Boosting(提升方法)之XGBoost
XGBoost是一个机器学习味道非常浓厚的模型,在数学上非常规范,运用正则化、L2范数、二阶梯度、泰勒公式和分布式计算方法,对GBDT等提升树模型进行优化,不仅能处理更大规模的数据,而且运行效率特别高。看完了XGBoost的原理后,我只能借用邓紫棋在《我是歌手》舞台上唱《喜欢你》时说的那句话:“太漂亮啦”,来表达我内心的感受。
怎么学习XGBoost这个模型呢?我是沿着 “ 决策树(CART)—AdaBoost—GBDT—XGBoost ” 这样的路线来学习的,所幸这正是比较顺的一条学习路径,因为XGBoost就是站在前人的肩膀上被提出来或者说改进的一个模型。为什么说站在前人肩膀上呢?大致说来,XGBoost是一种提升树模型,基学习器是CART回归树,在GBDT用一阶负梯度代替残差的基础上加上二阶梯度,在采样时还借鉴了Random Forest(随机森林)的Sub-Sampling方法。
自己还是初学者,整理这篇博客并没有自己独到的见解,而是通过这种方式来整理知识点,记录自己学习时的思考。
要把XGBoost的数学原理了解到能用的地步,我觉得需要搞明白几个问题:
1、XGBoost的基学习器是什么?
2、XGBoost模型中的参数是什么?
3、XGBoost的目标函数是什么?
4、XGBoost是怎么选择特征和特征的分裂点的?
5、XGBoost是怎么防止过拟合的?
所以在学习的过程中,多在心里问问自己这几个问题,而不能迷失在数学推导当中。
一、XGBoost的基学习器
XGBoost的基学习器是CART回归树。还记得之前学过的,CART叫做分类与回归树,既可以用于分类也可以用于回归,而这里用的是它的回归树模型。接下来回答两个问题。
1、CART回归树的特点是什么呢?
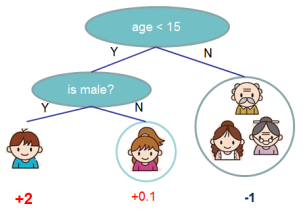
特点是每个叶子节点上都包含一个权重,也叫做分数,所以CART回归树可以认为是每个叶子节点都附有权重的二叉决策树。这符合“回归”二字的意思,因为回归模型的预测值是需要可以相加的,而分数作为连续值相加是有意义的。以下就是一棵CART回归树。
2、CART回归树如何用数学公式表示?XGBoost又如何由CART回归树组合而成呢?
假设一个训练数据集中有n个样本(xi,yi),每个样本的输入值xi有m个特征,把这个数据集记作D={(xi, yi)}(|D|=n, xi∈Rm,yi∈R)。提升树由K棵CART回归树组合而成,其预测值就等于K棵CART回归树的预测值之和,而每棵CART回归树表示为:f(x)=wq(x)。
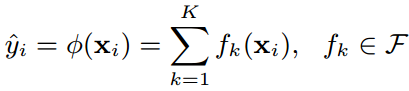
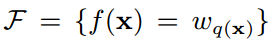
上面的第一个式子表示XGBoost的预测值(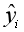 )等于K棵CART回归树(fk(x))的预测值(fk(xi))之和。
)等于K棵CART回归树(fk(x))的预测值(fk(xi))之和。
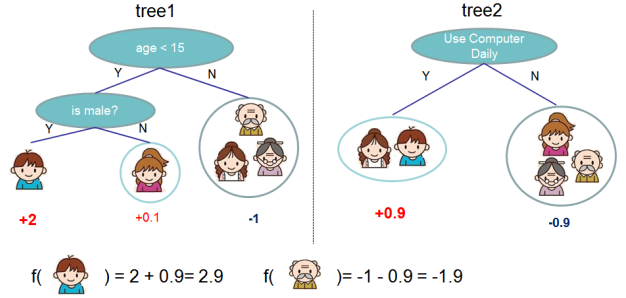
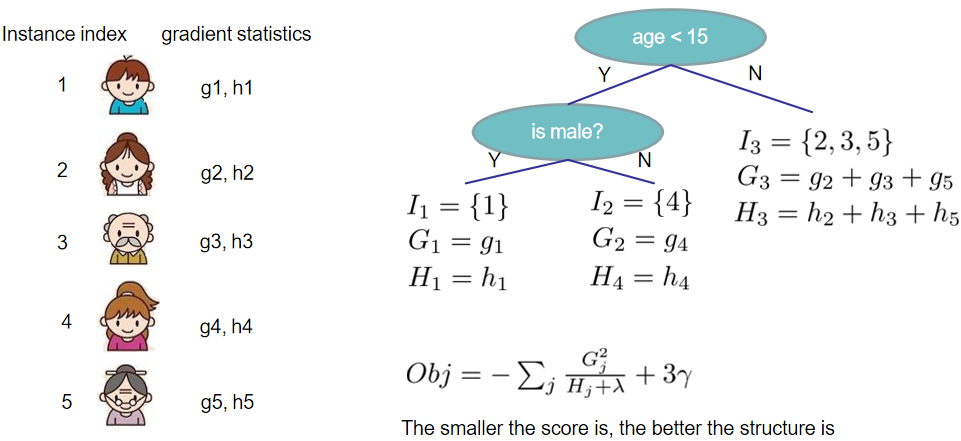
