python3 爬虫爬取深圳公租房轮候库(深圳房网)
深圳公租房轮候库已经朝着几十万人的规模前进了,这是截至16年10月之前的数据了,贴上来大家体会下
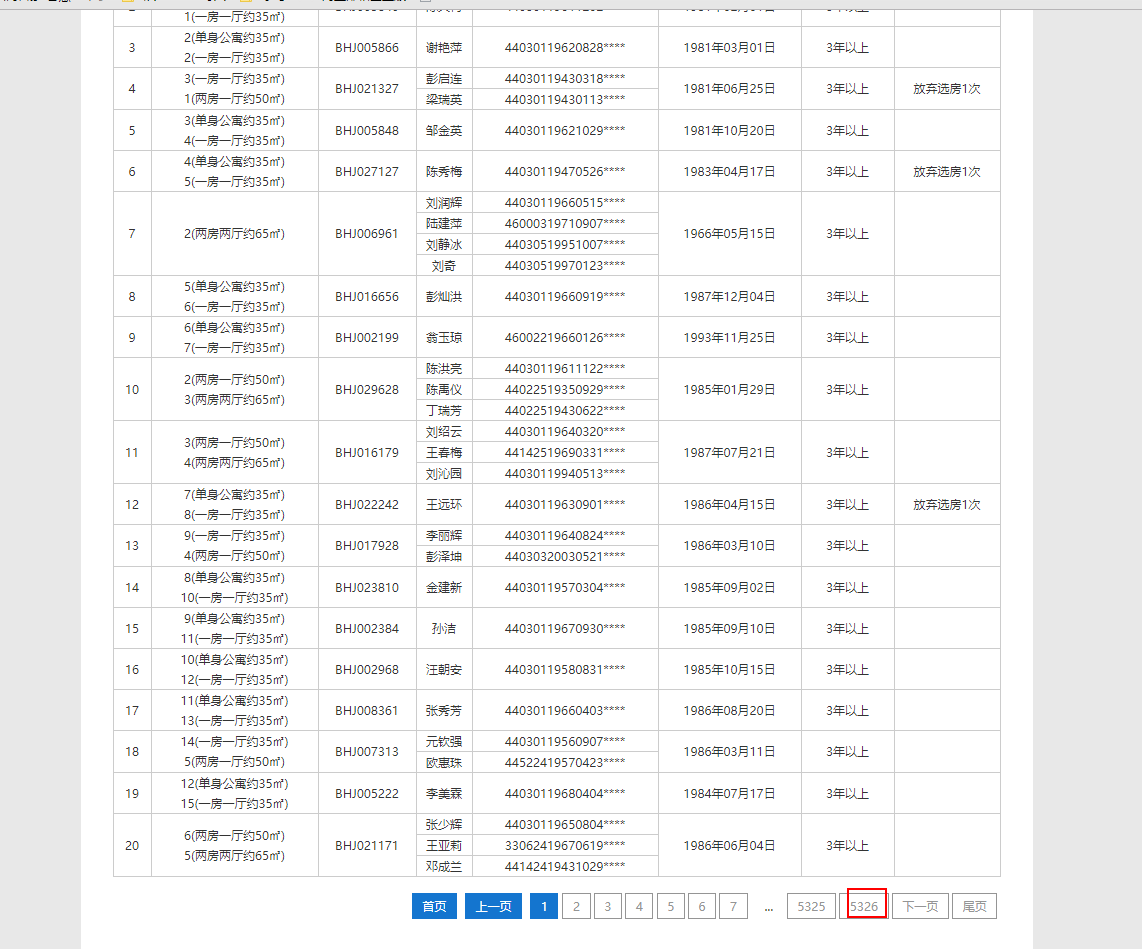
所以17年已更新妥妥的10W+
今天就拿这个作为爬虫的练手项目
1、环境准备:
操作系统:win10
python版本:python3.5.3
开发工具:sublime 3
python需要安装的库:
anaconda 没安装的可以去https://mirrors.tuna.tsinghua.edu.cn/help/anaconda/这里下载,国内镜像比较快;
Requests urllib的升级版本打包了全部功能并简化了使用方法(点我查看官方文档)
beautifulsoup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.(点我查看官方文档)
LXML 一个HTML解析包 用于辅助beautifulsoup解析网页
Requests ,beautifulsoup ,LXML 模块安装方式:windows的命令提示符窗口输入以下代码即可
pip install requests pip install beautifulsoup4 pip install lxml
直接贴代码吧
import requests
from bs4 import BeautifulSoup
import os
class Gongzufang():
#获取页面数据
def all_url(self,url):
html = self.request(url)
all_a = BeautifulSoup(html.text, 'lxml').find('table', class_='sort-tab').find_all('tr')
for a in all_a:
title = a.get_text("|", strip=True)
print(title)
#self.save_data(url)
#获取分页面地址
def html(self, url):
html = self.request(url)
max_span = BeautifulSoup(html.text, 'lxml').find('div', class_='fix pagebox').find_all('a')[-3].get_text()
for page in range(1, int(max_span) + 1):
page_url = url + '/' + '0-'+str(page)+'-0-0-1'
self.all_url(page_url)
def save_data(self,data_url):#下载数据
pass
#获取网页的response 然后返回
def request(self, url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.10240','Connection': 'Keep-Alive','Referer':'http://www.mzitu.com/tag/baoru/'}
content = requests.get(url, headers=headers)
return content
#实例化
Gongzufang = Gongzufang()
#给函数all_url、html传入参数 你可以当作启动爬虫(就是入口)
Gongzufang.html('http://anju.szhome.com/gzfpm')
Gongzufang.all_url('http://anju.szhome.com/gzfpm')
结果如下:
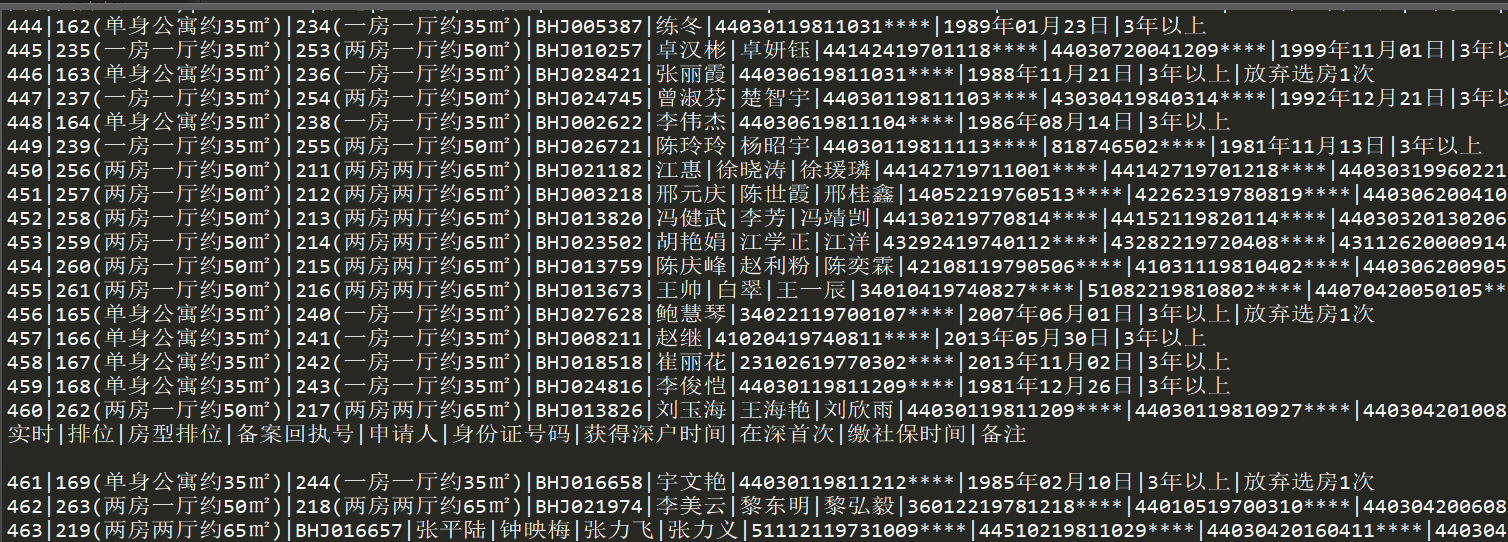
后续:
结果爬到6w+的时候出现了个偏僻字:。。
衬衫哥决定不填这个坑,反正只是想爬身份证的信息。。
修改后的代码如下:
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
#import os
import re
#import sys
#import io
#sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
class Gongzufang():
#获取页面数据
def all_url(self,url):
html = self.request(url)
all_a = BeautifulSoup(html.text, 'lxml').find('table', class_='sort-tab').find_all('tr')
#all_a = BeautifulSoup(html.text, 'lxml').find('table', class_='sort-tab').find_all('td')[0:9]
for a in all_a:
for find_td in a.find_all('td')[4:5]:
text_td = find_td.get_text("\r", strip=True)
print(text_td)
with open('d:/test.txt', 'a') as f:
print(text_td,file=f)
#print(title)
#获取分页面地址
def html(self, url):
html = self.request(url)
max_span = BeautifulSoup(html.text, 'lxml').find('div', class_='fix pagebox').find_all('a')[-3].get_text()
for page in range(1, int(max_span) + 1):
page_url = url + '/' + '0-'+str(page)+'-0-0-1'
self.all_url(page_url)
def save_data(self,data_url):#下载数据
pass
#获取网页的response 然后返回
def request(self, url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.10240','Connection': 'Keep-Alive','Referer':'http://www.mzitu.com/tag/baoru/'}
content = requests.get(url, headers=headers)
return content
#实例化
Gongzufang = Gongzufang()
#给函数all_url、html传入参数 你可以当作启动爬虫(就是入口)
Gongzufang.html('http://anju.szhome.com/gzfpm')
Gongzufang.all_url('http://anju.szhome.com/gzfpm')
现在又可以开始快乐的爬取数据了
python3 爬虫爬取深圳公租房轮候库(深圳房网)的更多相关文章
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- python3爬虫爬取网页思路及常见问题(原创)
学习爬虫有一段时间了,对遇到的一些问题进行一下总结. 爬虫流程可大致分为:请求网页(request),获取响应(response),解析(parse),保存(save). 下面分别说下这几个过程中可以 ...
