[19/03/28-星期四] IO技术_基本概念&字符编码与解码
一、概念
输入(Input) 指的是:可以让程序从外部系统获得数据(核心含义是“读”,读取外部数据)
常见的应用:
Ø 读取硬盘上的文件内容到程序。例如:播放器打开一个视频文件、word打开一个doc文件。
Ø 读取网络上某个位置内容到程序。例如:浏览器中输入网址后,打开该网址对应的网页内容;下载网络上某个网址的文件。
Ø 读取数据库系统的数据到程序。
Ø 读取某些硬件系统数据到程序。例如:车载电脑读取雷达扫描信息到程序;温控系统等。
输出(Output) 指的是:程序输出数据给外部系统从而可以操作外部系统(核心含义是“写”,将数据写出到外部系统)
常见的应用有:
Ø 将数据写到硬盘中。例如:我们编辑完一个word文档后,将内容写到硬盘上进行保存。
Ø 将数据写到数据库系统中。例如:我们注册一个网站会员,实际就是后台程序向数据库中写入一条记录。
Ø 将数据写到某些硬件系统中。例如:导弹系统导航程序将新的路径输出到飞控子系统,飞控子系统根据数据修正飞行路径。
数据源(data source) 指提供数据的原始媒介。常见的数据源有:数据库、文件、其他程序、内存、网络连接、IO设备
分为:
源设备:为程序提供数据,一般对应输入流。
目标设备:程序数据的目的地,一般对应输出流。
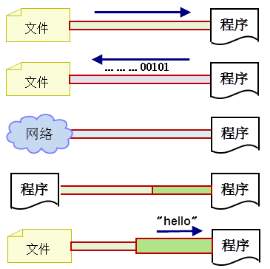
流(stream):流动、流向。从一端(数据源)流向另一端(程序),是一个抽象、动态的概念,是一连串连续动态的数据集合。
注意:输入/输出流的划分是相对程序(以它为中心划分的)而言的,并不是相对数据源。
如现实中读书:程序相当于大脑,读书是将书本中的知识读入到大脑中,而写字是将大脑中的知识读出(输出)到书本上。

--- 对于输入流而言,数据源就像水箱,流(stream)就像水管中流动着的水流,程序就是我们最终的用户。
我们通过流(A Stream)将数据源(Source)中的数据(information)输送到程序(Program)中。
涉及到类:InputStream 字节输入流 Reader 字符输入流
--- 对于输出流而言,目标数据源就是目的地(dest),
我们通过流(A Stream)将程序(Program)中的数据(information)输送到目的数据源(dest)中。
涉及到的类:OutputStream 字节输出流 Writer 字符输出流

二、核心类( 整个Java.io包中最重要的5个类和3个接口)
File 文件类
InputStream 字节输入流
OutputStream 字节输出流
Reader 字符输入流
Writer 字符输出流
Closeable 关闭流接口(Java告诉操作系统可以关闭流接口)
Flushable 刷新流接口
Serializable 序列化流接口
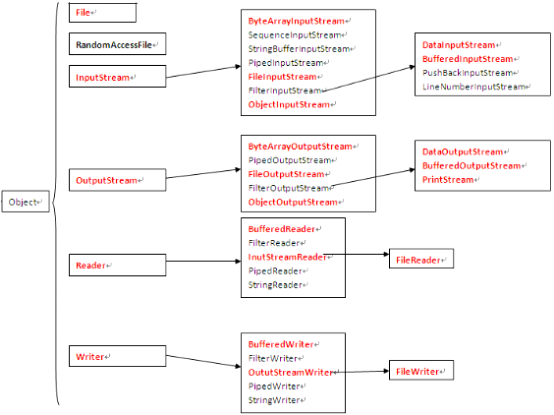
1. InputStream/OutputStream 字节流的抽象类。
2. Reader/Writer 字符流的抽象类。
3. FileInputStream/FileOutputStream 节点流:以字节为单位直接操作“文件”。
4. ByteArrayInputStream/ByteArrayOutputStream 节点流:以字节为单位直接操作“字节数组对象”。
5. ObjectInputStream/ObjectOutputStream 处理流:以字节为单位直接操作“对象”。
6. DataInputStream/DataOutputStream 处理流:以字节为单位直接操作“基本数据类型与字符串类型”。
7. FileReader/FileWriter 节点流:以字符为单位直接操作“文本文件”(注意:只能读写文本文件)。
8. BufferedReader/BufferedWriter 处理流:将Reader/Writer对象进行包装,增加缓存功能,提高读写效率。
9. BufferedInputStream/BufferedOutputStream 处理流:将InputStream/OutputStream对象进行包装,增加缓存功能,提高 读写效率。
10. InputStreamReader/OutputStreamWriter 处理流:将字节流对象转化成字符流对象。
