初识Python第三天(二)
2.2 OrderedDict有序字典
import collections
dic = collections.OrderedDict()
dic['k1'] = 'v1'
dic['k2'] = 'v2'
dic['k3'] = 'v3'
print(dic)
dic.move_to_end('k1') #将'k1'放到字典末尾
print(dic) #OrderedDict([('k1', 'v1'), ('k2', 'v2'), ('k3', 'v3')])
#OrderedDict([('k2', 'v2'), ('k3', 'v3'), ('k1', 'v1')])
move_to_end将指定元素放到最后
import collections
dic = collections.OrderedDict()
dic['k1'] = 'v1'
dic['k2'] = 'v2'
dic['k3'] = 'v3'
print(dic dic.popitem()
print(dic) #OrderedDict([('k1', 'v1'), ('k2', 'v2'), ('k3', 'v3')])
#OrderedDict([('k1', 'v1'), ('k2', 'v2')])
popitem 移除最新添加的元素(后进先出)
#移除指定元素,可将移除的元素赋值给自己
import collections
dic = collections.OrderedDict()
dic['k1'] = 'v1'
dic['k2'] = 'v2'
dic['k3'] = 'v3'
print(dic)
dic.pop('k2')
print(dic) #OrderedDict([('k1', 'v1'), ('k2', 'v2'), ('k3', 'v3')])
#OrderedDict([('k1', 'v1'), ('k3', 'v3')]) import collections
dic = collections.OrderedDict()
dic['k1'] = 'v1'
dic['k2'] = 'v2'
dic['k3'] = 'v3'
print(dic)
ret = dic.pop('k2')
print(ret) #将移除的元素赋值给变量 #OrderedDict([('k1', 'v1'), ('k2', 'v2'), ('k3', 'v3')])
#v2
pop移除指定元素
import collections
dic = collections.OrderedDict()
dic['k1'] = 'v1'
dic['k2'] = 'v2'
dic['k3'] = 'v3'
print(dic)
dic.setdefault('k4', '') #setdefault设置默认值,如果对象后面不加参数默认为None
print(dic) #OrderedDict([('k1', 'v1'), ('k2', 'v2'), ('k3', 'v3')])
#OrderedDict([('k1', 'v1'), ('k2', 'v2'), ('k3', 'v3'), ('k4', '66')])
setdefault设置默认值
import collections
dic = collections.OrderedDict()
dic['k1'] = 'v1'
dic['k2'] = 'v2'
dic['k3'] = 'v3'
print(dic)
dic.update({'k1':'v111', 'k10':'v10'})
print(dic) #OrderedDict([('k1', 'v1'), ('k2', 'v2'), ('k3', 'v3')])
#OrderedDict([('k1', 'v111'), ('k2', 'v2'), ('k3', 'v3'), ('k10', 'v10')])
update更新原有的数据
2.3 默认字典
import collections
dic = collections.defaultdict(list) #设置类型为列表类型
dic['k1'].append('alex')
print(dic) #defaultdict(<class 'list'>, {'k1': ['alex']})
2.4可命令元组
#可命令元组
import collections
MytupleClass = collections.namedtuple('MytupleClass',['x', 'y', 'z']) #创建一个类,类名为MytupleClass
obj = MytupleClass(11,22,33)
print(obj.x) #直接通过命令元素去访问元组对应的元素
print(obj[0]) #等同于上面这种方式,但是没有上面这种方式可读性强
