Simple2D-22(重构)纹理池
以前 Simple2D 使用 TextureManager,现在将它改为 TexturePool (纹理池)。主要是负责加载和管理纹理,这次为 TexturePool 添加纹理集的功能,纹理集就是将大量的图片拼合成一张纹理。
纹理集的制作
你可以使用软件 TexturePacher 来创建纹理集:
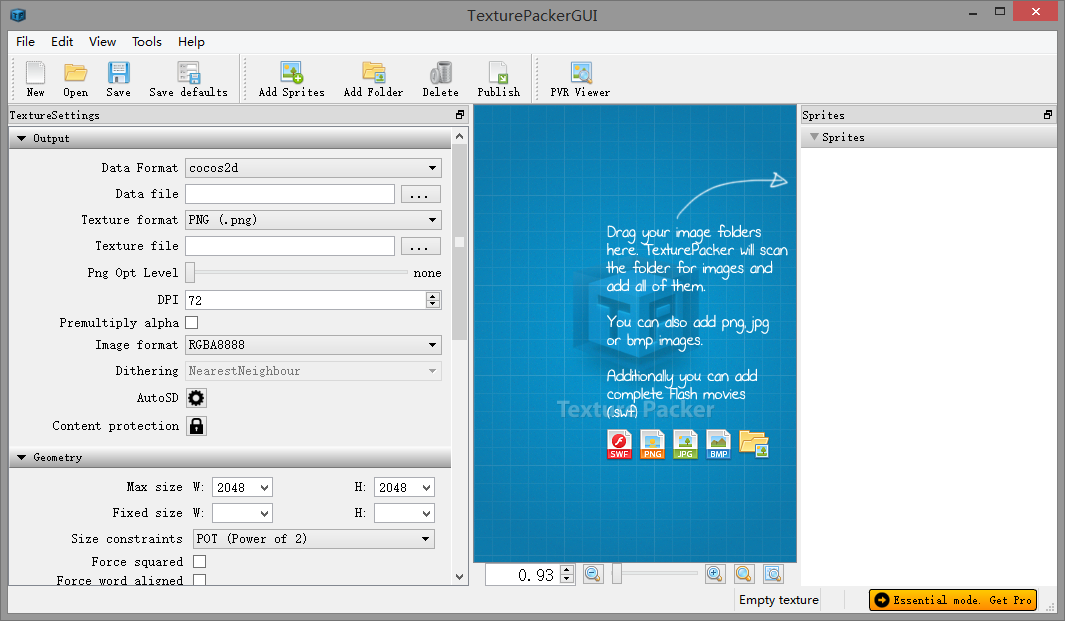
将图片文件拖曳到左边的窗口,然后将 Output 的 DataFormat 设置为 cocos2d,最后选择 Data File 和 Texture File 的输出路径,点击工具栏的 Publish 按钮后得到两个文件 xxx.plist 和 xxx.png,再将这两个文件放置在 Assert 文件夹即可。
解析 Plist 文件
由于 Plist 文件时 xml 格式的,所以可以使用 Tinyxml 库来解析,其中只需要读取 plist 文件的三个信息即可:
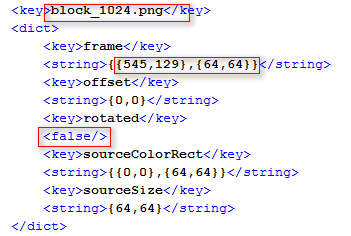
1、纹理文件名,与小图相关联的标签
2、小图的大小和小图在大图中的位置偏移,用来计算纹理坐标
3、小图是否旋转,TexturePacher 在合并小图时为了合理分配空间位置,必要时会对小图旋转 90o,计算纹理坐标时要进行旋转
OpenGL 为每个纹理分配一个唯一的 ID,而纹理集的多张小图都来自于一张纹理,为了管理这些纹理,需要两个结构:TextureUnique 和 Texture2D。TextureUnique 对于着一张纹理,而 Texture2D 则对应小图:
struct Texture2D
{
TextureUnique* textureUnique; int width;
int height;
Vec2 uv[];
};
Texture2D 保存图片的大小(该大小是小图的大小,不是纹理的大小)、纹理坐标和 TextureUnique 对象。
TexturePool 使用 ParsePlistFile( ) 函数来解析 plist 文件:
bool TexturePool::ParsePlistFile(const std::string& filename, std::vector<PlistParseData>& ppd_list)
{
tinyxml2::XMLDocument doc; auto path = PathHelper::fullPath(filename);
if ( doc.LoadFile(path.c_str()) != tinyxml2::XML_NO_ERROR ) {
LOG_WRITE_DEBUG("不存在 plist 文件:%s", filename.c_str());
return false;
} tinyxml2::XMLElement* frame_ele = nullptr;
tinyxml2::XMLElement* context_ele = nullptr; tinyxml2::XMLNode* plist_node = doc.RootElement(); plist_node = plist_node->FirstChildElement();
frame_ele = plist_node->FirstChildElement(); tinyxml2::XMLElement* begin_node = frame_ele->NextSiblingElement()->FirstChildElement(); std::string left, right; while ( begin_node ) {
PlistParseData ppd; ppd.filename = begin_node->GetText();
context_ele = begin_node->NextSiblingElement(); context_ele = context_ele->FirstChildElement("string");
std::string size = context_ele->GetText(); /* {{xx, xx},{xx, xx}} */
left = size.substr(, size.find_first_of("}") - );
right = left.substr(left.find_first_of(",") + , left.size() - left.find_first_of(","));
left = left.substr(, left.find_first_of(",")); ppd.offsetx = atoi(left.c_str());
