Solr入门之(8)中文分词器配置
Solr中虽然提供了一个中文分词器,但是效果很差,可以使用IKAnalyzer或Mmseg4j 或其他中文分词器。
一、IKAnalyzer分词器配置:
1、下载IKAnalyzer(IKAnalyzer2012_u6)包,当前使用版本IKAnalyzer2012_u6.jar
2、将IKAnalyzer2012_u6包下的IKAnalyzer.cfg.xml和stopword.dic复制到solr应用/WEB-INF/classes下。
3、在${solr_home}/[core路径下]/conf/schema.xml中增加一个自定义fieldType:
<!-- 中文IK分词 -->
<fieldType name="text_ik_analyzer" positionIncrementGap="100" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.solr.IKTokenizerFactory"/>
<filter class="solr.StopFilterFactory" enablePositionIncrements="true" words="stopwords.txt" ignoreCase="true"/>
<filter class="solr.WordDelimiterFilterFactory" splitOnCaseChange="1" catenateAll="0" catenateNumbers="1" catenateWords="1" generateNumberParts="1" generateWordParts="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPorterFilterFactory" protected="protwords.txt"/>
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.solr.IKTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" ignoreCase="true" expand="true" synonyms="synonyms.txt"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/>
<filter class="solr.WordDelimiterFilterFactory" splitOnCaseChange="1" catenateAll="0" catenateNumbers="0" catenateWords="0" generateNumberParts="1" generateWordParts="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPorterFilterFactory" protected="protwords.txt"/>
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
</fieldType>
4、在schema.xml中增加一个字段:
<field name="test_ik_field" type="text_ik_analyzer" indexed="true" stored="true" termVectors="true" termPositions="true" termOffsets="true" />
5、启动solr应用,即可在客户端界面查看分词效果。
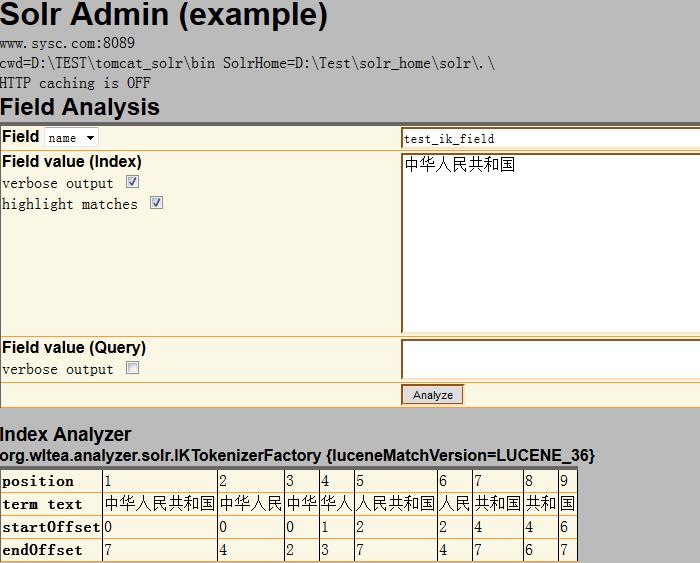
二、Mmseg4j分词器:
配置方式与上面类似,暂时未定义。
Solr入门之(8)中文分词器配置的更多相关文章
- 真分布式SolrCloud+Zookeeper+tomcat搭建、索引Mysql数据库、IK中文分词器配置以及web项目中solr的应用(1)
版权声明:本文为博主原创文章,转载请注明本文地址.http://www.cnblogs.com/o0Iris0o/p/5813856.html 内容介绍: 真分布式SolrCloud+Zookeepe ...
- 2.IKAnalyzer 中文分词器配置和使用
一.配置 IKAnalyzer 中文分词器配置,简单,超简单. IKAnalyzer 中文分词器下载,注意版本问题,貌似出现向下不兼容的问题,solr的客户端界面Logging会提示错误. 给出我配置 ...