print(obj.y)
print(obj.z) #
#
#
#
2.5 deque双向队列
import collections
newdeque = collections.deque(['alex', 'eric', 'jack']) #创建一个双向队列
print(newdeque) #deque(['alex', 'eric', 'jack']) newdeque.append('') #追加一个元素到队列
print(newdeque) #deque(['alex', 'eric', 'jack', '11']) newdeque.appendleft('') #追加一个元素到左侧
print(newdeque) #deque(['22', 'alex', 'eric', 'jack', '11']) newc = newdeque.count('alex') #对队列里某个元素进行计数
print(newc) # newdeque.extend(['', '']) #扩展队列元素
print(newdeque) #deque(['22', 'alex', 'eric', 'jack', '11', '44', '55']) newdeque.extendleft(['aa', 'bb']) #从左侧进行扩展
print(newdeque) #deque(['bb', 'aa', '22', 'alex', 'eric', 'jack', '11', '44', '55']) newdeque.insert(2, 'haha') #插入到下标2的位置
print(newdeque) #deque(['alex', 'eric', 'haha', 'jack']) newdeque.reverse() #顺序反转
print(newdeque) #deque(['jack', 'haha', 'eric', 'alex']) newdeque.rotate(3) #将队列末尾3个元素反转到队列左侧
print(newdeque) #deque(['haha', 'eric', 'alex', 'jack'])
2.5.1 deque双向队列,该对象与collections的deque实质是完全一样的效果,这里就不作演示了,使用方法如下:
import queue
q = queue.Queue(['a', 'b'])
import queue
newdeque = queue.Queue(3) #设置队列长度为3,也就是队列里面只有3个任务,如果不设置队列长度,就可以有
#无限个任务,直到内存耗尽
newdeque.put(['', '']) #放入第一个任务
get1 = newdeque.get() #获取第一个任务
print(get1) #['1', '2'] newdeque.put(['a', 'b']) #放入第二个任务
get2 = newdeque.get() #获取第二个任务
print(get2) #['a', 'b'] isempty = newdeque.empty() #判断队列是否为空
print(isempty) # True isfull = newdeque.full() #判断多列是否已经满了
print(isfull) #False
queue 单项队列
三.深浅拷贝
import copy #导入拷贝模块
copy.copy() #浅拷贝
copy.deepcopy() #深拷贝
name = 'alex'
copyname = name #赋值
#浅拷贝
import copy
a1 = [10,'b1',[111,112],'ha',]
a2 = copy.copy(a1) #浅拷贝
print(a1)
print(a2) a1[1] = 11 #改变a1的值
a1[2][0] = 1111 #改变a1内嵌列表的值,将a1的第2个下标的第0个下标值改变
print(a1)
print(a2)
print(id(a1))
print(id(a2))
print(id(a1[2][0]))
print(id(a2[2][0])) #[10, 'b1', [111, 112], 'ha']
#[10, 'b1', [111, 112], 'ha']
#通过下面的对比,发现浅拷贝对于内嵌多层数据类型的操作,如果多层数据类型值改变,浅拷贝的对象也会跟着改变
#[10, 11, [1111, 112], 'ha']
#[10, 'b1', [1111, 112], 'ha'] #12542664
#12543688 #7183888
#7183888
#深拷贝
import copy
a1 = [10,'b1',[111,112],'ha',]
a2 = copy.deepcopy(a1) #深拷贝
print(a1)
print(a2) a1[1] = 11 #改变a1的值