以上图为例,XGBoost由两棵CART回归树组成,确定了两棵树的结构和叶子节点的分数后,把{男娃}这个样本扔进两棵树中,得到他在两棵树中的分数{+2,+0.9},也称为预测值,然后相加,就得到了XGBoost的预测值。
第二个式子表示所有可能的CART回归树,这K棵树就是从这个空间中挑选出来的。第二个式子中的q(x)比较重要,要好好理解,首先q表示一棵回归树的结构,结构确定则树的深度、各内部节点(特征)、决策规则和叶子节点中的样本都确定了,那么q(xi)表示将一个样本映射为所在的叶子节点的位置的函数,比如上图tree1中最左边那个男娃,他被分在了第一个叶子节点,所以q(男娃)=1。而wq(x)正是每个叶子节点上的权重(分数),比如tree1中那个男娃的分数为2,在5个人中最高,就是说以是否满足条件{年龄小于15岁 and 性别为男}来进行判断,5个人中,这个男娃是最符合这两个条件的。那么每棵CART回归树fk(x)就由这两个要素组成:q和wq(x),也就是树的结构和叶子节点上的权重。
于是我们就明白了CART回归树长什么样,而且怎么由多棵CART回归树得到XGBoost。
二、XGBoost中的参数
要得到我们想要的模型,首先得知道模型长什么样,然后要估计模型中的参数,才能得到最终的结果。
那么XGBoost中的参数是什么?
答案是:XGBoost的参数如果看成两种,那就是K棵CART回归树的结构q和每棵树的叶子节点的权重wq(x);参数如果看成一种,那就是K棵CART回归树fk(x);因为每棵CART回归树fk(x)就由两个要素组成:q和wq(x)。
所以敲黑板,参数不只是权重wq(x),而是每棵CART回归树,或者说fk(x)这K个函数!我们把参数记作:
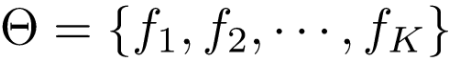
知道了参数是什么,那么用什么方法估计参数呢?机器学习的套路就是定义一个目标函数,然后通过最小化目标函数,来求参数。所以下一步看XGBoost的目标函数长什么样。
三、XGBoost的目标函数
XGBoost的目标函数是结构风险最小化的,也就是由损失函数(loss function)和正则化项(regularization)构成。
如果已知模型为K棵CART回归树组成的XGBoost模型,即:
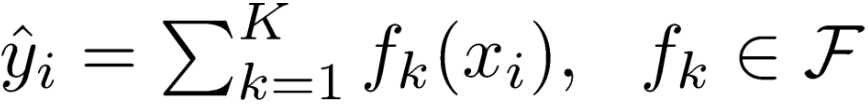
那么目标函数为:
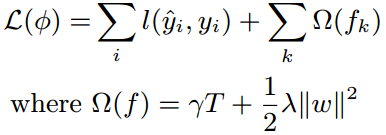
拆成两部分来看。
1、训练损失
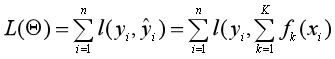
计算的是模型的预测值和真实值yi之间的差异,衡量的是模型的拟合程度。
2、模型的复杂度
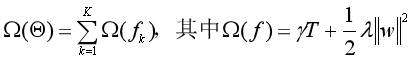
模型的复杂度用每棵CART回归树的叶子节点个数T和叶子节点上权重的L2范数来衡量。把这两项之和作为正则化项加入到目标函数当中,对模型的复杂度进行惩罚,使模型倾向于选择叶子节点少,权重数值小而平滑的CART回归树。因为叶子节点数量越多,模型越复杂,越容易过拟合,而叶子节点的权重如果出现非常大的极端值,也会对模型的结果产生不良影响。
所以我们希望学习的模型是既对训练样本有比较好的拟合效果,又比较简单。这两个小目标存在一定的冲突,而最小化目标函数就是要在这两个小目标之间进行权衡,取得一个最优解。
看完上面的内容,是不是感觉还漏了东西?是的,我们选择什么损失函数来计算训练损失呢?L这个函数取什么类型?
