JavaWeb HTTP
1. Http协议
1.1. 什么是Http协议
Http的全称为HyperText Transfer Protocol,译为超文本传输协议,是一种详细规定了浏览器和万维网服务器之间互相通信的规则,通过因特网传送万维网文档的数据传送协议。是互联网上应用最为广泛的一种网络协议。
1.2. 百度百科
HTTP是Hyper Text Transfer Protocol(超文本传输协议)的缩写。它的发展是万维网协会(World Wide Web Consortium)和Internet工作小组IETF(Internet Engineering Task Force)合作的结果,(他们)最终发布了一系列的RFC,RFC 1945[7] 定义了HTTP/1.0版本。其中最著名的就是RFC 2616 。RFC 2616定义了今天普遍使用的一个版本——HTTP 1.1。为纪念Tim Berners-Lee提出HTTP后对互联网发展的贡献,万维网协会保留有他最原始提交的版本 。
HTTP协议(HyperText Transfer Protocol,超文本传输协议)是用于从WWW服务器传输超文本到本地浏览器的传送协议。它可以使浏览器更加高效,使网络传输减少。它不仅保证计算机正确快速地传输超文本文档,还确定传输文档中的哪一部分,以及哪部分内容首先显示(如文本先于图形)等 。
HTTP是一个应用层协议,由请求和响应构成,是一个标准的客户端服务器模型。HTTP是一个无状态的协议。
1.3. 维基百科
HTTP是一个客户端终端(用户)和服务器端(网站)请求和应答的标准(TCP)。通过使用Web浏览器、网络爬虫或者其它的工具,客户端发起一个HTTP请求到服务器上指定端口(默认端口为80)。我们称这个客户端为用户代理程序(user agent)。应答的服务器上存储着一些资源,比如HTML文件和图像。我们称这个应答服务器为源服务器(origin server)。在用户代理和源服务器中间可能存在多个“中间层”,比如代理、网关或者隧道(tunnel)。
尽管TCP/IP协议是互联网上最流行的应用,HTTP协议中,并没有规定必须使用它或它支持的层。事实上,HTTP可以在任何互联网协议上,或其他网络上实现。HTTP假定其下层协议提供可靠的传输。因此,任何能够提供这种保证的协议都可以被其使用。因此也就是其在TCP/IP协议族使用TCP作为其传输层。
通常,由HTTP客户端发起一个请求,创建一个到服务器指定端口(默认是80端口)的TCP连接。HTTP服务器则在那个端口监听客户端的请求。一旦收到请求,服务器会向客户端返回一个状态,比如"HTTP/1.1 200 OK",以及返回的内容,如请求的文件、错误消息、或者其它信息。
1.4. 发展历史
超文本传输协议的前身是世外桃源(Xanadu)项目,超文本的概念是泰德˙纳尔森(Ted Nelson)在1960年代提出的。进入哈佛大学后,纳尔森一直致力于超文本协议和该项目的研究,但他从未公开发表过资料。1989年,蒂姆˙伯纳斯˙李(Tim Berners Lee)在CERN(欧洲原子核研究委员会 = European Organization for Nuclear Research)担任软件咨询师的时候,开发了一套程序,奠定了万维网(WWW = World Wide Web)的基础。1990年12月,超文本在CERN首次上线。1991年夏天,继Telnet等协议之后,超文本转移协议成为互联网诸多协议的一分子。
当时,Telnet协议解决了一台计算机和另外一台计算机之间一对一的控制型通信的要求。邮件协议解决了一个发件人向少量人员发送信息的通信要求。文件传输协议解决一台计算机从另外一台计算机批量获取文件的通信要求,但是它不具备一边获取文件一边显示文件或对文件进行某种处理的功能。新闻传输协议解决了一对多新闻广播的通信要求。而超文本要解决的通信要求是:在一台计算机上获取并显示存放在多台计算机里的文本、数据、图片和其他类型的文件;它包含两大部分:超文本转移协议和超文本标记语言(HTML)。HTTP、HTML以及浏览器的诞生给互联网的普及带来了飞跃 。
1.5. Http/1.0与Http/1.1
Http/1.0这是第一个在通讯中指定版本号的HTTP协议版本,至今仍被广泛采用,特别是在代理服务器中。使用Http/1.0协议版本,客户端与服务器端建立链接后,只能获取一个Web资源。
Http/1.1当前版本。持久连接被默认采用,并能很好地配合代理服务器工作。还支持以管道方式在同时发送多个请求,以便降低线路负载,提高传输速度。使用Http/1.1协议版本,客户端与服务器端建立链接后,可以获取多个Web资源。
HTTP/1.1相较于HTTP/1.0协议的区别主要体现在:
- 缓存处理
- 带宽优化及网络连接的使用
- 错误通知的管理
- 消息在网络中的发送
- 互联网地址的维护
- 安全性及完整性
1.6. URL和URI
URL的全称为Uniform Resource Locator,译为统一资源定位符。URL是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
URI的全称为Uniform Resource Identifier,译为统一资源标志符。URI是一个用于标识某一互联网资源名称的字符串。 该种标识允许用户对网络中(一般指万维网)的资源通过特定的协议进行交互操作。URI由包括确定语法和相关协议的方案所定义。
2. 相关工具
2.1. IE浏览器的HttpWatch
