N-gram模型
建立在马尔可夫模型上的一种概率语法.它通过对自然语言的符号串中n个符号同时出现概率的统计数据来推断句子的结构关系.当n=2时,称为二元语法,当n=3时,称为三元语法.
N-Gram是大词汇连续语音识别中 常用的一种语言模型,对中文而言,我们称之为汉语语言模型(CLM, Chinese Language Model)。汉语语言模型利用上下文中相邻词间的搭配信息,在需要把连续无空格的拼音、笔划,或代表字母或笔划的数字,转换成汉字串(即句子)时,可以 计算出具有最大概率的句子,从而实现到汉字的自动转换,无需用户手动选择,避开了许多汉字对应一个相同的拼音(或笔划串,或数字串)的重码问题。
该模型基于这样一种假设,第n个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。常用的是二元的Bi-Gram和三元的Tri-Gram。
在介绍N-gram模型之前,让我们先来做个香农游戏(Shannon Game)。我们给定一个词,然后猜测下一个词是什么。当我说“艳照门”这个词时,你想到下一个词是什么呢?我想大家很有可能会想到“陈冠希”,基本上不 会有人会想到“陈志杰”吧。N-gram模型的主要思想就是这样的。
对于一个句子T,我们怎么算它出现的概率呢?假设T是由词序列W1,W2,W3,…Wn组成的,那么P(T)=P(W1W2W3Wn)=P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1)
补充知识:

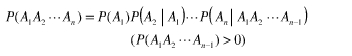
但是这种方法存在两个致命的缺陷:一个缺陷是参数空间过大,不可能实用化;另外一个缺陷是数据稀疏严重。
为了解决这个问题,我们引入了马尔科夫假设:一个词的出现仅仅依赖于它前面出现的有限的一个或者几个词。
如果一个词的出现仅依赖于它前面出现的一个词,那么我们就称之为bigram。即
P(T) = P(W1W2W3…Wn)=P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1)
≈P(W1)P(W2|W1)P(W3|W2)…P(Wn|Wn-1)
如果一个词的出现仅依赖于它前面出现的两个词,那么我们就称之为trigram。
在实践中用的最多的就是bigram和trigram了,而且效果很不错。高于四元的用的很少,因为训练它需要更庞大的语料,而且数据稀疏严重,时间复杂度高,精度却提高的不多。
那么我们怎么得到P(Wn|W1W2…Wn-1)呢?一种简单的估计方法就是最大似然估计(Maximum Likelihood Estimate)了。即P(Wn|W1W2…Wn-1) = (C(W1 W2…Wn))/(C(W1 W2…Wn-1))
剩下的工作就是在训练语料库中数数儿了,即统计序列C(W1 W2…Wn) 出现的次数和C(W1 W2…Wn-1)出现的次数。
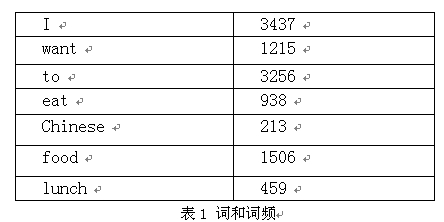
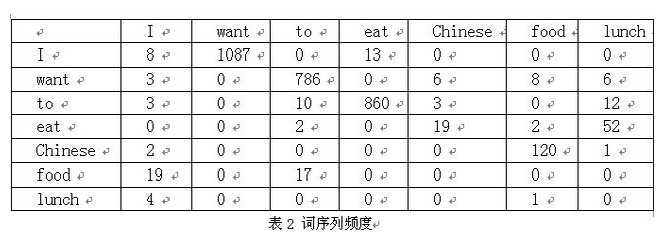
下面我们用bigram举个例子。假设语料库总词数为13,748
P(I want to eat Chinese food)
=P(I)*P(want|I)*P(to|want)*P(eat|to)*P(Chinese|eat)*P(food|Chinese)
=0.25*1087/3437*786/1215*860/3256*19/938*120/213
=0.000154171
ps:网上很多资料中,表1,词与词频的张表是没有的,所以造成文章表意不清。
这里还有一个问题要说,那就是数据稀疏问题了,假设词表中有20000个词,如果是bigram那么可能的N-gram就有400000000个,如果是trigram,那么可能的N-gram就有8000000000000个!那么对于其中的很多词对的组合,在语料库中都没有出现,根据最大似然估计得到的概率将会是0,这会造成很大的麻烦,在算句子的概率时一旦其中的某项为0,那么整个句子的概率就会为0,最后的结果是,我们的模型只能算可怜兮兮的几个句子,而大部分的句子算得的概率是0. 因此,我们要进行数据平滑(data Smoothing),数据平滑的目的有两个:一个是使所有的N-gram概率之和为1,使所有的N-gram概率都不为0.有关数据平滑的详细内容后面会再讲到,这里不再赘述。
了解了噪声信道模型和N-gram模型的思想之后,其实我们自己就能实现一个音词转换系统了,它是整句智能输入法的核心,其实我们不难猜到,搜狗拼音和微软拼音的主要思想就是N-gram模型的,不过在里面多加入了一些语言学规则而已。

N-gram模型的更多相关文章
- Paddle Graph Learning (PGL)图学习之图游走类模型[系列四]
Paddle Graph Learning (PGL)图学习之图游走类模型[系列四] 更多详情参考:Paddle Graph Learning 图学习之图游走类模型[系列四] https://aist ...
