第三百三十七节,web爬虫讲解2—PhantomJS虚拟浏览器+selenium模块操作PhantomJS
第三百三十七节,web爬虫讲解2—PhantomJS虚拟浏览器+selenium模块操作PhantomJS
PhantomJS虚拟浏览器
phantomjs 是一个基于js的webkit内核无头浏览器 也就是没有显示界面的浏览器,利用这个软件,可以获取到网址js加载的任何信息,也就是可以获取浏览器异步加载的信息
下载网址:http://phantomjs.org/download.html 下载对应系统版本
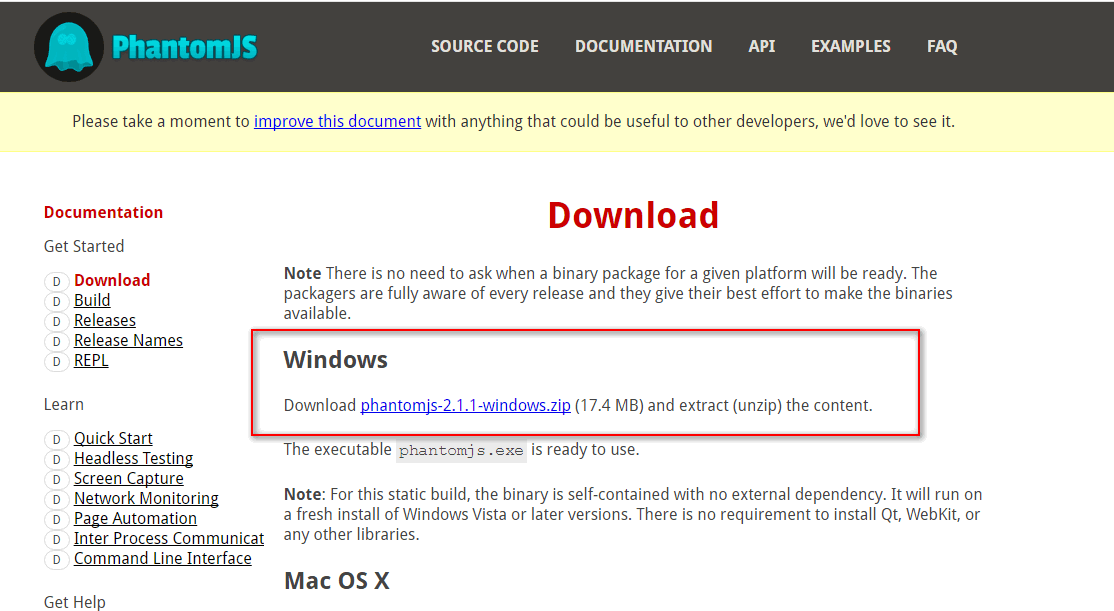
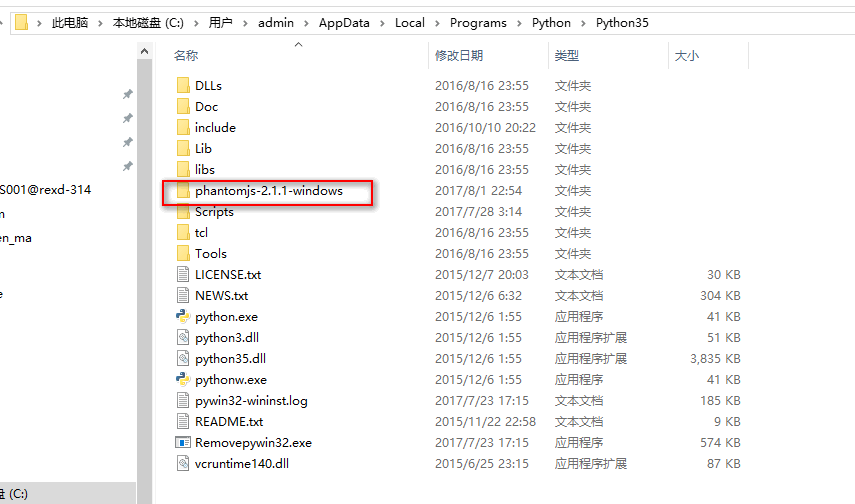
下载后解压PhantomJS文件,将解压文件夹,剪切到python安装文件夹
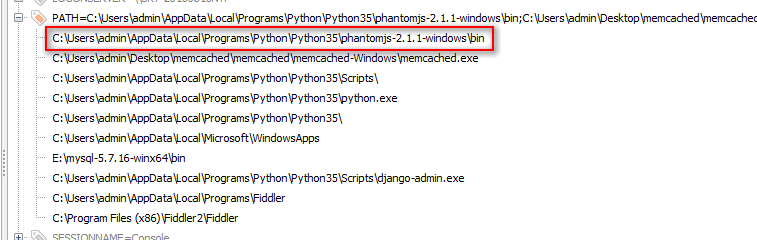
然后将PhantomJS文件夹里的bin文件夹添加系统环境变量
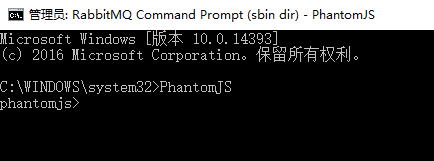
cdm 输入命令:PhantomJS 出现以下信息说明安装成功
selenium模块是一个python操作PhantomJS软件的一个模块
selenium模块PhantomJS软件
webdriver.PhantomJS()实例化PhantomJS浏览器对象
get('url')访问网站
find_element_by_xpath('xpath表达式')通过xpath表达式找对应元素
clear()清空输入框里的内容
send_keys('内容')将内容写入输入框
click()点击事件
get_screenshot_as_file('截图保存路径名称')将网页截图,保存到此目录
page_source获取网页htnl源码
quit()关闭PhantomJS浏览器
#!/usr/bin/env python
# -*- coding:utf8 -*-
from selenium import webdriver #导入selenium模块来操作PhantomJS
import os
import time
import re llqdx = webdriver.PhantomJS() #实例化PhantomJS浏览器对象
llqdx.get("https://www.baidu.com/") #访问网址 # time.sleep(3) #等待3秒
# llqdx.get_screenshot_as_file('H:/py/17/img/123.jpg') #将网页截图保存到此目录 #模拟用户操作
llqdx.find_element_by_xpath('//*[@id="kw"]').clear() #通过xpath表达式找到输入框,clear()清空输入框里的内容
llqdx.find_element_by_xpath('//*[@id="kw"]').send_keys('叫卖录音网') #通过xpath表达式找到输入框,send_keys()将内容写入输入框
llqdx.find_element_by_xpath('//*[@id="su"]').click() #通过xpath表达式找到搜索按钮,click()点击事件 time.sleep(3) #等待3秒