ppd.offsety = atoi(right.c_str()); right = size.substr(size.find_last_of("{") + , size.size() - size.find_last_of("{") - );
left = right.substr(, right.find_first_of(","));
right = right.substr(right.find_first_of(",") + , right.size() - right.find_first_of(",")); ppd.width = atoi(left.c_str());
ppd.height = atoi(right.c_str()); context_ele = context_ele->NextSiblingElement();
context_ele = context_ele->NextSiblingElement();
context_ele = context_ele->NextSiblingElement();
context_ele = context_ele->NextSiblingElement(); std::string rotate = context_ele->Name();
ppd.rotate = (rotate.compare("true") == ); begin_node = begin_node->NextSiblingElement();
begin_node = begin_node->NextSiblingElement(); ppd_list.push_back(ppd);
}
/* 获取图像文件名 */
frame_ele = frame_ele->NextSiblingElement();
frame_ele = frame_ele->NextSiblingElement();
frame_ele = frame_ele->NextSiblingElement(); tinyxml2::XMLElement* metadata = frame_ele->FirstChildElement("string");
std::string texture_name = metadata->GetText(); metadata = metadata->NextSiblingElement("string");
std::string texture_size = metadata->GetText(); int dot = texture_size.find_first_of(","); PlistParseData ppd;
ppd.filename = texture_name;
ppd.width = atoi(texture_size.substr(, dot - ).c_str());
ppd.height = atoi(texture_size.substr(dot + , texture_size.size() - dot - ).c_str()); ppd_list.push_back(ppd);
return true;
}
将解析得到的小图数据保存到 PlistParseData 结构中,然后得到一个 PlistParseData 数组:
struct PlistParseData
{
std::string filename;
bool rotate; int offsetx;
int offsety; int width;
int height;
};
通过 PlistParseData 数组就可以创建 TextureUnique 和 Texture2D 对象了:
bool TexturePool::LoadFileFromPlist(const std::string& filename)
{
std::vector<PlistParseData> ppd_list;
if ( ParsePlistFile(filename, ppd_list) == false ) {
LOG_WRITE("解析文件 %s 失败!", filename.c_str());
return false;
} TextureUnique* texture_unique = new TextureUnique(ppd_list.back().filename.c_str()); for ( int i = ; i < ppd_list.size() - ; i++ ) {
PlistParseData& ppd = ppd_list[i]; Texture2D* texture_2d = new Texture2D;