- Solr6.5.0配置中文分词器配置
准备工作: solr6.5.0安装成功 1.去官网https://github.com/wks/ik-analyzer下载IK分词器 2.Solr集成IK a)将ik-analyzer-solr6.x ...
- Es学习第五课, 分词器介绍和中文分词器配置
上课我们介绍了倒排索引,在里面提到了分词的概念,分词器就是用来分词的. 分词器是ES中专门处理分词的组件,英文为Analyzer,定义为:从一串文本中切分出一个一个的词条,并对每个词条进行标准化.它由 ...
- 对本地Solr服务器添加IK中文分词器实现全文检索功能
在上一篇随笔中我们提到schema.xml中<field/>元素标签的配置,该标签中有四个属性,分别是name.type.indexed与stored,这篇随笔将讲述通过设置type属性的 ...
- Windows下面安装和配置Solr 4.9(三)支持中文分词器
首先将下载解压后的solr-4.9.0的目录里面F:\tools\开发工具\Lucene\solr-4.9.0\contrib\analysis-extras\lucene-libs找到lucene- ...
- Solr学习笔记之2、集成IK中文分词器
Solr学习笔记之2.集成IK中文分词器 一.下载IK中文分词器 IK中文分词器 此文IK版本:IK Analyer 2012-FF hotfix 1 完整分发包 二.在Solr中集成IK中文分词器 ...
- windows 上配置solr5.2.1+solr4.3+中文分词器
搭建5.2.1 1.下载 Tomcat解压后的目录为 D:\Program Files\Apache Software Foundation\apache-tomcat-8.0.22 solr解压后的 ...
- Solr6.5配置中文分词器
Solr作为搜索应用服务器,我们在使用过程中,不可避免的要使用中文搜索.以下介绍solr自带的中文分词器和第三方分词器IKAnalyzer. 注:下面操作在Linux下执行,所添加的配置在windo ...
随机推荐
- iframe框架中用js改变父级Url
<script type="text/javascript"> var path = window.location.href;//当前也面的跳转 ...
- PHP网页缓存技术
http://blog.sina.com.cn/s/blog_646e51c40100weu9.html 前台静态化:把动态页面解析后保存为静态页面 文件缓存:把查询结果保存为文件,XML 内存缓存: ...
- Redis系列-配置文件小结
如果不指定配置文件,Redis也可以启动,此时,redis使用默认的内置配置.不过在正式环境,常常通过配置文件[通常叫redis.conf]来配置redis. redis.conf配置格式如下: ke ...
- JavaScript——Window对象
1.serTimeout()和setinterval()可用于注册在指定的时间之后单词或者重复调用的函数. 2.window对象的location属性引用的是Location对象,表示该窗口当前显示的 ...
- HTML锚点参考II
锚点使用:<a href="#a">会直接找到id为a的元素的位置,不需要其他设置.如此简单! <a href="#a"> <li ...
- POJ 1308
http://poj.org/problem?id=1308 题意:判断这是不是一棵树. 思路:这个题还是有部分坑点的.首先空树也是一棵树,还有森林不是树. 关于森林的判断我是利用并查集把每一个点压缩 ...
- yii框架详解 之 CWebApplication 运行流程分析
在 程序入口处,index.php 用一句 Yii::createWebApplication($config)->run(); 开始了app的运行. 那么,首先查看 CWebApplicat ...
- FIX_前缀后缀_未提交
问题 B: FIX 时间限制: 1 Sec 内存限制: 64 MB提交: 38 解决: 11[提交][状态][讨论版] 题目描述 如果单词 X 由单词 Y 的前若干个字母构成,我们称 X 是 Y ...
- jQuery中attr()方法用法实例
本文实例讲述了jQuery中attr()方法用法.分享给大家供大家参考.具体分析如下: 此方法设置或返回匹配元素的属性值. attr()方法根据参数的不同,功能也不同. 语法结构一: 获取第一个匹配元 ...
- 【python】 urllib.unquote()
来源:http://blog.csdn.net/anhuidelinger/article/details/10096727 urllib.unquote() 字符串被当作url提交时会被自动进行ur ...