【Python3爬虫】大众点评爬虫(破解CSS反爬)
本次爬虫的爬取目标是大众点评上的一些店铺的店铺名称、推荐菜和评分信息。
一、页面分析
进入大众点评,然后选择美食(http://www.dianping.com/wuhan/ch10),可以看到一页有15家店铺,而除了店铺的名称,还能看到店铺的地址、推荐菜、评分等信息,看起来都没什么问题。
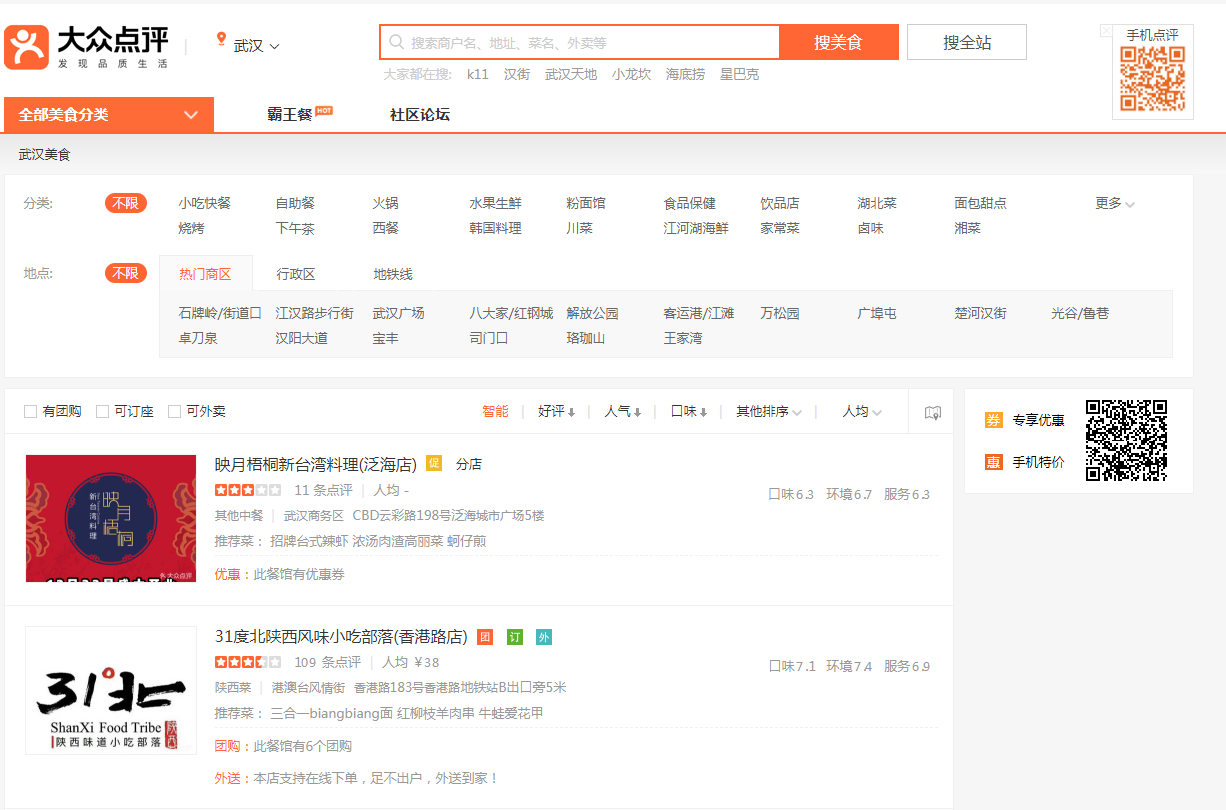
打开开发者工具,然后选择查看一下评分,就发现事情没那么简单了(如下图)。这些评分的数字去哪儿了呢?
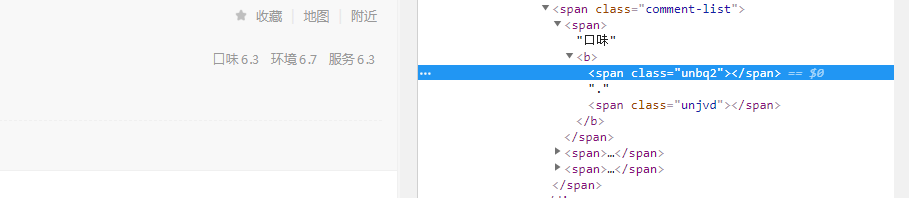
其实这些数字是SVG矢量图,SVG矢量图是基于可扩展标记语言,用于描述二维矢量图形的一种图形格式,通过使用不同的偏移量就能显示不同的字符,这样就能很巧妙地隐藏信息了,如果我们用xpath去解析网页得到的就是一个个""。这次爬虫的难点就在于如何得到这些评分的信息,既然我们能够知道它是怎么反爬的,那我们是不是就能想办法实现反反爬呢?先说下破解思路吧:首先要解析网页,找到这个网页使用的SVG矢量图,拿到这个矢量图后,如果我们能得到每个数字对应的偏移量,那就能将这些偏移量转化成图片中的数字了。
二、破解步骤
首先查看网页源码,既然使用的是SVG矢量图,那我们搜索一下svg会不会有惊喜呢?果然有惊喜:

把这个链接复制一下,然后打开这个链接,会看到有很多的class名称和background,这么多的数据,怎么知道有没有我们想要的东西呢?这时候搜索一下unbq2:

可以看到unbq2这个class对应的background为(-199.0px,-109.0px),但是我们还是没有办法得到具体的数字啊,怎么办呢?
我们再搜索一下svg会有什么结果呢?这一步会得到几个以.svg结尾的链接,将这些链接提取出来:
span[class^="ma"]{background-image: url(//s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/9e045e6574fb7ae10b5aae4ae4a0c444.svg);span[class^="yj"]{background-image: url(//s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/39510b070120e6a5b7c8754ab729ee2e.svg);span[class^="dz"]{background-image: url(//s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/8eecf780b3c9ecefd5ad508502dd80a5.svg);span[class^="un"]{background-image: url(//s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/39ecd4a57969825db02c38a01f4f34c6.svg);
可以看到以"un"开头的class使用的背景图片的链接就是//s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/39ecd4a57969825db02c38a01f4f34c6.svg
{kind=link}

这就是我们要找的SVG矢量图了,现在的问题就在于如何将偏移量转化成对应的数字呢?首先把这些数字提取出来:
99851465728255648017534661485297040380627087820023
03763928255311814779807306445209731282368541175419
06266544999197136339
然后打开开发者工具,可以发现每个数字都有对应着一组x和y的值:

在前面的分析中我们知道数字6对应的偏移量是(-199.0px,-109.0px),然后我们也可以分析一下别的数字对应的偏移量,然后通过这些分析可以知道y方向上的偏移量只是为了确定这个class对应的数字在哪一行,而x方向的偏移量需要进行一下处理,具体方法为:
(x方向上的偏移量+7)/(-12)
比如(-199+7)/(-12)=16,这个16就表示对应的数字索引为16(第一个数字索引为0),然后y方向的偏移量对应的行数为3,最后从上面的数字中寻找第3行第17个数字--正好为6,也就是说unbq2这个class对应的数字就是6,这样我们就已经成功实现了反反爬。
三、爬取步骤
由于大众点评会对我们的UserAgent和Cookie进行检查,所以在爬取的时候要带上Cookie,而且如果一直用一个UserAgent也会被识别出来,所以得采用不同的UserAgent。这里我要分析一个第三方模块:fake_useragent,没有安装这个模块的可以使用pip命令进行安装。我们通过使用这个模块就能得到随机的UserAgent了,使用方法如下:
from fake_useragent import UserAgent ua = UserAgent()
for i in range():
print(ua.random)
运行结果如下:

店铺名称和推荐菜的爬取相对简单,这里就不赘述了,主要说一下如何爬取店铺的评分信息。
在我们得到网页的源码之后,需要先把css文件的url提取出来:
# 提取css文件的url
css_url = "http:" + re.search('(//.+svgtextcss.+\.css)', html).group()
然后将以"un"开头的class名称和对应的偏移量全部提取出来,以供后面使用:
css_res = requests.get(css_url)
# 这一步得到的列表内容为css中class的名字及其对应的偏移量
css_list = re.findall('(un\w+){background:(.+)px (.+)px;', '\n'.join(css_res.text.split('}')))
这里还要对得到的数据进行一下处理,因为y方向上的偏移量并不参与计算,最终得到的y_dict中的键是y方向上的偏移量,值是y方向上的偏移量对应的行数:
# 过滤掉匹配错误的内容,并对y方向上的偏移量初步处理
css_list = [[i[0], i[1], abs(float(i[2]))] for i in css_list if len(i[0]) == 5]
# y_list表示在y方向上的偏移量,完成排序和去重
y_list = [i[2] for i in css_list]
y_list = sorted(list(set(y_list)))
# 生成一个字典
y_dict = {y_list[i]: i for i in range(len(y_list))}
然后我们要提取以”un“开头的class所对应svg图片的url,并访问这个url,将图片中的数字都提取出来:
# 提取svg图片的url
svg_url = "http:" + re.findall('class\^="un".+(//.+svgtextcss.+\.svg)', '\n'.join(css_res.text.split('}')))[0]
svg_res = requests.get(svg_url)
# 得到svg图片中的所有数字
digits_list = re.findall('>(\d+)<', svg_res.text)
进行到这一步,我们就已经得到了所有以un开头的class对应的偏移量和所有的数字了,然后我们就可以利用前面的计算方法将这些偏移量转变成对应的数字了,也就能得到每个店铺的评分信息了。
最终运行结果如下:

完整代码已上传到GitHub!
【Python3爬虫】大众点评爬虫(破解CSS反爬)的更多相关文章
- Python爬虫反反爬:CSS反爬加密彻底破解!
刚开始搞爬虫的时候听到有人说爬虫是一场攻坚战,听的时候也没感觉到特别,但是经过了一段时间的练习之后,深以为然,每个网站不一样,每次爬取都是重新开始,所以,爬之前谁都不敢说会有什么结果. 前两天,应几个 ...
- 爬虫--反爬--css反爬---大众点评爬虫
大众点评爬虫分析,,大众点评 的爬虫价格利用css的矢量图偏移,进行加密 只要拦截了css 解析以后再写即可 # -*- coding: utf- -*- """ Cre ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫入门教程 63-100 Python字体反爬之一,没办法,这个必须写,反爬第3篇
背景交代 在反爬圈子的一个大类,涉及的网站其实蛮多的,目前比较常被爬虫coder欺负的网站,猫眼影视,汽车之家,大众点评,58同城,天眼查......还是蛮多的,技术高手千千万,总有五花八门的反爬技术 ...
- python爬虫的一个常见简单js反爬
python爬虫的一个常见简单js反爬 我们在写爬虫是遇到最多的应该就是js反爬了,今天分享一个比较常见的js反爬,这个我已经在多个网站上见到过了. 我把js反爬分为参数由js加密生成和js生成coo ...
- 【Python3爬虫】猫眼电影爬虫(破解字符集反爬)
一.页面分析 首先打开猫眼电影,然后点击一个正在热播的电影(比如:毒液).打开开发者工具,点击左上角的箭头,然后用鼠标点击网页上的票价,可以看到源码中显示的不是数字,而是某些根本看不懂的字符,这是因为 ...
- Python爬虫入门教程 65-100 爬虫与反爬虫的修罗场,点评网站,字体反爬之三
爬虫与反爬虫的修罗场 哪种平台最吸引爬虫爱好者,当然是社区类的,那里容易产生原生态,高质量的数据啊, 你看微博,知乎,豆瓣爬的不亦乐乎. 评论也是产生内容的好地方 生活类点评网站 旅游类点评网站 音乐 ...
- Node.js大众点评爬虫
大众点评上有很多美食餐馆的信息,正好可以拿来练练手Node.js. 1. API分析 大众点评开放了查询商家信息的API,这里给出了城市与cityid之间的对应关系,链接http://m.api.di ...
- 《C# 爬虫 破境之道》:第二境 爬虫应用 — 第六节:反爬策略研究
之前的章节也略有提及反爬策略,本节,我们就来系统的对反爬.反反爬的种种,做一个了结. 从防盗链说起: 自从论坛兴起的时候,网上就有很多人会在论坛里发布一些很棒的文章,与当下流行的“点赞”“分享”一样, ...
随机推荐
- python高级编程1
1.如何在列表,字典,集合中根据条件筛选数据? 如: 过滤列表[3, 9, -1, 10, 20, -2...]中的负数 筛出字典{‘小明’:70, 'Jim':88,'Tom':98...}中值高于 ...
- 知识点:java一些方法会有横线?以Date 过期方法为例
原因:他们的开发者在升级方法后,添加了@Deprecated注释, 目的是为了提醒我们,这个方法现在已经有新的方法了,不建议继续使用! 比如: JAVA中Date的tolocalstring为什么不建 ...
- Java7里try-with-resources分析
这个所谓的try-with-resources,是个语法糖.实际上就是自动调用资源的close()函数.和Python里的with语句差不多. 例如: [java] view plain copy ...
- [UOJ#207. 共价大爷游长沙]——LCT&随机化
题目大意: 传送门 给一颗动态树,给出一些路径并动态修改,每次询问一条边是否被所有路径覆盖. 题解: 先%一发myy. 开始感觉不是很可做的样子,发现子树信息无论维护什么都不太对…… 然后打开题目标签 ...
- 【BZOJ 3561】 DZY Loves Math VI
题目: 给定正整数n,m.求 题解: 水题有益身心健康.(博客园的辣鸡数学公式) 其实到这我想强上伯努利数,然后发现$n^2$的伯努利数,emmmmmm 发现这个式子可以算时间复杂度,emmmmm ...
- laravel 查询数据返回的结果
laravel查询数据返回的结果 在插入数据库的时候,发现查询数据返回的结果是一个对象;即使是空数据 返回的不是true或者false 那么要判断该结果是否查询有结果 该如果呢? 学习源头: http ...
- 磁盘IOPS计算与测量
IOPS (Input/Output Per Second)即每秒的输入输出量(或读写次数),是衡量磁盘性能的主要指标之一.IOPS是指单位时间内系统能处理的I/O请求数量,一般以每秒处理的I/O请求 ...
- Python 魔术方法笔记
魔术方法总是被__包围, 如__init__ , __len__都是常见的魔术方法,这里主要写一下我遇到的一些魔术方法 setitem 对某个索引值赋值时 即可以进行赋值操作,如 def __seti ...
- java基于BasicPlayer调用 播放音乐
无聊中想想用java调用下听音乐的api.晚上很多文章用的比较老大方法了,都是用原生的代码写,而且不支持mp3格式,BasicPlayer第三方包提供了很好的api调用,简单的3行代码就可以调用mp3 ...
- 前端学习笔记之HTML body内常用标签
阅读目录 一 HTML语义化 二 字符实体 三 h系列标签 四 p标签 五 img标签 六 a标签 七 列表标签 八 table标签 九 form标签 一 HTML语义化 body中的标签是会显示到浏 ...