Python Web学习笔记之多线程编程
本次给大家介绍Python的多线程编程,标题如下:
- Python多线程简介
- Python多线程之threading模块
- Python多线程之Lock线程锁
- Python多线程之Python的GIL锁
- Python多线程之ThreadLocal
- 多进程与多线程比较
- 多进程与多线程比较之执行特点
- 多进程与多线程比较之切换
- 多进程与多线程比较之计算密集型和IO密集型
Python多线程简介
一个进程由若干个线程组成,在Python标准库中,有两个模块thread和threading提供调度线程的接口。介于thread是低级模块,很多功能还不完善,我们一般只会用到threading这个比较完善的高级模块,因此这里我们只讨论threading模块的使用。
Python多线程之threading模块
要启动一个线程,我们只需要把一个函数传入Thread实例,然后调用start()运行,这个我们之前操作进程调用Process实例的方式如出一辙。

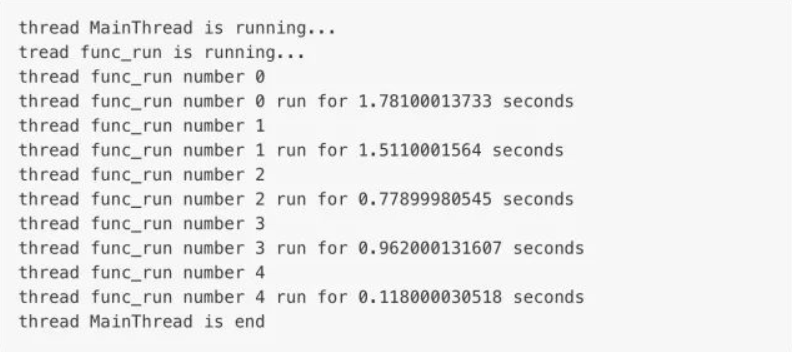
current_thread()函数用于返回当前线程的实例,主线程实例的名字为MainThread,子线程的名字可以在创建时给予,或者被默认给予Thread-1,Thread-2这样的名字。
Python多线程之Lock线程锁
多进程和多线程最大的区别就在于,对于多进程,同一个变量各自有一份拷贝存在于每个进程,互不影响,而多线程不然,所有的线程共用所有的变量,因此,任何一个变量都可以被任意的一个线程修改。为了避免多个线程同时修改同一个变量这种危险情况的出现。
首先我们需要理解,多个线程同时修改一个变量这种情况是怎么出现的。
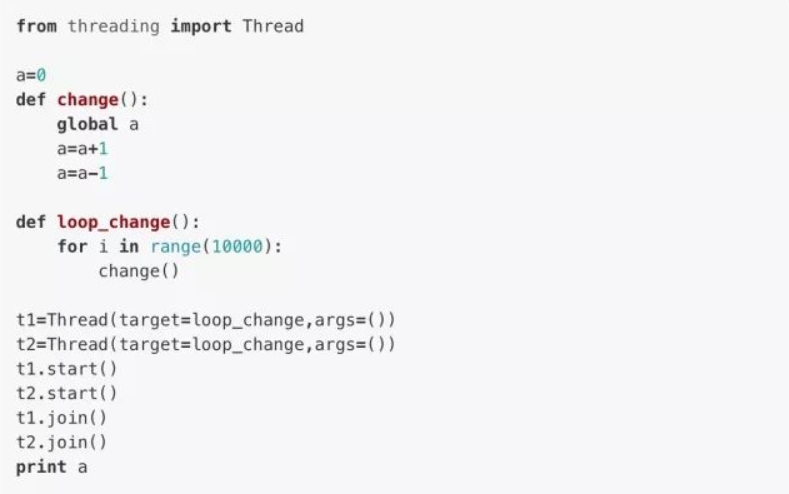

