浅谈kafka streams
随着数据时代的到来,数据的实时计算也越来越被大家重视。实时计算的一个重要方向就是实时流计算,目前关于流计算的有很多成熟的技术实现方案,比如Storm、Spark Streaming、flink等。
我今天要讲的kafka streams体量上来说没有那么大,都算不上一个框架,只是kafka的一个类库。麻雀虽小,五脏俱全。kafka streams能提供强大的流处理的功能,并且具备一些大框架不具备的灵活特点。
这篇文章的目标是把流计算这个事讲清楚,并介绍kafka streams是如何来做流计算的如有欠妥之处,欢迎指出。
大纲
- 什么是流计算
- 什么是kafka streams
- kafka streams的特点、架构、关键问题处理
- word count示例
一、什么是流计算
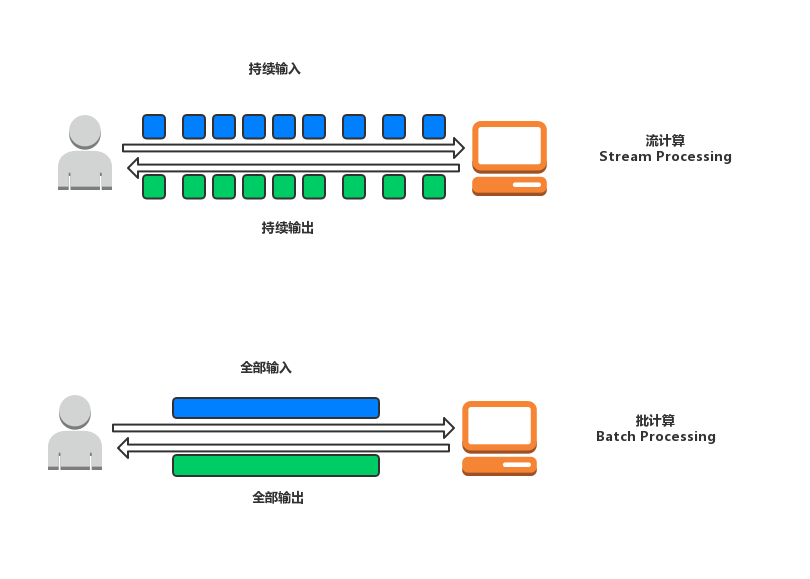
在介绍流计算之前,我们先把在它之前的批计算讲一下。
批计算是在计算之前将这次计算的源数据一次性到位,按数据块来处理数据,每一个task接收一定大小的数据块,然后经过批计算在这次计算的结果一次性返还给调用者。
批计算的处理的对象是有限数据(bound data),得到的结果也是一个有限结果集,因此批量计算中的每个任务都是短任务,任务在处理完其负责的数据后关闭。
流计算与之相反,流计算处理的对象是无限数据(unbound data),流式计算的上游算子处理完一条数据后,会立马发送给下游算子,所以一条数据从进入流式系统到输出结果的时间间隔较短,经过流计算得到的结果也是无限的结果集。
流式计算往往是长任务,每个work一直运行,持续接受数据源传过来的数据。
二、什么是kafka streams
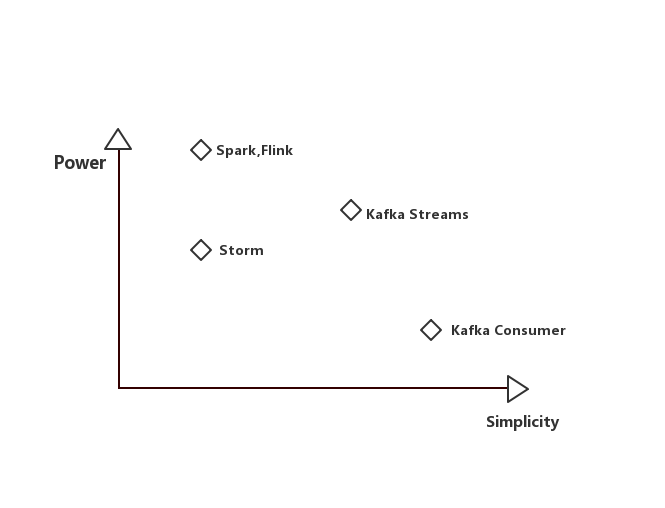
说到流计算,很多人会想到Storm、Spark Streaming、Flink。确实这些框架目前都已经完美的支持流计算,并且很多大厂都有相应的使用案例,但是这些框架使用起来门槛很高,首先要学习框架的使用,各种规范,然后要讲业务迁移到框架中,其次线上使用这些流计算框架,部署也是一个很头疼的事。但是今天要讲的主角Kafka Streams,是Kafka 在0.10版本加入的一个新的类库,官方定位是轻量级的流计算类库。简单体现在以下几个方面:
1)由于Kafka Streams是Kafka的一个lib,所以实现的程序不依赖单独的环境
2)基于功能实现时比较简洁,只需要基于规范实现业务逻辑即可,规模和Failover等问题有Kafka本身的特性保证。
三、Kafka Streams的特点、组件及架构
1、Kafka Streams的特点
1) 轻量级java应用,除了kafka,无需依赖资源调度框架
2) 毫秒级延迟
3)支持stateful(有状态的)处理,如join,aggregation等。
4)试错成本很低,相比较其他框架,
5)支持exactly-once语义支持
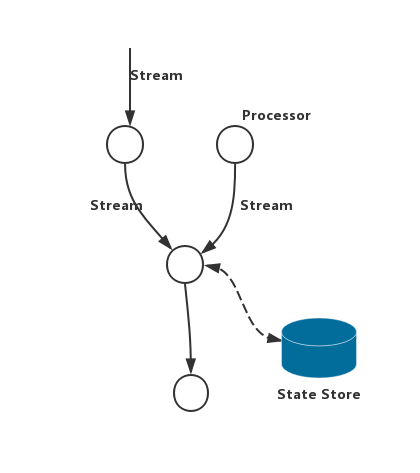
2、组件
1)Stream Topology:Processor 处理后后结果输出
2)Processor: Stream Topology中的节点,是一个基本的计算节点
3)State Store:本地信息存储
类型:
1)Key-value based
2)Window based
容错性
1)本地RocksDB备份
2)远程由changelog topic备份在broker上
3、架构图
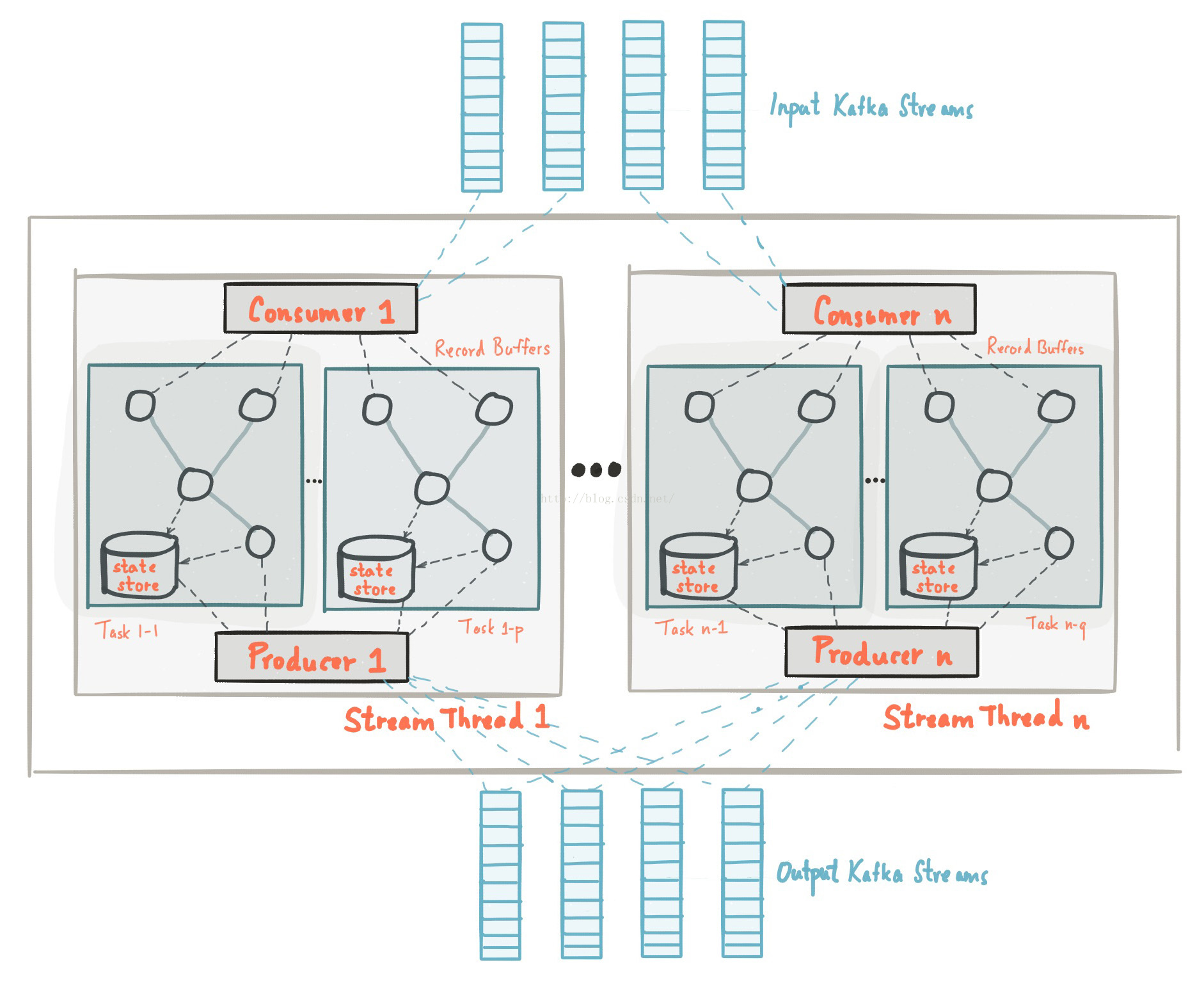
(该图摘自Confluent官网)
4、流计算的一些关键问题的处理
1)故障恢复(Fault Tolerance)
Kafka Streams的容错构建在Kafka本之上,由于Kafka Consumer Group已经实现HA,因此当出现消费异常的导致流处理任务失败的时候,会转移到其他机器继续消费处理,中间的过程数据不会丢失,但是要考虑重复消费的问题。
2)状态处理(Stateful Compute)