llqdx.get_screenshot_as_file('H:/py/17/img/123.jpg') #将网页截图,保存到此目录 neir = llqdx.page_source #获取网页内容
print(neir)
llqdx.quit() #关闭浏览器 pat = "<title>(.*?)</title>"
title = re.compile(pat).findall(neir) #正则匹配网页标题
print(title)
PhantomJS浏览器伪装,和滚动滚动条加载数据
有些网站是动态加载数据的,需要滚动条滚动加载数据
实现代码
DesiredCapabilities 伪装浏览器对象
execute_script()执行js代码
current_url获取当前的url
#!/usr/bin/env python
# -*- coding:utf8 -*-
from selenium import webdriver #导入selenium模块来操作PhantomJS
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities #导入浏览器伪装模块
import os
import time
import re dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap['phantomjs.page.settings.userAgent'] = ('Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0')
print(dcap)
llqdx = webdriver.PhantomJS(desired_capabilities=dcap) #实例化PhantomJS浏览器对象 llqdx.get("https://www.jd.com/") #访问网址 #模拟用户操作
for j in range(20):
js3 = 'window.scrollTo('+str(j*1280)+','+str((j+1)*1280)+')'
llqdx.execute_script(js3) #执行js语言滚动滚动条
time.sleep(1) llqdx.get_screenshot_as_file('H:/py/17/img/123.jpg') #将网页截图,保存到此目录 url = llqdx.current_url
print(url) neir = llqdx.page_source #获取网页内容
print(neir)
llqdx.quit() #关闭浏览器 pat = "<title>(.*?)</title>"
title = re.compile(pat).findall(neir) #正则匹配网页标题
print(title)
第三百三十七节,web爬虫讲解2—PhantomJS虚拟浏览器+selenium模块操作PhantomJS的更多相关文章
- 十六 web爬虫讲解2—PhantomJS虚拟浏览器+selenium模块操作PhantomJS
PhantomJS虚拟浏览器 phantomjs 是一个基于js的webkit内核无头浏览器 也就是没有显示界面的浏览器,利用这个软件,可以获取到网址js加载的任何信息,也就是可以获取浏览器异步加载的 ...
