ELK收集mysql_slow.log
关于慢查询的收集及处理也耗费了我们太多的时间和精力,如何在这一块也能提升效率呢?且看本文讲解如何利用ELK做慢日志收集。
ELK 介绍
ELK 最早是 Elasticsearch(以下简称ES)、Logstash、Kibana 三款开源软件的简称,三款软件后来被同一公司收购,并加入了Xpark、Beats等组件,改名为Elastic Stack,成为现在最流行的开源日志解决方案,虽然有了新名字但大家依然喜欢叫她ELK,现在所说的ELK就指的是基于这些开源软件构建的日志系统。
我们收集mysql慢日志的方案如下:
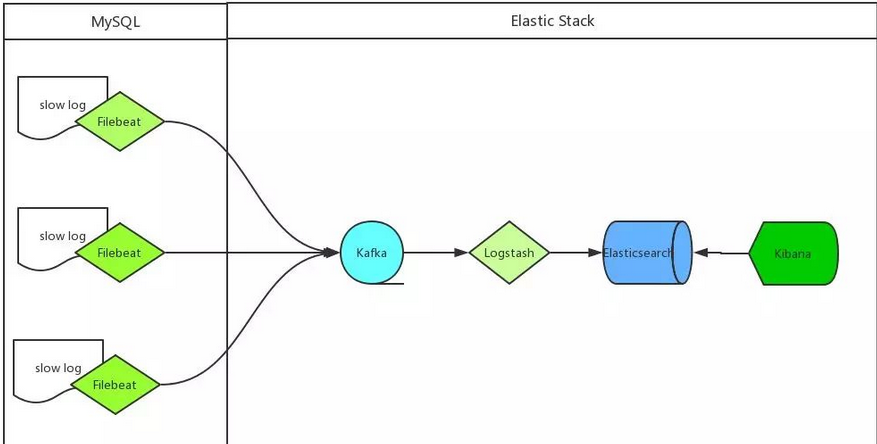
mysql 服务器安装 Filebeat 作为 agent 收集 slowLog
Filebeat 读取 mysql 慢日志文件做简单过滤传给 Kafka 集群
Logstash 读取 Kafka 集群数据并按字段拆分后转成 JSON 格式存入 ES 集群
Kibana读取ES集群数据展示到web页面上
慢日志分类
目前主要使用的mysql版本有5.5、5.6 和 5.7,经过仔细对比发现每个版本的慢查询日志都稍有不同,如下:
5.5 版本慢查询日志

5.6 版本慢查询日志

5.7 版本慢查询日志

慢查询日志异同点:
每个版本的Time字段格式都不一样
相较于5.6、5.7版本,5.5版本少了Id字段
use db语句不是每条慢日志都有的
可能会出现像下边这样的情况,慢查询块# Time:下可能跟了多个慢查询语句
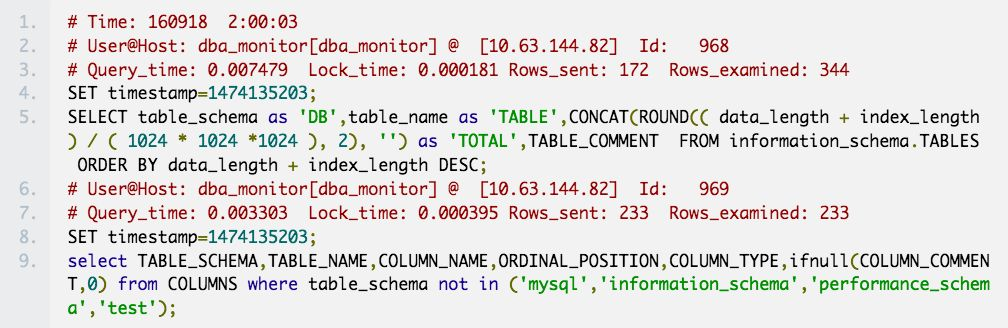
处理思路
上边我们已经分析了各个版本慢查询语句的构成,接下来我们就要开始收集这些数据了,究竟应该怎么收集呢?
