使用scrapy-redis构建简单的分布式爬虫
前言
scrapy是python界出名的一个爬虫框架。Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
虽然scrapy能做的事情很多,但是要做到大规模的分布式应用则捉襟见肘。有能人改变了scrapy的队列调度,将起始的网址从start_urls里分离出来,改为从redis读取,多个客户端可以同时读取同一个redis,从而实现了分布式的爬虫。就算在同一台电脑上,也可以多进程的运行爬虫,在大规模抓取的过程中非常有效。
准备
既然这么好能实现分布式爬取,那都需要准备什么呢?
需要准备的东西比较多,都有:
- scrapy
- scrapy-redis
- redis
- mysql
- python的mysqldb模块
- python的redis模块
为什么要有mysql呢?是因为我们打算把收集来的数据存放到mysql中
1. scrapy安装
pip install scrapy
- 1
- 2
也可以clone下相应的github地址https://github.com/scrapy/scrapy/tree/1.1
2. scrapy-redis安装
pip install scrapy-redis
- 1
- 2
同样可以clone下相应的github地址https://github.com/rolando/scrapy-redis
他俩具体有什么区别呢?https://www.zhihu.com/question/32302268/answer/55724369有知乎大神的回答
3.redis
redis本身只提供了在类linux环境中安装,不支持windows,官网http://redis.io/,如果需要在windows下做练习的朋友,可以参考我的这篇http://blog.csdn.net/howtogetout/article/details/51520254
4.mysql
因为我们打算用mysql来存储数据,所以mysql的配置是不可或缺的。下载地址http://dev.mysql.com/downloads/
5.mysqldb模块和redis模块
为什么需要这2个呢,是因为python不能直接操作数据库,需要通过库来支持。而这2个就是相应数据库的支持库。
mysqldb:https://sourceforge.net/projects/mysql-python/files/mysql-python/1.2.3/,windows环境下可以直接下.exe来快速安装
redis:
pip install redis
这样就是最简单的了。
动工
先来看下scrapy-redis的一些不同的地方。 
首先就是class的父对象变了,变成了特有的RedisSpider,这是scrapy-redis里面自己定义的新的爬虫类型。其次就是不再有start_urls了,取而代之的是redis_key,scrapy-redis将key从list中pop出来成为请求的url地址。
我们这次选取的对象是58同城的平板电脑信息。
首先来看一下架构信息。 
scrapy.cfg文件我们可以不管,readme.rst文件也不管(这个是github上有用的,scrapy创建项目的时候并没有)
pbdnof58文件夹内的结构: 
items定义文件,settings设置文件,pipelines处理文件以及spiders文件夹。
spiders文件夹盛放着我们编写的具体爬虫: 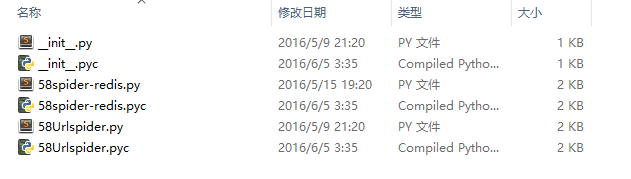
可以看到里面有2个爬虫,一个是用来爬所有的url地址,并将其传递给redis。而另外一个则是根据爬取出来的地址处理具体的商品信息。
具体来看。首先是settings.py文件。 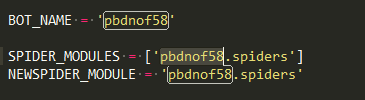
跟scrapy一样,写明spider的位置。 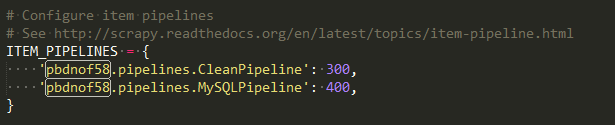
2个处理数据的pipeline中的类,数字越小优先执行。 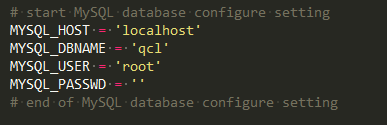
因为数据要存放在mysql中,所以需要配置下mysql的信息。而redis是默认采用本地的,所以并没有配置信息,如果是连接别的主机的话,需要配置下redis的连接地址。
item.py文件 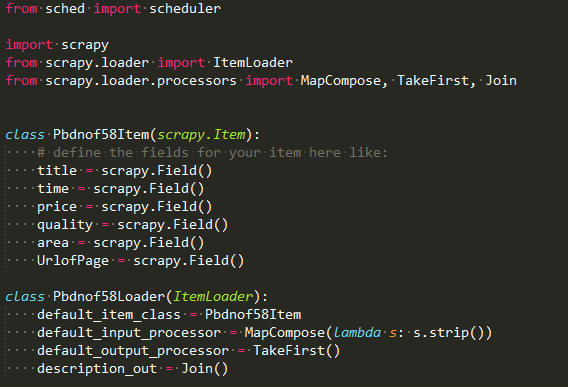
与scrapy相比多了个调度文件,多了个ItemLoader类,照着做就好了,ItemLoader类后面会用到的。
pipeline.py文件
最重要的是这个将结果存储到mysql中。
要在一个名为qcl的数据库之中建一个名叫58pbdndb的表。qcl对应settings的配置。
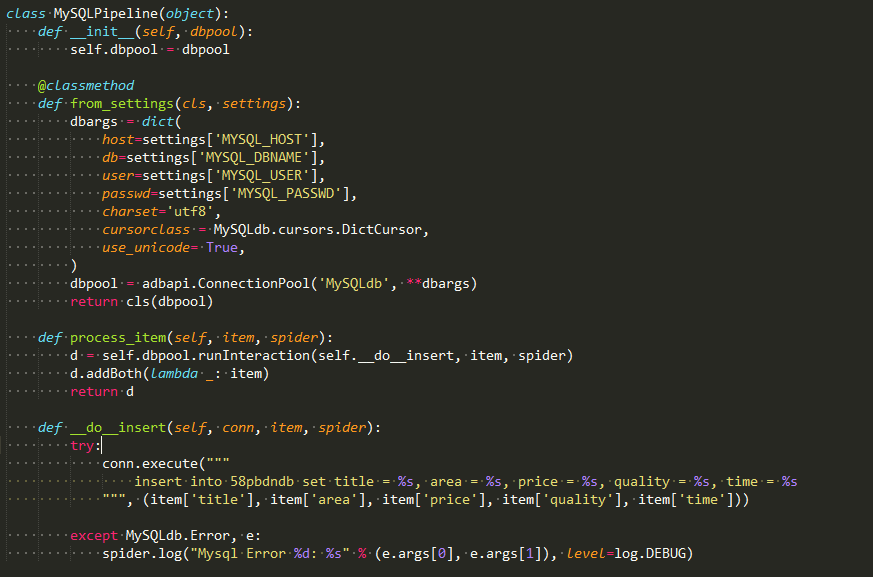
