Kafka分布式消息模型
Kafka开发的主要初衷目标是构建一个用来处理海量日志,用户行为和网站运营统计等的数据处理框架。在结合了数据挖掘,行为分析,运营监控等需求的情况下,需要能够满足各种实时在线和批量离线处理应用场合对低延迟和批量吞吐性能的要求。从需求的根本上来说,高吞吐率是第一要求,其次是实时性和持久性。
既有的消息队列框架或者对消息传送的可靠性提供了较高的保证,由此带来较大的负担,不能满足海量高吞吐率的要求;或者完全面向实时消息处理系统,对于批量离线处理的场合无法提供足够的缓存和持久性要求。
而多数针对大数据开发应用的日志收集处理系统(e.g. scribe, flume)则通常更适合批量离线处理场合,对实时在线处理的场合支持不够。
总体而言,Kafka试图提供一个同时满足在线和离线处理海量数据的消息派发系统。
一、Kafka的实现
Kafka的集群有多个Broker服务器组成,每个类型的消息被定义为topic,同一topic内部的消息按照一定的key和算法被分区(partition)存储在不同的Broker上,消息生产者producer和消费者consumer可以在多个Broker上生产/消费topic.
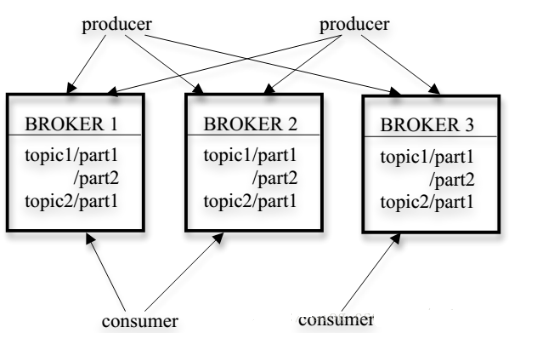
核心思想:以高效率作为第一设计原则,Kafka的结构设计在很多方面都做了激进的取舍.
Topic
Topic是生产者生产、消费者消费的队列标识。一个Topic由一个或多个partition组成,每个partition可以单独存在一个broker上,消费者可以往任一partition发送消息,以此实现生产的分布式,任一partition都可以被且只被一个消费者消息,以此实现消费的分布式;因此partition的设计提供了分布式的基础。

同时,从上图我们也能发现这种设计还有一个优点,因为每个partition内的消息是有序的,而一个partition只能被一个消费者消费,因此Kafka能提供partition层面的消息有序,而传统的队列在多个consumer的情况下是完全无法保证有序的。
1、极简的数据结构和应用模式

消息队列是以log文件的形式存储,消息生产者只能将消息添加到既有的文件尾部,没有任何ID信息用于消息的定位,完全依靠文件内的位移,因此消息的使用者只能依靠文件位移顺序读取消息,这样也就不需要维护复杂的支持随即读取的索引结构。
Kafka broker完全不维护和协调多用户使用消息的行为模式,用户自己维护位移用来索引消息。
最小的并发访问单位就是partition分区,同一用户组内的所有用户(可以理解为同一个应用的所有并发进程)只能有一个访问同一分区,同时分区的个数是固定的,不支持动态调整。这样最大简化了多进程/分布式client之间对消息处理访问的并发控制的复杂度,当然也带来一定的使用模式上的限制(比如最大并发度完全取决于预先规划的partition的个数)
此外分区也带来一个问题就是消息只是分区内部有序而不是全局有序的。如果需要全局有序,应用需要自己靠别的机制来保证。
使用Pull模式派发消息,消息的使用情况,比如是否还有consumer没有读取,是否重复读取(改进中)等,在Broker端也完全不跟踪维护,消息的过期处理简单的由定时器定时删除(比如保留7天),由此简化各种消息跟踪维护的开销。
2、采取各种方式最大化数据传输效率
比如生产者和消费者可以批量读写消息减少RPC开销。使用Zero Copy方式在内核层直接将文件内容传送给网络Socket,避免应用层数据拷贝,使用合理的压缩格式等
3、激进的内存管理模式
基本的意思就是不管理。Kafka不在JVM进程内部维护消息Cache,消息直接从文件中读写,完全依赖操作系统在文件系统层面的cache,避免在JVM中管理Cache带来的额外数据结构开销和GC带来的性能代价。基于批量处理和顺序读写的应用模式,最大化利用文件系统的Cache机制和规避文件读写相对内存读写的性能代价
4、HA
Kafka在0.8之前message是没有备份容错机制的,producer的工作模式是fire and forget,如果一个broker失效,那么相关topic分区的相关消息也就丢失了。这种设计的原因在于最初的应用模式,如日志/用户行为等消息的处理,对数据的健壮性方面要求不高,可以容忍部分数据的缺失。采用fire and forget 模式,不需要等待Broker ack,有利于提高producer的吞吐率。
不过在0.8版本中,添加了数据replica的机制,一个消息分区的多个replica分布在不同的Broker上,由leader replica负责日常读写,通过zookeeper监督failover,不同的分区的leader replica均衡负载到不同的Broker上。在这种情况下,producer可以选择不等待leader replica的Ack,部分Ack,或者完全备份完毕后Ack等不同的ack机制。这三种机制,性能依次递减 (producer吞吐量降低1-3倍),数据健壮性则依次递增。
Kafka分布式消息模型的更多相关文章
- Kafka——分布式消息系统
Kafka——分布式消息系统 架构 Apache Kafka是2010年12月份开源的项目,采用scala语言编写,使用了多种效率优化机制,整体架构比较新颖(push/pull),更适合异构集群. 设 ...
