借助Chrome和插件爬取数据
![]()
工具
- Chrome浏览器
- TamperMonkey
- ReRes
Chrome浏览器
chrome浏览器是目前最受欢迎的浏览器,没有之一,它兼容大部分的w3c标准和ecma标准,对于前端工程师在开发过程中提供了devtools和插件等工具,非常方便使用。在爬取数据的过程中,最常用的应该是开发工具中的Element、Source和Network功能,分别查看DOM结构,源码和网络请求。同时,有很多基于Chrome浏览器的插件又给我们赋予了浏览器级别的能力,来处理数据。
TamperMonkey
Tampermonkey 是一个chrome插件,是一款免费的浏览器扩展和最为流行的用户脚本管理器。简单来说就是可以指定进入某些页面的时候调用指定的JS代码,这样我们就可以将页面中的某些数据整理出来,并保存到localStorage或者indexeddb中。
ReRes
ReRes是一个chrome的插件,它可以支持将某个在线的JS重定向到另一个JS上,也就是用另一个JS来替代原来页面中的JS,这个新的JS中我们可以修改一部分逻辑来满足我们的需求。
抓取流程
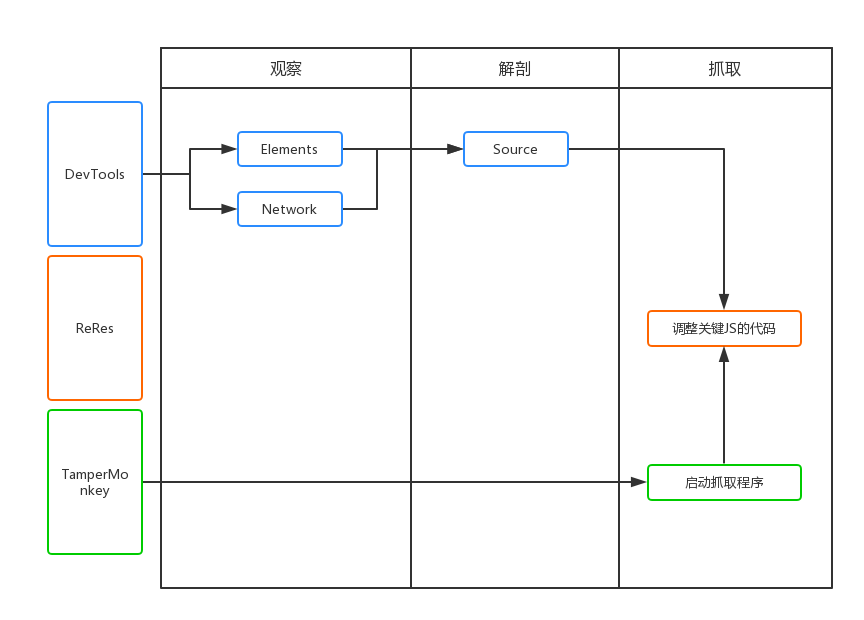
如上图所示,抓取分为三个步骤,分别是观察,解刨和抓取。
观察
首先是观察,我们需要通过devtools中的Elements和Network标签页,对要抓取的页面进行阅读,数据可能是在DOM元素中,也可能是通过Ajax接口直接返回,总之找到从哪里拿数据最合适。
当然,如果数据如果都是Ajax接口的方式返回,都会很容易抓取,但有时候我们可能会碰到比较讲究的网站,它们回对数据进行加密,返回的一个乱码的字符串,这个时候我们需要对代码进行解剖。