- 双击HttpWatch安装文件,开始安装HttpWatch工具。

- 点击“Next”按钮,继续安装过程。

- 选择HttpWatch许可文件后,点击“Next”按钮,继续安装过程。
- 点击“I Agree”按钮,继续安装过程。
- 勾掉“Add HttpWatch plug-in to Firefox”选项,取消安装火狐浏览器插件。点击“Next”按钮,继续安装过程。

- 选择自定义安装目录后,点击“Install”按钮,继续安装过程。
- 勾掉“Display Getting Started instructions”选项,点击“Finish”按钮,结束安装过程。
2.2. 火狐浏览器的Firebug
- 首先我们需要安装火狐浏览器。
- 安装火狐浏览器成功后,我们可以运行火狐浏览器。
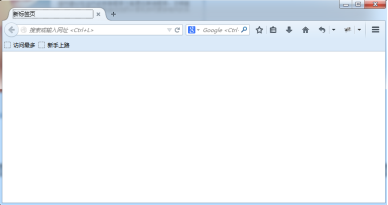
- 我们可以在线安装Firebug工具插件:在火狐浏览器右上角点击菜单,在菜单中选择“附加组件”。
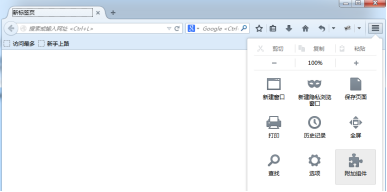
- 在附加组件界面的搜索框中输入“firebug”关键字,查找对应内容。

- 选择Firebug,点击安装即可。
- 我们也可以离线安装Firebug工具插件。
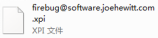
- 将Firebug离线安装文件,拖拽到火狐浏览器中。
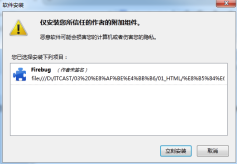
- 选择“立刻安装”即可。
2.3. 谷歌浏览器的开发模式
- 首先我们需要安装谷歌浏览器。

- 安装谷歌浏览器成功后,我们可以运行谷歌浏览器。
- 在谷歌浏览器右上角点击菜单,在菜单中选择“工具”,并选择“开发者工具”选项。
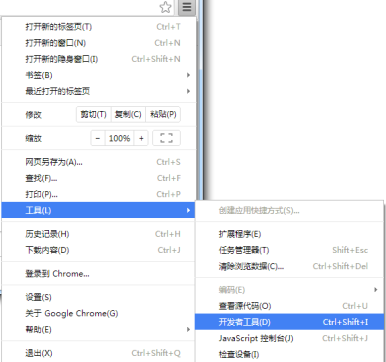
- 启动谷歌浏览器中的开发者模式。

3. 请求协议
3.1. GET方式请求
我们通过一个案例来研究GET方式请求协议是怎么样的。
- 建立一个HTML页面,用于GET方式请求。
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<title>01_get.html</title>
<meta http-equiv="keywords" content="keyword1,keyword2,keyword3">
<meta http-equiv="description" content="this is my page">
<meta http-equiv="content-type" content="text/html; charset=UTF-8">
</head>
<body>
<h1>GET方式请求</h1>
<form id="userinfo" method="get" action="01_get.html">
用户名:<input type="text" id="username" name="username">
<input type="submit" id="submit" value="提交">
</form>
</body>
</html>
- 将当前工程发布到Tomcat服务器中运行,启动Tomcat服务器。
- 打开浏览器,输入http://localhost:8080/http/01_get.html地址访问对应页面。
- 打开HttpWatch工具,并抓去GET方式请求信息。
通过上述案例,我们可以获取GET方式的请求信息,具体内容如下:
GET /http/01_get.html HTTP/1.1
Accept: application/x-ms-application, image/jpeg, application/xaml+xml, image/gif, image/pjpeg, application/x-ms-xbap, */*
Referer: http://localhost:8080/http/01_get.html
Accept-Language: zh-CN
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; qdesk 2.5.1277.202; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; InfoPath.3)
Accept-Encoding: gzip, deflate
If-Modified-Since: Thu, 11 Sep 2014 02:44:35 GMT
If-None-Match: W/"679-1410403475587"
Host: localhost:8080
Connection: Keep-Alive
请求协议主要组成部分为请求行、请求头和请求体。在上述GET方式的请求协议信息中:
- 请求行为:GET /http/01_get.html HTTP/1.1
- 请求头为:
Accept: application/x-ms-application, image/jpeg, application/xaml+xml, image/gif, image/pjpeg, application/x-ms-xbap, */*
Referer: http://localhost:8080/07_http/01_get.html