texture_2d->textureUnique = texture_unique;
texture_2d->width = ppd.width;
texture_2d->height = ppd.height; /* 计算纹理坐标 */
Vec2 p1, p2;
if ( ppd.rotate ) {
p1.x = ( float ) ppd.offsetx / texture_unique->width;
p1.y = - ( float ) (ppd.offsety + ppd.width) / texture_unique->height; p2.x = ( float ) (ppd.offsetx + ppd.height) / texture_unique->width;
p2.y = - ( float ) ppd.offsety / texture_unique->height; texture_2d->uv[].set(p1.x, p1.y);
texture_2d->uv[].set(p1.x, p2.y);
texture_2d->uv[].set(p2.x, p2.y);
texture_2d->uv[].set(p2.x, p1.y);
}
else {
p1.x = ( float ) ppd.offsetx / texture_unique->width;
p1.y = - ( float ) (ppd.offsety + ppd.height) / texture_unique->height; p2.x = ( float ) (ppd.offsetx + ppd.width) / texture_unique->width;
p2.y = - ( float ) ppd.offsety / texture_unique->height; texture_2d->uv[].set(p1.x, p1.y);
texture_2d->uv[].set(p1.x, p2.y);
texture_2d->uv[].set(p2.x, p2.y);
texture_2d->uv[].set(p2.x, p1.y);
}
vTextureMap.insert(std::make_pair(ppd.filename, texture_2d));
}
return true;
}
将得到的 Texture2D 对象保存到一个数组中,最后通过 TexturePool 提供的函数 Texture2D* GetTexture(const std::string& filename) 获取 Texture2D 对象。而 TextureUnique 则用于纹理的删除,但 TexturePool 并没有提供纹理的删除操作,也就是你无法再不需要纹理时删除纹理,只能在程序结束后删除。
Texture2D 是 Sprite、Painter 和 ImGui 使用的图片渲染对象,而 TextureUnique 只是在 TexturePool 内部使用。
源码下载:Simple2D-20.rar
Simple2D-22(重构)纹理池的更多相关文章
- Simple2D-20(重构)
为什么重构 Simple2D 开始的时候打算使用几周的时间来实现 Simple2D 的,主要是实现一些简单的 2D 渲染功能.但是编写的过程中不满于它只能实现简单的功能,后来添加了诸如Alpha测试. ...
- Simple2D-21(重构)渲染部分
以前 Simple2D 的渲染方法是先设置 Pass,然后添加顶点数据,相同 Pass 的顶点数据会合并在一起.当设置新的 Pass 时,将旧的 Pass 和对应的顶点数据添加到渲染数组中.最后在帧结 ...
- java web学习总结(十六) -------------------数据库连接池
一.应用程序直接获取数据库连接的缺点 用户每次请求都需要向数据库获得链接,而数据库创建连接通常需要消耗相对较大的资源,创建时间也较长.假设网站一天10万访问量,数据库服务器就需要创建10万次连接,极大 ...
- javaweb学习总结(三十九)——数据库连接池
一.应用程序直接获取数据库连接的缺点 用户每次请求都需要向数据库获得链接,而数据库创建连接通常需要消耗相对较大的资源,创建时间也较长.假设网站一天10万访问量,数据库服务器就需要创建10万次连接,极大 ...
- Linux简单线程池实现(带源码)
这里给个线程池的实现代码,里面带有个应用小例子,方便学习使用,代码 GCC 编译可用.参照代码看下面介绍的线程池原理跟容易接受,百度云下载链接: http://pan.baidu.com/s/1i3z ...