11. PrintStream 处理流:将OutputStream进行包装,可以方便地输出字符,更加灵活。
三、分类
按流的方向分类:
1. 输入流:数据流向是数据源到程序(以InputStream、Reader结尾的流)。
2. 输出流:数据流向是程序到目的地(以OutPutStream、Writer结尾的流)。
按处理的数据单元分类:
1. 字节流:以字节为单位获取数据,命名上以Stream结尾的流一般是字节流,如FileInputStream、FileOutputStream。
2. 字符流:以字符为单位获取数据,命名上以Reader/Writer结尾的流一般是字符流,如FileReader、FileWriter。
按处理对象不同分类:
1. 节点流:可以直接从数据源或目的地读写数据,如FileInputStream、FileReader、DataInputStream等。
2. 处理流:不直接连接到数据源或目的地,是”处理流的流”。通过对其他流的处理提高程序的性能,如BufferedInputStream、BufferedReader等。
处理流也叫包装流。
节点流处于IO操作的第一线,所有操作必须通过它们进行;处理流可以对节点流进行包装,提高性能或提高程序的灵活性。

四、字符编码与解码
/**
* 字符编码与解码,以电脑为中心 编码:incode 解码:decode
* 字节(电脑中)-->>>字符(符合人的常识,便于书写):(字节)解码(成字符)
* 字符(符合人的常识,便于书写)-->>>字节(电脑中):(字符)编码(成字节)
* 编码规范:字符集(码表)就是大字典
* 常用:ASCII码
* ANSI:美国国家标准协会,每个国家(非拉丁语系国家)自己制定自己的文字的编码规则 ,中国的ANSI对应就是GB2312标准 日本就是JIT标准
* 但是ASCII码的(0-127)不能用,从之后开始编码
* GBK(国标码):中文:2个字节 ;英文、数字:1个字节 ,包含GB2312
* Unicode(Universal Code) 万国码,中国的自己编码(GBK)和日本(JIT)可能同一个数字对应不同的字符,即日文和中文同时存在时
* 可能不会正确解析,所以Unicode统一编码,保证所以字符都不会重复,共计100多万字符,包含世界所有国家的字符,保证可以正确解析。
* UTF-8(万国码,最短8位即1个字节):变长Unicode,1-3个字节不等 (中文:3个字节;英文:1个字节)
* UTF-16(标准2个字节):定长Unicode,中英文都是2个字节 如一个数7834H (16进制表示) 高字节 78H 低字节34H,(FE FF大端、FF FE小端)
* ----UTF-16BE(Big Endian:大的字节序,大端表示),(16位的)数据高字节(78H)存在低地址(7-0位),低字节(34H)存在高位(15-8位)
* ----UTF-16LE(Low Endian:大的字节序,小端表示),数据高字节(78H)存在高地址(15-8位),低字节(34H)存在高位(7-0位)
*
*/
package cn.sxt.test; import java.io.UnsupportedEncodingException; public class Test_0327_Code {
public static void main(String[] args) throws UnsupportedEncodingException {
String msg="2019中国Ab";
//测试编码 字符到字节 。GBK:有单字节,0-127的编码与ASCII码完全一致
byte datas[]=msg.getBytes();//默认使用工程的字符集GBK, 中文:2个字节 ;英文、数字:1个字节
for (int i=0;i<datas.length ;i++) {
System.out.printf("datas[%d]=%d;",i,datas[i]);
}
System.out.println("\n"+datas.length);//输出字节数:4+2*2+2=10 //UTF-8:0-127的编码与ASCII码完全一致,由于有单字节编码,所以兼容ASCII码
byte datas2[]=msg.getBytes("UTF-8");//中文:3 个字节,英文、数字:1个字节
for (int i=0;i<datas2.length ;i++) {