拼装日志行:mysql 的慢查询日志多行构成了一条完整的日志,日志收集时要把这些行拼装成一条日志传输与存储。
Time行处理:# Time: 开头的行可能不存在,且我们可以通过SET timestamp这个值来确定SQL执行时间,所以选择过滤丢弃Time行
一条完整的日志:最终将以# User@Host: 开始的行,和以SQL语句结尾的行合并为一条完整的慢日志语句
确定SQL对应的DB:use db这一行不是所有慢日志SQL都存在的,所以不能通过这个来确定SQL对应的DB,慢日志中也没有字段记录DB,所以这里建议为DB创建账号时添加db name标识,例如我们的账号命名方式为:projectName_dbName,这样看到账号名就知道是哪个DB了
确定SQL对应的主机:我想通过日志知道这条SQL对应的是哪台数据库服务器怎么办?
慢日志中同样没有字段记录主机,可以通过filebeat注入字段来解决,例如我们给filebeat的name字段设置为服务器IP,这样最终通过beat.name这个字段就可以确定SQL对应的主机了。
Filebeat配置
filebeat 完整的配置文件如下:
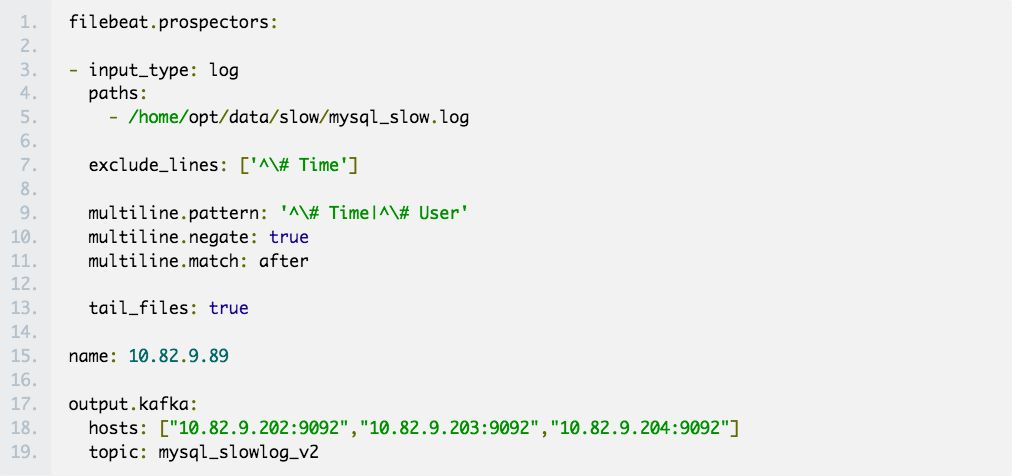
重要参数解释:
input_type:指定输入的类型是log或者是stdin
paths:慢日志路径,支持正则,比如/data/*.log
exclude_lines:过滤掉# Time开头的行
multiline.pattern:匹配多行时指定正则表达式,这里匹配以# Time或者# User开头的行,Time行要先匹配再过滤
multiline.negate:定义上边pattern匹配到的行是否用于多行合并,也就是定义是不是作为日志的一部分
multiline.match:定义如何将皮排行组合成时间,在之前或者之后
tail_files:定义是从文件开头读取日志还是结尾,这里定义为true,从现在开始收集,之前已存在的不管
name:设置filebeat的名字,如果为空则为服务器的主机名,这里我们定义为服务器IP
output.kafka:配置要接收日志的kafka集群地址可topic名称
Kafka 接收到的日志格式:
{"@timestamp":"2018-08-07T09:36:00.140Z","beat":{"hostname":"db-7eb166d3","name":"10.63.144.71","version":"5.4.0"},"input_type":"log","message":"# User@Host: select[select] @ [10.63.144.16] Id: 23460596\n# Query_time: 0.155956 Lock_time: 0.000079 Rows_sent: 112 Rows_examined: 366458\nSET timestamp=1533634557;\nSELECT DISTINCT(uid) FROM common_member WHERE hideforum=-1 AND uid != 0;","offset":1753219021,"source":"/data/slow/mysql_slow.log","type":"log"}