Kafka Stream 提供了一个抽象概念KTable,KStream来解决状态存储和数据变化的问题。这里简单介绍下Kafka Stream如何实现有状态的处理,为了实现状态的概念,Kafka Streams有两个重要抽象:KStream 和 KTable。分别对应数据流和数据库,区别在于key-value对值如何被解释。Kafka Streams作为流处理技术,很好的将存储状态的表(table)和作为记录的流(stream)无缝地结合在了一起。
3)乱序问题处理(Out-of-Order Handling)
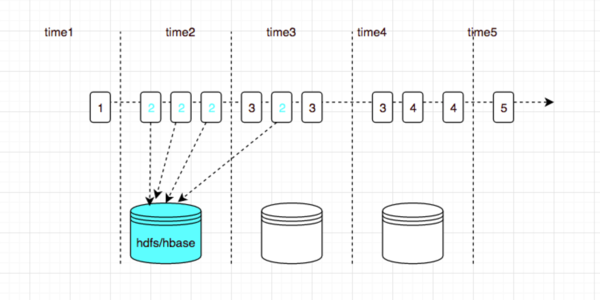
无序数据对于无状态处理其实没什么影响,对于有状态的处理,则直接导致处理逻辑是否正确,比如聚合操作。通常流处理中,数据有三个时间属性:
i)事件时间(Event Time):数据产生时间
ii)处理时间(Processing Time):数据被处理时间
iii)摄取时间(Ingest Time): 数据存储到kafka分区的时间。
在处理无序的数据通过架将中间聚合结果保存在KTable中,后来的数据计算会覆盖之前的,这种处理方式类似Spark和Flink中的watermark机制,等待一个给定时间后,开始计算,后来的数据将会舍弃。
四、来一个wordcount例子
一般编程领域学习一个新技术都会以hello-world开始,但是在大数据计算,则是以word-count开始,顾名思义,统计单词数量。
1、启动zookeeper
zkServer.cmd
2、启动kafka
kafka-server-start.bat d:\soft\tool\Kafka\kafka_2.12-2.1.0\config\server.properties
3、创建一个用于存储输入数据的topic
kafka-console-producer.bat --broker-list localhost:9092 --topic streams-file-input < file-input.txt
为了方便演示,其中file-input.txt我是直接放到kafka的bin目录下
4、在idea中创建一个简单的项目,书写以下代码:
- /**
- * ymm56.com Inc.