- python3爬虫爬取煎蛋网妹纸图片(上篇)
其实之前实现过这个功能,是使用selenium模拟浏览器页面点击来完成的,但是效率实际上相对来说较低.本次以解密参数来完成爬取的过程. 首先打开煎蛋网http://jandan.net/ooxx,查看 ...
- python3 爬虫---爬取糗事百科
这次爬取的网站是糗事百科,网址是:http://www.qiushibaike.com/hot/page/1 分析网址,参数''指的是页数,第二页就是'/page/2',以此类推... 一.分析网页 ...
- python3 爬虫---爬取豆瓣电影TOP250
第一次爬取的网站就是豆瓣电影 Top 250,网址是:https://movie.douban.com/top250?start=0&filter= 分析网址'?'符号后的参数,第一个参数's ...
- python3爬虫-爬取新浪新闻首页所有新闻标题
准备工作:安装requests和BeautifulSoup4.打开cmd,输入如下命令 pip install requests pip install BeautifulSoup4 打开我们要爬取的 ...
- python3爬虫-爬取58同城上所有城市的租房信息
from fake_useragent import UserAgent from lxml import etree import requests, os import time, re, dat ...
- python3爬虫爬取猫眼电影TOP100(含详细爬取思路)
待爬取的网页地址为https://maoyan.com/board/4,本次以requests.BeautifulSoup css selector为路线进行爬取,最终目的是把影片排名.图片.名称.演 ...
- python3爬虫爬取煎蛋网妹纸图片(下篇)2018.6.25有效
分析完了真实图片链接地址,下面要做的就是写代码去实现了.想直接看源代码的可以点击这里 大致思路是:获取一个页面的的html---->使用正则表达式提取出图片hash值并进行base64解码--- ...
随机推荐
- 3springboot:springboot配置文件(配置文件、YAML、属性文件值注入<@Value、@ConfigurationProperties、@PropertySource,@ImportResource、@Bean>)
1.配置文件: springboot默认使用一个全局配置文件 配置文件名是固定的 配置文件有两种(开头均是application,主要是文件的后缀): ->application.prope ...
- 虚拟机Centos安装docker小记
本书记录是参考 <Spring Cloud 与 Docker 微服务架构实战(第二版)>这本书实现的. 记录简单几个命令,安装顺序如下: 1. 安装docker所需的包 sudo yum ...
- Vue 问题记录
Vue 问题记录 汇总日常开发中遇到的关于vue的问题 VeeValidator 语言设置 校验消息默认是英文的,定义中文或其他语言的错误提示消息 import VeeValidate from 'v ...
- 使用npm uninstall卸载express无效
最近在看<node.js开发指南>学习node.js,因为书是2012年的书,对应的各种软件.包的版本就特别老,其中第五章用到express,书中版本用的是2.X版本,而我这边通过npm ...
- String.prototype是什么?
String.prototype用于为某字符串对象新增方法,比如: 在javascript中有一方法replace,它是用于替换某字符串中第一个匹配的字符,如果我们想为它追加一个循环匹配所有字符的方法 ...
- HDU 1009 FatMouse' Trade(简单贪心 物品可分割的背包问题)
传送门: http://acm.hdu.edu.cn/showproblem.php?pid=1009 FatMouse' Trade Time Limit: 2000/1000 MS (Java/O ...
- jquery固定位置浮动
示例: <!DOCTYPE html> <html> <head> <title>test page</title> <script ...
- Flex布局(一)flex-direction
采用Flex布局的元素,被称为Flex容器(flex container),简称"容器".其所有子元素自动成为容器成员,成为Flex项目(Flex item),简称"项目 ...
- 数据库函数(Left、Right)
MySQL 字符串截取函数:left(), right(), substring(), substring_index().还有 mid(), substr().其中,mid(), substr() ...
- #leetcode刷题之路7- 整数反转
给出一个 32 位的有符号整数,你需要将这个整数中每位上的数字进行反转. 示例 1:输入: 123输出: 321 示例 2:输入: -123输出: -321 示例 3:输入: 120输出: 21 #i ...