docker swarm搭建tidb踩坑日记
背景
公司新项目数据量翻了一倍,每天上亿数据量的读写,传统的单库单表已经满足不了目前的需求,得考虑下分布式存储了。那用啥呢,之前有考虑用到mycat,但是一进官网,一股山寨气息扑面而来,技术群进群还收费。。。打扰了,随后阅览各种逼乎大佬的文章,tidb见吹的不错,就这个了,但部署一看文档似乎有点小麻烦,使用推荐的Ansible部署还得格式化磁盘https://pingcap.com/docs-cn/v3.0/how-to/deploy/orchestrated/ansible/,k8s又不会,那就用swarm先简单部署一套吧,没人会,没运维?。。。没事,我头铁,直接上
机器:四台(都没外网,局域网互通),ubuntu
搭建swarm集群
参考https://yeasy.gitbooks.io/docker_practice/swarm_mode/create.html
使用 docker swarm init 在管理节点初始化一个 Swarm 集群。
docker@manager:~$ docker swarm init --advertise-addr 192.168.99.100
Swarm initialized: current node (dxn1zf6l61qsb1josjja83ngz) is now a manager. To add a worker to this swarm, run the following command: docker swarm join \
--token SWMTKN-1-49nj1cmql0jkz5s954yi3oex3nedyz0fb0xx14ie39trti4wxv-8vxv8rssmk743ojnwacrr2e7c \
192.168.99.100:2377 To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
如果你的 Docker 主机有多个网卡,拥有多个 IP,必须使用 --advertise-addr 指定 IP。
分别登录其余三台机器
docker swarm join \
--token SWMTKN-1-49nj1cmql0jkz5s954yi3oex3nedyz0fb0xx14ie39trti4wxv-8vxv8rssmk743ojnwacrr2e7c \
192.168.99.100:2377
这时,init的那台机器就成了leader节点,其他三成就成了worker节点
查看集群
root@tagsystem004:/tidb_data# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
eevif6put7mqcjjqk7cjqilvm tagsystem001 Ready Active 18.09.5
utcf7oyz4y50mqvoksqm5havp tagsystem002 Ready Active 18.09.5
gxtqaz0pxyirccelnrycxveov * tagsystem004 Ready Active Leader 18.09.5
v2ku133nvee0mckbd1kfgsqu8 tagsystem005 Ready Active 18.09.5
查看集群服务
docker service ls
目前集群上尚无任何服务
搭建harbor
四台集群均无外网,swarm集群就得需要用到私有仓库,这里我用了harbor
搭建记录
https://www.cnblogs.com/qflyue/p/11571058.html
harbor搭建完成后需要把tidb部署所需要的镜像传到harbor (必须)
搭建完成后,记得把crt文件放到每个服务器对应目录下
下载 tidb-docker-compose
git clone https://github.com/pingcap/tidb-docker-compose.git
编辑docker-swarm.yml,将所用镜像编辑为harbor中上传的镜像(当然,有外网的话不用修改,harbor也不用搭建)
version: '3.3' networks:
default:
driver: overlay
attachable: true services:
pd0:
image: pingcap/pd:latest
ports:
- "2379"
volumes:
- ./config/pd.toml:/pd.toml:ro
- ./data:/data
- ./logs:/logs
command:
- --name=pd0
- --client-urls=http://0.0.0.0:2379
- --peer-urls=http://0.0.0.0:2380
- --advertise-client-urls=http://pd0:2379
- --advertise-peer-urls=http://pd0:2380
- --initial-cluster=pd0=http://pd0:2380,pd1=http://pd1:2380,pd2=http://pd2:2380
- --data-dir=/data/pd0
- --config=/pd.toml
- --log-file=/logs/pd0.log
- --log-level=info
pd1:
image: pingcap/pd:latest
ports:
- "2379"
volumes:
- ./config/pd.toml:/pd.toml:ro
- ./data:/data
- ./logs:/logs
command:
- --name=pd1
- --client-urls=http://0.0.0.0:2379
- --peer-urls=http://0.0.0.0:2380
- --advertise-client-urls=http://pd1:2379
- --advertise-peer-urls=http://pd1:2380
- --initial-cluster=pd0=http://pd0:2380,pd1=http://pd1:2380,pd2=http://pd2:2380
- --data-dir=/data/pd1
- --config=/pd.toml
- --log-file=/logs/pd1.log
pd2:
image: pingcap/pd:latest
ports:
- "2379"
volumes:
- ./config/pd.toml:/pd.toml:ro
- ./data:/data
- ./logs:/logs
command:
- --name=pd2
- --client-urls=http://0.0.0.0:2379
- --peer-urls=http://0.0.0.0:2380
- --advertise-client-urls=http://pd2:2379
- --advertise-peer-urls=http://pd2:2380
- --initial-cluster=pd0=http://pd0:2380,pd1=http://pd1:2380,pd2=http://pd2:2380
- --data-dir=/data/pd2
- --config=/pd.toml
- --log-file=/logs/pd2.log
tikv:
image: pingcap/tikv:latest
ports:
- target: 20160
published: 20160
environment:
- TASK_SLOT={{.Task.Slot}}
volumes:
- ./config/tikv.toml:/tikv.toml:ro
- ./data:/data
- ./logs:/logs
entrypoint: [ "/bin/sh", "-c", "/tikv-server --advertise-addr=$$HOSTNAME:20160 --addr=0.0.0.0:20160 --data-dir=/data/tikv$$TASK_SLOT --pd=pd0:2379,pd1:2379,pd2:2379 --config=/tikv.toml --log-file=/logs/tikv$$TASK_SLOT.log --log-level=info" ]
depends_on:
- "pd0"
- "pd1"
- "pd2"
deploy:
replicas: 3
restart_policy:
condition: on-failure tidb:
image: pingcap/tidb:latest
ports:
- target: 4000
published: 4000
- target: 10080
published: 10080
environment:
- TASK_SLOT={{.Task.Slot}}
volumes:
- ./config/tidb.toml:/tidb.toml:ro
- ./logs:/logs
entrypoint: [ "/bin/sh", "-c", "/tidb-server --store=tikv --path=pd0:2379,pd1:2379,pd2:2379 --config=/tidb.toml --log-file=/logs/tidb$$TASK_SLOT.log -L info" ]
depends_on:
- "tikv"
deploy:
replicas: 1 tispark-master:
image: pingcap/tispark:latest
command:
- /opt/spark/sbin/start-master.sh
volumes:
- ./config/spark-defaults.conf:/opt/spark/conf/spark-defaults.conf:ro
environment:
SPARK_MASTER_PORT: 7077
SPARK_MASTER_WEBUI_PORT: 8080
ports:
- "7077:7077"
- "8080:8080"
depends_on:
- "tikv"
deploy:
replicas: 1
tispark-slave:
image: pingcap/tispark:latest
command:
- /opt/spark/sbin/start-slave.sh
- spark://tispark-master:7077
volumes:
- ./config/spark-defaults.conf:/opt/spark/conf/spark-defaults.conf:ro
environment:
SPARK_WORKER_WEBUI_PORT: 38081
ports:
- "38081:38081"
depends_on:
- tispark-master
deploy:
