10分钟入门spark
Spark是硅谷各大公司都在使用的当红炸子鸡,而且有愈来愈热的趋势,所以大家很有必要了解学习这门技术。本文其实是笔者深入浅出hadoop系列的第三篇,标题里把hadoop去掉了因为spark可以不依赖于Hadoop。Spark可以运行在多种持久化系统之上,比如HDFS, Amazon S3, Azure Storage, Cassandra, Kafka。把深入浅出去掉了是因为Spark功能实在太强大(Spark SQL, Spark Streaming, Spark GraphX, Spark MLlib),本文只能抛砖引玉帮大家节省时间入个门,打算以后分专题深入总结一下sql, graph, streaming和machine learning方面的应用。
Spark History
- 2009 project started at UC berkeley's AMP lab
- 2012 first release (0.5)
- 2014 became top level apache project
- 2014 1.0
- 2015 1.5
- 2016 2.0
Spark 起源
map reduce以及之前系统存在的问题
- cluster memory 没有被有效运用
- map reduce重复冗余使用disk I/O,比如前一个job的output存在硬盘中,然后作为下一个job的input,这部分disk I/O如果都在内存中是可以被节省下来的。这一点在ad hoc query上尤为突出,会产生大量的中间文件,而且completion time比中间文件的durability要更为重要。
- map reduce的job要不停重复的做join,算法写起来要不停的tuning很蛋疼。
- 没有一个一站式解决方案,往往需要好几个系统比如mapreduce用来做batch processing,storm用来做stream processing,elastic search用来做交互式exploration。这就造成了冗余的data copy。
- interactive query和stream processing的需求越来越大,比如需要ad hoc analytics和快速的decision-making
- machine learning的需求越来越多
spark的破解方案
- RDD abstraction with rich API
- 充分使用内存
- 一站式提供Spark SQL, Spark Streaming, Spark GraphX, Spark MLlib
spark 架构
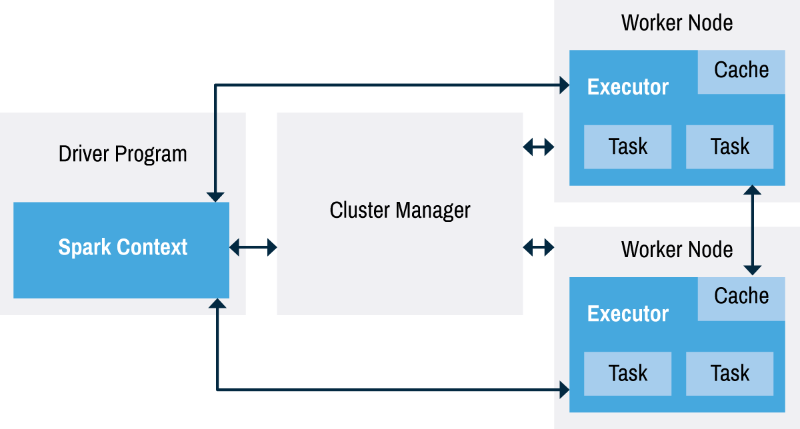
cluster manager: manage to execute tasks could be spark's standalone cluster manager, YARN(参见我之前讲mapreduce的文章) or Mesos。可以用来track当前可用的资源。
Spark applications包括driver process和若干executor processes。driver process是整个spark app的核心,运行main() function, 维护spark application的信息,响应用户输入,分析,distribute并且schedule work across executors。executors用来执行driver分配给它们的task,并把computation state report back to driver。
pyspark 安装
最简单的方式就是在如下地址下载tar包:
https://spark.apache.org/downloads.html
命令行运行:
$ export PYSPARK_PYTHON=python3
$ ./bin/pyspark
Python 3.6.4 (default, Jan 6 2018, 11:51:15)
[GCC 4.2.1 Compatible Apple LLVM 9.0.0 (clang-900.0.39.2)] on darwin
。。。
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.2.1
/_/ Using Python version 3.6.4 (default, Jan 6 2018 11:51:15)
SparkSession available as 'spark'.