a1[2][0] = 1111 #改变a1内嵌列表的值,将a1的第2个下标的第0个下标值改变
print(a1)
print(a2)
print(id(a1))
print(id(a2))
print(id(a1[2][0]))
print(id(a2[2][0])) #[10, 'b1', [111, 112], 'ha']
#[10, 'b1', [111, 112], 'ha']
#结合上面的例子进行对比发现,对应深层拷贝,内嵌多层的数据类型的值,被改变,不会影响到另一方拷贝或被拷贝的对象
#[10, 11, [1111, 112], 'ha']
#[10, 'b1', [111, 112], 'ha']
#19030728
#19031752
#7118352
#1723483792
四.函数
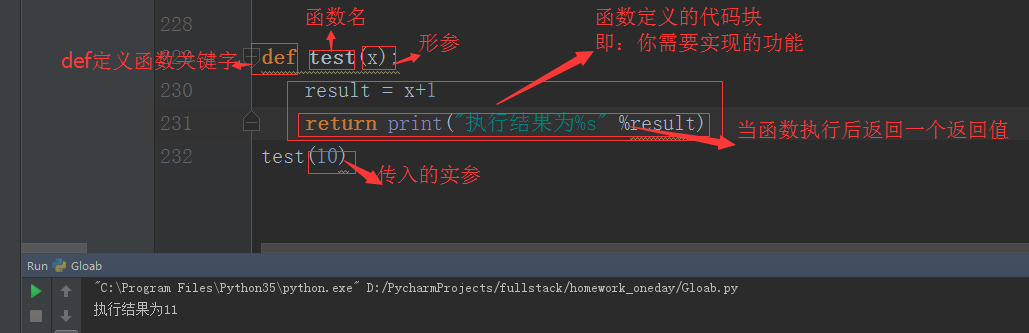
函数定义主要有如下要点
1.def:表示函数的关键字
2.函数名:函数的名称,日后可根据函数名调用函数
3.函数体:函数中进行一系列的逻辑计算。
4.参数:为函数提供数据
5.返回值:当函数中执行完成后,可以给调用者返回数据
以上要点中,比较重要的有参数和返回值
def func(): #创建一个函数,没有接收参数
print('hello') func() #直接执行函数
#执行结果 hello foo = func #创建一个对象
foo() #执行对象
#执行结果 hello def func(arg): #传入一个参数
print('hello %s' % arg) func('laiying') #执行结果输出 hello laiying def func(arg1,arg2): #传入两个参数
print('hello %s, %s' % (arg1, arg2)) func('laiying','good') #执行结果输出 hello laiying, good def func(*args): #动态参数,多个参数,可以为空
print('hello %s' % (''.join(args))) func('laiying', '很棒', 'very good') #执行结果输出hello laiying很棒very good #以下两种方式得到的效果相同
def show(*args,**kwargs):
print(args,type(args))
print(kwargs,type(kwargs))
show(11,22,33, n1= 88,n2='alex')
#结果输出(11, 22, 33) <class 'tuple'>{'n2': 'alex', 'n1': 88} <class 'dict'> def show(*args,**kwargs):
print(args,type(args))
print(kwargs,type(kwargs))
a = [11, 22, 33, ]
b = {'n1':88, 'n2':'alex'}
show(*a, **b)
#结果输出(11, 22, 33) <class 'tuple'>{'n2': 'alex', 'n1': 88} <class 'dict'>
函数参数
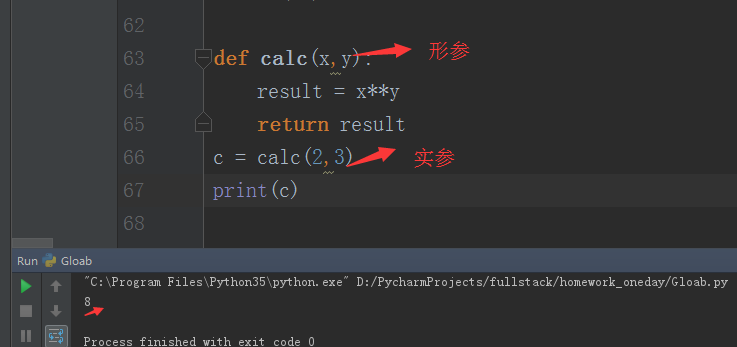
1.形参变量只有在被调用时才分配内存单元, 在调用结束时,即可释放所分配的内存单元,因此,形参只在函数内部有效,
函数调用结束返回时主调用函数后则不能在使用该形参变量
2.实参可以是常量,变量,表达试,函数等,无论实参是何类型的量,在进行函数调用时,它们都必须有确定的值,
以便把这些值传送给行参,因此应预先用赋值,输入等办法使参数获得确定值
3.位置参数和关键字(标准调用:实参与行参位置必须一一对应,关键字调用:位置无需固定)
4.默认参数
5.参数组 *args 以元组的形式传入参数 **kwagrs以字典的形式传入参数

以上参数是以一个整体,元组,字典的方式传入,如果需要一次传入多个元素,但是又可以分开一个一个传入,可以使用以下方式
参数的传入规则 (位置参数,关键字参数)---------默认参数------------参数组
五.嵌套函数
# 创建嵌套函数
NAME = 'alex'
def global_test(): # 第一层定义的函数
name = 'rain'
print("global_test: ",name)
def local_test(): # 第二层定义的函数
name = 'jack'
print("local_test: ",name)
def test(): # 第三成第一的函数
name = 'ying'
print("test: ",name) test()
local_test()
global_test() #执行结果
global_test: rain
local_test: jack