Accept-Language: zh-CN
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; qdesk 2.5.1277.202; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; InfoPath.3)
Accept-Encoding: gzip, deflate
If-Modified-Since: Thu, 11 Sep 2014 02:44:35 GMT
If-None-Match: W/"679-1410403475587"
Host: localhost:8080
Connection: Keep-Alive
- 请求体为空。
请求行中包含请求方式、资源路径和协议版本。其中GET是请求方式,/http/01_get.html是资源路径,HTTP/1.1是协议版本。
请求头中的信息格式是以Key:Value,Value形式存在,具体解释如下:
|
请求头信息 |
说明 |
|
Accept: application/x-ms-application, image/jpeg, |
客户端识别文件类型 |
|
Referer: http://localhost:8080/http/01_get.html |
防止盗链 |
|
Accept-Language: zh-CN |
客户端语言 |
|
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; qdesk 2.5.1277.202; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; InfoPath.3) |
浏览器类型 |
|
Accept-Encoding: gzip, deflate |
客户端支持编码类型 |
|
If-Modified-Since: Thu, 11 Sep 2014 02:44:35 GMT |
控制缓存 |
|
If-None-Match: W/"679-1410403475587" |
判断资源是否改变 |
|
Host: localhost:8080 |
访问服务器地址 |
|
Connection: Keep-Alive |
请求后链接状态 |
GET方式的请求协议中,请求体为空。原因是发送的参数内容增加在请求链接的后面。
GET方式的请求协议中,请求参数被增加到URL地址中,其长度通常会被限制,一般情况下是1kb。
3.2. POST方式请求
我们通过一个案例来研究GET方式请求协议是怎么样的。
- 建立一个HTML页面,用于POST方式请求。
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<title>02_post.html</title>
<meta http-equiv="keywords" content="keyword1,keyword2,keyword3">
<meta http-equiv="description" content="this is my page">
<meta http-equiv="content-type" content="text/html; charset=UTF-8">
</head>
<body>
<h1>POST方式请求</h1>
<form id="userinfo" method="post" action="02_post.html">
用户名:<input type="text" id="username" name="username">
年龄:<input type="text" id="age" name="age">
<input type="submit" id="submit" value="提交">
</form>
</body>
</html>
- 将当前工程发布到Tomcat服务器中运行,启动Tomcat服务器。
- 打开浏览器,输入http://localhost:8080/http/02_post.html地址访问对应页面。
- 打开HttpWatch工具,并抓去POST方式请求信息。
通过上述案例,我们可以获取GET方式的请求信息,具体内容如下:
POST /http/02_post.html HTTP/1.1
Accept: application/x-ms-application, image/jpeg, application/xaml+xml, */*
Referer: http://localhost:8080/http/02_post.html
Accept-Language: zh-CN
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; qdesk 2.5.1277.202; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; InfoPath.3)
Content-Type: application/x-www-form-urlencoded
Accept-Encoding: gzip, deflate
Host: localhost:8080
Content-Length: 25
Connection: Keep-Alive
Cache-Control: no-cache username=zhangwuji&age=18