理论上来说,不论我们如何调用函数change(),共享变量a的值都应该为0,但实际上,因为两个线程t1,t2之间交替运行的次数过多,导致a的结果未必就是0了。
要理解这种情况首先要简单的了解一下CPU执行代码时的底层工作原理:
在编程语言中,一行代码在底层运行的情况未必就是作为一行来完成的,例如上面的代码a = a + 1,CPU在处理时实际上的运行方式是先用一个临时变量存储a+
1的值,再把这个临时变量的值赋给a,若是学习过arm开发,就可以理解到,CPU在工作时的情况实际上是先将值a和1分别存入两个寄存器,然后将两个寄存器的值进行加法运算并将结果存入第三个寄存器,之后再将第三个寄存器的值存入并覆盖原本保存a的值的寄存器内。用代码语言可以作如下理解:

正因此,因为两个线程都调用了各自的寄存器,或者说都有各自的临时变量c3,那么当t1和t2交替运行时,就可能出现下述代码所描述的情况:

为了避免这种情况的发生,我们就需要提供线程锁来确保:当一个线程获得了change()的调用权时,另一个线程就不能在同时执行change()方法,直到锁被释放之后,获得了该锁才能继续进行修改。
我们用threading.lock()方法创建一个线程锁
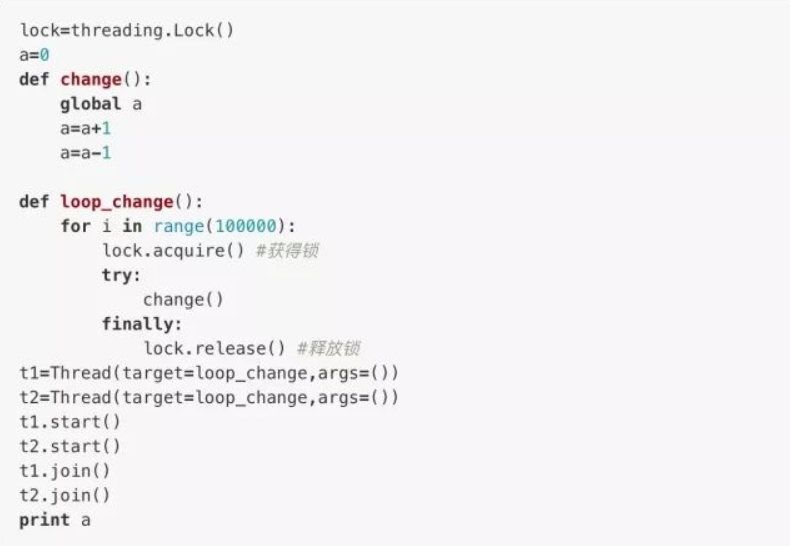

这样子,无论如何运行,结果都将是我们预期的0。
当多个线程同时执行lock.acquire()时,只有一个线程能够成功地获得线程锁,然后继续执行代码,其它线程只能等待锁的释放。同时获得锁的线程一定要记得释放,否则会成为死线程。因此我们会用try...finally...来确保锁的释放。然而,锁的问题就是一方面让原本多线程的任务实际上又变成了单线程的运行方式(尽管对于Python的伪多线程而言,这并不会造成什么性能的下降),另外,又由于可以存在多个锁,对于不同的线程可能会持有不同的锁并且试图获取对方的锁时,可能会造成死锁,导致多个线程全部挂起,这时只能通过操作系统来强行终止。
Python多线程之Python的GIL锁
对于一个多核CPU,它可以同时执行多个线程。我们可以通过Windows提供的任务管理器看见CPU的资源占用率,因此,当我们提供一个无限循环的死线程时,CPU一核的占用率就会提升到100%,若是提供两个,就又会有一核的占用率到100%。如果在java或者C中这么做,那么确实会发生这种情况,但是,如果我们在Python中这样尝试的话