- * Copyright (c) 2013-2019 All Rights Reserved.
- */
- package wikiedits;
- import org.apache.kafka.common.serialization.Serde;
- import org.apache.kafka.common.serialization.Serdes;
- import org.apache.kafka.streams.KafkaStreams;
- import org.apache.kafka.streams.StreamsConfig;
- import org.apache.kafka.streams.kstream.KStream;
- import org.apache.kafka.streams.kstream.KStreamBuilder;
- import org.apache.kafka.streams.kstream.KTable;
- import java.util.Arrays;
- import java.util.Properties;
- /**
- * @author LvHuiKang
- * @version $Id: KafkaStreamTest.java, v 0.1 2019-03-26 19:45 LvHuiKang Exp $$
- */
- public class KafkaStreamTest {
- public static void main(String[] args) {
- Properties config = new Properties();
- config.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-wordcount");
- config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
- config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
- config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
- Serde<String> sdeStr = Serdes.String();
- Serde<Long> sdeLong = Serdes.Long();
- KStreamBuilder builder = new KStreamBuilder();
- KStream<String, String> inputLines = builder.stream(sdeStr, sdeStr, "streams-file-input");
- KTable<String, Long> wordCounts = inputLines.flatMapValues(inputLine -> Arrays.asList(inputLine.toLowerCase().split("\\W+"))).groupBy((key, word) -> word).count("Counts");
- wordCounts.to(sdeStr, sdeLong, "streams-wordcount-output");
- KafkaStreams streams = new KafkaStreams(builder, config);
- streams.start();
- System.out.println();
- }
- }
pom 依赖如下:
- <dependency>
- <groupId>org.apache.kafka</groupId>
- <artifactId>kafka-streams</artifactId>
- <version>0.11.0.0</version>
- </dependency>
- <dependency>
- <groupId>org.apache.kafka</groupId>
- <artifactId>kafka_2.11</artifactId>
- <version>0.11.0.0</version>
- </dependency>
然后启动main方法,运行如下:
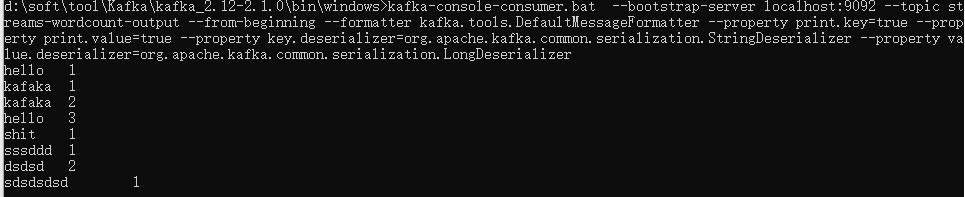
5、启动consumer:
kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic streams-wordcount-output --from-beginning --formatter kafka.tools.DefaultMessageFormatter --property print.key=true --property print.value=true --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer --property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
展示如下:
五、总结
本文简单介绍了kafka streams这个作为轻量级流计算引擎的架构、主要组件已经区别其他流计算引擎的特点,并通过word-count简单演示了kafka streams的使用。本文也是在我研究流计算时无意发现的一个技术,仍有很多关键的技术点没有吃透并给大家讲解,后续研究后会追加。感谢你的阅读,欢迎指正不足,并进行讨论。
浅谈kafka streams的更多相关文章
- 浅谈分布式消息技术 Kafka(转)
一只神秘的程序猿. Kafka的基本介绍 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可 ...
