【转载】RETE算法研究
本文转自:http://www.ibm.com/developerworks/cn/opensource/os-drools/
RETE算法是大多数规则引擎采用的一种模式匹配算法,比如开源的Drools引擎,就是改进了RETE算法实现。上午发现这篇文章描述的比较清晰易懂,对我这个初学者很有帮助,故收藏细品。
在 AI 领域,产生式系统是一个很重要的理论。产生式推理分为正向推理和逆向推理产生式,其规则的一般形式是:IF 条件 THEN 操作。rete 算法是实现产生式系统中正向推理的高效模式匹配算法,通过形成一个 rete 网络进行模式匹配,利用基于规则的系统的时间冗余性和结构相似性特征 [8],提高系统模式匹配效率。Drools 引擎就是利用 rete 算法对规则进行分析,形成 rete 网络,对模式进行匹配。
1. Rete 算法概述
Rete 算法最初是由卡内基梅隆大学的 Charles L.Forgy 博士在 1974 年发表的论文中所阐述的算法 , 该算法提供了专家系统的一个高效实现。自 Rete 算法提出以后 , 它就被用到一些大型的规则系统中 , 像 ILog、Jess、JBoss Rules 等都是基于 RETE 算法的规则引擎 [7]。
Rete 在拉丁语中译为"net",即网络。Rete 匹配算法是一种进行大量模式集合和大量对象集合间比较的高效方法,通过网络筛选的方法找出所有匹配各个模式的对象和规则。
其核心思想是将分离的匹配项根据内容动态构造匹配树,以达到显著降低计算量的效果。Rete 算法可以被分为两个部分:规则编译和规则执行[7]。当 Rete 算法进行事实的断言时,包含三个阶段:匹配、选择和执行,称做 match-select-act cycle。
2. Rete 算法相关概念
Rete 算法规则相关的概念有如下几个:
Fact:已经存在的事实,它是指对象之间及对象属性之间的多元关系,为简单起见,事实用一个三元组来表示:(标识符 ^ 属性值)[1],例如如下事实:
w1:(B1 ^ on B2) w6:(B2 ^color blue)
w2:(B1 ^ on B3) w7:(B3 ^left-of B4)
w3:(B1 ^ color red) w8:(B3 ^on table)
w4:(B2 ^on table) w9:(B3 ^color red)
w5:(B2 ^left-of B3)
Rule:规则,包含条件和行为两部分,条件部分又叫左手元(LHS),行为部分又叫右手元(RHS)。条件部分可以有多条条件,并且可以用 and 或 or 连接 [1]。其一般形式如下:
(name-of-this-production
LHS /*one or more conditions*/
-->
RHS /*one or more actions*/
)
例如,下面的例子:
(find-stack-of-two-blocks-to-the-left-of-a-red-block
(^on)
(^left-of)
(^color red)
-->
...RHS...
)
Patten:模式,也就是规则的条件部分,是已知事实的泛化形式,是未实例化的多元关系[1]。比如,前面的那条规则的条件部分:
(^on)
(^left-of)
(^color red)
Rete 网络的概念[1][9][10]如下:
RootNode:Rete 网络的根节点,所有对象通过 Root 节点进入网络。
ObjectTypeNode:对象类型节点,保证所传入的对象只会进入自己类型所在的网络,提高了工作效率。
AlphaNode:Alpha 节点是规则的条件部分的一个模式,一个对象只有和本节点匹配成功后,才能继续向下传播。
