spark HA 安装配置和使用(spark1.2-cdh5.3)
安装环境如下:
- 操作系统:CentOs 6.6
- Hadoop 版本:CDH-5.3.0
- Spark 版本:1.2
集群5个节点 node01~05
node01~03 为worker、 node04、node05为master
spark HA 必须要zookeepr来做协同服务,做master主备切换,zookeeper的安装和配置再次不做赘述。
yum源的配置请看:
1.安装
查看spark的相关包有哪些:
[root@node05 hadoop-yarn]# yum list |grep spark
spark-core.noarch 1.2.0+cdh5.3.0+364-1.cdh5.3.0.p0.36.el6
spark-history-server.noarch 1.2.0+cdh5.3.0+364-1.cdh5.3.0.p0.36.el6
spark-master.noarch 1.2.0+cdh5.3.0+364-1.cdh5.3.0.p0.36.el6
spark-python.noarch 1.2.0+cdh5.3.0+364-1.cdh5.3.0.p0.36.el6
hue-spark.x86_64 3.7.0+cdh5.3.0+134-1.cdh5.3.0.p0.24.el6
spark-worker.noarch 1.2.0+cdh5.3.0+364-1.cdh5.3.0.p0.36.el6
以上包作用如下:
- spark-core: spark 核心功能
- spark-worker: spark-worker 初始化脚本
- spark-master: spark-master 初始化脚本
- spark-python: spark 的 Python 客户端
- hue-spark: spark 和 hue 集成包
- spark-history-server
node04,node05上安装master,node01、node02、node03上安装worker
在node04,node05上运行
sudo yum -y install spark-core spark-master spark-worker spark-python spark-history-server
在node01~03上运行
sudo yum -y install spark-core spark-worker spark-python
node04:spark-master spark-history-server
node05:spark-master
node01:spark-worker
node02:spark-worker
2,修改配置文件
(1)修改配置文件 /etc/spark/conf/spark-env.sh,其内容如下
export SPARK_LAUNCH_WITH_SCALA=0
export SPARK_LIBRARY_PATH=${SPARK_HOME}/lib
export SCALA_LIBRARY_PATH=${SPARK_HOME}/lib
export SPARK_MASTER_WEBUI_PORT=18080
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_PORT=7078
export SPARK_WORKER_WEBUI_PORT=18081
export SPARK_WORKER_DIR=/var/run/spark/work
export SPARK_LOG_DIR=/var/log/spark
export SPARK_PID_DIR='/var/run/spark/'
#采用Zookeeper保证HA,导入相应的环境变量
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node01:2181,node02:2181,node03:2181 -Dspark.deploy.zookeeper.dir=/spark" export JAVA_HOME=/usr/java/jdk1.7.0_71/
#如果是多Master的情况下,不能定义Spark_Master_IP的属性,否则无法启动多个Master,这个属性的定义可以在Application中定义
#export SPARK_MASTER_IP=node04
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
#指定每个Worker需要的内存大小(全局)
export SPARK_WORKER_MEMORY=5g #下面是结合Spark On Yarn方式的集群模式需要配置的,独立集群模式不需要配置
export HADOOP_HOME=/usr/lib/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/Hadoop
#spark on yarn 提交任务时防止找不到resourcemanager :INFO Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1 SECONDS)
export SPARK_YARN_USER_ENV="CLASSPATH=/usr/lib/hadoop"
export SPARK_DAEMON_JAVA_OPTS还可以采用另一种导入方式
#指定Spark恢复模式,这里采用Zookeeper模式,默认为NONE
spark.deploy.recoveryMode ZOOKEEPER