- 浅谈分布式消息技术 Kafka
Kafka的基本介绍Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/ngin ...
- 搞懂分布式技术21:浅谈分布式消息技术 Kafka
搞懂分布式技术21:浅谈分布式消息技术 Kafka 浅谈分布式消息技术 Kafka 本文主要介绍了这几部分内容: 1基本介绍和架构概览 2kafka事务传输的特点 3kafka的消息存储格式:topi ...
- [翻译]Kafka Streams简介: 让流处理变得更简单
Introducing Kafka Streams: Stream Processing Made Simple 这是Jay Kreps在三月写的一篇文章,用来介绍Kafka Streams.当时Ka ...
- Kafka Streams简介: 让流处理变得更简单
Introducing Kafka Streams: Stream Processing Made Simple 这是Jay Kreps在三月写的一篇文章,用来介绍Kafka Streams.当时Ka ...
- 【转】浅谈分布式服务协调技术 Zookeeper
非常好介绍Zookeeper的文章, Google的三篇论文影响了很多很多人,也影响了很多很多系统.这三篇论文一直是分布式领域传阅的经典.根据MapReduce,于是我们有了Hadoop:根据GFS, ...
- 浅谈ELK日志分析平台
作者:珂珂链接:https://zhuanlan.zhihu.com/p/22104361来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 小编的话 “技术干货”系列文章 ...
- Kafka Streams | 流,实时处理和功能
1.目标 在我们之前的Kafka教程中,我们讨论了Kafka中的ZooKeeper.今天,在这个Kafka Streams教程中,我们将学习Kafka中Streams的实际含义.此外,我们将看到Kaf ...
- [转帖]浅谈响应式编程(Reactive Programming)
浅谈响应式编程(Reactive Programming) https://www.jianshu.com/p/1765f658200a 例子写的非常好呢. 0.9312018.02.14 21:22 ...
随机推荐
- kubectl自动补全
source <(kubectl completion bash) echo "source <(kubectl completion bash)" >> ...
- DS控件库 DS标签的另类用法之折叠展开
某些场合下,可以通过动态设置DS标签的文本内容来输出不同的显示效果,以下是示例. 示例中的素材 示例资源文本 String1="<linkimg=E1><b>&l ...
- Microsoft.Office.Interop.Excel 报错
Microsoft.Office.Interop.Excel 报错 引用dll 在以下目录 C:\Windows\assembly\GAC_MSIL\Microsoft.Office.Interop. ...
- jQuery内容过滤选择器与子元素过滤选择器用法实例分析
jQuery选择器内容过滤 一.:contains(text) 选择器::contains(text)描述:匹配包含给定文本的元素返回值:元素集合 示例: ? 1 2 $("div.mini ...
- Java实现"命令式"简易文本编辑器原型
源自早先想法, 打算从界面方向做些尝试. 找到个简单文本编辑器的实现: Simple Text Editor - Java Tutorials. 原本的菜单/按钮界面如下. 包括基本功能: 新建/打开 ...
- 关于C++11右值引用和移动语义的探究
关于C++11右值引用和移动语义的探究
- Node编码规范
编码规范 1. 缩进 采用2个空格缩进,而不是tab缩进.空格在编辑器中与字符是等宽的,而tab可能因编辑器的设置不同.2个空格会让代码看起来紧凑.明快. 2. 变量声明 永远用var声明变量,不加v ...
- idea Maven项目找不到相关依赖包(红色波浪线)
前两天做项目的时候,把团队其他人的代码从git同步到自己电脑上,出现了冲突.发现是maven依赖出现了问题,之前的截图找不到了,我就简单描述一下.就是下图箭头所示位置出现了红色波浪线. 在网上找了很多 ...
- Review: Basic Knowledge about JavaScript 1
JavaScript shanzm
- java-retry实现
有这样一个需求,当调用某个方法抛出异常,比如通过 HttpClient 调用远程接口时由于网络原因报 TimeOut 异常:或者所请求的接口返回类似于“处理中”这样的信息,需要重复去查结果时,我们希望 ...