解剖
也就是对页面中的逻辑代码进行拆解和分析,找到关键的代码为我所用。通常网站的JS代码都是混淆和压缩过的,我们可以使用Chrome开发工具中的Source工具对代码进行基本的格式化,来方便阅读。然后简单介绍一下我寻找关键代码的方法:
- 元素标签寻找法
- 元素事件寻找法
- Ajax接口名称寻找法
当然,这里在寻找关键字的时候,需要使用Chrome开发者工具的Search功能。
元素标签寻找法
当我们找到一个关键的DOM元素的时候,你认为页面JS会对这个元素做操作,比如取值,删除,等,就可以通过这个元素自带的id或者class来搜索,通常,这些id和类名是不会被混淆的,可以直接找到。
元素事件寻找法
当我们认为某个元素绑定过click或者其他事件,而且具有重要意义,就可以通过Elements面板中的Event Listeners中寻找最有可能的事件,然后查看对应的JS代码。
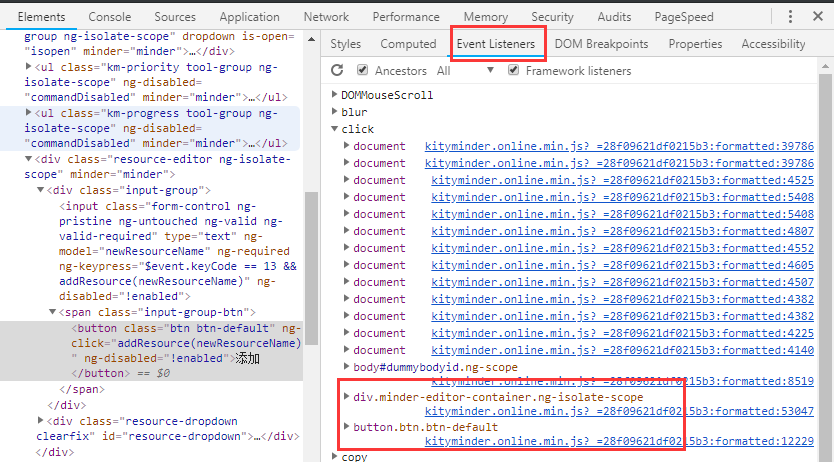
当然如果在Elements面板中的DOM结构上直接标记了方法名,如下图所示,你就可以直接全局Search【CheckInput】。
<input type="submit" name="Editor$Edit$lkbPost" value="发布草稿" onclick="return CheckInput();" id="Editor_Edit_lkbPost" class="Button">
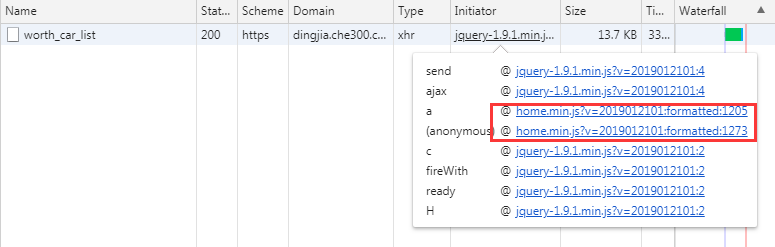
Ajax接口名称寻找法
当我们找到想要的接口的时候,我们在Network中能够找到这个接口的名称,直接全局Seach,或者通过Initiator中JS调用的堆栈信息找到具体调用的代码。