JoinNode:用作连接(jion)操作的节点,相当于 and,相当于数据库的表连接操作,属于 betaNode 类型的节点。BetaNode 节点用于比较两个对象和它们的字段。两个对象可能是相同或不同的类型。我们将这两个输入称为左和右。BetaNode 的左输入通常是一组对象的数组。BetaNode 具有记忆功能。左边的输入被称为 Beta Memory,会记住所有到达过的语义。右边的输入成为 Alpha Memory,会记住所有到达过的对象。
NotNode:根据右边输入对左边输入的对象数组进行过滤,两个 NotNode 可以完成' exists '检查。
LeftInputAdapterNodes:将单个对象转化成对象数组。
TerminalNode: 被用来表明一条规则已经匹配了它的所有条件(conditions)。
图 1 展示的是一个简单的 rete 网络:
图 1. RETE 网络
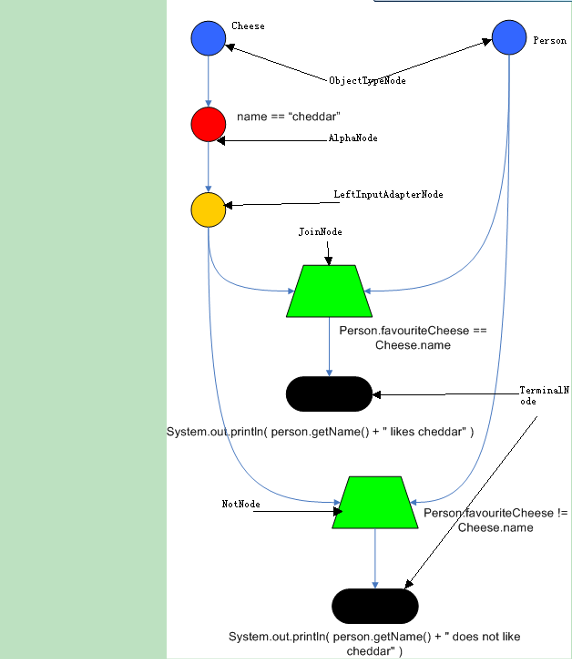
3. 创建 rete 网络
Rete 算法的编译结果是创建了规则集对应的 Rete 网络 , 它是一个事实可以在其中流动的图。
创建 rete 网络的过程 [1]如下:
1) 创建根节点;
2) 加入一条规则 1 (Alpha 节点从 1 开始,Beta 节点从 2 开始 );
,检查模式中的参数类型,如果是新类型,则加入一个类型节点;
b. 检查模式 1 对应的 Alpha 节点是否已存在,如果存在则记录下节点位置,如果没有则将模式 1 作为一个 Alpha 节点加入到网络中,同时根据 Alpha 节点的模式建立 Alpha 内存表;
c. 重复 b 直到所有的模式处理完毕;
d. 组合 Beta 节点,按照如下方式: Beta(2) 左输入节点为 Alpha(1),右输入节点为 Alpha(2);Beta(i) 左输入节点为 Beta(i-1),右输入节点为 Alpha(i),i>2。并将两个父节点的内存表内联成为自己的内存表;
e. 重复 d 直到所有的 Beta 节点处理完毕;
f. 将动作(Then 部分)封装成叶节点(Action 节点)作为 Beta(n) 的输出节点;
3) 重复 2) 直到所有规则处理完毕;
执行完上述步骤,建立的 rete 网络如下图 2 (a 图为含有 3 个规则的 rete 网络,b 图为含有一个规则的 rete 网络 ):
图 2. beta-network and alpha-network

上图(a 图和 b 图),他们的左边的部分都是 beta-network, 右边都是 alpha-network, 圆圈是 join-node。右边的 alpha-network 是根据事实库和规则条件构建的,其中除 alpha-network 节点的节点都是根据每一条规则条件的模式 , 从事实库中 match 过来的,即在编译构建网络的过程中静态建立的。只要事实库是稳定的,RETE 算法的执行效率应该是非常高的,其原因就是已经通过静态的编译,构建了 alpha-network。左边的 beta-network 表现出了 rules 的内容,其中 p1,p2,p3 共享了许多 BetaMemory 和 join-node, 这样能加快匹配速度。
4. Rete 算法的匹配过程
匹配过程如下:
1) 对于每个事实,通过 select 操作进行过滤,使事实沿着 rete 网达到合适的 alpha 节点。
2) 对于收到的每一个事实的 alpha 节点,用 Project( 投影操作 ) 将那些适当的变量绑定分离出来。使各个新的变量绑定集沿 rete 网到达适当的 bete 节点。