- 第三百二十七节,web爬虫讲解2—urllib库爬虫—基础使用—超时设置—自动模拟http请求
第三百二十七节,web爬虫讲解2—urllib库爬虫 利用python系统自带的urllib库写简单爬虫 urlopen()获取一个URL的html源码read()读出html源码内容decode(& ...
- 第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中 前面我们讲到的elasticsearch( ...
- 第三百五十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
第三百五十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码 scrapy-redis是一个可以scrapy结合redis搭建分布式爬虫的开 ...
- 第三百九十七节,Django+Xadmin打造上线标准的在线教育平台—其他插件使用说,主题本地化设置
第三百九十七节,Django+Xadmin打造上线标准的在线教育平台—其他插件使用说,主题本地化设置 主题设置是在xadmin\plugins\themes.py这个文件 默认xadmin是通过下面这 ...
- 第三百八十七节,Django+Xadmin打造上线标准的在线教育平台—网站上传资源的配置与显示
第三百八十七节,Django+Xadmin打造上线标准的在线教育平台—网站上传资源的配置与显示 首先了解一下static静态文件与上传资源的区别,static静态文件里面一般防止的我们网站样式的文件, ...
- 第三百七十七节,Django+Xadmin打造上线标准的在线教育平台—apps目录建立,以及数据表生成
第三百七十七节,Django+Xadmin打造上线标准的在线教育平台—apps目录建立,以及数据表生成 apps目录建立 我们创建一个apps目录,将所有的app放到apps目录里去,这样方便管理,也 ...
- 第三百二十二节,web爬虫,requests请求
第三百二十二节,web爬虫,requests请求 requests请求,就是用yhthon的requests模块模拟浏览器请求,返回html源码 模拟浏览器请求有两种,一种是不需要用户登录或者验证的请 ...
- 第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础 在urllib中,我们一样可以使用xpath表达式进行信息提取,此时,你需要首先安装lxml模块 ...
随机推荐
- 6 Multi-Cloud Architecture Designs for an Effective Cloud
https://www.simform.com/multi-cloud-architecture/ Enterprises increasingly want to take advantage of ...
- 【Java】Java复习笔记-第二部分
类和对象 类:主观抽象,是对象的模板,可以实例化对象 习惯上类的定义格式: package xxx; import xxx; public class Xxxx { 属性 ······; 构造器 ·· ...
- Docker考前突击
dockerfile 介绍 镜像(Image) 容器(Container) 仓库(Repository)
- postgre与mysql区别
SQL兼容性 PostgreSQL 9.5 兼容 SQL:2011 子集 http://www.postgresql.org/docs/9.5/static/features-sql-standard ...
- Flask简介,安装,demo,快速入门
1.Flask简介 Flask是一个相对于Django而言轻量级的Web框架. 和Django大包大揽不同,Flask建立于一系列的开源软件包之上,这其中 最主要的是WSGI应用开发库Werkzeug ...
- hashCode()方法与equals()方法的说明
1,一般我们自己用时,只使用equals()方法,用于判断两个对象是否是业务上等价的.2,在重写equals()方法时,强烈推荐也要重写hashCode()方法,因为有的集合用到了hashCode() ...
- Memory Models And Namespaces
分开编译 不要把变量和函数的定义放到头文件中. 可以分开编译源文件,然后将它们连接起来生成最终的可执行文件. 如果你只修改了一个文件,你可以只重新编译这个文件,之前编译过的其他文件就不需要再次编译了, ...
- Mac OS下 Redis2.6.14部署记录
Mac OS下 Redis2.6.14部署记录 部署一个Redis作为缓存进行验证,记录部署过程. 官网:http://redis.io/,目前最近稳定版为2.6.14 解压,进入目录.按照READ ...
- VS2013安装MVC5
打开VS 选择 .net 4.5 创建项目 右击项目 选择管理NuGet 输入Microsoft.AspNet.Mvc -Version 5.0.0 安装最新版本的MVC5
- JS事件对象,筋斗云导航练习,跟随鼠标练习,放大镜练习,进度条练习
JS事件对象,筋斗云导航练习,跟随鼠标练习,放大镜练习,进度条练习 btn.onclick = function(event) { 语句 } 其中event就是事件对象,在这个方法中指向的对象是onc ...