Logstash配置
logstash完整的配置文件如下:

重要参数解释:
input:配置 kafka 的集群地址和 topic 名字
filter:过滤日志文件,主要是对 message 信息(看前文 kafka 接收到的日志格式)进行拆分,拆分成一个一个易读的字段,例如User、Host、Query_time、Lock_time、timestamp等。
grok段根据我们前文对mysql慢日志的分类分别写不通的正则表达式去匹配,当有多条正则表达式存在时,logstash会从上到下依次匹配,匹配到一条后边的则不再匹配。
date字段定义了让SQL中的timestamp_mysql字段作为这条日志的时间字段,kibana上看到的实践排序的数据依赖的就是这个时间
output:配置ES服务器集群的地址和index,index自动按天分割
kibana查询展示
打开Kibana添加 mysql-slowlog-* 的Index,并选择timestamp,创建Index Pattern
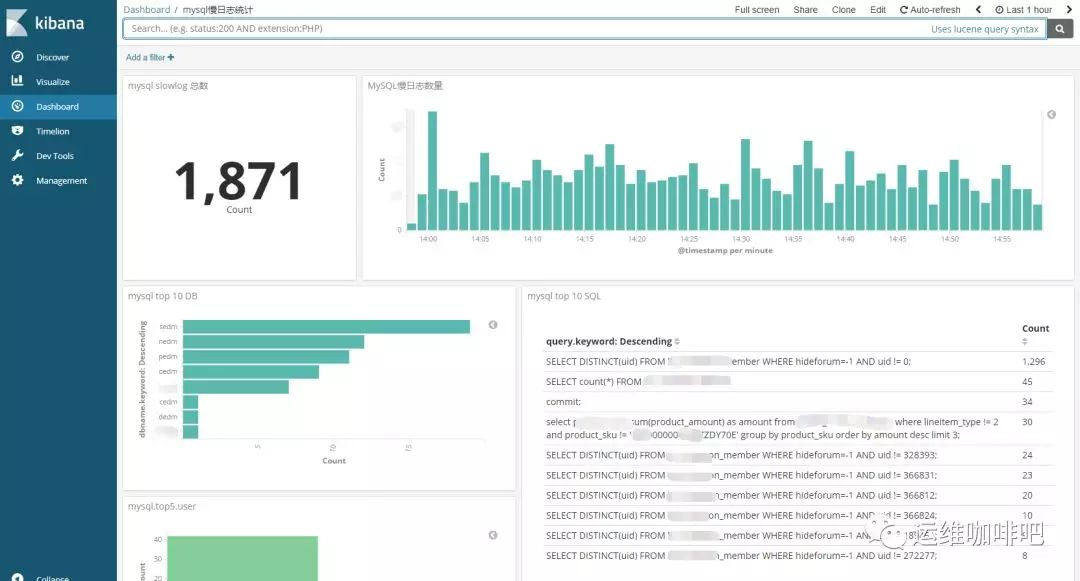
进入Discover页面,可以很直观的看到各个时间点慢日志的数量变化,可以根据左侧Field实现简单过滤,搜索框也方便搜索慢日志,例如我要找查询时间大于2s的慢日志,直接在搜索框输入 query_time: > 2 回车即可。
点击每一条日志起边的很色箭头能查看具体某一条日志的详情。
如果你想做个大盘统计慢日志的整体情况,例如top 10 SQL等,也可以很方便的通过web界面配置。
文章转自:https://mp.weixin.qq.com/s/NQuxPt0Gm_Z1FVNwLVA48g
ELK收集mysql_slow.log的更多相关文章
- elk收集分析nginx access日志
elk收集分析nginx access日志 首先elk的搭建按照这篇文章使用elk+redis搭建nginx日志分析平台说的,使用redis的push和pop做队列,然后有个logstash_inde ...
- ELK收集Nginx自定义日志格式输出
1.ELK收集日志的有两种常用的方式: 1.1:不修改源日志格式,简单的说就是在logstash中转通过 grok方式进行过滤处理,将原始无规则的日志转换为规则日志(Logstash自定义日志格式) ...
- ELK收集Nginx|Tomcat日志
1.Nginx 日志收集,先安装Nginx cd /usr/local/logstash/config/etc/,创建如下配置文件,代码如下 Nginx.conf input { file { typ ...