3) 对于收到新的变量绑定的 beta 节点,使用 Project 操作产生新的绑定集,使这些新的变量绑定沿 rete 网络至下一个 beta 节点以至最后的 Project。
4) 对于每条规则,用 project 操作将结论实例化所需的绑定分离出来。
如果把 rete 算法类比到关系型数据库操作,则事实集合就是一个关系,每条规则就是一个查询,再将每个事实绑定到每个模式上的操作看作一个 Select 操作,记一条规则为 P,规则中的模式为 c1,c2,…,ci, Select 操作的结果记为 r(ci), 则规则 P 的匹配即为 r(c1)◇r(c2)◇…◇(rci)。其中◇表示关系的连接(Join)操作。
Rete 网络的连接(Join)和投影 (Project) 和对数据库的操作形象对比如图 3 所示:
图 3. join and project
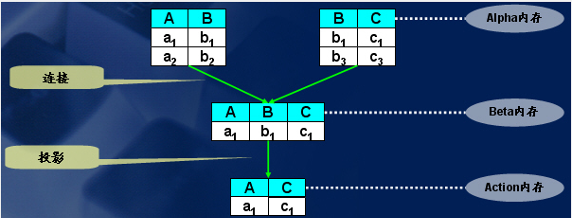
5. Rete 算法的特点、不足和建议
Rete算法有如下特点:
a. Rete 算法是一种启发式算法,不同规则之间往往含有相同的模式,因此在 beta-network 中可以共享 BetaMemory 和 betanode。如果某个 betanode 被 N 条规则共享,则算法在此节点上效率会提高 N 倍。
b. Rete 算法由于采用 AlphaMemory 和 BetaMemory 来存储事实,当事实集合变化不大时,保存在 alpha 和 beta 节点中的状态不需要太多变化,避免了大量的重复计算,提高了匹配效率。
c. 从 Rete 网络可以看出,Rete 匹配速度与规则数目无关,这是因为事实只有满足本节点才会继续向下沿网络传递。
Rete算法的不足:
a. 事实的删除与事实的添加顺序相同, 除了要执行与事实添加相同的计算外, 还需要执行查找, 开销很高 [3]。
b. RETE 算法使用了β存储区存储已计算的中间结果, 以牺牲空间换取时间, 从而加快系统的速度。然而β存储区根据规则的条件与事实的数目而成指数级增长, 所以当规则与事实很多时, 会耗尽系统资源 [3]。
针对 Rete 算法的特点和不足,在应用或者开发基于 Rete 算法的规则引擎时,提出如下建议:
a. 容易变化的规则尽量置后匹配,可以减少规则的变化带来规则库的变化。
b. 约束性较为通用或较强的模式尽量置前匹配,可以避免不必要的匹配。
c. 针对 Rete 算法内存开销大和事实增加删除影响效率的问题,技术上应该在 alpha 内存和 beata 内存中,只存储指向内存的指针,并对指针建里索引(可用 hash 表或者非平衡二叉树)。
d. Rete 算法 JoinNode 可以扩展为 AndJoinNode 和 OrJoinNode,两种节点可以再进行组合 [5]。
【转载】RETE算法研究的更多相关文章
- Akamai在内容分发网络中的算法研究(翻译总结)
作者 | 钱坤 钱坤,腾讯后台开发工程师,从事领域为流媒体CDN相关,参与腾讯TVideo平台开发维护. 原文是<Algorithmic Nuggets in Content Delivery& ...
- 【java规则引擎】模拟rete算法的网络节点以及匹配过程
转载请注明:http://www.cnblogs.com/shangxiaofei/p/6340655.html 本文只用于理解rete算法,通过一个规则的编译成的网络结构,以及匹配过程去理解rete ...
- 【java规则引擎】之Drools之Rete算法
一:规则引擎--->规则引擎的核心是Pattern Matcher(模式匹配器).不管是正向推理还是反向推理,首先要解决一个模式匹配的问题.--->对于规则的模式匹配,可以定义为: 一个规 ...