create table 58pbdndb(id INT NOT NULL AUTO_INCREMENT,title VARCHAR(100) NOT NULL,price VARCHAR(40) NOT NULL,quality VARCHAR(40),area VARCHAR(40),time VARCHAR(40) NOT NULL,PRIMARY KEY ( id ))DEFAULT CHARSET=utf8;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
注意:我并没有在表的一开始检查字段是否存在,如果你在调试过程中不止一次的话,你可能需要多次删除表中数据。
58Urlspider.py文件 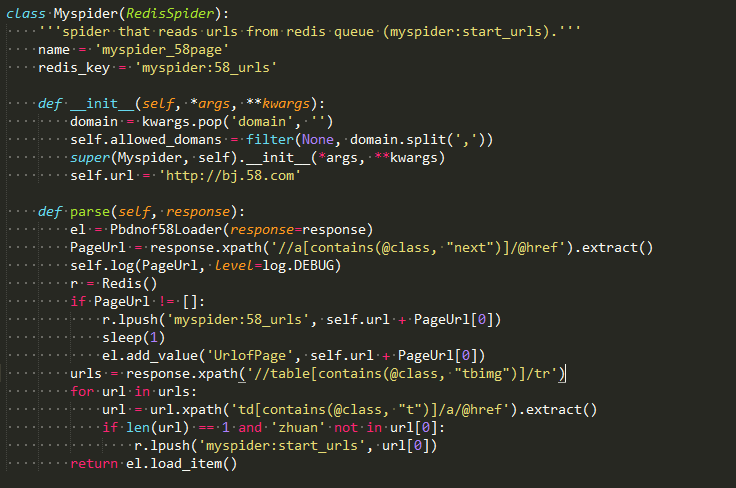
这个爬虫实现了2个功能。1是如果next(也就是下一页)存在,则把下一页的地址压进redis的myspider:58_urls的这个list中,供自己继续爬取。2是提取出想要爬取的商品具体网址,压进redis的myspider:start_urls的list中,供另一个爬虫爬取。
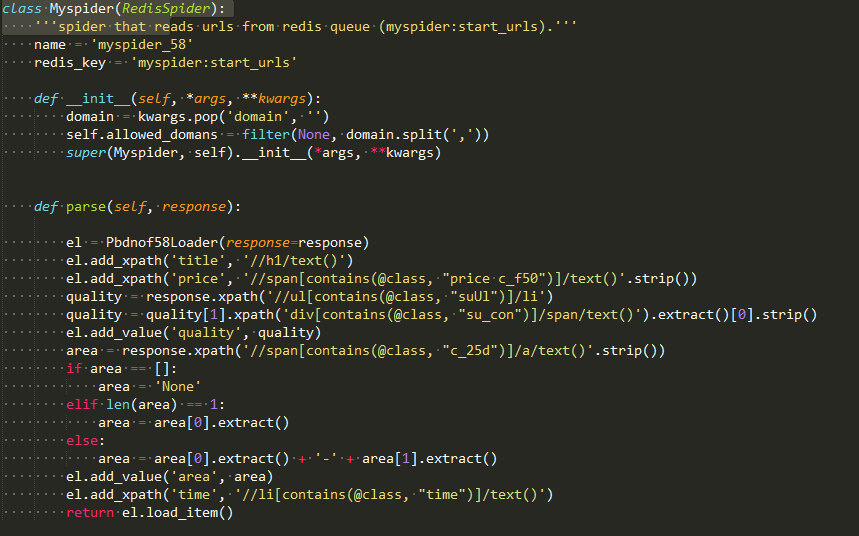
58spider-redis.py文件
这个爬虫是用来抓取具体的商品信息。可以看到ItemLoader类的add_path和add_value方法的使用。
最后
运行方法跟scrapy相同,就是进入pbdnof58文件夹下(注意下面是只有spiders文件夹的那个).输入
scrapy crawl myspider_58page和scrapy crawl myspider_58
- 1
- 2
可以输入多个来观察多进程的效果。。打开了爬虫之后你会发现爬虫处于等待爬取的状态,是因为2个list此时都为空。所以需要
lpush myspider:58_urls http://hz.58.com/pbdn/0/
- 1
- 2
来设置一个初始地址,好啦,这样就可以愉快的看到所有的爬虫都动起来啦。
最后来张数据库的图
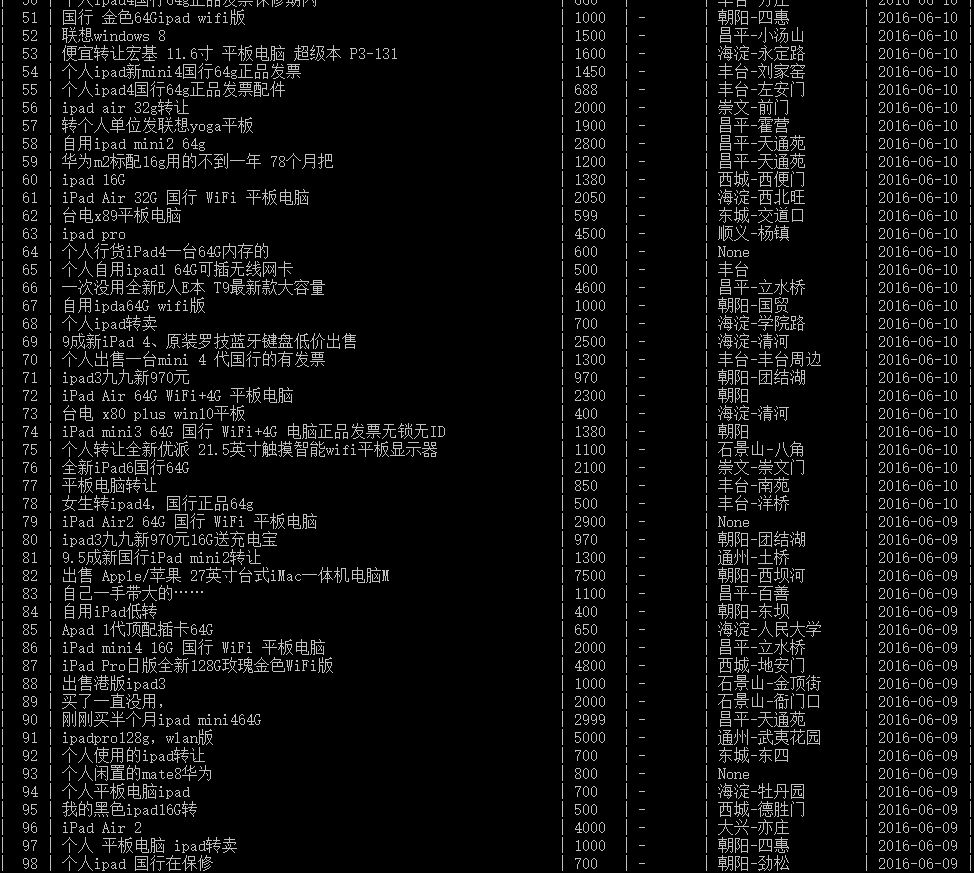
本文相对比较简单,只是scrapy-redis的基本应用。本人也比较小白,刚刚开始学习,如有什么问题,欢迎提出来共同进步。
ps:本文的github地址:https://github.com/qcl643062/spider/tree/master/pbdnof58
使用scrapy-redis构建简单的分布式爬虫的更多相关文章
- Python 用Redis简单实现分布式爬虫
Redis通常被认为是一种持久化的存储器关键字-值型存储,可以用于几台机子之间的数据共享平台. 连接数据库 注意:假设现有几台在同一局域网内的机器分别为Master和几个Slaver Master连接 ...