- JavaWeb学习(三十)———— 数据库连接池
一.应用程序直接获取数据库连接的缺点 用户每次请求都需要向数据库获得链接,而数据库创建连接通常需要消耗相对较大的资源,创建时间也较长.假设网站一天10万访问量,数据库服务器就需要创建10万次连接,极大 ...
- javaweb(三十九)——数据库连接池
一.应用程序直接获取数据库连接的缺点 用户每次请求都需要向数据库获得链接,而数据库创建连接通常需要消耗相对较大的资源,创建时间也较长.假设网站一天10万访问量,数据库服务器就需要创建10万次连接,极大 ...
- Tomcat 与 数据库连接池 的小坑
连接池的优点众所周知. 我们可以自己实现数据库连接池,也可引入实现数据库连接池的jar包,按要求进行配置后直接使用. 关于这方面的资料,好多dalao博客上记录的都是旧版本Tomcat的配置方式,很可 ...
- javaweb基础(39)_数据库连接池
一.应用程序直接获取数据库连接的缺点 用户每次请求都需要向数据库获得链接,而数据库创建连接通常需要消耗相对较大的资源,创建时间也较长.假设网站一天10万访问量,数据库服务器就需要创建10万次连接,极大 ...
随机推荐
- zstack(一)运行及开发环境搭建及说明(转载)
本篇介绍zstack的部署环境,以及二次开发环境 运行环境 讲真,ZStack的安装做的还是不错的,提供多种安装模式,如离线安装.在线安装.一键安装.分布式安装等.安装的过程其实都很简单,当然这也是z ...
- Hadoop 和 Spark 的关系
Hadoop实质上是一个分布式数据基础设施: 它将巨大的数据集分派到一个由普通计算机组成的集群中的多个节点进行存储,意味着您不需要购买和维护昂贵的服务器硬件. 同时,Hadoop还会索引和跟踪这些数据 ...
- [C#]画图全攻略(饼图与柱状图)(转)
http://blog.chinaunix.net/uid-15481846-id-2769484.html 首先建立一个c#的类库. 打开vs.net,建立一个名为Insight_cs.WebC ...
- 如何在UltraEdit中高亮显示PB代码
打开UE,从菜单中选择高级->配置… 点击打开按钮,注意文件WordFile.txt最后一个高亮显示语言的编号,格式为“ /L(number) ”,假设最后一个高亮显示语言的编号是15,修改UE ...
- linux 信号处理 二 (信号的默认处理)
今天碰到一个SIGHUP问题,再复习一遍: 有些信号的默认处理方式为“终止+core”,这里的core表示,进程终止时,会在进程的当前工作目录生产一个core文件,该文件是进程终止时的内存快照,以便以 ...
- bzoj 4449: [Neerc2015]Distance on Triangulation
Description 给定一个凸n边形,以及它的三角剖分.再给定q个询问,每个询问是一对凸多边行上的顶点(a,b),问点a最少经过多少条边(可以是多边形上的边,也可以是剖分上的边)可以到达点b. I ...
- bzoj4153 [Ipsc2015]Familiar Couples
Description 有n对夫妇,一开始夫妇之间互不认识,若两男或两女成为朋友,称他们为"熟人","熟人"关系具有传递性,即若a熟b且b熟c则a熟c.若两组夫 ...
- 基于Linux的Samba开源共享解决方案测试(五)
对于客户端的网络监控如图: 双NAS网关50Mb码率视音频文件的稳定写测试结果如下: 100Mb/s负载性能记录 NAS网关资源占用 稳定写 稳定写 CPU空闲 内存空闲 网卡占用 NAS1 16个稳 ...
- 那些你希望N年前就掌握的命令
这篇文章转载自黑客志,短短的一篇文章我找到了3个对我非常有用的技巧,在信息爆炸的今天,简直就跟捡宝似的,希望这些命令对你也有帮助. 有人在Reddit上发帖询问:有没有哪条命令是你希望自己在几年前就掌 ...
- ORM创建 脚本运行