sqoop数据导入到Hdfs 或者hive
用java代码调用shell脚本执行sqoop将hive表中数据导出到mysql
http://www.cnblogs.com/xuyou551/p/7999773.html
用sqoop将mysql的数据导入到hive表中
https://www.cnblogs.com/xuyou551/p/7998846.html
1:先将mysql一张表的数据用sqoop导入到hdfs中
准备一张表

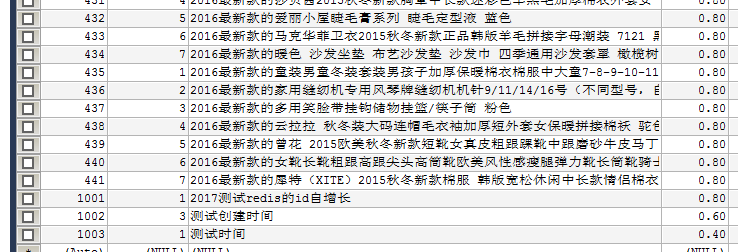
需求 将 bbs_product 表中的前100条数据导 导出来 只要id brand_id和 name 这3个字段
数据存在 hdfs 目录 /user/xuyou/sqoop/imp_bbs_product_sannpy_ 下

bin/sqoop import \
--connect jdbc:mysql://172.16.71.27:3306/babasport \
--username root \
--password root \
--query 'select id, brand_id,name from bbs_product where $CONDITIONS LIMIT 100' \
--target-dir /user/xuyou/sqoop/imp_bbs_product_sannpy_ \
--delete-target-dir \
--num-mappers 1 \
--compress \
--compression-codec org.apache.hadoop.io.compress.SnappyCodec \
--fields-terminated-by '\t'
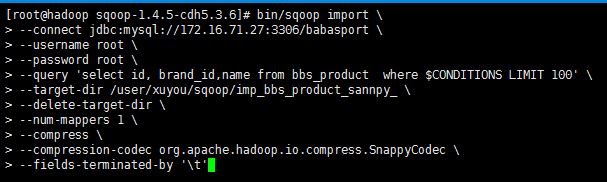
ps: 如果导出的数据库是mysql 则可以添加一个 属性 --direct
1 bin/sqoop import \
2 --connect jdbc:mysql://172.16.71.27:3306/babasport \
3 --username root \
4 --password root \
5 --query 'select id, brand_id,name from bbs_product where $CONDITIONS LIMIT 100' \
6 --target-dir /user/xuyou/sqoop/imp_bbs_product_sannpy_ \
7 --delete-target-dir \
8 --num-mappers 1 \
9 --compress \
10 --compression-codec org.apache.hadoop.io.compress.SnappyCodec \
11 --direct \
12 --fields-terminated-by '\t'
加了 direct 属性在导出mysql数据库表中的数据会快一点 执行的是mysq自带的导出功能
第一次执行所需要的时间

第二次执行所需要的时间 (加了direct属性)

执行成功

2:启动hive 在hive中创建一张表
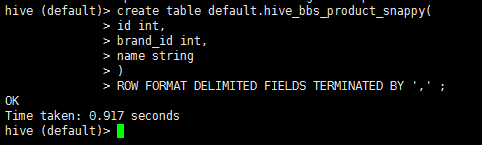
1 drop table if exists default.hive_bbs_product_snappy ;
2 create table default.hive_bbs_product_snappy(
3 id int,
4 brand_id int,
5 name string
6 )
7 ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ;
3:将hdfs中的数据导入到hive中
1 load data inpath '/user/xuyou/sqoop/imp_bbs_product_sannpy_' into table default.hive_bbs_product_snappy ;

4:查询 hive_bbs_product_snappy 表
1 select * from hive_bbs_product_snappy;

此时hdfs 中原数据没有了

然后进入hive的hdfs存储位置发现

注意 :sqoop 提供了 直接将mysql数据 导入 hive的 功能 底层 步骤就是以上步骤
创建一个文件 touch test.sql 编辑文件 vi test.sql
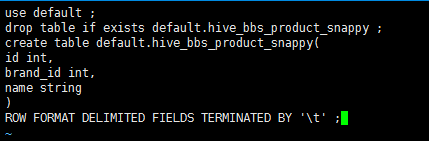
1 use default;
2 drop table if exists default.hive_bbs_product_snappy ;
3 create table default.hive_bbs_product_snappy(
4 id int,
5 brand_id int,
6 name string
7 )
8 ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ;
在 启动hive的时候 执行 sql脚本
bin/hive -f /opt/cdh-5.3.6/sqoop-1.4.5-cdh5.3.6/test.sql