- 基于Redis的三种分布式爬虫策略
前言: 爬虫是偏IO型的任务,分布式爬虫的实现难度比分布式计算和分布式存储简单得多. 个人以为分布式爬虫需要考虑的点主要有以下几个: 爬虫任务的统一调度 爬虫任务的统一去重 存储问题 速度问题 足够“ ...
- 基于 Redis 实现简单的分布式锁
摘要 分布式锁在很多应用场景下是非常有效的手段,比如当运行在多个机器上的不同进程需要访问同一个竞争资源的时候,那么就会涉及到进程对资源的加锁和释放,这样才能保证数据的安全访问.分布式锁实现的方案有很多 ...
- 基于Redis实现简单的分布式锁【理论】
摘要 分布式锁在很多应用场景下是非常有效的手段,比如当运行在多个机器上的不同进程需要访问同一个竞争资源的时候,那么就会涉及到进程对资源的加锁和释放,这样才能保证数据的安全访问.分布式锁实现的方案有很多 ...
- 基于Redis实现简单的分布式锁
在分布式场景下,有很多种情况都需要实现最终一致性.在设计远程上下文的领域事件的时候,为了保证最终一致性,在通过领域事件进行通讯的方式中,可以共享存储(领域模型和消息的持久化数据源),或者做全局XA ...
- redis实现简单的分布式锁
在分布式系统中多个请求并发对少数资源进行争抢,例如10个人同时秒杀一件商品,如果不用分布式的锁进行处理(当然还有其它的处理方案),则很容易出现多个人抢到一个商品(超卖)的情况,用redis可以比较容易 ...
- 基于docker+redis++urlib/request的分布式爬虫原理
一.整体思路及中心节点的配置 1.首先在虚拟机中运行一个docker,docker中运行的是一个linux系统,里面有我们所有需要的东西,linux系统,python,mysql,redis以及一些p ...
- 使用Redis构建简单的ORM
Reids相关的资料引用 http://www.tuicool.com/articles/bURJRj [Reids各种数据类型的应用场景] https://github.com/antirez/re ...
- 采用requests库构建简单的网络爬虫
Date: 2019-06-09 Author: Sun 我们分析格言网 https://www.geyanw.com/, 通过requests网络库和bs4解析库进行爬取此网站内容. 项目操作步 ...
随机推荐
- poj 2369 Permutations - 数论
We remind that the permutation of some final set is a one-to-one mapping of the set onto itself. Les ...
- noip杂题题解
这道题没有什么可说的,先统计,然后几次快排,答案就出来了 Code(整齐但不简洁的代码) #include<iostream> #include<cstdio> #includ ...
- cogs 444. [HAOI2010]软件安装
★★☆ 输入文件:install.in 输出文件:install.out 简单对比 时间限制:1 s 内存限制:128 MB [问题描述]现在我们的手头有N个软件,对于一个软件i,它要 ...
- HDU 4135 Co-prime(容斥:二进制解法)题解
题意:给出[a,b]区间内与n互质的个数 思路:如果n比较小,我们可以用欧拉函数解决,但是n有1e9.要求区间内互质,我们可以先求前缀内互质个数,即[1,b]内与n互质,求互质,可以转化为求不互质,也 ...
- UVa 1151 买还是建
https://vjudge.net/problem/UVA-1151 题意: 平面上有n个点,你的任务是让所有n个点连通.为此,你可以新建一些边,费用等于两个端点的距离平方和.另外还有q个套餐可以购 ...
- UVa 10603 倒水问题
https://vjudge.net/problem/UVA-10603 题意:三个杯子,倒水问题.找出最少倒水量. 思路:路径寻找问题.不难,暴力枚举. #include<iostream&g ...
- AtCoder Grand Contest 013 C :Ants on a Circle
本文版权归ljh2000和博客园共有,欢迎转载,但须保留此声明,并给出原文链接,谢谢合作. 本文作者:ljh2000 作者博客:http://www.cnblogs.com/ljh2000-jump/ ...
- Codeforces Round #223 (Div. 2) E. Sereja and Brackets 线段树区间合并
题目链接:http://codeforces.com/contest/381/problem/E E. Sereja and Brackets time limit per test 1 secon ...
- go 语言字典元素删除
package main import "fmt" func main() { /* 创建map */ countryCapitalMap := map[string]string ...
- ubuntu 16.04 kinetic 安装rosbridge
sudo apt-get install ros-kinetic-rosbridge-server