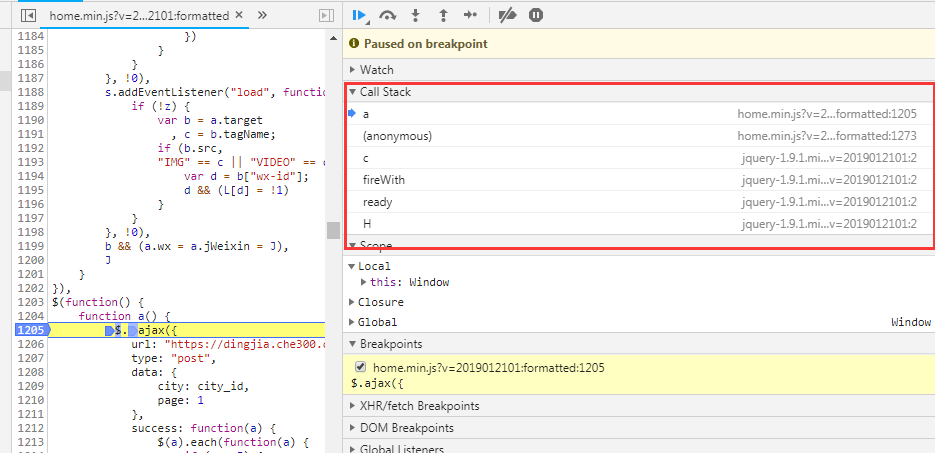
通过这三个步骤,我们基本已经能够找到我们需要的业务代码,剩下就是不断在这个基础上去找加密和解密的逻辑,同样是通过打断点,然后在Source面板中的Callbacks中寻找函数调用的堆栈,然后找到其他的逻辑。
抓取
抓取数据无非就是将数据通过自动化的方式提取,保存到指定的位置即可。
这里我们就要依赖我们的两个插件TamperMonkey和ReRes。我通常将关键JS保存到本地进行修改,然后通过使用ReRes将线上JS映射到本地JS上,然后就可以为所欲为,比如,使用封装好的解密函数解密数据,将数据保存到indexeddb中。
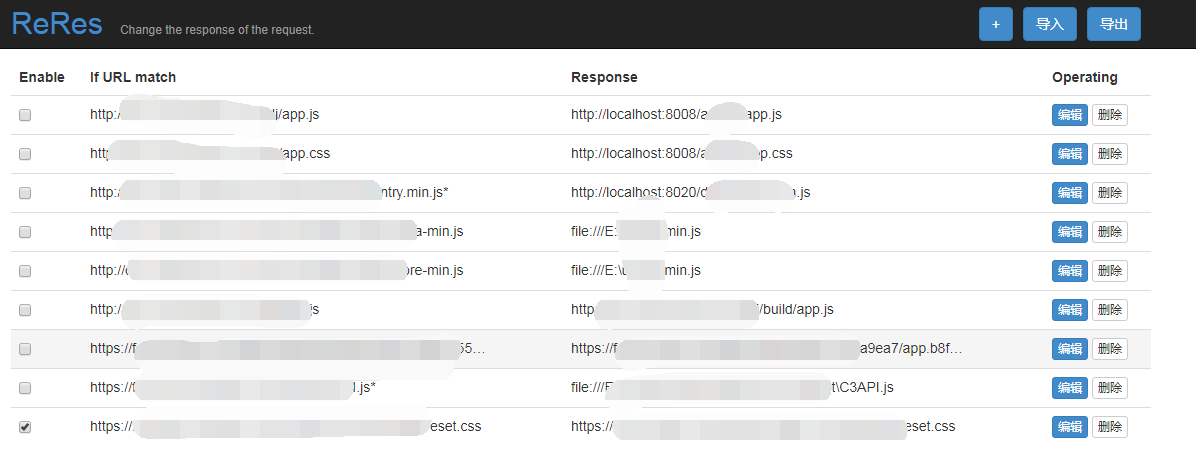
使用TamperMonkey主要是来定义一些全局变量,以及开始启动抓取过程,比如遍历DOM节点,模拟点击事件,记录已抓取的数据的位置。

总结
依赖Chrome浏览器去抓取数据,只是一种方便快捷的抓取方式,当然并不是很实用,因为Chrome不能直接操作数据库,我们的数据还是缓存在了浏览器中,导出就需要花点时间。本文只是讲了部分抓取数据的思路,具体可以使用Puppeteer、Phantomjs等工具来抓取。
借助Chrome和插件爬取数据的更多相关文章
- 【个人】爬虫实践,利用xpath方式爬取数据之爬取虾米音乐排行榜
实验网站:虾米音乐排行榜 网站地址:http://www.xiami.com/chart 难度系数:★☆☆☆☆ 依赖库:request.lxml的etree (安装lxml:pip install ...