System.out.printf("datas2[%d]=%d;",i,datas2[i]);
}
System.out.println("\n"+datas2.length); //输出:12 //UTF-16 使用2个或4个字节来编码,实际上测试的效果也是
byte datas3[]=msg.getBytes("UTF-16");//不太确定中英文所占字符数.例如"2"占4个字节 但"1"和"中"和"A""a"只占2个字节
for (int i=0;i<datas3.length ;i++) {
System.out.printf("datas3[%d]=%d;",i,datas3[i]);
}
System.out.println("\n"+datas3.length);//此电脑输出为18 //UTF-16LE 小端存储 数据高字节(78H)存在高地址(15-8位),低字节(34H)存在高位(7-0位)
byte datas4[]=msg.getBytes("UTF-16LE");//中英文数字均是2个字节
for (int i=0;i<datas4.length ;i++) {
System.out.printf("data4[%d]=%d;",i,datas4[i]);
}
System.out.println("\n"+datas4.length);//输出16 byte datas5[]=msg.getBytes("UTF-16BE");//中英文数字均是2个字节
System.out.println(datas5.length); //测试解码: 字节到字符 相当于拿个大字典去翻译二进制字节成一个个的字符
//datas数组是用GBK加密的 4个参数 (要解码的数组名字,从下标哪个位置开始解码,给定解码后的存储空间,用那个字典解密)
//乱码原因:1、字节数不够 msg3解码过程中最后一个字符字节数不够不能成功解码
// 2、字典不对 如msg4是用的UTF-16LE编码的但却用GBK解码 String msg2=new String(datas, 0, datas.length, "GBK");//正确解码 //对于datas4数组,从下标0开始解码,解码长度为:总长度-1=15(即解码datas数组下标为0-14的字符),所用的字典为"UTF-16LE"。
//解码成功后把解码后的字符串赋值给msg4。对于datas4数组字符全是2个字节编码的,对于数组的下标0-13即前7个字符可以正确解码,
//但是下标14和下标15共同表示一个字符'a',只给出下标14无法正确解码(翻译)出正确的字符、所以出现乱码。
String msg3=new String(datas4, 0, datas4.length-1, "UTF-16LE"); String msg4=new String(datas4, 0, datas4.length, "GBK");//字典不对,出现乱码
System.out.println(msg2);
System.out.println(msg3);
System.out.println(msg4); } }
[19/03/28-星期四] IO技术_基本概念&字符编码与解码的更多相关文章
- [19/03/31-星期日] IO技术_四大抽象类_字符流( 字符输入流 Reader、 字符输出流 Writer )(含字符缓冲类)
一.概念 Reader Reader用于读取的字符流抽象类,数据单位为字符. int read(): 读取一个字符的数据,并将字符的值作为int类型返回(0-65535之间的一个值,即Unicode ...
- [19/04/02-星期二] IO技术_字符流分类总结(含字符转换流InputStreamReader/ OutputStreamWriter,实现字节转字符)
一.概念 ------->1.BufferedReader/BufferedWriter [参考19.03.31文章] *Reader/Writer-------->2.InputStre ...
- [19/04/01-星期一] IO技术_字节流分类总结(含字节数组(Array)流、字节数据(Data)流、字节对象(Object)流)
一.字节流分类概括 -->1.ByteArrayInputStream /ByteArrayOutputStream(数组字节输入输出) InputStream/OutputStr ...
