十三:Transparent Encryption in HDFS(转)
透明加密:http://blog.csdn.net/linlinv3/article/details/44963429
hadoop透明加密 kms
HDFS 实现透明,端到端加密。配置完成后,用户往hdfs上存储数据的时候,无需用户做任何程序代码的更改(意思就是调用KeyProvider API ,用于在数据存入到HDFS上面的时候进行数据加密,解密的过程一样)。这意味着数据加密和解密由客户端完成的。HDFS 不会存储或访问未加密的数据或数据加密密钥(由kms管理)。
连接地址:
背景介绍
- 应用程序级加密。这是最安全、最灵活的方法。应用程序最终控制是什么加密,可以准确地反映用户的需求。然而,编写应用程序这样做是很难的。这也不是一个选择为客户现有的应用程序不支持加密。
- 数据库级加密。类似的应用程序级加密的属性。大多数数据库厂商提供某种形式的加密。然而,可能有性能问题。一个例子是,索引不能加密。
- 文件系统级进行加密。该选项提供了高性能、应用程序透明,通常容易部署。但是,它无法模型应用程序级别的一些政策。例如,多租户应用程序基于最终用户可能想要加密。一个数据库可能需要不同的加密设置每一列存储在单个文件中。
- 磁盘级别加密。容易部署和高性能,但也很不灵活。
配置
<!-- KMS Backend KeyProvider -->
<property>
<name>hadoop.kms.key.provider.uri</name>
<value>jceks://file@/${user.home}/kms.keystore</value>
<description>
URI of the backing KeyProvider for the KMS.
</description>
</property>
<property>
<name>hadoop.security.keystore.java-keystore-provider.password-file</name>
<value>kms.keystore</value>
<description>
If using the JavaKeyStoreProvider, the password for the keystore file.
</description>
</property>
<!-- KMS Cache -->
<property>
<name>hadoop.kms.cache.enable</name>
<value>true</value>
<description>
Whether the KMS will act as a cache for the backing KeyProvider.
When the cache is enabled, operations like getKeyVersion, getMetadata,
and getCurrentKey will sometimes return cached data without consulting
the backing KeyProvider. Cached values are flushed when keys are deleted
or modified.
</description>
</property> <property>
<name>hadoop.kms.cache.timeout.ms</name>
<value>600000</value>
<description>
Expiry time for the KMS key version and key metadata cache, in
milliseconds. This affects getKeyVersion and getMetadata.
</description>
</property> <property>
<name>hadoop.kms.current.key.cache.timeout.ms</name>
<value>30000</value>
<description>
Expiry time for the KMS current key cache, in milliseconds. This
affects getCurrentKey operations.
</description>
</property>
Audit logs are aggregated for API accesses to the GET_KEY_VERSION, GET_CURRENT_KEY, DECRYPT_EEK, GENERATE_EEK operations.
<!-- KMS Audit -->
<property>
<name>hadoop.kms.audit.aggregation.window.ms</name>
<value>10000</value>
<description>
Duplicate audit log events within the aggregation window (specified in
ms) are quashed to reduce log traffic. A single message for aggregated
events is printed at the end of the window, along with a count of the
number of aggregated eventsfu.
</description>
</property>
<!-- KMS Security --> <property>
<name>hadoop.kms.authentication.type</name>
<value>simple</value>
<description>
Authentication type for the KMS. Can be either "simple"
or "kerberos".
</description>
</property>
- KMS_HTTP_PORT
- KMS_ADMIN_PORT
- KMS_MAX_THREADS
- KMS_LOG
export KMS_LOG=${KMS_HOME}/logs/kms
export KMS_HTTP_PORT=16000
export KMS_ADMIN_PORT=16001
/etc/hadoop/conf/hdfs-site.xml
<property>
<name>dfs.encryption.key.provider.uri</name>
<value>kms://http@localhost:16000/kms</value>
</property>
/etc/hadoop/confcore-site.xml
<property>
<name>hadoop.security.key.provider.path</name>
<value>kms://http@localhost:16000/kms</value>
</property>
# su - hdfs
# hadoop key create key1
# hadoop key list -metadata


# hdfs dfs -mkdir /secureweblogs
# hdfs crypto -createZone -keyName key1 -path /secureweblogs
# hdfs crypto -listZones
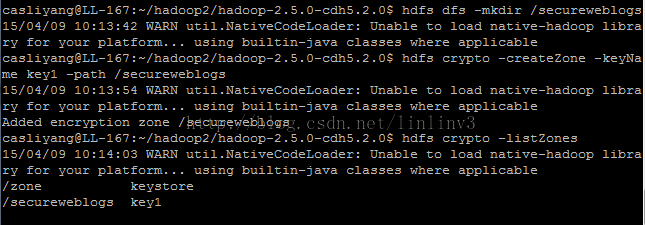

实验结果:

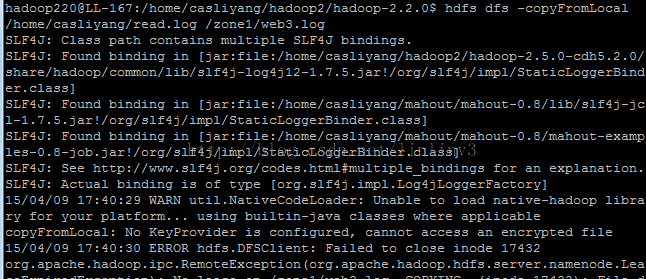


补充说明:
生成秘钥 keytool -delete -alias 'kms.keystore'; 删除别名为kms.keystore的秘钥keytool -genkey -alias 'kms.keystore'; 生成 别名为kms.keystore的秘钥使用生成秘钥的命令后,会在用户根目录下生成相应的文件


hdfs dfs -cat /.reserved/raw/zone1/localfile.dat zone1 是加密区 localfile.dat 是加密文件 ,查看该文件 显示的是被加密的文件(乱码);
十三:Transparent Encryption in HDFS(转)的更多相关文章
- hadoop2.6.0汇总:新增功能最新编译 32位、64位安装、源码包、API下载及部署文档
相关内容: hadoop2.5.2汇总:新增功能最新编译 32位.64位安装.源码包.API.eclipse插件下载Hadoop2.5 Eclipse插件制作.连接集群视频.及hadoop-eclip ...
- 安装部署Apache Hadoop (本地模式和伪分布式)
本节内容: Hadoop版本 安装部署Hadoop 一.Hadoop版本 1. Hadoop版本种类 目前Hadoop发行版非常多,有华为发行版.Intel发行版.Cloudera发行版(CDH)等, ...
- 【转载 Hadoop&Spark 动手实践 2】Hadoop2.7.3 HDFS理论与动手实践
简介 HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.是根据google发表的论文翻版的.论文为GFS(Google File System)Go ...
- [HDFS Manual] CH3 HDFS Commands Guide
HDFS Commands Guide HDFS Commands Guide 3.1概述 3.2 用户命令 3.2.1 classpath 3.2.2 dfs 3.2.3 envvars 3.2.4 ...
- 从零自学Hadoop(12):Hadoop命令中
阅读目录 序 HDFS Commands User Commands Administration Commands Debug Commands 引用 系列索引 本文版权归mephisto和博客园共 ...
- HBASE 基础命令总结
HBASE基础命令总结 一,概述 本文中介绍了hbase的基础命令,作者既有记录总结hbase基础命令的目的还有本着分享的精神,和广大读者一起进步.本文的hbase版本是:HBase 1.2.0-cd ...
- 【大数据系列】hadoop命令指导官方文档翻译
Hadoop Commands Guide Overview Shell Options Generic Options User Commands archive checknative class ...
- Rootkit Hacking Technology && Defence Strategy Research
目录 . The Purpose Of Rootkit . Syscall Hijack . LKM Module Hidden . Network Communication Hidden . Fi ...
- OCP读书笔记(27) - 题库(ExamG)
601.You need to perform a block media recovery on the tools01.dbf data file in the SALES database by ...
随机推荐
- 【2018 ICPC亚洲区域赛南京站 A】Adrien and Austin(博弈)
题意: 有一排n个石子(注意n可以为0),每次可以取1~K个连续的石子,Adrien先手,Austin后手,若谁不能取则谁输. 思路: (1) n为0时的情况进行特判,后手必胜. (2) 当k=1时, ...
- operator.attrgetter() 进行对象排序
## 使用operator.attrgetter() 进行对象排序 from operator import attrgetter class Student: def __init__(self, ...
- Hadoop 动态扩容 增加节点
基础准备 在基础准备部分,主要是设置hadoop运行的系统环境 修改系统hostname(通过hostname和/etc/sysconfig/network进行修改) 修改hosts文件,将集群所有节 ...
- Ruby中的类
初识ruby中的类 只需要简单的两行 class Point end 如果我们此时实例化一个类那么他会有一些自省(introspection)的方法 p = Point.new p.methodes( ...
- Java学习笔记二十八:Java中的接口
Java中的接口 一:Java的接口: 接口(英文:Interface),在JAVA编程语言中是一个抽象类型,是抽象方法的集合,接口通常以interface来声明.一个类通过继承接口的方式,从而来继承 ...
- EEPROM读写学习笔记与I2C总线(二)
无论任何电子产品都会涉及到数据的产生与数据的保存,这个数据可能并不是用来长久保存,只是在运行程序才会用到,有些数据体量较大对于获取时效性并不太强,各种各样的数据也就有不同的存储载体,这次在EEPROM ...
- 【blockly教程】第六章 Blockly的进阶
6.1 模块化程序设计 一个较大的程序一般应分为若干个程序模块,每一个模块用来实现一个特定的功能.所有的高级语言中都有子程序这个概念,用子程序实现模块的功能.比如在C语言中,子程序的作用是由函数完成 ...
- APP如何发布到Google play 商店
APP如何发布到Google play 商店?以及有哪些需要注意的点 2015-05-13 10:07 19773人阅读 评论(1) 收藏 举报 分类: iPhone游戏开发(330) 链接:ht ...
- Ubentu编译Android源码(AOSP)
前言: 一直想要编译一下Android 源码,之前去google 看,下载要下载repo. 当时很懵逼,repo 是个什么?(repo 是一个python 脚本,因为Android 源码git 仓库太 ...
- js实现无限级分类
let arr = [ {id:1,name:"php",pid:0}, {id:2,name:"php基础",pid:1}, {id:3,name:" ...