setup:
python setup.py install
导入
from pyspark import SparkConf, SparkContext
RDDs (Resilient Distributed Datasets)
- Resilient: able to withstand failures
- Distributed: spanning across multiple machines
- read-only, partitioned collection of records
RDD 在最新的spark2.x中有逐渐被淡化的趋势,是曾经的主角,现在算作low level API,基本不太可能在生产实践中用到,但是有助于理解spark。新型的RDD需要实现如下接口
- partitions()
- iterator(p: Partition)
- dependencies()
- optional: partitioner for key-value RDD (E.g. RDD is hash-partitioned)
从local collection中创建RDD
>>> mycollection = "Spark Qing Ge Guide : Big Data Processing Made Simple".split(" ")
>>> words = spark.sparkContext.parallelize(mycollection, 2)
>>> words.setName("myWords")
myWords ParallelCollectionRDD[35] at parallelize at PythonRDD.scala:489
>>> words.name()
'myWords'
transformations
distinct:
>>> words.distinct().count()
[Stage 23:> (0 + 0) / 2]
10
filter:
>>> words.filter(lambda word: startsWithS(word)).collect()
['Spark', 'Simple']
map:
>>> words2 = words.map(lambda word: (word, word[0], word.startswith("S")))
>>> words2.filter(lambda record: record[2]).take(5)
[('Spark', 'S', True), ('Simple', 'S', True)]
flatmap:
>>> words.flatMap(lambda word: list(word)).take(5)
['S', 'p', 'a', 'r', 'k']
sort:
>>> words.sortBy(lambda word: len(word) * -1).take(5)
['Processing', 'Simple', 'Spark', 'Guide', 'Qing']
Actions
reduce:
>>> spark.sparkContext.parallelize(range(1,21)).reduce(lambda x, y : x+y)
210
count:
>>> words.count()
10
first:
>>> words.first()
'Spark'
max and min:
>>> spark.sparkContext.parallelize(range(1,21)).max()
20
>>> spark.sparkContext.parallelize(range(1,21)).min()
1
take:
>>> words.take(5)
['Spark', 'Qing', 'Ge', 'Guide', ':']
注意:spark uses lazy transformation, 上文提到的所有transformation都只有在action时才会被调用。
Saving files
>>> words.saveAsTextFile("file:/tmp/words")
$ ls /tmp/words/
_SUCCESS part-00000 part-00001
$ cat /tmp/words/part-00000
Spark
Qing
Ge
Guide
:
$ cat /tmp/words/part-00001
Big
Data
Processing
Made
Simple
Caching
>>> words.cache()
myWords ParallelCollectionRDD[35] at parallelize at PythonRDD.scala:489
options include: memory only(default), disk only, both
CoGroups
>>> import random
>>> distinctChars = words.flatMap(lambda word: word.lower()).distinct()
>>> charRDD = distinctChars.map(lambda c: (c, random.random()))
>>> charRDD2 = distinctChars.map(lambda c: (c, random.random()))
>>> charRDD.cogroup(charRDD2).take(5)
[('s', (<pyspark.resultiterable.ResultIterable object at 0x10ab49c88>, <pyspark.resultiterable.ResultIterable object at 0x10ab49080>)), ('p', (<pyspark.resultiterable.ResultIterable object at 0x10ab49438>, <pyspark.resultiterable.ResultIterable object at 0x10ab49048>)), ('r', (<pyspark.resultiterable.ResultIterable object at 0x10ab494a8>, <pyspark.resultiterable.ResultIterable object at 0x10ab495c0>)), ('i', (<pyspark.resultiterable.ResultIterable object at 0x10ab49588>, <pyspark.resultiterable.ResultIterable object at 0x10ab49ef0>)), ('g', (<pyspark.resultiterable.ResultIterable object at 0x10ab49ac8>, <pyspark.resultiterable.ResultIterable object at 0x10ab49da0>))]
Inner Join
>>> keyedChars = distinctChars.map(lambda c: (c, random.random()))
>>> outputPartitions = 10
>>> chars = words.flatMap(lambda word: word.lower())
>>> KVcharacters = chars.map(lambda letter: (letter, 1))
>>> KVcharacters.join(keyedChars).count()
44
>>> KVcharacters.join(keyedChars, outputPartitions).count()
44
Aggregations
from functools import reduce
>>> def addFunc(left, right):
... return left + right
...