POST方式的请求协议同样包含请求行、请求头和请求体。在上述POST方式的请求协议信息中:
- 请求行为:POST /http/02_post.html HTTP/1.1。其中POST是请求方式,/http/02_post.html是资源路径,HTTP/1.1是协议版本。
- 请求头为:
Accept: application/x-ms-application, image/jpeg, application/xaml+xml, */*
Referer: http://localhost:8080/07_http/02_post.html
Accept-Language: zh-CN
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; qdesk 2.5.1277.202; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; InfoPath.3)
Content-Type: application/x-www-form-urlencoded
Accept-Encoding: gzip, deflate
Host: localhost:8080
Content-Length: 25
Connection: Keep-Alive
Cache-Control: no-cache
- 请求体为username=zhangwuji&age=18。请求体的内容主要是请求参数,格式是以Key:Value形式存在。
3.3. 防止盗链案例
首先我们要清楚什么是盗链,所谓盗链就是指服务提供商自己不提供服务的内容,通过技术手段绕过其它有利益的最终用户界面(如广告),直接在自己的网站上向最终用户提供其它服务提供商的服务内容,骗取最终用户的浏览和点击率。受益者不提供资源或提供很少的资源,而真正的服务提供商却得不到任何的收益。
防止其他网站盗链的原理,就是利用请求协议中的Referer来控制。实现方式就是在服务器端判断请求协议中的Referer的信息是否正确,如果正确就返回响应的内容,否则就无返回。
下面我们就模拟一下网站防止盗链的原理。
- 首先我们创建一个网站的主页面。
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<title>index.html</title>
<meta http-equiv="keywords" content="keyword1,keyword2,keyword3">
<meta http-equiv="description" content="this is my page">
<meta http-equiv="content-type" content="text/html; charset=UTF-8">
</head>
<body>
<a href="refererServlet">特价商品</a>
</body>
</html>
- 然后我们完成服务器端防止盗链的逻辑内容。
public class RefererServlet extends HttpServlet {
// 处理GET方式的请求
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// 判断请求中referer是否存在,有效 --- 防止盗链
String referer = request.getHeader("referer");
if(referer!=null && referer.equals("http://localhost:8080/http/index.html")){
// 有效
response.setContentType("text/html;charset=utf-8");
response.getWriter().println("笔记本1000元");
}else{
// 无效
response.setContentType("text/html;charset=utf-8");
response.getWriter().println("盗链真无耻!");
}
}
// 处理POST方式的请求
public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doGet(request, response);
}
}
- 将工程发布到Tomcat服务器,启动Tomcat服务器。
- 打开浏览器,输入http://localhost:8080/http/index.html地址。
- 在网站主页面中,点击“特价商品”链接,会返回正确内容。
- 如果在浏览器地址栏中直接输入http://localhost:8080/http/refererServlet链接。
- 由于直接输入链接地址的请求协议中,没有referer信息,所以会显示报错信息。
那我们是否可以编写程序来伪造referer信息进行请求,以达到对应的内容呢?答案当然是可以的。下面我们就看一下是如何伪造referer信息进行请求:
创建一个Java文件用于伪造referer信息进行发送请求。
public class URLClient {
public static void main(String[] args) throws Exception {
// 建立访问目标URL对象
URL url = new URL("http://localhost:8080/http/refererServlet");