test: ying #通过以上结果我们可以看出,嵌套函数的执行顺序是,先执行外层函数,然后依次执行内层中的嵌套函数, 内层中的函数不可在其他地方调用,只能在该函数中调用
六:函数中global与nonlocal的作用

通过以上截图可以看出,只要通过global关键字将变量改为了全局变量,那么以前的那个全局变量就会被覆盖,以后在执行该变量时,执行的就是通过global从新定义的这个全局变量,
全局变量的范围就是整个程序
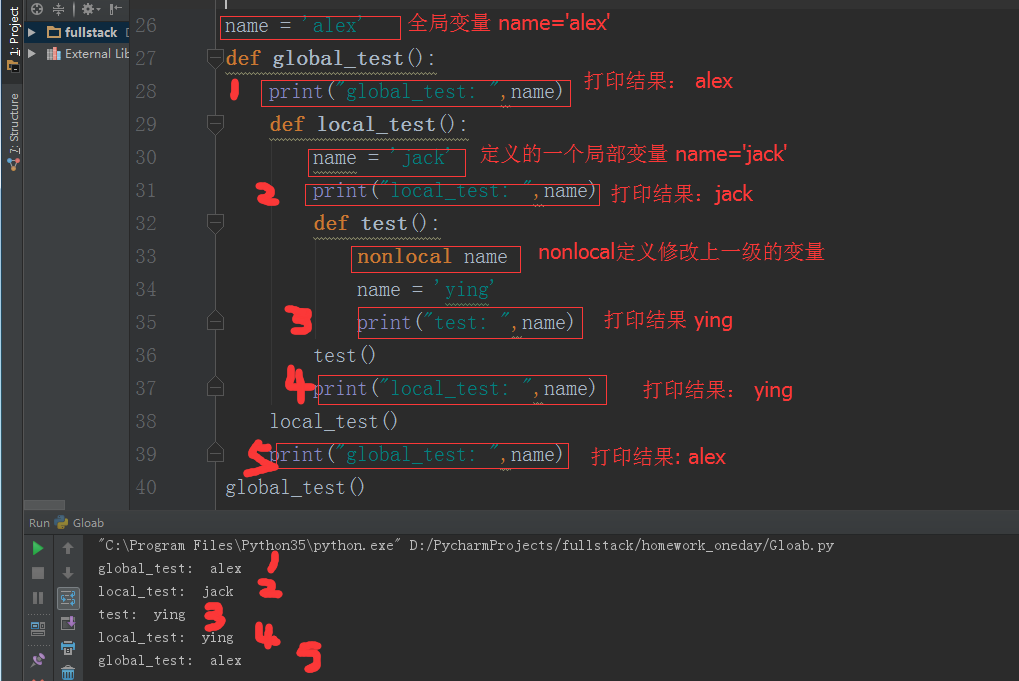
通过以上截图可以看出nonloacl关键字的作用就是,将上一层的变量修改为当前变量,只对上一层生效,不能对其它层生效
六.递归
在函数内部,可以调用其他函数,如果一个函数在内部调用自己本身,这个函数就是递归函数
def calc(n):
print(n)
if int(n/2) == 0:
return n
return calc(int(n/2))
calc(10) #执行结果
10
5
2
1 #根据以上结果,我们来分析一下执行的流程
1.给calc这个函数传入一个参数n为10
2.打印这个函数
3.if判断n是不是等0,如果n==0就终止这个函数,并给一个返回值n
4.终止自身函数的运行,然后调用自己,计算n/2,并将这个值给返回。 5.重复以上执行流程,一直到n/2==0,就终止这个函数本身的运行,并return一个返回值n
递归问路
person_list = ["alex","jakc","rain"]
def ask_way(person_list):
print('-'*60)
if len(person_list) == 0:
return "没有人知道"
person = person_list.pop(0)
if person == "rain":
return "%s说:我知道,圆明园在海淀,下地铁就到" %person
print("hi [%s],请问圆明园在什么地方" %person)
print("%s回答道:我不知道,你等在,我帮你问下一个人%s"%(person,person_list))
res = ask_way(person_list)
print("%s问的结果是:%res" %(person,res))
return res
res = ask_way(person_list)
print(res) ###########执行结果##########
------------------------------------------------------------
hi [alex],请问圆明园在什么地方
alex回答道:我不知道,你等在,我帮你问下一个人['jakc', 'rain']
------------------------------------------------------------
hi [jakc],请问圆明园在什么地方
jakc回答道:我不知道,你等在,我帮你问下一个人['rain']
------------------------------------------------------------
jakc问的结果是:'rain说:我知道,圆明园在海淀,下地铁就到'es
alex问的结果是:'rain说:我知道,圆明园在海淀,下地铁就到'es
rain说:我知道,圆明园在海淀,下地铁就到
递归特性
1.必须要有一个明确的结束条件
2.每次进入更深一次递归时,问题规模相比上次递归都应有所减少
3.递归效率不高,递归层次过多会导致栈溢出
(在计算机中,函数调用是通过栈(stack)这个数据结果实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧,
由于栈的大小不是无限的,所以,递归调用的次数过多,会会导致栈溢出)
七.lambda & map
lambda书写格式:参数:表达式 直接得出一个结果,赋值给一个变量
lamdba存在的意义是对简单函数的简洁表达
func = lambda a:a+1 #创建形式参数a
ret = func(1) #函数内容,a+1 并把结果retun回去 print(ret)
#打印输出 2 map1 = map(lambda x:x+100, [11,22,33]) #map(函数,'参数')
print(list(map1))
#结果输出 [111, 122, 133] ,python2.x可以直接看到结果,python3.x需要转换成list才能看到结果
初识Python第三天(二)的更多相关文章
- python第三十二课——队列
队列:满足特点 --> 先进先出,类似于我们生活中的买票.安检 [注意] 对于队列而言:python中有为其封装特定的函数,在collections模块中的deque函数就可以获取一个队列对象; ...