spark.deploy.zookeeper.url node01:2181,node02:2181,node03:2181
spark.deploy.zookeeper.dir /spark
选项:
spark.deploy.recoveryMode NONE 恢复模式(Master重新启动的模式),有三种:1, ZooKeeper, 2, FileSystem, 3 NONE
spark.deploy.zookeeper.url ZooKeeper的Server地址
spark.deploy.zookeeper.dir /spark ZooKeeper 保存集群元数据信息的文件目录,包括Worker,Driver和Application。
(2)修改spark-default.conf (如果没有做下配置,日志将不会持久化,一旦运行完毕后,无法查看日志情况)
在最后增加如下选项
#是否启用事件日志记录
spark.eventLog.enabled true
#Driver任务运行的日志生成目录
spark.eventLog.dir hdfs://mycluster/user/spark/eventslog
#监控页面需要监控的目录,需要先启用和指定事件日志目录,配合上面两项使用
spark.history.fs.logDirectory hdfs://mycluster/user/spark/eventslog
#如果想 YARN ResourceManager 访问 Spark History Server ,则添加一行:
spark.yarn.historyServer.address http://node04:19888
hdfs://mycluster/user/spark/eventslog该目录为HDFS的目录,需要提前创建好,
同时这里用到了HADOOP HA模式的集群名称mycluster,所以我们需要把HADOOP的配置文件hdfs-site.xml复制到Spark的conf目录下,这样就不会报集群名字mycluster找不到的问题
(3)修改slaves
node01
node02
node03
修改完后把配置文件分发到其他节点:
scp -r /etc/spark/conf root@node01:/etc/spark
scp -r /etc/spark/conf root@node02:/etc/spark
scp -r /etc/spark/conf root@node03:/etc/spark
scp -r /etc/spark/conf root@node04:/etc/spark
创建hdfs上的目录;
sudo -u hdfs hadoop fs -mkdir /user/spark
sudo -u hdfs hadoop fs -mkdir /user/spark/eventlog
sudo -u hdfs hadoop fs -chown -R spark:spark /user/spark
sudo -u hdfs hadoop fs -chmod 1777 /user/spark/eventlog
3.启动
进入node05 的spark的sbin目录执行start-all.sh
[root@node05 sbin]# ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /var/log/spark/spark-root-org.apache.spark.deploy.master.Master-1-node05.out
node01: starting org.apache.spark.deploy.worker.Worker, logging to /var/log/spark/spark-root-org.apache.spark.deploy.worker.Worker-1-node01.out
node02: starting org.apache.spark.deploy.worker.Worker, logging to /var/log/spark/spark-root-org.apache.spark.deploy.worker.Worker-1-node02.out
node03: starting org.apache.spark.deploy.worker.Worker, logging to /var/log/spark/spark-root-org.apache.spark.deploy.worker.Worker-1-node03.out
进入node04的sbin目录执行start-master.sh
[root@node04 sbin]# start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /var/log/spark/spark-root-org.apache.spark.deploy.master.Master-1-node04.out
当node05 ALIVE时,node04 standby,node05挂掉时,node04会顶替成为master
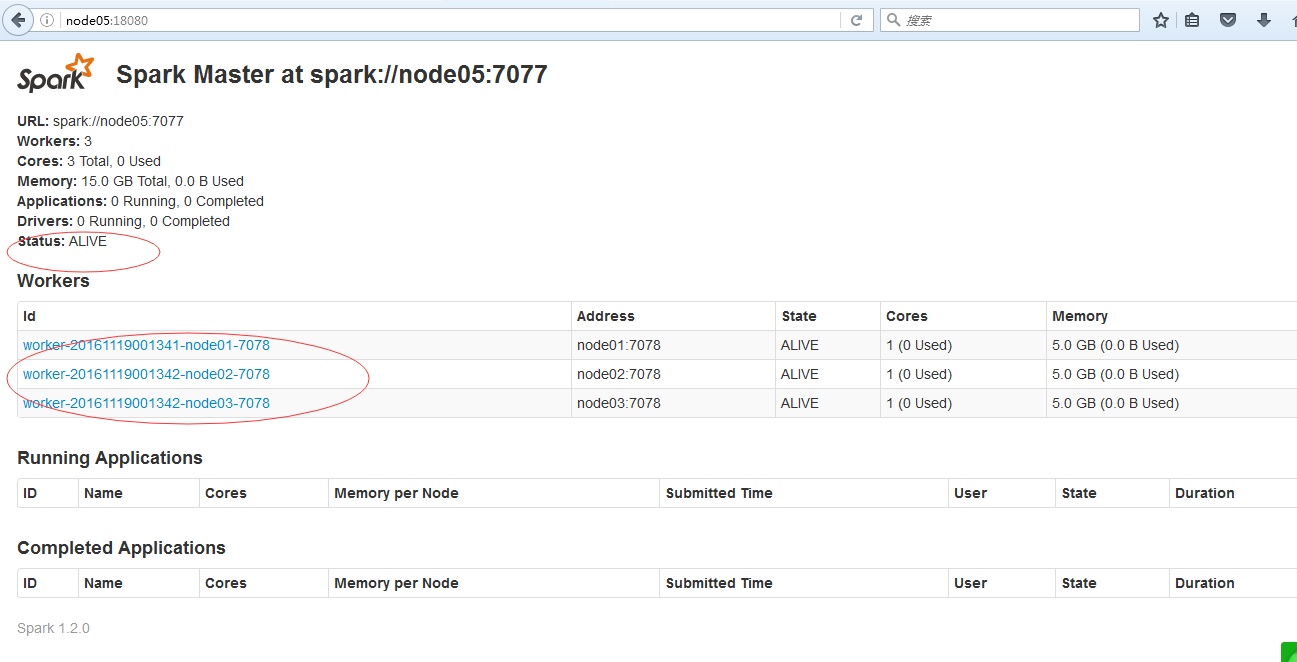
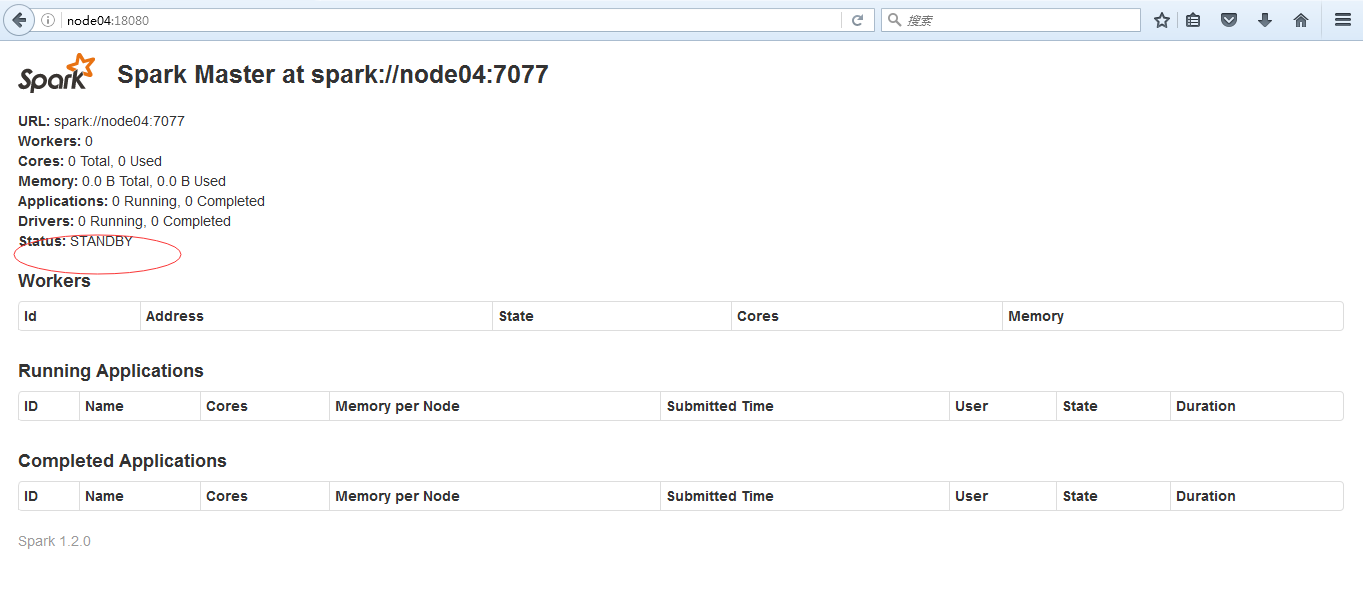
在node05把master停掉
[root@node05 sbin]# ./stop-master.sh
stopping org.apache.spark.deploy.master.Master

此时node04变成alive成为master

4. 测试
4.1 运行测试例子