// 建立目标URL连接
URLConnection urlConnection = url.openConnection();
// 伪造referer
urlConnection.addRequestProperty("referer", "http://localhost:8080/http/index.html");
// 抓取响应内容
byte[] buf = new byte[8192];
int len = urlConnection.getInputStream().read(buf);
// 输出内容
System.out.println(new String(buf,0,len));
}
}
4. 响应协议
4.1. 响应协议内容
无论请求方式是GET还是POST,响应协议内容基本都一致。下面我们就之前的案例中,研究响应协议的具体内容。
HTTP/1.1 200 OK
Server: Apache-Coyote/1.1
Accept-Ranges: bytes
ETag: W/"662-1410404751091"
Last-Modified: Thu, 11 Sep 2014 03:05:51 GMT
Content-Type: text/html
Content-Length: 662
Date: Thu, 11 Sep 2017 07:54:30 GMT
响应协议内容主要分为响应行、响应头和响应体。在上述响应协议信息中:
- 响应行:HTTP/1.1 200 OK
在响应行中,其中HTTP/1.1为协议版本,200表示状态码,OK则为表述信息。常用的状态码有以下几种:
|
状态码 |
说明 |
|
200 |
表示请求处理成功。 |
|
302 |
表示请求被重定向。 |
|
304 |
表示服务器端资源没有改变,查找本地缓存。 |
|
404 |
表示客户端访问资源不存在。 |
|
500 |
表示服务器端内部出现错误。 |
- 响应头:
Server: Apache-Coyote/1.1
Accept-Ranges: bytes
ETag: W/"662-1410404751091"
Last-Modified: Thu, 11 Sep 2014 03:05:51 GMT
Content-Type: text/html
Content-Length: 662
Date: Thu, 11 Sep 2017 07:54:30 GMT
响应头中的信息格式是以Key:Value,Value形式存在,具体解释如下:
|
响应头 |
说明 |
|
Location: http://www.localhost:8080/index.html |
重定向跳转到的地址 |
|
Server: Apache-Coyote/1.1 |
服务器类型 |
|
Content-Encoding: gzip |
响应编码类型 |
|
Accept-Ranges: bytes |
服务器端是否接收请求 |
|
Last-Modified: Thu, 11 Sep 2014 03:05:51 GMT |
服务器端缓存策略 |
|
Content-Type: text/html |
响应字符集编码 |
|
Content-Length: 662 |
响应长度 |
|
Refresh: 1;url=http:// www.localhost:8080 |
页面自动刷新 |
|
Date: Thu, 11 Sep 2014 07:54:30 GMT |
响应时间 |
|
Expires: -1 |
禁用浏览器缓存(考虑不同浏览器兼容性,存在三个字段) |
|
Cache-Control: no-cache |
|
|
Pragma: no-cache |
- 响应体:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head>
<title>01_get.html</title>
<meta http-equiv="keywords" content="keyword1,keyword2,keyword3">
<meta http-equiv="description" content="this is my page">
<meta http-equiv="content-type" content="text/html; charset=UTF-8">
</head>
<body>
<h1>GET方式请求</h1>
<form id="userinfo" method="get" action="01_get.html">
用户名:<input type="text" id="username" name="username">
<input type="submit" id="submit" value="提交">
</form>
</body>
</html>
4.2. 请求重定向案例
我们可以利用响应协议中的状态码和Location信息,完成页面的重定向功能。具体的做法如下:
- 创建一个Java文件来完成请求时,重定向到其他页面功能。
public class RedirectServlet extends HttpServlet {
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
// 设置状态码 302
response.setStatus(302);
// 指定重定向页面地址