执行sqoop直接导入hive的功能
1 bin/sqoop import \
2 --connect jdbc:mysql://172.16.71.27:3306/babasport \
3 --username root \
4 --password root \
5 --table bbs_product \
6 --fields-terminated-by '\t' \
7 --delete-target-dir \
8 --num-mappers 1 \
9 --hive-import \
10 --hive-database default \
11 --hive-table hive_bbs_product_snappy
看日志输出可以看出 在执行map任务之后 又执行了load data

查询 hive 数据

sqoop数据导入到Hdfs 或者hive的更多相关文章
- Sqoop(三)将关系型数据库中的数据导入到HDFS(包括hive,hbase中)
一.说明: 将关系型数据库中的数据导入到 HDFS(包括 Hive, HBase) 中,如果导入的是 Hive,那么当 Hive 中没有对应表时,则自动创建. 二.操作 1.创建一张跟mysql中的i ...
- 使用 sqoop 将mysql数据导入到hdfs(import)
Sqoop 将mysql 数据导入到hdfs(import) 1.创建mysql表 CREATE TABLE `sqoop_test` ( `id` ) DEFAULT NULL, `name` va ...
- sqoop数据导入命令 (sql---hdfs)
mysql------->hdfs sqoop导入数据工作流程: sqoop提交任务到hadoop------>hadoop启动mapreduce------->mapreduce通 ...
- Sqoop1.99.7将MySQL数据导入到HDFS中
准备 本示例将实现从MySQL数据库中将数据导入到HDFS中 参考文档: http://sqoop.apache.org/docs/1.99.7/user/Sqoop5MinutesDemo.html ...
- 使用Sqoop从mysql向hdfs或者hive导入数据时出现的一些错误
1.原表没有设置主键,出现错误提示: ERROR tool.ImportTool: Error during import: No primary key could be found for tab ...
- Sqoop 数据导入导出实践
Sqoop是一个用来将hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如:mysql,oracle,等)中的数据导入到hadoop的HDFS中,也可以将HDFS的数据导入到 ...
- sqoop 数据导入hive
一. sqoop: mysql->hive sqoop import -m 1 --hive-import --connect "jdbc:mysql://127.0.0.1:3306 ...
- Sqoop mysql 数据导入到hdfs
1.--direct 模式使用mysqldump 工具,所以节点上需要安装该工具,非direct 模式直接使用jdbc ,所以不需要 具体script参考如下: sqoop import --conn ...
- Hadoop Hive概念学习系列之HDFS、Hive、MySQL、Sqoop之间的数据导入导出(强烈建议去看)
Hive总结(七)Hive四种数据导入方式 (强烈建议去看) Hive几种数据导出方式 https://www.iteblog.com/archives/955 (强烈建议去看) 把MySQL里的数据 ...
随机推荐
- [LintCode] A + B 问题
Bit-by-Bit summation: class Solution { public: /* * @param a: The first integer * @param b: The seco ...
- bootstrap 媒体查询
//各类设备的分辨率 /*超小设备(手机,小于768px)*/ /* Bootstrap 中默认情况下没有媒体查询 */ /*超小型设备(小于768px)*/ @media (min-width:@s ...
- CodeFores 665D Simple Subset(贪心)
D. Simple Subset time limit per test 1 second memory limit per test 256 megabytes input standard inp ...
- Java基础系列(八)序列化与反序列化
先来看两个例子 示例一:将对象保存成字节数组,再把对象的字节数组还原为对象 示例中用到的Bean package com.huawei.beans; import java.io.Serializab ...
- 《挑战程序设计竞赛》2.5 最短路 AOJ0189 2249 2200 POJ3255 2139 3259 3268(5)
AOJ0189 http://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=0189 题意 求某一办公室到其他办公室的最短距离. 多组输入,n表示 ...
- tcp连接是基于socket通信的吗
https://zhidao.baidu.com/question/1305788160020716299.html ------ 网络七层协议 五层模型 TCP连接 HTTP连接 socket套接字 ...
- 第05章—Swagger2打造在线接口文档
spring boot 系列学习记录:http://www.cnblogs.com/jinxiaohang/p/8111057.html 码云源码地址:https://gitee.com/jinxia ...
- Spring 框架整合Struts2 框架和 Hibernate 框架
1. Spring 框架整合 Struts2 框架 // [第一种整合方式(不推荐)](http://www.cnblogs.com/linkworld/p/7718274.html) // 从 Se ...
- 转!java web项目 build path 导入jar包,tomcat启动报错 找不到该类
在eclipse集成tomcat开发java web项目时,引入的外部jar包,编译通过,但启动tomcat运行web时提示找不到jar包内的类,需要作如下配置,将jar包在部署到集成的tomcat环 ...
- ZOJ 2770 Burn the Linked Camp 差分约束
链接:http://acm.zju.edu.cn/onlinejudge/showProblem.do? problemCode=2770 Burn the Linked Camp Time Limi ...