你可以在官方站点查看官方的例子。 除此之外,Spark 在发布包的 examples 的文件夹中包含了几个例子( Scala、Java、Python)。运行 Java 和 Scala 例子时你可以传递类名给 Spark 的 bin/run-example脚本, 例如:
[root@node02 bin]# run-example SparkPi 10
16/11/19 00:34:51 INFO spark.SparkContext: Spark configuration:
spark.app.name=Spark Pi
spark.deploy.recoveryMode=ZOOKEEPER
spark.deploy.zookeeper.dir=/spark
spark.deploy.zookeeper.url=node01:2181,node02:2181,node03:2181
spark.eventLog.dir=hdfs://mycluster/user/spark/eventlog
spark.eventLog.enabled=true
spark.executor.memory=4g
spark.jars=file:/usr/lib/spark/lib/spark-examples-1.2.0-cdh5.3.0-hadoop2.5.0-cdh5.3.0.jar
spark.logConf=true
spark.master=local[*]
spark.scheduler.mode=FAIR
spark.yarn.historyServer.address=http://node04:19888
spark.yarn.submit.file.replication=3
16/11/19 00:34:51 INFO spark.SecurityManager: Changing view acls to: root
16/11/19 00:34:51 INFO spark.SecurityManager: Changing modify acls to: root
16/11/19 00:34:51 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
16/11/19 00:34:51 INFO slf4j.Slf4jLogger: Slf4jLogger started
16/11/19 00:34:51 INFO Remoting: Starting remoting
16/11/19 00:34:52 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@node02:45368]
16/11/19 00:34:52 INFO Remoting: Remoting now listens on addresses: [akka.tcp://sparkDriver@node02:45368]
16/11/19 00:34:52 INFO util.Utils: Successfully started service 'sparkDriver' on port 45368.
16/11/19 00:34:52 INFO spark.SparkEnv: Registering MapOutputTracker
16/11/19 00:34:52 INFO spark.SparkEnv: Registering BlockManagerMaster
16/11/19 00:34:52 INFO storage.DiskBlockManager: Created local directory at /tmp/spark-local-20161119003452-320d
16/11/19 00:34:52 INFO storage.MemoryStore: MemoryStore started with capacity 265.4 MB
16/11/19 00:34:52 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/11/19 00:34:52 INFO spark.HttpFileServer: HTTP File server directory is /tmp/spark-f91a5447-3d40-4ef8-ba3f-6c4391566017
16/11/19 00:34:52 INFO spark.HttpServer: Starting HTTP Server
16/11/19 00:34:52 INFO server.Server: jetty-8.y.z-SNAPSHOT
16/11/19 00:34:52 INFO server.AbstractConnector: Started SocketConnector@0.0.0.0:46389
16/11/19 00:34:52 INFO util.Utils: Successfully started service 'HTTP file server' on port 46389.
16/11/19 00:34:53 INFO server.Server: jetty-8.y.z-SNAPSHOT
16/11/19 00:34:53 INFO server.AbstractConnector: Started SelectChannelConnector@0.0.0.0:4040
16/11/19 00:34:53 INFO util.Utils: Successfully started service 'SparkUI' on port 4040.