- 【Spider】使用CrawlSpider进行爬虫时,无法爬取数据,运行后很快结束,但没有报错
在学习<python爬虫开发与项目实践>的时候有一个关于CrawlSpider的例子,当我在运行时发现,没有爬取到任何数据,以下是我敲的源代码:import scrapyfrom UseS ...
- python模拟浏览器爬取数据
爬虫新手大坑:爬取数据的时候一定要设置header伪装成浏览器!!!! 在爬取某财经网站数据时由于没有设置Header信息,直接被封掉了ip 后来设置了Accept.Connection.User-A ...
- Python分页爬取数据的分析
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 向右奔跑 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- Python实训day07pm【Selenium操作网页、爬取数据-下载歌曲】
练习1-爬取歌曲列表 任务:通过两个案例,练习使用Selenium操作网页.爬取数据.使用无头模式,爬取网易云的内容. ''' 任务:通过两个案例,练习使用Selenium操作网页.爬取数据. 使用无 ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- web scraper——简单的爬取数据【二】
web scraper——安装[一] 在上文中我们已经安装好了web scraper现在我们来进行简单的爬取,就来爬取百度的实时热点吧. http://top.baidu.com/buzz?b=1&a ...
- 关于js渲染网页时爬取数据的思路和全过程(附源码)
于js渲染网页时爬取数据的思路 首先可以先去用requests库访问url来测试一下能不能拿到数据,如果能拿到那么就是一个普通的网页,如果出现403类的错误代码可以在requests.get()方法里 ...
- node.js爬取数据并定时发送HTML邮件
node.js是前端程序员不可不学的一个框架,我们可以通过它来爬取数据.发送邮件.存取数据等等.下面我们通过koa2框架简单的只有一个小爬虫并使用定时任务来发送小邮件! 首先我们先来看一下效果图 差不 ...
随机推荐
- composer安装以及更新问题,配置中国镜像源。
配置国内镜像源 中国镜像源 https://pkg.phpcomposer.com/ composer 中文官网地址 http://www.phpcomposer.com/ 下载 Composer 安 ...
- CentOS6.*安装gitolite
http://www.kankanews.com/ICkengine/archives/64748.shtml 2人收藏此文章, 发表于4小时前(2013-10-22 16:12) , 已有26次阅读 ...
- markdown箭头的处理
转自:https://blog.csdn.net/m0_37167788/article/details/78603307 MarkDown - Latex符号(箭头)的整理 标签: markdown ...
- 理解、学习与使用 Java 中的 Optional
从 Java 8 引入的一个很有趣的特性是 Optional 类.Optional 类主要解决的问题是臭名昭著的空指针异常(NullPointerException) -- 每个 Java 程序员都 ...
- DIV水平垂直布局
<%@ page language="java" pageEncoding="utf-8" import="java.util.*,com.ta ...
- 向combobox控件中添加元素
函数定义: bool FillComboBox(CComboBox* pc, CStringList& slValues, bool bOnlyUniqueValues = false); 函 ...
- linux学习之路(3)
vim编辑器使用 命令模式:控制光标移动,可对文本进行复制.粘贴.删除和查找等工作. 输入模式:正常的文本录入. 末行模式:保存或退出文档,以及设置编辑环境. vim中常用命令: dd 删除(剪切) ...
- Form表单 JSON Content-type解析
Form表单 JSON Content-type解析 1 表单Form概述 在Form表单中,参数一般有: action 表单提交的url method 提交方式:post get name 表单的属 ...
- 第十四章——循环神经网络(Recurrent Neural Networks)(第二部分)
本章共两部分,这是第二部分: 第十四章--循环神经网络(Recurrent Neural Networks)(第一部分) 第十四章--循环神经网络(Recurrent Neural Networks) ...
- 一名合格的Web安全工程师之成长路径
最近经常听到公司的招聘专员反馈应聘者简历“水分”太大,尤其是技术岗位,例如Web安全工程师,明明是初级阶段的菜鸟,就敢写资深Web安全工程师:在几个项目做一些基础打杂的工作,就敢写带过团队,项目经验丰 ...