response.setHeader("Location", "index.html");
}
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doGet(request, response);
}
}
- 将工程发布到Tomcat服务器,启动Tomcat服务器。
- 打开浏览器,在地址栏中输入http://localhost:8080/http/redirectServlet。
通过上述案例,我们可以看到,请求之后响应信息中显示状态码为302,Location的值为index.html。实际运行效果自动跳转到index.html页面。
4.3. 自动刷新案例
我们可以利用响应协议中的refresh完成页面自动刷新的功能,具体实现方式如下:
- 创建一个Java文件来完成请求时,自动刷新到对应页面。
public class RefreshServlet extends HttpServlet {
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
// 设置refresh
response.setHeader("refresh", "5;url=index.html");
// 显示提示信息
response.setContentType("text/html;charset=utf-8");
response.getWriter().println("网页会在5秒后 跳转 index.html");
}
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doGet(request, response);
}
}
- 将工程发布到Tomcat服务器,启动Tomcat服务器。
- 打开浏览器,在地址栏中输入http://localhost:8080/http/refreshServlet。
通过上述案例,我们可以看到,请求在5秒之后,自动跳转到index.html页面。
4.4. gzip压缩案例
gzip是一种压缩格式,在请求和响应中使用压缩格式的好处,就是可以节省带宽资源。Tomcat服务器本身提供了gzip格式的压缩功能,下面我们通过具体的操作来看一看。
- 首先我们需要清空一下浏览器的缓存内容。
- 点击“工具”->“Internet选项”。
- 点击“浏览历史记录”栏中的“设置”按钮。
- 点击“查看文件”按钮,弹出浏览器缓存文件存储的文件夹,将其全部删除。
- 重新打开浏览器,访问Tomcat服务器的主页http://localhost:8080。
我们可以看到加入文件大小为11573KB,下面我们配置Tomcat服务器的gzip压缩格式,来看看压缩之后的大小。
- 进入到Tomcat服务器的安装目录中,找到conf目录中的server.xml文件并配置。
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443"
compressableMimeType="text/html,text/xml,text/plain"
compression="on"/>
- 重新启动Tomcat服务器,并清空浏览器的缓存内容,再次访问Tomcat服务器的主页。
我们可以看到大小为2281KB,文件已经被压缩。当然,这是使用了Tomcat服务器自身提供的功能。
4.5. 缓存策略案例
所谓缓存策略就是指将客户机本地的物理内存划分出一部分空间用来缓冲客户机回写到服务器的数据。实现原理是当客户端第一次请求服务器端时,缓存策略会将一些静态资源存储在客户端中。如果在之后的请求中,服务器端相关资源没有变化的话,服务器端会返回304状态码,客户端会直接读取本地缓存文件。这样做的好处是节省带宽资源。Tomcat服务器自身提供了缓存策略,下面我们来实际看一看。
- 首先清空浏览器中的所有缓存内容。
- 重新打开浏览器,在地址栏中输入http://localhost:8080,访问Tomcat服务器的主页。
- 然后点击浏览器中的刷新按钮,重新载入Tomcat服务器的主页。
通过上述操作我们可以发现,在重新刷新页面之后,大小是123KB,响应状态码为304,这表示第二次加载Tomcat服务器的主页时,访问的是本地缓存内容。
JavaWeb HTTP的更多相关文章
- 从啥也不会到可以胜任最基本的JavaWeb工作,推荐给新人的学习路线(二)
在上一节中,主要阐述了JavaScript方面的学习路线.先列举一下我朋友的经历,他去过培训机构,说是4个月后月薪过万,虽然他现在还未达到这个指标. 培训机构一般的套路是这样:先教JavaSE,什么都 ...
- JavaWeb——Servlet
一.基本概念 Servlet是运行在Web服务器上的小程序,通过http协议和客户端进行交互. 这里的客户端一般为浏览器,发送http请求(request)给服务器(如Tomcat).服务器接收到请求 ...
- JavaWeb——Listener
一.基本概念 JavaWeb里面的listener是通过观察者设计模式进行实现的.对于观察者模式,这里不做过多介绍,大概讲一下什么意思. 观察者模式又叫发布订阅模式或者监听器模式.在该模式中有两个角色 ...
- .JavaWeb文件上传和FileUpload组件使用
.JavaWeb文件上传 1.自定义上传 文件上传时的表单设计要符合文件提交的方式: 1.提交方式:post 2.表单中有文件上传的表单项:<input type="file" ...