16/11/19 00:34:53 INFO ui.SparkUI: Started SparkUI at http://node02:4040
16/11/19 00:34:53 INFO spark.SparkContext: Added JAR file:/usr/lib/spark/lib/spark-examples-1.2.0-cdh5.3.0-hadoop2.5.0-cdh5.3.0.jar at http://172.16.145.112:46389/jars/spark-examples-1.2.0-cdh5.3.0-hadoop2.5.0-cdh5.3.0.jar with timestamp 1479486893473
16/11/19 00:34:53 INFO scheduler.FairSchedulableBuilder: Created default pool default, schedulingMode: FIFO, minShare: 0, weight: 1
16/11/19 00:34:53 INFO util.AkkaUtils: Connecting to HeartbeatReceiver: akka.tcp://sparkDriver@node02:45368/user/HeartbeatReceiver
16/11/19 00:34:53 INFO netty.NettyBlockTransferService: Server created on 37623
16/11/19 00:34:53 INFO storage.BlockManagerMaster: Trying to register BlockManager
16/11/19 00:34:53 INFO storage.BlockManagerMasterActor: Registering block manager localhost:37623 with 265.4 MB RAM, BlockManagerId(<driver>, localhost, 37623)
16/11/19 00:34:53 INFO storage.BlockManagerMaster: Registered BlockManager
16/11/19 00:34:54 WARN shortcircuit.DomainSocketFactory: The short-circuit local reads feature cannot be used because libhadoop cannot be loaded.
16/11/19 00:34:54 INFO scheduler.EventLoggingListener: Logging events to hdfs://mycluster/user/spark/eventlog/local-1479486893516
16/11/19 00:34:55 INFO spark.SparkContext: Starting job: reduce at SparkPi.scala:35
16/11/19 00:34:55 INFO scheduler.DAGScheduler: Got job 0 (reduce at SparkPi.scala:35) with 10 output partitions (allowLocal=false)
16/11/19 00:34:55 INFO scheduler.DAGScheduler: Final stage: Stage 0(reduce at SparkPi.scala:35)
16/11/19 00:34:55 INFO scheduler.DAGScheduler: Parents of final stage: List()
16/11/19 00:34:55 INFO scheduler.DAGScheduler: Missing parents: List()
16/11/19 00:34:55 INFO scheduler.DAGScheduler: Submitting Stage 0 (MappedRDD[1] at map at SparkPi.scala:31), which has no missing parents
16/11/19 00:34:55 INFO storage.MemoryStore: ensureFreeSpace(1728) called with curMem=0, maxMem=278302556
16/11/19 00:34:55 INFO storage.MemoryStore: Block broadcast_0 stored as values in memory (estimated size 1728.0 B, free 265.4 MB)
16/11/19 00:34:55 INFO storage.MemoryStore: ensureFreeSpace(1126) called with curMem=1728, maxMem=278302556
16/11/19 00:34:55 INFO storage.MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1126.0 B, free 265.4 MB)
16/11/19 00:34:55 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:37623 (size: 1126.0 B, free: 265.4 MB)
16/11/19 00:34:55 INFO storage.BlockManagerMaster: Updated info of block broadcast_0_piece0
16/11/19 00:34:55 INFO spark.SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:838
16/11/19 00:34:55 INFO scheduler.DAGScheduler: Submitting 10 missing tasks from Stage 0 (MappedRDD[1] at map at SparkPi.scala:31)
16/11/19 00:34:55 INFO scheduler.TaskSchedulerImpl: Adding task set 0.0 with 10 tasks
16/11/19 00:34:55 INFO scheduler.FairSchedulableBuilder: Added task set TaskSet_0 tasks to pool default
16/11/19 00:34:55 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, PROCESS_LOCAL, 1357 bytes)
16/11/19 00:34:55 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, PROCESS_LOCAL, 1357 bytes)
16/11/19 00:34:55 INFO scheduler.TaskSetManager: Starting task 2.0 in stage 0.0 (TID 2, localhost, PROCESS_LOCAL, 1357 bytes)
16/11/19 00:34:55 INFO scheduler.TaskSetManager: Starting task 3.0 in stage 0.0 (TID 3, localhost, PROCESS_LOCAL, 1357 bytes)
16/11/19 00:34:55 INFO executor.Executor: Running task 1.0 in stage 0.0 (TID 1)
16/11/19 00:34:55 INFO executor.Executor: Running task 0.0 in stage 0.0 (TID 0)
16/11/19 00:34:55 INFO executor.Executor: Running task 3.0 in stage 0.0 (TID 3)
16/11/19 00:34:55 INFO executor.Executor: Running task 2.0 in stage 0.0 (TID 2)
16/11/19 00:34:55 INFO executor.Executor: Fetching http://172.16.145.112:46389/jars/spark-examples-1.2.0-cdh5.3.0-hadoop2.5.0-cdh5.3.0.jar with timestamp 1479486893473
16/11/19 00:34:55 INFO util.Utils: Fetching http://172.16.145.112:46389/jars/spark-examples-1.2.0-cdh5.3.0-hadoop2.5.0-cdh5.3.0.jar to /tmp/fetchFileTemp1952931669628282908.tmp
16/11/19 00:34:56 INFO executor.Executor: Adding file:/tmp/spark-a281a361-04d2-495d-bfa7-ccd2a9c9a2ac/spark-examples-1.2.0-cdh5.3.0-hadoop2.5.0-cdh5.3.0.jar to class loader
16/11/19 00:34:56 INFO executor.Executor: Finished task 1.0 in stage 0.0 (TID 1). 727 bytes result sent to driver
16/11/19 00:34:56 INFO executor.Executor: Finished task 3.0 in stage 0.0 (TID 3). 727 bytes result sent to driver
