入数据功能
url.py代码: url(r'^workimport/$', 'keywork.views.import_keywork', name='import_keywork') view.py代码: fr ...
- [diango]批量导入不重复数据
去年研究导入数据的时候写了一个批量导入数据的脚本,但有个问题,如果导入这批数据在数据库中已经存在,那么我们导入的数据不就重复了么,本文就讨论如何解决这个问题? 程序如下: #coding:utf-8 ...
- [Django]数据批量导入
前言:历经一个月的复习,考试终于结束了.这期间上班的时候有研究了Django网页制作过程中,如何将数据批量导入到数据库中. 这个过程真的是惨不忍睹,犯了很多的低级错误,这会在正文中说到的.再者导入数据 ...
- 报表开发之批量导入导出excel
在日常使用报表过程中,会有这样一种情况,你将Excel表分发给各个员工,员工填完后,统一整理成多个Excel,你需要将这些数据,用报表的填报功能,提交录入到数据库中,这样一来可避免到服务器机房录数据的 ...
随机推荐
- JedisCluster API 整理
windows版redis启动服务器命令:redis-server redis.windows.conf 图表来自菜鸟教程: 列表的操作命令 序号 命令及描述 1 BLPOP key1 [key2 ] ...
- JeecgBoot 2.1.1 代码生成器AI版本发布,基于SpringBoot+AntDesign的JAVA快速开发平台
此版本重点升级了 Online 代码生成器,支持更多的控件生成,所见即所得,极大的提高开发效率:同时做了数据库兼容专项工作,让 Online 开发兼容更多数据库:Mysql.SqlServer.Ora ...
- PAT甲级——A1003Emergency
As an emergency rescue team leader of a city, you are given a special map of your country. The map s ...
- 引用不了XXservice,怎么办?
1.tEdasArchiveLogService = (TEdasArchiveLogService) SpringContextHolder.getBean("TEdasArchiveLo ...
- mysql之sql优化
sql的执行顺序: 先看下下面两条多表关联sql,第1条查询到1条记录,第2条查无记录: on 筛选条件在笛卡尔积之前,where筛选条件在笛卡尔积之后执行 先执行from, join的话,左连接,左 ...
- Python-pip更改国内源
windows方式: 1.打开任意文件夹,在上方地址栏中输入%appdata% 2.在此目录里新建文件夹pip 3.在pip文件夹里新建文件名:pip.ini 4.把以下内容复制到pip.ini中,保 ...
- Redis学习笔记01-分布式锁
1.分布式锁的定义与理解 在并发任务中,当对数据执行修改和删除时为了防止多个任务同时拿到数据而产生的混乱,这时就要用到分布式锁来限制程序的并发执行. Redis分布式锁本质上要实现的目标就是在Redi ...
- ES6之主要知识点(四)数值
引自:http://es6.ruanyifeng.com/#docs/number 1.Number.isFinite(),Number.isNaN() Number.isFinite(); // t ...
- vue 报错:Cannot read property '_wrapper' of undefined
我的情况是@click="xx" ,而xx函数未定义
- 2019-8-31-dotnet-通过-WMI-获取系统安装的驱动
title author date CreateTime categories dotnet 通过 WMI 获取系统安装的驱动 lindexi 2019-08-31 16:55:59 +0800 20 ...