KVcharacters.groupByKey().map(lambda row: (row[0], reduce(addFunc, row[1]))).collect()
[('s', 4), ('p', 3), ('r', 2), ('i', 5), ('g', 5), ('d', 3), ('b', 1), ('c', 1), ('l', 1), ('a', 4), ('k', 1), ('q', 1), ('n', 2), ('e', 5), ('u', 1), (':', 1), ('t', 1), ('o', 1), ('m', 2)]
Spark 执行和调度
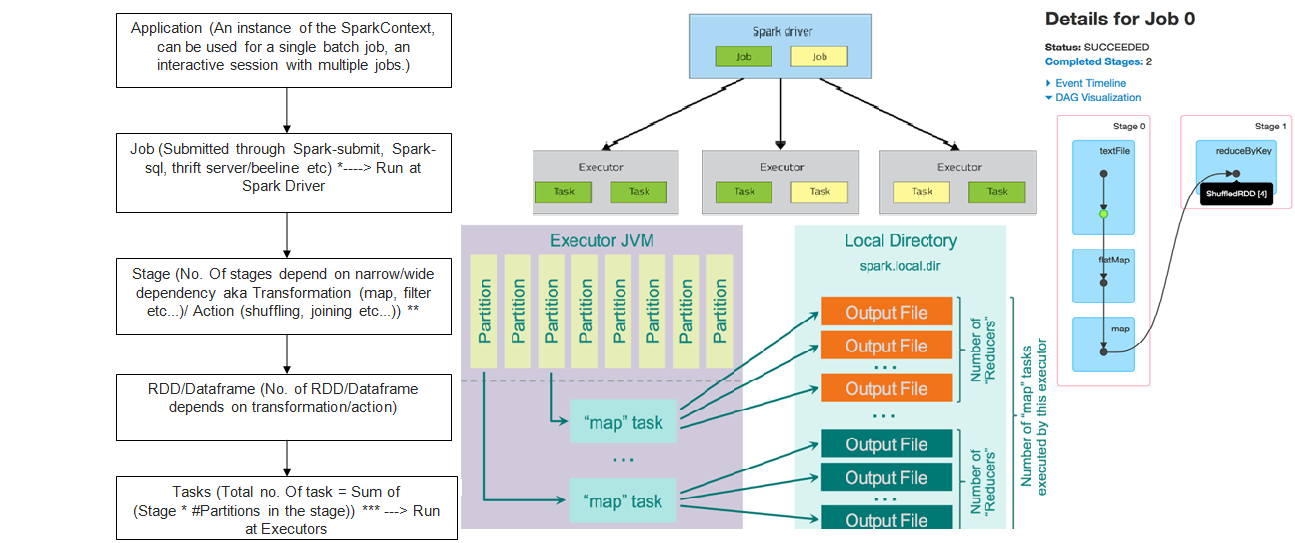
具体来说就是
- invoke an action...
- ...spawns the job...
- ...that gets divided into the stages by the job scheduler...
- ...and tasks are created for every job stage
其中,stage和task的区别在于:stage是RDD level,不会被立即执行,而task会被立即执行。
Broadcast variables
- read-only shared variables with effective sharing mechanism
- useful to share dictionaries and models
今天就先到这,更多内容以后有机会再聊
10分钟入门spark的更多相关文章
- Apache Shiro系列三,概述 —— 10分钟入门
一.介绍 看完这个10分钟入门之后,你就知道如何在你的应用程序中引入和使用Shiro.以后你再在自己的应用程序中使用Shiro,也应该可以在10分钟内搞定. 二.概述 关于Shiro的废话就不多说了 ...
- JavaScript 10分钟入门
JavaScript 10分钟入门 随着公司内部技术分享(JS进阶)投票的失利,先译一篇不错的JS入门博文,方便不太了解JS的童鞋快速学习和掌握这门神奇的语言. 以下为译文,原文地址:http://w ...