16/11/19 00:34:56 INFO scheduler.TaskSetManager: Starting task 4.0 in stage 0.0 (TID 4, localhost, PROCESS_LOCAL, 1357 bytes)
16/11/19 00:34:56 INFO executor.Executor: Running task 4.0 in stage 0.0 (TID 4)
16/11/19 00:34:56 INFO executor.Executor: Finished task 0.0 in stage 0.0 (TID 0). 727 bytes result sent to driver
16/11/19 00:34:56 INFO scheduler.TaskSetManager: Starting task 5.0 in stage 0.0 (TID 5, localhost, PROCESS_LOCAL, 1357 bytes)
16/11/19 00:34:56 INFO executor.Executor: Running task 5.0 in stage 0.0 (TID 5)
16/11/19 00:34:56 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 727 ms on localhost (1/10)
16/11/19 00:34:56 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 747 ms on localhost (2/10)
16/11/19 00:34:56 INFO scheduler.TaskSetManager: Finished task 3.0 in stage 0.0 (TID 3) in 734 ms on localhost (3/10)
16/11/19 00:34:56 INFO scheduler.TaskSetManager: Starting task 6.0 in stage 0.0 (TID 6, localhost, PROCESS_LOCAL, 1357 bytes)
16/11/19 00:34:56 INFO executor.Executor: Running task 6.0 in stage 0.0 (TID 6)
16/11/19 00:34:56 INFO executor.Executor: Finished task 4.0 in stage 0.0 (TID 4). 727 bytes result sent to driver
16/11/19 00:34:56 INFO executor.Executor: Finished task 2.0 in stage 0.0 (TID 2). 727 bytes result sent to driver
16/11/19 00:34:56 INFO scheduler.TaskSetManager: Starting task 7.0 in stage 0.0 (TID 7, localhost, PROCESS_LOCAL, 1357 bytes)
16/11/19 00:34:56 INFO executor.Executor: Running task 7.0 in stage 0.0 (TID 7)
16/11/19 00:34:56 INFO scheduler.TaskSetManager: Starting task 8.0 in stage 0.0 (TID 8, localhost, PROCESS_LOCAL, 1357 bytes)
16/11/19 00:34:56 INFO executor.Executor: Running task 8.0 in stage 0.0 (TID 8)
16/11/19 00:34:56 INFO scheduler.TaskSetManager: Finished task 4.0 in stage 0.0 (TID 4) in 60 ms on localhost (4/10)
16/11/19 00:34:56 INFO scheduler.TaskSetManager: Finished task 2.0 in stage 0.0 (TID 2) in 762 ms on localhost (5/10)
16/11/19 00:34:56 INFO executor.Executor: Finished task 5.0 in stage 0.0 (TID 5). 727 bytes result sent to driver
16/11/19 00:34:56 INFO scheduler.TaskSetManager: Starting task 9.0 in stage 0.0 (TID 9, localhost, PROCESS_LOCAL, 1357 bytes)
16/11/19 00:34:56 INFO scheduler.TaskSetManager: Finished task 5.0 in stage 0.0 (TID 5) in 59 ms on localhost (6/10)
16/11/19 00:34:56 INFO executor.Executor: Running task 9.0 in stage 0.0 (TID 9)
16/11/19 00:34:56 INFO executor.Executor: Finished task 8.0 in stage 0.0 (TID 8). 727 bytes result sent to driver
16/11/19 00:34:56 INFO scheduler.TaskSetManager: Finished task 8.0 in stage 0.0 (TID 8) in 113 ms on localhost (7/10)
16/11/19 00:34:56 INFO executor.Executor: Finished task 6.0 in stage 0.0 (TID 6). 727 bytes result sent to driver
16/11/19 00:34:56 INFO scheduler.TaskSetManager: Finished task 6.0 in stage 0.0 (TID 6) in 134 ms on localhost (8/10)
16/11/19 00:34:56 INFO executor.Executor: Finished task 9.0 in stage 0.0 (TID 9). 727 bytes result sent to driver
16/11/19 00:34:56 INFO scheduler.TaskSetManager: Finished task 9.0 in stage 0.0 (TID 9) in 136 ms on localhost (9/10)
16/11/19 00:34:56 INFO executor.Executor: Finished task 7.0 in stage 0.0 (TID 7). 727 bytes result sent to driver
16/11/19 00:34:56 INFO scheduler.TaskSetManager: Finished task 7.0 in stage 0.0 (TID 7) in 157 ms on localhost (10/10)
16/11/19 00:34:56 INFO scheduler.DAGScheduler: Stage 0 (reduce at SparkPi.scala:35) finished in 0.933 s
16/11/19 00:34:56 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool default
16/11/19 00:34:56 INFO scheduler.DAGScheduler: Job 0 finished: reduce at SparkPi.scala:35, took 1.468791 s
Pi is roughly 3.142804
16/11/19 00:34:56 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/stages/stage/kill,null}
16/11/19 00:34:56 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/,null}
16/11/19 00:34:56 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/static,null}
16/11/19 00:34:56 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/executors/threadDump/json,null}
16/11/19 00:34:56 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/executors/threadDump,null}
16/11/19 00:34:56 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/executors/json,null}
16/11/19 00:34:56 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/executors,null}
16/11/19 00:34:56 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/environment/json,null}
16/11/19 00:34:56 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/environment,null}