可以看到,从 multiprocessing.cpu_count()得知我们有4个CPU,然后打印了4行说明已经执行了4个线程,这个时候我们的CPU占用率应该是满的,但实际上
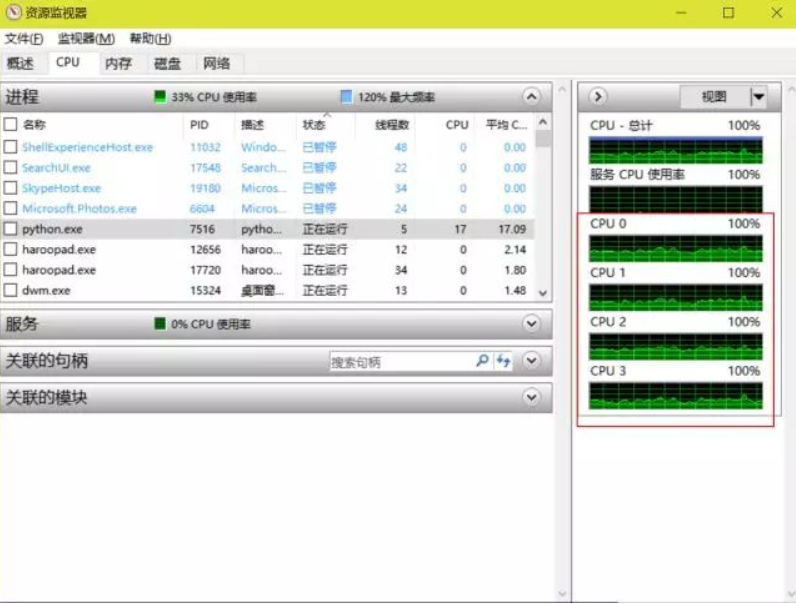
我们从红框中看到,情况并非如此。实际上哪怕我们启用再多的线程,CPU的占用率也不会提高多少。这是因为尽管Python使用的是真正的线程,但Python的解释器在执行代码时有一个GIL锁(Gloabal Interpreter Lock),不论是什么Python代码,一旦执行必然会获得GIL锁,然后每执行100行代码就会释放GIL锁使得其它线程有机会执行。GIL锁实际上就给一个Python进程的所有线程都上了锁,因此哪怕是再多的线程,在一个Python进程中也只能交替执行,也即是只能使用一个核。
Python多线程之ThreadLocal
既然我们已经知道,一个全局变量会受到所有线程的影响,那么,我们应该如何构建一个独属于这个线程的“全局变量”?换言之,我们既希望这个变量在这个线程中拥有类似于全局变量的功能,又不希望其它线程能够调用它,以防止出现上面所述的问题,该怎么做?

可以看到,在这个子线程中,如果我们希望函数do_task1()和do_task2()能用到变量a,则必须将它作为参数传进去。
使用ThreadLocal对象便是用于解决这个问题的方法而免于繁琐的操作,它由threading.local()方法创建:


我们可以认为ThreadLocal的原理类似于创建了一个词典,当我们创建一个变量local_varient.a的时候实际上是在local_varient这个词典里面创建了数个以threading.current_thread()为关键字(当前线程),不同线程中的a为值的键值对组成的dict,可以参照下面这个例程:

结果与上面用ThreadLocal的例程是一样的。当然,我在这里只是试图简单的描述一下ThreadLocal的工作原理,因为实际上它的工作原理和我们上面利用dict的例程并不是完全一样的,因为ThreadLocal对象可供传给的变量完全不只一个:

甚至local_varient.c、local_varient.d…都可以,没有一定的数量限制。而dict中能用threading.current_thread()做关键字的键值对都只能有一个不是吗。
进程和线程的比较
在初步了解进程和线程以及它们在Python中的运用方式之后,我们现在来讨论一下二者的区别与利弊。
多进程与多线程比较之执行特点
首先,我们简单了解一下多任务的工作模式:通常我们会将其设计为Master-Worker 模式,Master负责分配任务,Worker负责执行任务,多任务环境下通常是一个Master对应多个Worker。
那么多进程任务实现Master-Worker,主进程就是Master,其它进程是Worker。而多线程任务,主线程Master,子线程Worker。
先来说说多进程,多进程的优点就在于,它的稳定性高。因为一个子进程的崩溃不会影响到其它子进程和主进程(主进程挂了还是会全崩的)。但多进程的问题就在于,其创建进程的开销过大,特别是Windows系统,其多进程的开销要比使用fork()的Unix/Linux系统大的多得多。并且,对于一个操作系统本身而言,它能够同时运行的进程数也是有限的。
多线程模式占用的资源消耗没有多进程那么大,因此它也往往会更快一些(但似乎也不会快太多?但至少在Windows下多线程的效率往往要比多进程要高),而且,多线程模式与多进程模式正好相反,一个线程挂掉会直接让进程内包括主线程的所有的线程都崩溃,因为所有线程共享进程的内存。在Windows系统中,如果我们看到了这样的提示“该程序执行了非法操作,即将关闭”,那往往就是因为某个线程出现问题导致整个进程的崩溃。
多进程与多线程比较之切换
在使用多进程或多线程的时候都应该考虑线程数或者进程数切换的开销。无论是进程还是线程,如果数量太多,那么效率是肯定上不去的。
因为操作系统在切换进程和线程时,需要先保存当前执行的现场环境(包括CPU寄存器的状态,内存页等),然后再准备另一个任务的执行环境(恢复上次的寄存器状态,切换内存页等),才能开始执行新任务。这个过程虽然很快,但再快也是需要耗时的,因此一旦任务数量过于庞大,那么浪费在准备环境的时间就也会非常巨大。
多进程与多线程比较之计算密集型和IO密集型
考虑多任务的类型也是我们判断如何构建工作模式的一个重要点。我们可以将任务简单的分为两类:计算密集型和IO密集型。
计算密集型任务的特点是要进行大量的运算,消耗CPU资源,例如一些复杂的数学运算,或者是一些视频的高清解码运算等等,纯靠CPU的计算能力来执行的任务。这种任务虽然也可以用多任务模式来完成,但任务之间切换的消耗往往比较大,因此若是要高效的进行这类任务的运算,计算密集型任务同时进行的数量最好不要超过CPU的核心数。
而对于语言而言,代码运行的效率对于计算密集型任务也是至关重要,因此,类似于Python这样的高级语言往往不适合,而像C这样的底层语言的效率就会更高。好在Python处理这类任务时用的往往是用C编写的库,但若是要自己实现这类任务的底层计算功能,还是以C为主比较好。
IO密集型的特点则是要进行大量的输入输出,涉及到网络、磁盘IO的任务往往都是IO密集型任务,这类任务消耗CPU的资源并不高,往往时间都是花在等待IO操作完成,因为IO操作的速度往往都比CPU和内存运行的速度要慢很多。对于IO密集型任务,多任务执行提升的效率就会很高,但当然,任务数量还是有一个限度的。
而对于这类任务使用的编程语言,Python这类开发效率高的语言就会更适合,因为能减少代码量,而C语言效果就很差,因为写起来很麻烦。
现代操作系统对IO操作进行了巨大的改进,其提供了异步IO的操作来实现单进程单线程执行多任务的方式,它在单核CPU上采用单进程模型可以高效地支持多任务。而在多核CPU上也可以运行多个进程(数量与CPU核心数相同)来充分地利用多核CPU。通过异步IO编程模型来实现多任务是目前的主流趋势。而在Python中,单进程的异步编程模型称为协程。
Python Web学习笔记之多线程编程的更多相关文章
- Python Web学习笔记之并发编程IO模型
了解新知识之前需要知道的一些知识 同步(synchronous):一个进程在执行某个任务时,另外一个进程必须等待其执行完毕,才能继续执行 #所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调 ...
- Python Web学习笔记之socket编程
Python 提供了两个基本的 socket 模块. 第一个是 Socket,它提供了标准的 BSD Sockets API. 第二个是 SocketServer, 它提供了服务器中心类,可以简化网络 ...
- Python Web学习笔记之并发编程的孤儿进程与僵尸进程
1.前言 之前在看<unix环境高级编程>第八章进程时候,提到孤儿进程和僵尸进程,一直对这两个概念比较模糊.今天被人问到什么是孤儿进程和僵尸进程,会带来什么问题,怎么解决,我只停留在概念上 ...