- 【转】快速理解Kafka分布式消息队列框架
from:http://blog.csdn.net/colorant/article/details/12081909 快速理解Kafka分布式消息队列框架 标签: kafkamessage que ...
- Kafka 分布式消息队列介绍
Kafka 分布式消息队列 类似产品有JBoss.MQ 一.由Linkedln 开源,使用scala开发,有如下几个特点: (1)高吞吐 (2)分布式 (3)支持多语言客户端 (C++.Java) 二 ...
- KAFKA分布式消息系统[转]
KAFKA分布式消息系统 转自:http://blog.chinaunix.net/uid-20196318-id-2420884.html Kafka[1]是linkedin用于日志处理的分布式消 ...
- Kafka分布式消息队列
基本架构 Kafka分布式消息队列的作用: 解耦:将消息生产阶段和处理阶段拆分开,两个阶段互相独立各自实现自己的处理逻辑,通过Kafka提供的消息写入和消费接口实现对消息的连接处理.降低开发复杂度,提 ...
- 在Centos 7上安装配置 Apche Kafka 分布式消息系统集群
Apache Kafka是一种颇受欢迎的分布式消息代理系统,旨在有效地处理大量的实时数据.Kafka集群不仅具有高度可扩展性和容错性,而且与其他消息代理(如ActiveMQ和RabbitMQ)相比,还 ...
- KAFKA分布式消息系统
2015-01-05 大数据平台 Hadoop大数据平台 基本概念 kafka的工作方式和其他MQ基本相同,只是在一些名词命名上有些不同.为了更好的讨论,这里对这些名词做简单解释.通过这些解释应该可以 ...
- [转载] KAFKA分布式消息系统
转载自http://blog.chinaunix.net/uid-20196318-id-2420884.html Kafka[1]是linkedin用于日志处理的分布式消息队列,linkedin的日 ...
- 【转】KAFKA分布式消息系统
Kafka[1]是linkedin用于日志处理的分布式消息队列,linkedin的日志数据容量大,但对可靠性要求不高,其日志数据主要包括用户行为(登录.浏览.点击.分享.喜欢)以及系统运行日志(CPU ...
随机推荐
- DBMS_ERRLOG记录DML错误日志(一)
当一个DML运行的时候,如果遇到了错误,则这条语句会整个回滚,就好像没有执行过.不过对于一个大的DML而言,如果个别数据错误而导致整个语句的回滚,会浪费很多的资源和运行时间,从10g开始Oracle支 ...
- MSSQL导入数据时,出现“无法截断表 因为表正由Foreign key引用”错误
* 错误 0xc002f210: 准备 SQL 任务: 执行查询“TRUNCATE TABLE [dsc100552_db].[dbo].[ALV_SalesBigClass] ”失败,错误如下:“无 ...
- NET程序的破解--静态分析(Xenocode Fox 2006 Evaluation)
NET程序已经红红火火的兴起,就象LINUX一样势不可挡的涌来.作为一名Cracker,你会选择躲避吗?嘿嘿,对俺而言,挑战更富有趣味. 破解好几个.NET的程序了,一直想写出来,只是时间问题,所以拖 ...
- .Net 代码安全保护产品DNGuard HVM使用
前辈人物写的程序啊! 官方网站:http://www.dnguard.net/index.aspx 官方博客:http://www.cnblogs.com/rick/ (很久没更新了) 原文http: ...
- arcgis下载
你懂的~ t.cn/RA4cc3k 密码ygdr 包含10.2全部,含有(亲测)字样表示测试过OK的,SP是从esri网站下载的几乎全部patch和sp,包括desktop.engine和sever: ...
- Nuget~让包包带上自己的配置信息
我们知道一般开发组件之后,组件都有相关配置项,最常见的作法就是把它写到web.config里,而如果你将这个文件直接放到nuget里打包,在进行安装包包时,会提示你这个文件已经存在,不能去覆盖原来的c ...
- 根据字符串创建FTP本地目录 并按照日期建立子目录返回路径
/** * 根据字符串创建FTP本地目录 并按照日期建立子目录返回 * @param path * @return */ private String getFolder(String path) { ...
- GB2312 Unicode转换表实现跨平台utf8转码unicode
在GSM模块中,为发送中文短信,采用pdu发送,需要unicode编码.源程序编辑软件将中文转化为GB2312编码,再下列的GB2312 Unicode转换表转为unicode. 实现2维数值,GB2 ...
- delphi 11 编辑模式 浏览模式
编辑模式 浏览模式 设置焦点 //在使用前需要Webbrowser已经浏览过一个网页 否则错误 uses MSHTML; ///获取Webbrowser编辑模式里面的内容procedure EditM ...
- iOS开发——实用篇&提高iOS开发效率的方法和工具
提高iOS开发效率的方法和工具 介绍 这篇文章主要是介绍一下我在iOS开发中使用到的一些可以提升开发效率的方法和工具. IDE 首先要说的肯定是IDE了,说到IDE,Xcode不能跑,当然你也可能同时 ...