16/11/19 00:34:56 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/storage/rdd/json,null}
16/11/19 00:34:56 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/storage/rdd,null}
16/11/19 00:34:56 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/storage/json,null}
16/11/19 00:34:56 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/storage,null}
16/11/19 00:34:56 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/stages/pool/json,null}
16/11/19 00:34:56 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/stages/pool,null}
16/11/19 00:34:56 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/stages/stage/json,null}
16/11/19 00:34:56 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/stages/stage,null}
16/11/19 00:34:56 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/stages/json,null}
16/11/19 00:34:56 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/stages,null}
16/11/19 00:34:56 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/jobs/job/json,null}
16/11/19 00:34:56 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/jobs/job,null}
16/11/19 00:34:56 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/jobs/json,null}
16/11/19 00:34:56 INFO handler.ContextHandler: stopped o.e.j.s.ServletContextHandler{/jobs,null}
16/11/19 00:34:56 INFO ui.SparkUI: Stopped Spark web UI at http://node02:4040
16/11/19 00:34:56 INFO scheduler.DAGScheduler: Stopping DAGScheduler
16/11/19 00:34:57 INFO spark.MapOutputTrackerMasterActor: MapOutputTrackerActor stopped!
16/11/19 00:34:57 INFO storage.MemoryStore: MemoryStore cleared
16/11/19 00:34:57 INFO storage.BlockManager: BlockManager stopped
16/11/19 00:34:57 INFO storage.BlockManagerMaster: BlockManagerMaster stopped
16/11/19 00:34:57 INFO remote.RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.
16/11/19 00:34:57 INFO remote.RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports.
16/11/19 00:34:57 INFO spark.SparkContext: Successfully stopped SparkContext
16/11/19 00:34:57 INFO Remoting: Remoting shut down
16/11/19 00:34:57 INFO remote.RemoteActorRefProvider$RemotingTerminator: Remoting shut down.
通过 Python API 来运行交互模式:
# 使用2个 Worker 线程本地化运行 Spark(理想情况下,该值应该根据运行机器的 CPU 核数设定)
[root@node02 bin]# pyspark --master local[2]
Python 2.6.6 (r266:84292, Jan 22 2014, 09:42:36)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-4)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
16/11/19 00:38:55 INFO spark.SparkContext: Spark configuration:
spark.app.name=PySparkShell
spark.deploy.recoveryMode=ZOOKEEPER
spark.deploy.zookeeper.dir=/spark
spark.deploy.zookeeper.url=node01:2181,node02:2181,node03:2181
spark.eventLog.dir=hdfs://mycluster/user/spark/eventlog
spark.eventLog.enabled=true
spark.executor.memory=4g
spark.logConf=true
spark.master=local[2]
spark.rdd.compress=True
spark.scheduler.mode=FAIR
spark.serializer.objectStreamReset=100
spark.yarn.historyServer.address=http://node04:19888
spark.yarn.submit.file.replication=3
16/11/19 00:38:55 INFO spark.SecurityManager: Changing view acls to: root
16/11/19 00:38:55 INFO spark.SecurityManager: Changing modify acls to: root
16/11/19 00:38:55 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
16/11/19 00:38:56 INFO slf4j.Slf4jLogger: Slf4jLogger started
16/11/19 00:38:56 INFO Remoting: Starting remoting
16/11/19 00:38:56 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@node02:47345]
16/11/19 00:38:56 INFO Remoting: Remoting now listens on addresses: [akka.tcp://sparkDriver@node02:47345]
16/11/19 00:38:56 INFO util.Utils: Successfully started service 'sparkDriver' on port 47345.
16/11/19 00:38:56 INFO spark.SparkEnv: Registering MapOutputTracker
16/11/19 00:38:56 INFO spark.SparkEnv: Registering BlockManagerMaster
16/11/19 00:38:56 INFO storage.DiskBlockManager: Created local directory at /tmp/spark-local-20161119003856-0d19
16/11/19 00:38:56 INFO storage.MemoryStore: MemoryStore started with capacity 265.4 MB
16/11/19 00:38:57 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/11/19 00:38:57 INFO spark.HttpFileServer: HTTP File server directory is /tmp/spark-7d1a1480-43a8-4195-a1f1-3909f5c8d02b
16/11/19 00:38:57 INFO spark.HttpServer: Starting HTTP Server
16/11/19 00:38:57 INFO server.Server: jetty-8.y.z-SNAPSHOT
16/11/19 00:38:57 INFO server.AbstractConnector: Started SocketConnector@0.0.0.0:56686
16/11/19 00:38:57 INFO util.Utils: Successfully started service 'HTTP file server' on port 56686.