- 初识Python(三)
一.作用域 对于变量的作用域,执行声明并在内存中存在,该变量就可以在后续的代码中使用: 外层变量,可以被内层变量使用:内层变量,也可以被外层变量使用: 如下示例: #!/usr/bin/env pyt ...
- 初识Python第三天(一)
一.set集合 set是一个无序且不重复的元素集合 print(dir(set)) #['__and__', '__class__', '__contains__', '__delattr__', ' ...
- python第三十二课——栈
栈:满足特点 --> 先进后出,类似于我们生活中的子弹夹 [注意] 对于栈结构而言:python中没有为其封装特定的函数,我们可以使用list(列表)来模拟栈的特点 使用list对象来模拟栈结构 ...
- 笨办法学Python(三十二)
习题 32: 循环和列表 现在你应该有能力写更有趣的程序出来了.如果你能一直跟得上,你应该已经看出将“if 语句”和“布尔表达式”结合起来可以让程序作出一些智能化的事情. 然而,我们的程序还需要能很快 ...
- python学习 (三十二) 异常处理
1 异常: def exceptionHandling(): try: a = b = d = a / b print(d) except ZeroDivisionError as ex: print ...
- 孤荷凌寒自学python第三十八天初识python的线程控制
孤荷凌寒自学python第三十八天初识python的线程控制 (完整学习过程屏幕记录视频地址在文末,手写笔记在文末) 一.线程 在操作系统中存在着很多的可执行的应用程序,每个应用程序启动后,就可以看 ...
- 孤荷凌寒自学python第三十三天python的文件操作初识
孤荷凌寒自学python第三十三天python的文件操作初识 (完整学习过程屏幕记录视频地址在文末,手写笔记在文末) 今天开始自学python的普通 文件操作部分的内容. 一.python的文件打开 ...
- 初识python(二)
初识python(二) 1.变量 变量:把程序运行的中间结果临时的存在内存里,以便后续的代码调用. 1.1 声明变量: #!/usr/bin/env python # -*- coding: utf- ...
随机推荐
- [CareerCup] 17.7 English Phrase Describe Integer 英文单词表示数字
17.7 Given any integer, print an English phrase that describes the integer (e.g., "One Thousand ...
- 一个参数大小写引发的uploadify报错 "Syntax error, unrecognized expression: #"
上传控件uploadify 报错"Syntax error, unrecognized expression: #" 版本为 uploadify3.2 报错原因:参数ID[hi ...
- 你应了解的4种JS设计模式
学习地址: http://mp.weixin.qq.com/s?__biz=MjM5MTA1MjAxMQ==&mid=2651223556&idx=1&sn=8cd7a2272 ...
- ngrok访问外网
1. 外网映射工具介绍 windows用户: 1,下载windows版本的客户端,解压到你喜欢的目录2,在命令行下进入到path/to/windows_386/下3,执行 ngrok -config= ...
- iOS9 HTTP传输安全
1.在Info.plist中添加 NSAppTransportSecurity 类型 Dictionary 2.在 NSAppTransportSecurity 下添加 NSAllowsArbitr ...
- 【7集iCore3基础视频】7-5 iTool2驱动安装
iTool2驱动安装: 高清源视频:链接:http://pan.baidu.com/s/1dF5FtlB%20密码:g5x7 iCore3 购买链接:https://item.taobao.com/i ...
- 安装SSD固态硬盘
满足三个要求:开启AHCI."4K对齐".SSD初始化. 1. 开启AHCI模式 重启,进入bios,高级模式,SATA模式选择,选择AHCI. 2. 4K对齐 第3步,在分区的时 ...
- SharePoint 2013 网站应用程序、网站集、网站知识整理
网站应用程序:Web 应用程序是一种可以通过Web访问的应用程序.我们自己以前用VS开发的Web应用程序一般是通过人工部署到IIS上的,而SharePoint的Web应用程序是由SharePoint安 ...
- P4行为模型BMV2依赖关系安装:thrift nanomsg nnpy安装
由于安装p4factory的步骤需要OF的支持,我需要下载p4的行为模型BMV2: thrift是支持BMV2的软件框架:nanomsg是一个实现了几种"可扩展协议"的高性能通信库 ...
- asp.net identity 2.2.0 在WebForm下的角色启用和基本使用(一)
基本环境:asp.net 4.5.2 仔细看了在Webform下,模板就已经启动了角色控制,已经不用再进行设置了.直接调用相关类就可以了.这和原来在网站根目录下配置Web.config完全不同了. 相 ...