- [19/03/30-星期六] IO技术_四大抽象类_ 字节流( 字节输入流 InputStream 、字符输出流 OutputStream )_(含字节文件缓冲流)
一.概念及分类 InputStream(输入流)/OutputStream(输出流)是所有字节输入输出流的父类 [注]输入流和输出流的是按程序运行所在的内存的角度划分的 字节流操作的数据单元是8的字节 ...
- [19/04/03-星期三] IO技术_其它流(RandomAccessFile 随机访问流,SequenceInputStream 合并流)
一.RandomAccessFile 随机访问流 [版本1] /* *RandomAccessFile 所谓随机读取就是 指定位置开始或指定位置结束 的读取写入文件 * 实现文件的拆分与合并 模拟下载 ...
- [19/03/13-星期三] 数组_二维数组&冒泡排序&二分查找
一.二维数组 多维数组可以看成以数组为元素的数组.可以有二维.三维.甚至更多维数组,但是实际开发中用的非常少.最多到二维数组(我们一般使用容器代替,二维数组用的都很少). [代码示例] import ...
- [19/03/12-星期二] 数组_遍历(for-each)&复制&java.util.Arrays类
一.遍历 for-each即增强for循环,是JDK1.5新增加的功能,专门用于读取数组或集合中所有的元素,即对数组进行遍历. //数组遍历 for-each public class Test_03 ...
- [19/03/23-星期六] 容器_ 泛型Generics
一.概念 生活中的容器不难理解,是用来容纳物体的,程序中的“容器”也有类似的功能,就是用来容纳和管理数据. 数组就是一种容器,可以在其中放置对象或基本类型数据. ---优势:是一种简单的线性序列,可以 ...
- [SAP ABAP开发技术总结]字符编码与解码、Unicode
声明:原创作品,转载时请注明文章来自SAP师太技术博客( 博/客/园www.cnblogs.com):www.cnblogs.com/jiangzhengjun,并以超链接形式标明文章原始出处,否则将 ...
随机推荐
- 测试域名ping延迟脚本
#!/bin/bash if [ $# -lt 1 ]thenecho "Usage:avg file1"exit 1fiecho "================== ...
- C++命名空间使用代码
namesp.h #pragma once #include <string> namespace pers { using namespace std; struct Person { ...
- [javaEE] jsp的指令
jsp的指令:jsp的指令(directive)是为jsp引擎而设计的,他们并不直接产生任何可见输出,而是告诉引擎如何处理jsp 页面中的其他部分 页面头部的page指令 <%@page imp ...
- java_对象序列化、反序列化
1.概念 序列化:将对象转化为字节序列的过程 反序列化:将字节序列转化为对象的过程 用途: A:将对象转化为字节序列保存在硬盘上,如文件中,如文本中的例子就是将person对象序列化成字节序列,存在p ...
- Tomcat Post请求大小限制
理论上讲,POST是没有大小限制的.HTTP协议规范也没有进行大小限制,起限制作用的是服务器的处理程序的处理能力. 如:在Tomcat下取消POST大小的限制(Tomcat默认2M): 打开tomca ...
- Mybatis执行sql(insert、update、delete)返回值问题
数据库:Mysql 在使用mybatis的过程中对执行sql的返回值产生疑问,顺手记录一下. 结论: insert: 插入n条记录,返回影响行数n.(n>=1,n为0时实际为插入失败) up ...
- vs2015 web项目加载失败解决办法
1.问题 ---------------------------Microsoft Visual Studio---------------------------Web 应用程序项目 XXWeb 已 ...
- Perl学习笔记(1)----入门
在UNIX/Linux 系统上,打开命令终端,输入 'rpm -q perl' 查看系统是否安装了 perl ---- 在自己的CentOS7 系统上,默认自带了 perl 软件: root@javi ...
- JavaScript中sort()方法
sort()方法主要是用于对数组进行排序,默认情况下该方法是将数组元素转换成字符串,然后按照ASC码进行排序,这个大家都能理解,但如果数组元素是一个Object呢,转不了字符串,难道不能进行排序?答案 ...
- 十一、使用a标签打电话、发短信、发邮件
<a href="tel:400-888-6633">拨打电话<a> <a href="sms:19956321564">发 ...