16/11/19 00:38:57 INFO server.Server: jetty-8.y.z-SNAPSHOT
16/11/19 00:38:57 INFO server.AbstractConnector: Started SelectChannelConnector@0.0.0.0:4040
16/11/19 00:38:57 INFO util.Utils: Successfully started service 'SparkUI' on port 4040.
16/11/19 00:38:57 INFO ui.SparkUI: Started SparkUI at http://node02:4040
16/11/19 00:38:57 INFO scheduler.FairSchedulableBuilder: Created default pool default, schedulingMode: FIFO, minShare: 0, weight: 1
16/11/19 00:38:57 INFO util.AkkaUtils: Connecting to HeartbeatReceiver: akka.tcp://sparkDriver@node02:47345/user/HeartbeatReceiver
16/11/19 00:38:58 INFO netty.NettyBlockTransferService: Server created on 49996
16/11/19 00:38:58 INFO storage.BlockManagerMaster: Trying to register BlockManager
16/11/19 00:38:58 INFO storage.BlockManagerMasterActor: Registering block manager localhost:49996 with 265.4 MB RAM, BlockManagerId(<driver>, localhost, 49996)
16/11/19 00:38:58 INFO storage.BlockManagerMaster: Registered BlockManager
16/11/19 00:38:59 WARN shortcircuit.DomainSocketFactory: The short-circuit local reads feature cannot be used because libhadoop cannot be loaded.
16/11/19 00:38:59 INFO scheduler.EventLoggingListener: Logging events to hdfs://mycluster/user/spark/eventlog/local-1479487137931
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 1.2.0
/_/ Using Python version 2.6.6 (r266:84292, Jan 22 2014 09:42:36)
SparkContext available as sc.
>>>
你也可以运行 Python 编写的应用:
$ mkdir -p /usr/lib/spark/examples/python
$ tar zxvf /usr/lib/spark/lib/python.tar.gz -C /usr/lib/spark/examples/python
$ ./bin/spark-submit examples/python/pi.py 10
另外,你还可以运行 spark shell 的交互模式:
# 使用2个 Worker 线程本地化运行 Spark(理想情况下,该值应该根据运行机器的 CPU 核数设定)
$ ./bin/spark-shell --master local[2] Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ `_/
/___/ .__/\_,_/_/ /_/\_\ version 1.2.0
/_/ Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Type :help for more information. Spark context available as sc. scala> val lines = sc.textFile("data.txt")
scala> val lineLengths = lines.map(s => s.length)
scala> val totalLength = lineLengths.reduce((a, b) => a + b)
上面是一个 RDD 的示例程序,从一个外部文件创建了一个基本的 RDD对象。如果想运行这段程序,请确保 data.txt 文件在当前目录中存在。
4.2 在集群上运行
Standalone 模式
该模式下只需在一个节点上安装 spark 的相关组件即可。通过 spark-shel l 运行下面的 wordcount 例子,
读取 hdfs 的一个例子: $ echo "hello world" >test.txt
$ hadoop fs -put test.txt /tmp $ spark-shell
scala> val file = sc.textFile("hdfs://mycluster/tmp/test.txt")
scala> file.count()
更复杂的一个例子,运行 mapreduce 统计单词数:
$ spark-shell
scala> val file = sc.textFile("hdfs://mycluster/tmp/test.txt")
scala> val counts = file.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
scala> counts.saveAsTextFile("hdfs://mycluster/tmp/output")
运行完成之后,你可以查看 hdfs://mycluster/tmp/output 目录下的文件内容
[root@node01 spark]# hadoop fs -cat /tmp/output/part-00000
(hello,1)
(world,1)
另外,spark-shell 后面还可以加上其他参数,例如:连接指定的 master、运行核数等等:
$ spark-shell --master spark://node04:7077 --cores 2
scala>
也可以增加 jar:
$ spark-shell --master spark://node04:7077 --cores 2 --jars code.jar
scala>
运行 spark-shell --help 可以查看更多的参数。
另外,也可以使用 spark-submit 以 Standalone 模式运行 SparkPi 程序:
$ spark-submit --class org.apache.spark.examples.SparkPi --deploy-mode client --master spark://node04:7077 /usr/lib/spark/lib/spark-examples-1.2.0-cdh5.3.0-hadoop2.5.0-cdh5.3.0.jar 10
Spark on Yarn
以 YARN 客户端方式运行 SparkPi 程序:
spark-submit --class org.apache.spark.examples.SparkPi --deploy-mode client --master yarn /usr/lib/spark/lib/spark-examples-1.2.0-cdh5.3.0-hadoop2.5.0-cdh5.3.0.jar 10
以 YARN 集群方式运行 SparkPi 程序:
spark-submit --class org.apache.spark.examples.SparkPi --deploy-mode cluster --master yarn /usr/lib/spark/lib/spark-examples-1.2.0-cdh5.3.0-hadoop2.5.0-cdh5.3.0.jar 10
运行在 YARN 集群之上的时候,可以手动把 spark-assembly 相关的 jar 包拷贝到 hdfs 上去,然后设置 SPARK_JAR 环境变量:
$ hdfs dfs -mkdir -p /user/spark/share/lib
$ hdfs dfs -put $SPARK_HOME/lib/spark-assembly.jar /user/spark/share/lib/spark-assembly.jar $ SPARK_JAR=hdfs://<nn>:<port>/user/spark/share/lib/spark-assembly.jar
参考:http://blog.csdn.net/furenjievip/article/details/44003467
http://blog.csdn.net/durie_/article/details/50789560
spark HA 安装配置和使用(spark1.2-cdh5.3)的更多相关文章
- Spark HA 配置中spark.deploy.zookeeper.url 的意思
Spark HA的配置网上很多,最近我在看王林的Spark的视频,要付费的.那个人牛B吹得很大,本事应该是有的,但是有本事,不一定就是好老师.一开始吹中国第一,吹着吹着就变成世界第一.就算你真的是世界 ...