- K8S(15)监控实战-ELK收集K8S内应用日志
K8S监控实战-ELK收集K8S内应用日志 目录 K8S监控实战-ELK收集K8S内应用日志 1 收集K8S日志方案 1.1 传统ELk模型缺点: 1.2 K8s容器日志收集模型 2 制作tomcat ...
- ELK 收集 Tomcat日志以及修改Tomcat日志格式
ELK 收集 Tomcat日志以及修改Tomcat日志格式 Tomcat日志 想要收集tomcat 日志 首先我们要对tomcat的日志有足够的了解 tomca日志分类 简单的说tomcat logs ...
- elk收集tomcat日志
1.elk收集tomcat普通日志: 只在logstash节点增加如下文件,重启logstash即可: cat >>/home/logstash-6.3.0/config/tomcat_t ...
- ELK收集日志到mysql
场景需求 在使用ELK对日志进行收集的时候,如果需要对数据进行存档,可以考虑使用数据库的方式.为了便于查询,可以同时写一份数据到Elasticsearch 中. 环境准备 CentOS7系统: 192 ...
- ELK收集tomcat访问日志并存取mysql数据库案例
这个案例中,tomcat产生的日志由filebeat收集,然后存取到redis中,再由logstash进行过滤清洗等操作,最后由elasticsearch存储索引并由kibana进行展示. 1.配置t ...
- 带你了解zabbix整合ELK收集系统异常日志触发告警~
今天来了解一下关于ELK的“L”-Logstash,没错,就是这个神奇小组件,我们都知道,它是ELK不可缺少的组件,完成了输入(input),过滤(fileter),output(输出)工作量,也是我 ...
随机推荐
- MySQL登陆小问题
root用户创建用户 CREATE USER gechong IDENTIFIED BY 'gechong'; 登录数据库时提示错误: C:\Users\gechong>mysql -u gec ...
- 写出3个使用this的典型应用
(1).在html元素事件属性中使用,如: <input type=”button” onclick=”showInfo(this);” value=”点击一下” /> (2).构造函数 ...
- MariaDB的存储过程和函数
创建存储过程 DELIMITER $$ DROP PROCEDURE IF EXISTS `sp_test1`; CREATE PROCEDURE sp_test1(IN a int, IN b in ...
- 事件响应的优先级、stopProgapation禁止下层组件响应
cocos2d-js没有完整的鼠标事件处理,这点比js/flash的要差一些,不过凑合着也可以用了. 一般界面编程,可以用显示列表的Node作为监听器的优先级,在上方的会比下方的高优先级. 而coco ...
- Spring Cloud开发实践 - 01 - 简介和根模块
简介 使用Spring Boot的提升主要在于jar的打包形式给运维带来了很大的便利, 而Spring Cloud本身的优点不是那么明显, 相对于Dubbo而言, 可能体现在跨语言的交互性上(例如可以 ...
- Android从无知到有知——NO.3
昨天看了下几种常见的布局,类似于曾经学的html.关于css+div没有接触太多,但这几种布局都比較简单.仅仅要逻辑没有太大问题就能整出来. 相对布局是我们平时默认的布局,也是最经常使用的.前边做的& ...
- (原)torch,caffe,python中读入数据的默认范围
转载请注明出处: http://www.cnblogs.com/darkknightzh/p/6554388.html 之前torch(image.load).caffe(默认的).python(使用 ...
- socket.io简介
websocket是一种比较简单的协议,各种语言中都有很多实现版本,实际上它们差别不大,都是在websocket的基础上做些封装,随便选一个即可. socket.io就是众多websocket库中的一 ...
- 【转】IOCP创建
转自:http://www.cmnsoft.com/wordpress/?p=248 感谢原作者.我在此整理一下: 完成端口(IOCP)是WINDOWS平台上特有的一种技术.要使用IOCP技术,就要用 ...
- 深入解读键值产生原理,linux中的软链接和硬链接(转)
键值 = 文件标示符 + 项目ID 当用到进程间的通信时, 必须要注意到的是键值是怎么产生的,我们知道任何一个文件时通过文件名来访问的, 而内核在对应的给其一个值,也就是文件标示符. 系统建立IPC通 ...