- javaWeb应用打包
在Java中,使用"jar"命令来对将JavaWeb应用打包成一个War包,jar命令的用法如下:
- JavaWeb——tomcat安装及目录介绍
一.web web可以说,就是一套 请求->处理->响应 的流程.客户端使用浏览器(IE.FireFox等),通过网络(Network)连接到服务器上,使用HTTP协议发起请求(Reque ...
- 做JavaWeb开发不知Java集合类不如归家种地
Java作为面向对象语言对事物的体现都是以对象的形式,为了方便对多个对象的操作,就要对对象进行存储.但是使用数组存储对象方面具有一些弊端,而Java 集合就像一种容器,可以动态地把多个对象的引用放入容 ...
- JavaWeb基础学习体系与学习思路
对于JAVAWEB的学习,首先一定要明确的是学习整体框架和思路,要有一个把控.对于WEB,很多人认为是做网页,简单的把静态网页与JAVAWEB与网页设计一概而论. 拿起一本JS就开始无脑的学习,学了一 ...
- Eclipse下配置javaweb项目快速部署到tomcat
用惯了VS,再用Eclipse,完全有一种从自动挡到手动挡的感觉啊. 很多同学在Eclipse下开发web项目,每一次修改代码,看效果的时候都有右键项目->Run as -> Run on ...
- javaweb学习笔记之servlet01
一.Servlet概述 A servlet is a small Java program that runs within a Web server. Servlets receive and re ...
随机推荐
- MathType可以在Word、PPT中插入矩阵吗
工科学生或者老师在写论文时最头痛的就是编辑公式,因为word自带的公式编辑器往往满足不了专业的公式需求,MathType就很好的解决了这个问题.在进行公式编辑时,难免会遇到输入矩阵的情况,那么怎么输入 ...
- HTML DOM和BOM常用操作总结
JavaScript Code 1234567891011121314151617181920212223242526272829303132333435363738394041424344454 ...
- iOS -转载-使用Navicat查看数据表的ER关系图
Navicat软件真是一个好东西.今天需要分析一个数据库,然后想看看各个表之间的关系,所以需要查看表与表之间的关系图,专业术语叫做ER关系图. 默认情况下,Navicat显示的界面是这样的: 软件将表 ...
- sql优化(1)
转自:https://blog.csdn.net/jie_liang/article/details/77340905 在sql查询中为了提高查询效率,我们常常会采取一些措施对查询语句进行sql优化, ...
- 巨蟒python全栈开发-第10天 函数进阶
一.今日主要内容总览(重点) 1.动态传参(重点) *,** *: 形参:聚合 位置参数*=>元组 关键字**=>字典 实参:打散 列表,字符串,元组=>* 字典=>** 形参 ...
- 网络编程4 网络编程之FTP上传简单示例&socketserver介绍&验证合法性连接
今日大纲: 1.FTP上传简单示例(详细代码) 2.socketserver简单示例&源码介绍 3.验证合法性连接//[秘钥加密(urandom,sendall)(注意:中文的!不能用)] 内 ...
- Linux网络配置:设置IP地址、网关DNS、主机名
查看网络信息 1.ifconfig eth0 2.ifconfig -a 3.ip add 设置主机名需改配置文件: /etc/hosts /etc/sysconfig/network vim /et ...
- 【转】windows 下 goprotobuf 的安装与使用
1. 安装 在网上看了很多教程,都提到要安装 protoc 与 protoc-gen-go,但通过尝试之后并不能正确安装 protoc,一下记录能够顺利安装 protoc 与 protoc-gen-g ...
- 实践中需要了解的cpu特性
目录 分段机制 特权级检查 GDT和LDT 堆栈切换 分页机制 中断 分段机制 实模式中cs是一个实实在在的段首地址,ip为cs所指向段的偏移,所以cs<<4+ip是当前cpu执行的指令. ...
- C/C++运算符及其优先级
1.自增自减 (1)前置运算:"先变后用" 如++i. 后置运算:"先用后变" 如i--. 比如: int i = 5. y1 = ++i: y2 = ...