- 孙鑫VC学习笔记:多线程编程
孙鑫VC学习笔记:多线程编程 SkySeraph Dec 11st 2010 HQU Email:zgzhaobo@gmail.com QQ:452728574 Latest Modified ...
- Python Web学习笔记之GIL机制下的鸡肋多线程
为什么有人会说 Python 多线程是鸡肋?知乎上有人提出这样一个问题,在我们常识中,多进程.多线程都是通过并发的方式充分利用硬件资源提高程序的运行效率,怎么在 Python 中反而成了鸡肋? 有同学 ...
- Python Web学习笔记之Python多线程和多进程、协程入门
进程和线程究竟是什么?如何使用进程和线程?什么场景下需要使用进程和线程?协程又是什么?协程和线程的关系和区别有哪些? 程序切换-CPU时间的分配 首先,我们的任何一个程序都需要运行在一个操作系统中,如 ...
- Python Web学习笔记之Python多线程基础
多线程理解 多线程是多个任务同时运行的一种方式.比如一个循环中,每个循环看做一个任务,我们希望第一次循环运行还没结束时,就可以开始第二次循环,用这种方式来节省时间. python中这种同时运行的目的是 ...
- Python Web学习笔记之TCP/IP、Http、Socket的区别
经常在笔试.面试或者工作的时候听到这些协议,虽然以前没怎么涉及过,但至少知道这些是和网络编程密不可分的知识,作为一个客户端开发程序员,如果可以懂得网络编程的话,他的作用和能力肯定会提升一个档次.原因很 ...
- Python Web学习笔记之CPU时间片
时间片即CPU分配给各个程序的时间,每个线程被分配一个时间段,称作它的时间片,即该进程允许运行的时间,使各个程序从表面上看是同时进行的.如果在时 间片结束时进程还在运行,则CPU将被剥夺并分配给另一个 ...
随机推荐
- 安装coreseek与sphinx遇见的问题
1.问题 using config file 'etc/csft.conf'...indexing index 'xml'...WARNING: source 'xml': xmlpipe2 supp ...
- Java中为什么需要反射?反射要解决什么问题?
一句话概括就是使用反射可以赋予jvm动态编译的能力,否则类的元数据信息只能用静态编译的方式实现,例如热加载,Tomcat的classloader等等都没法支持 Java中编译类型有两种: 静态编译:在 ...
- uid列表来讲讲我是如何利用php数组进行排重的
经常接到要对网站的会员进行站内信.手机短信.email进行群发信息的通知,用户列表一般由别的同事提供,当中难免会有重复,为了避免重复发送,所以我在进行发送信息前要对他们提供的用户列表进行排重. 假如得 ...
- Python之logging日志模块
logging 用于便捷既然日志切线程安全的模块 vim log_test.py import logging logging.basicConfig(filename='log.log', form ...
- Oracle管理监控之rlwrap-0.37.tar.gz实现sqlplus上下翻页
1.上传rlwrap-0.37.tar.gz到linux 2.解压rlwrap-0.37.tar.gz [root@node1 mnt]# tar zxvf rlwrap-0.37.tar.gz [r ...
- js之操作cookie
js通过document.cookie获取所有的cookie信息, cookie在存储的格式是键值对,key=value每个键值对之间用; (分号和空格隔开). 添加cookie和修改cookie的值 ...
- 【Python-虫师】自动化测试模型--参数化
一.自动化测试代码最开始是线性的,后续发展为模块化代码,所以涉及到了函数和方法的引用. 1. 函数和方法的最主要区别: Python的方法中定义函数的时候,函数中必须写self.而单独定义函数的时候则 ...
- 通过反射,获取linkedHashMap的最后一个键值对。对map按照值进行排序。
1:通过反射,获取linkedHashMap的最后一个键值对. Map<Integer, Integer> map = new LinkedHashMap<>(); Field ...
- 使用对象作为hashMap的键,需要覆盖hashcode和equals方法
1:HashMap可以存放键值对,如果要以对象(自己创建的类等)作为键,实际上是以对象的散列值(以hashCode方法计算得到)作为键.hashCode计算的hash值默认是对象的地址值. 这样就会忽 ...
- [py]python自省工具
参考 在日常生活中,自省(introspection)是一种自我检查行为.自省是指对某人自身思想.情绪.动机和行为的检查.伟大的哲学家苏格拉底将生命中的大部分时间用于自我检查,并鼓励他的雅典朋友们也这 ...