replicas: 1 tidb-vision:
image: pingcap/tidb-vision:latest
environment:
PD_ENDPOINT: pd0:2379
ports:
- "8010:8010" # monitors
pushgateway:
image: prom/pushgateway:v0.3.1
command:
- --log.level=error
prometheus:
user: root
image: prom/prometheus:v2.2.1
command:
- --log.level=error
- --storage.tsdb.path=/data/prometheus
- --config.file=/etc/prometheus/prometheus.yml
ports:
- "9090:9090"
volumes:
- ./config/prometheus.yml:/etc/prometheus/prometheus.yml:ro
- ./config/pd.rules.yml:/etc/prometheus/pd.rules.yml:ro
- ./config/tikv.rules.yml:/etc/prometheus/tikv.rules.yml:ro
- ./config/tidb.rules.yml:/etc/prometheus/tidb.rules.yml:ro
- ./data:/data
grafana:
image: grafana/grafana:6.0.1
environment:
GF_LOG_LEVEL: error
GF_PATHS_PROVISIONING: /etc/grafana/provisioning
GF_PATHS_CONFIG: /etc/grafana/grafana.ini
volumes:
- ./config/grafana:/etc/grafana
- ./config/dashboards:/var/lib/grafana/dashboards
ports:
- "3000:3000"
将项目文件传入到每个服务器相同目录下
写了个脚本,首先需配置免密登录
ssh-copy-id root@xxxx
然后将下面脚本保存为init_data.sh
cd tidb_docker_compose
vi init_data.sh
#!/usr/bin/env bash
mkdir -p /xxx/data
mkdir -p /xxx/logs #这里xxx根据实际配置路径修改,这是上面docker-swarm.yml volume
scp tidb_docker_compose root@xxxx #后面的xxxx是你的服务器地址
scp tidb_docker_compose root@xxxx
scp tidb_docker_compose root@xxxx
scp tidb_docker_compose root@xxxx
然后在每个服务器上,注释掉后面的四条scp
此时init_data文件
#!/usr/bin/env bash
mkdir -p /xxx/data
mkdir -p /xxx/logs #这里xxx根据实际配置路径修改,这是上面docker-swarm.yml volume
# scp tidb_docker_compose root@xxxx #后面的xxxx是你的服务器地址
# scp tidb_docker_compose root@xxxx
# scp tidb_docker_compose root@xxxx
# scp tidb_docker_compose root@xxxx
执行
./init_data.sh
下一步可以愉快地启动集群了,也可能不愉快
cd tidb_docker_compose docker stack deploy --with-registry-auth -c docker-swarm.yml tidb
查看服务启动状态
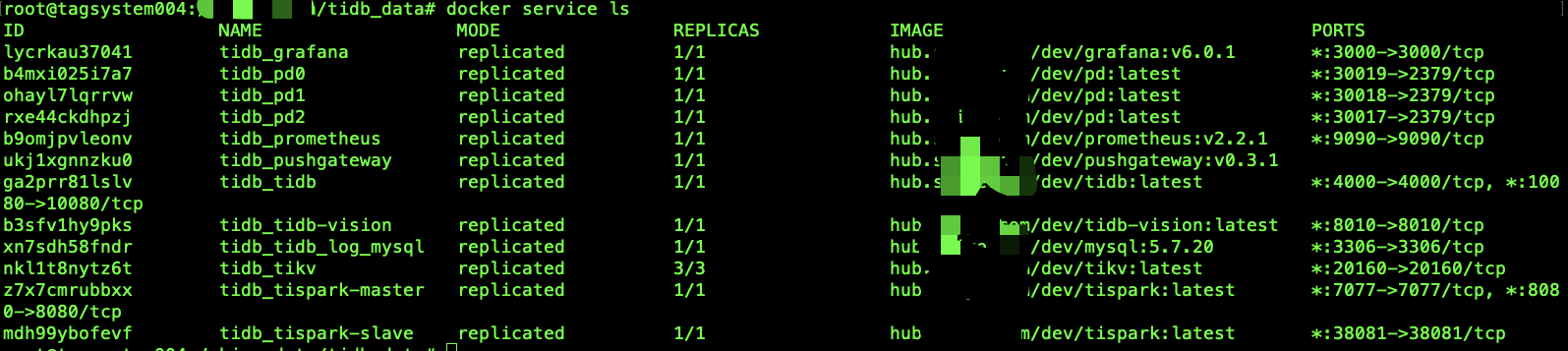
当服务启动不完全时
使用如下命令查看报错原因
# 查看服务
docker service ls # 查看服务日志 docker service ps --no-trunc 对应服务名 docker service logs 对应服务名 journalctl -u docker.service | tail -n 50
注:出现bind error 一类的,要看看每个机器上有没有这个文件夹或者文件,每个,划重点
其他错误的话,欢迎评论在博客下方。。。。我这是部署成功后才整理的文档,可能没那么细
使用tidb
mysql -u root -P 4000 -h 主节点的ip地址
之后的使用跟mysql就并无二致了,之后需要考虑问题-------高可用,数据迁移
docker swarm搭建tidb踩坑日记的更多相关文章
- Hexo搭建静态博客踩坑日记(二)
前言 Hexo搭建静态博客踩坑日记(一), 我们说到利用Hexo快速搭建静态博客. 这节我们就来说一下主题的问题与主题的基本修改操作. 起步 chrome github hexo git node.j ...
- Hexo搭建静态博客踩坑日记(一)
前言 博客折腾一次就好, 找一个适合自己的博客平台, 专注于内容进行提升. 方式一: 自己买服务器, 域名, 写前端, 后端(前后分离最折腾, 不分离还好一点)... 方式二: 利用Hexo, Hug ...