- Tensorflow 的Word2vec demo解析
简单demo的代码路径在tensorflow\tensorflow\g3doc\tutorials\word2vec\word2vec_basic.py Sikp gram方式的model思路 htt ...
- RNN神经网络和英中机器翻译的实现
本文系qitta的文章翻译而成,由renzhe0009实现.转载请注明以上信息,谢谢合作. 本文主要讲解以recurrent neural network为主,以及使用Chainer和自然语言处理其中 ...
- 词向量之Word2vector原理浅析
原文地址:https://www.jianshu.com/p/b2da4d94a122 一.概述 本文主要是从deep learning for nlp课程的讲义中学习.总结google word2v ...
- Word2vector原理
词向量: 用一个向量的形式表示一个词 词向量的一种表示方式是one-hot的表示形式:首先,统计出语料中的所有词汇,然后对每个词汇编号,针对每个词建立V维的向量,向量的每个维度表示一个词,所以,对应编 ...
- word2vec的Java源码【转】
一.核心代码 word2vec.java package com.ansj.vec; import java.io.*; import java.lang.reflect.Array; import ...
- Graph Embedding:
https://blog.csdn.net/hy_jz/article/details/78877483 基于meta-path的异质网络Embedding-metapath2vec metapath ...
- 利用 TensorFlow 入门 Word2Vec
利用 TensorFlow 入门 Word2Vec 原创 2017-10-14 chen_h coderpai 博客地址:http://www.jianshu.com/p/4e16ae0aad25 或 ...
- 统计学习方法 --- 感知机模型原理及c++实现
参考博客 Liam Q博客 和李航的<统计学习方法> 感知机学习旨在求出将训练数据集进行线性划分的分类超平面,为此,导入了基于误分类的损失函数,然后利用梯度下降法对损失函数进行极小化,从而 ...
- 机器学习PR:感知机模型
感知机是二类分类的线性分类模型,所谓二分类指的是输出的类别只有-1或1两种,所谓线性指的是输入的特征向量集合在特征空间中被超平面划分为相互分离的正负两类.感知机学习的目的正是为了求出将训练数据进行线性 ...
随机推荐
- InnoDB的WAL方式学习
之前写过一篇博文,<不好的MySQL过程编写习惯>(http://www.cnblogs.com/wingsless/p/5041838.html).这篇博文里强调了不要循环的提交事务,尽 ...
- Bootstrap 学习(1)
简介 Bootstrap,来自 Twitter,是目前最受欢迎的前端框架.Bootstrap 是基于 HTML.CSS.JAVASCRIPT 的,它简洁灵活,使得 Web 开发更加快捷. Bootst ...
- 基于Bootstrap的DropDownList的JQuery组件的完善版
在前文 创建基于Bootstrap的下拉菜单的DropDownList的JQuery插件 中,实现了DropDownList的JQuery组件,但是留有遗憾.就是当下拉菜单出现滚动条的时候,滚动条会覆 ...
- Codeforces 549B. Looksery Party[构造]
B. Looksery Party time limit per test 1 second memory limit per test 256 megabytes input standard in ...
- NOIP2012借教室[线段树|离线 差分 二分答案]
题目描述 在大学期间,经常需要租借教室.大到院系举办活动,小到学习小组自习讨论,都需要 向学校申请借教室.教室的大小功能不同,借教室人的身份不同,借教室的手续也不一样. 面对海量租借教室的信息,我们自 ...
- java 解决中文乱码
//1.代码解决 public class LuanMa { public static String getNewString(String luanma){ String result = &qu ...
- ural One-two, One-two 2
One-two, One-two 2 Time Limit:2000MS Memory Limit:65536KB 64bit IO Format:%I64d & %I64u ...
- AC日记——潜伏着 openjudge 1.7 11
11:潜伏者 总时间限制: 1000ms 内存限制: 65536kB 描述 R国和S国正陷入战火之中,双方都互派间谍,潜入对方内部,伺机行动. 历经艰险后,潜伏于S国的R国间谍小C终于摸清了S国军 ...
- http协议(二)请求和响应报文的构成
http协议用于客户端和服务器之间的通信,请求访问资源的一方称为客户端,而提供资源响应的一方称为服务器端. 下面就是客户端和服务端之间简单的通信过程 PS:请求必须从客户端建立通信,服务端没收到请求之 ...
- Vs 2015 调试ASP.NET Core修改监听端口
如何改变监听IP地址和端口?在这里找到了答案:https://github.com/aspnet/KestrelHttpSer... 把Program.cs加一行UseUrls代码如下: using ...