- July-程序员面试、算法研究、编程艺术、红黑树、数据挖掘5大经典原创系列集锦与总结
程序员面试.算法研究.编程艺术.红黑树.数据挖掘5大经典原创系列集锦与总结 http://blog.csdn.net/v_july_v/article/details/6543438
- 经典算法研究系列:二、Dijkstra 算法初探
July 二零一一年一月 本文主要参考:算法导论 第二版.维基百科. 一.Dijkstra 算法的介绍 Dijkstra 算法,又叫迪科斯彻算法(Dijkstra),算法解决的是有向图中单个源点到 ...
- 静态频繁子图挖掘算法用于动态网络——gSpan算法研究
摘要 随着信息技术的不断发展,人类可以很容易地收集和储存大量的数据,然而,如何在海量的数据中提取对用户有用的信息逐渐地成为巨大挑战.为了应对这种挑战,数据挖掘技术应运而生,成为了最近一段时期数据科学的 ...
- RETE算法介绍
RETE算法介绍一. rete概述Rete算法是一种前向规则快速匹配算法,其匹配速度与规则数目无关.Rete是拉丁文,对应英文是net,也就是网络.Rete算法通过形成一个rete网络进行模式匹配,利 ...
- Rete算法
RETE算法介绍一. rete概述Rete算法是一种前向规则快速匹配算法,其匹配速度与规则数目无关.Rete是拉丁文,对应英文是net,也就是网络.Rete算法通过形成一个rete网络进行模式匹配,利 ...
- sauvola二值化算法研究
sauvola二值化算法研究 sauvola是一种考虑局部均值亮度的图像二值化方法, 以局部均值为基准在根据标准差做些微调.算法实现上一般用积分图方法 来实现.这个方法能很好的解决全局阈值方法的短 ...
随机推荐
- java 单例的实现及多线程下的安全
package com.demo01; public class Single { /** * 设计模式:单例设计模式 * 解决一个类中只允许存在一个对象这种情况: * 不允许通过类,无限制的创建该类 ...
- Python入门-初始函数
今天让我们来初步认识一个在python中非常重要的组成部分:函数 首先,让我们来幻想这样一个场景: 比如说我们现在想要通过社交软件约一个妹子,步骤都有什么? print('打开手机 ') print( ...
- 申请微信小程序步骤
一.注册 注册网址:https://mp.weixin.qq.com/ 选择账号类型:选择 小程序 注册账号 填写邮箱密码并激活:未注册过公众平台.开放平台.企业号.未绑定个人号的邮箱. 填写主体信息 ...
- 小小的js
//安全登陆不允许iframe嵌入 if (window.top !== window.self) { window.top.location = window.location; } 使用filte ...
- CentOS 7运维管理笔记(5)----源代码安装Apache 2.4,搭建LAMP服务器
########################## 2016-07-07-Thu--20:34 补充 ##################### 编译安装OpenSSL笔记: 如果系统要使用 ...
- 学习C++从入门到精通的的十本最经典书籍
原文:http://blog.csdn.net/a_302/article/details/17558369 最近想学C++,找了一下网上推荐的书籍,转载过来给大家分享 转载自http://c.chi ...
- .Net Core 初体验及总结(内含命令大全)
dotnet 命令目录: dotnet new -创建 dotnet restore -还原 dotnet build -编译 dotnet run -运行 dotnet test -测试 dot ...
- idea 出现 java.lang.OutOfMemoryError: PermGen space
今天在项目启动时候,刚刚启动 就 报了 Exception in thread "http-bio-8080-exec-1" 之后 出现了 java.lang.OutOfMemor ...
- C++11标准之右值引用(rvalue reference)
1.右值引用引入的背景 临时对象的产生和拷贝所带来的效率折损,一直是C++所为人诟病的问题.但是C++标准允许编译器对于临时对象的产生具有完全的自由度,从而发展出了Copy Elision.RVO(包 ...
- 错误: 安装必备组件失败: 安装必备组件失败: SqlInstanceRtc 有关详细信息
错误: 安装必备组件失败: 安装必备组件失败: SqlInstanceRtc 有关详细信息 查看错误得知是安装sqlexpr_x64.exe的时候出现了错误 解决: 通过打开skype镜像,找到sql ...