- AI相关 TensorFlow -卷积神经网络 踩坑日记之一
上次写完粗浅的BP算法 介绍 本来应该继续把 卷积神经网络算法写一下的 但是最近一直在踩 TensorFlow的坑.所以就先跳过算法介绍直接来应用场景,原谅我吧. TensorFlow 介绍 TF是g ...
- docker swarm 搭建与服务更新
一,docker swarm 是什么 Docker Swarm.Docker Machine与Docker Compose号称Docker三剑客Docker Swarm 和 Docker Compos ...
- 人工智能(AI)库TensorFlow 踩坑日记之一
上次写完粗浅的BP算法 介绍 本来应该继续把 卷积神经网络算法写一下的 但是最近一直在踩 TensorFlow的坑.所以就先跳过算法介绍直接来应用场景,原谅我吧. TensorFlow 介绍 TF是g ...
- Linux系统搭建GitLab---阿里云Centos7搭建Gitlab踩坑
一.简介 GitLab,是一个利用 Ruby on Rails 开发的开源应用程序,实现一个自托管的Git项目仓库,可通过Web界面进行访问公开的或者私人项目安装. 它拥有与GitHub类似的功能,能 ...
- hexo博客谷歌百度收录踩坑日记
title: hexo博客谷歌百度收录踩坑日记 toc: false date: 2018-04-17 00:09:38 百度收录文件验证 无论怎么把渲染关掉或者render_skip都说我的格式错误 ...
- Docker Swarm搭建多服务器下Docker集群
对于有多台服务器来讲,如果每一台都去手动操控,那将会是一件非常浪费时间的事情,毕竟时间这东西,于我们而言,十分宝贵,或许在开始搭建环境的时候耗费点时间,感觉是正常的,我也如此,花费大堆时间在采坑和填坑 ...
- docker~swarm搭建docker高可用集群
回到目录 Swarm概念 Swarm是Docker公司推出的用来管理docker集群,它将一群Docker宿主机变成一个单一的,虚拟的主机.Swarm使用标准的Docker API接口作为其前端访问入 ...
随机推荐
- python-null
很早之前,遇到过一个面试官问的python中有没有null,当时有点紧张,想成了None,就脱口而出是有的.今天遇到了none问题,所以就正好说一下. python中是没有NULL的. Python中 ...
- css中background背景属性概述
background:url(背景图片路径) no-repeat;/*不重复默认在左上方*/ background:url(背景图片路径) no-repeat center;/*不重复背景图片中间显示 ...
- php文件上传$_FILES数组格式
<form action="" enctype="multipart/form-data" method="post"> < ...
- MaxCompute 构建企业云数据仓库CDW的最佳实践建议
在本文中阿里云资深产品专家云郎分享了基于阿里云 MaxCompute 构建企业云数据仓库CDW的最佳实践建议. 本文内容根据演讲视频以及PPT整理而成. 大家下午好,我是云郎,之前在甲骨文做企业架构师 ...
- $.ajax中contentType: “application/json” 的用法
不使用contentType: “application/json”则data可以是对象 $.ajax({ url: actionurl, type: "POST", datTyp ...
- MSSQL 为db创建user
use [IBatisNet]GO if not exists (select * from master.dbo.syslogins where loginname = N'IBatisNet')B ...
- Spark day02
Standalone模式两种提交任务方式 Standalone-client提交任务方式 提交命令 ./spark-submit --master spark://node1:7077 --class ...
- 洛谷 P1119 灾后重建 最短路+Floyd算法
目录 题面 题目链接 题目描述 输入输出格式 输入格式 输出格式 输入输出样例 输入样例 输出样例 说明 思路 AC代码 总结 题面 题目链接 P1119 灾后重建 题目描述 B地区在地震过后,所有村 ...
- python中defaultdict类
回宿舍前翻翻Codeforces的时候发现了一个有趣的代码..其实是我没这么用过 :D 这是一份417B的代码 import sys from collections import defaultdi ...
- BKDRHash算法的初步了解
字符串hash最高效的算法, 搜了一下, 原理是: 字符串的字符集只有128个字符,所以把一个字符串当成128或更高进制的数字来看,当然是唯一的 这里unsigned不需要考虑溢出的问题, 不过 ...