- kafka原理和实践(一)原理:10分钟入门
系列目录 kafka原理和实践(一)原理:10分钟入门 kafka原理和实践(二)spring-kafka简单实践 kafka原理和实践(三)spring-kafka生产者源码 kafka原理和实践( ...
- Markdown - Typora 10分钟入门 - 精简归纳
Markdown - Typora 10分钟入门 - 精简归纳 JERRY_Z. ~ 2020 / 8 / 22 转载请注明出处! 目录 Markdown - Typora 10分钟入门 - 精简归纳 ...
- [入门到吐槽系列] Webix 10分钟入门 一 管理后台制作
前言 本人是服务端程序员,同时需要兼职前端开发.常用的就是原生态的HTML.Javascript,也用过ExtJS.Layui.可是ExtJS变公司后非常难用.Layui上手还行,用过一段时间,会觉得 ...
- [入门到吐槽系列] Webix 10分钟入门 二 表单Form的使用
前言 继续接着上一篇的webix入门:https://www.cnblogs.com/zc22/p/15912342.html.今天完成剩下两个最重要的控件,表单和表格的使用.掌握了这两个,整个Web ...
- Webpack 10分钟入门
可以说现在但凡开发Single page application,webpack是一个不可或缺的工具. WebPack可以看做是一个模块加工器,如上图所示.它做的事情是,接受一些输入,经过加工产生一些 ...
- 「从零单排canal 01」 canal 10分钟入门(基于1.1.4版本)
1.简介 canal [kə'næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据 订阅 和 消费.应该是阿里云DTS(Data Transfer Servi ...
- python 10分钟入门pandas
本文是对pandas官方网站上<10 Minutes to pandas>的一个简单的翻译,原文在这里.这篇文章是对pandas的一个简单的介绍,详细的介绍请参考:Cookbook .习惯 ...
随机推荐
- WPF笔记(2.4 Grid)
第一章已经简单介绍过这个容器,这一节详细介绍.Grid一般是用表格(Grid.Row 和Grid.Column )的,比StackPanel更细致一些,但是,这么玩很麻烦,先横着竖着定义一大堆,然后把 ...
- Jetson TX2上的demo(原创)
Jetson TX2上的demo 一.快速傅里叶-海动图 sample The CUDA samples directory is copied to the home directory on th ...
- template.compile()方法
template.compile(source, options) source:必传,渲染模板的内容. options:可选,通常不传.(其实是我还没研究明白) return:一个渲染函数. 示例如 ...
- CentOS7系统配置国内yum源和epel源
1.首先进入/etc/yum.repos.d/目录下,新建一个repo_bak目录,用于保存系统中原来的repo文件 [root@bogon ~]# cd /etc/yum.repos.d/ [roo ...
- 给php加速安装APC
说明:APC-3.1.13 适应于 php-5.4.27 下载: wget http://blog.xinfilm.com/softdir/APC-3.1.13.tgz tar -zxvf APC-3 ...
- Java:对象的强、软、弱和虚引用[转]
原文链接:http://zhangjunhd.blog.51cto.com/113473/53092/ 原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否则将追究法 ...
- CTSC 2017 滚粗记
CTSC 2017 滚粗记 结束好几天了一直没写. 明天就要去参加二轮省选了,填一下坑吧. 所以可能很多东西已经忘了 Day -2 [5.5 Fri] 周五晚上是其他学信竞的同学来机房的时间... 也 ...
- BZOJ 3669: [Noi2014]魔法森林 [LCT Kruskal | SPFA]
题目描述 为了得到书法大家的真传,小 E 同学下定决心去拜访住在魔法森林中的隐 士.魔法森林可以被看成一个包含 n 个节点 m 条边的无向图,节点标号为 1,2,3,…,n,边标号为 1,2,3,…, ...
- vuex是什么东西?
vuex是什么鬼? 文档上面对vuex的解释是 "一个专为 Vue.js 应用程序开发的状态管理模式",恩,看完这句是否对vuex有了一个大概的认识? 答案是:"认识你个 ...
- [Python Study Notes]磁盘信息和IO性能
''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''' ...