- Spark_安装配置_运行模式
一.Spark支持的安装模式: 1.伪分布式(一台机器即可) 2.全分布式(至少需要3台机器) 二.Spark的安装配置 1.准备工作 安装Linux和JDK1.8 配置Linux:关闭防火墙.主机名 ...
- 安装spark ha集群
安装spark ha集群 1.默认安装好hadoop+zookeeper 2.安装scala 1.解压安装包 tar zxvf scala-2.11.7.tgz 2.配置环境变量 vim /etc/p ...
- Hive on Spark安装配置详解(都是坑啊)
个人主页:http://www.linbingdong.com 简书地址:http://www.jianshu.com/p/a7f75b868568 简介 本文主要记录如何安装配置Hive on Sp ...
- Mac 配置Spark环境scala+python版本(Spark1.6.0)
1. 从官网下载Spark安装包,解压到自己的安装目录下(默认已经安装好JDK,JDK安装可自行查找): spark官网:http://spark.apache.org/downloads.html ...
- Spark standlone安装与配置
spark的安装简单,去官网下载与集群hadoop版本相一致的文件即可. 解压后,主要需要修改spark-evn.sh文件. 以spark standlone为例,配置dn1,nn2为master,使 ...
- 最新版spark1.1.0集群安装配置
和分布式文件系统和NoSQL数据库相比而言,spark集群的安装配置还算是比较简单的: 很多教程提到要安装java和scala,但我发现spark最新版本是包含scala的,JRE采用linux内嵌的 ...
- spark集群安装配置
spark集群安装配置 一. Spark简介 Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发.Spark基于map reduce 算法模式实现的分布式计算,拥有Hadoo ...
- spark 安装配置
最佳参考链接 https://opensourceteam.gitbooks.io/bigdata/content/spark/install/spark-160-bin-hadoop26an_zhu ...
随机推荐
- 查看sid
查看用户sid: whoami /user 查看系统sid: 使用PSTools工具中的 psgetsid.exe命令查看
- 记一次Time-Wait导致的问题
去年(2014年)公司决定服务框架改用Finagle(后续文章详细介绍),but 公司业务系统大部分是C#写的,然后 finagle只提供了 scala/java 的Client 于是 只能自己动手丰 ...
- 兼容,原来在这里就已经開始--------Day34
看了两天,算是将w3cschool的javascript部分浏览了一遍.在脑海中大约有了一点概念,也才真切体会到:一入江湖深似海.欲穷此路难上难啊,至少如今看起来是遥遥无期.太多不懂, 太多茫然,只是 ...
- 一个简单的弹出层ProgressBar
https://github.com/eltld/SimpleLoading
- [终极精简版][图解]Nginx搭建flv mp4流媒体服务器
花了我接近3周,历经了重重问题,今日终于把流媒体服务器搞定,赶紧的写个博文以免忘记... 起初是跟着网上的一些教程来的,但是说的很不全面,一些东西也过时不用了(比如jwplayer老版本).我这次是用 ...
- [Express] Level 3: Massaging User Data
Flexible Routes Our current route only works when the city name argument matches exactly the propert ...
- poj 3249 Test for Job (DAG最长路 记忆化搜索解决)
Test for Job Time Limit: 5000MS Memory Limit: 65536K Total Submissions: 8990 Accepted: 2004 Desc ...
- 设计模式 ( 十八 ) 策略模式Strategy(对象行为型)
设计模式 ( 十八 ) 策略模式Strategy(对象行为型) 1.概述 在软件开发中也经常遇到类似的情况,实现某一个功能有多种算法或者策略,我们能够依据环境或者条件的不同选择不同的算法或者策略来完毕 ...
- [原创]SQL Server 阻止了对组件 'Ad Hoc Distributed Queries' 的 STATEMENT 'OpenRowset/OpenDatasource' 的访问
TSQL查询Excel数据使用openrowset通常会报如下错误: 消息 ,级别 ,状态 ,第 行 SQL Server 阻止了对组件 'Ad Hoc Distributed Queries' 的 ...
- Cannot instantiate the type HttpClient问题
看自己动手写爬虫,没想到一上来就跪了. 里面提到用的jar包是apache的http客户端开源项目---HttpClient 就去官网下载了一个版本4.3 当按书上代码敲时 HttpClient ht ...