在GBDT(或者叫GBM),我们常用平方损失函数,还有的提升树模型用的是对数似然损失函数,XGBoost的损失函数其实可以是多样化的,因为有了泰勒展开式、一阶梯度和二阶梯度这三样“上古神器”,只要损失函数满足连续可微条件,咱都给它整得服服帖帖。
那如何最小化这个目标函数,求出K棵CART回归树的方程,也就是参数呢?于是就到了下一部分,用前向分步算法,一棵树一棵树地找出来。
四、XGBoost的参数求解
(一)问题分析
我们已经知道了目标函数,要求的参数是K棵CART回归树的方程,可是一步到位地把K个方程求出来是不可能的。祖师爷AdaBoost用的是加法模型和前向分步算法,每一步只学习一个基学习器,逐步逼近最优化的模型。XGBoost也是一样的做法,把求解过程分为K步,每一步只求出一棵CART回归树。
从另一个角度来看,要求的参数是每一棵CART回归树的结构和叶子节点上的权重,因此可以分解为两个问题:
一是确定一棵CART回归树的最好结构q
确定树的结构,这也就是在根节点和内部节点上,先选择哪个特征分裂,后选择哪个特征分裂,以及每个特征如何选择最佳分裂点的问题。还是看下面这个图,图中的CART树的结构已经确定了,特征有两个{年龄:(小于15,大于15),性别:(男,女)},先从年龄这个特征开始分裂,再从性别开始分裂。那时光倒流至这棵树没有产生之前,怎么就知道先拿年龄这个特征开刀?而且按照年龄是否小于15来分裂呢?
这里面其实又有两个问题,一是怎么衡量一个特征以及特征的分裂点的好坏呢(还记得CART分类树用基尼指数准则,而CART回归树用平方损失函数吧)?XGBoost是用分裂后目标函数值减少的程度来衡量,这个指标叫做增益(gain)。二是计算出了衡量特征好坏的指标数值后,怎么从M个特征中选择最好的特征作为分裂节点呢?陈天奇用了两种算法,解决了第二个问题,一种是贪心算法,一种是近似算法。
二是在CART回归树的结构确定的前提下,确定叶子节点上的最优权重wq(x)
对于CART回归树来说,确定了树结构之后,还需要确定叶子节点的权重,才算成功构建了一棵树。比如上面这个图,知道先从年龄这个特征开始分裂,再分裂性别这个特征后,还需要得到{+2,+0.1,-1}这三个权重。这个问题的求解过程精彩纷呈,荡气回肠,是初中数学(二次函数最优解)、高中数学(一阶梯度和二阶梯度)和本科数学(泰勒展开式)的集大成者,乃XGBoost的重中之重。
按道理得先得到CART回归树的结构,再求叶子节点上的最优权重才对,可是在陈天奇的论文中并不是这样求解的。他是先假定树的结构已经确定了,然后求出叶子节点上权重的表达式,再反过来用贪心算法得到树的最优结构。
(二)问题求解
1、加法模型和前向分步算法
首先把模型初始化为0,然后在每一轮迭代中,都求出一棵新的CART回归树,并把这棵树加到模型中去,这就是加法模型和前向分步算法的思想。那么在第t轮迭代中,参数就是第t棵树ft(x),是我们要求的,求出来后才可以将模型进行更新。
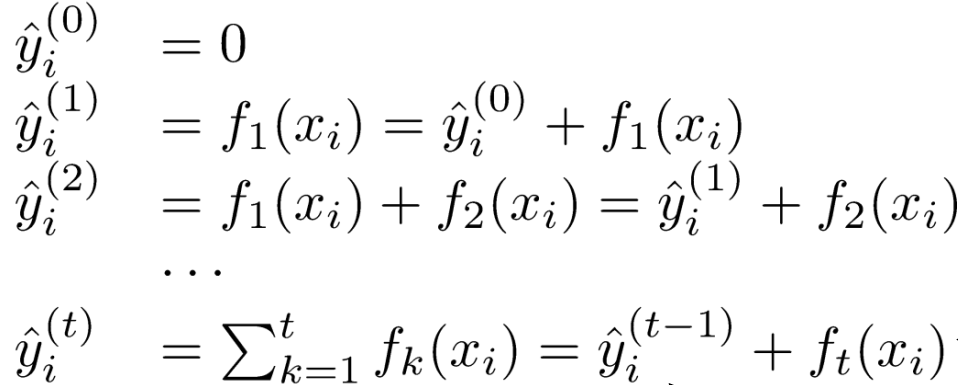
怎么求这棵树呢?通过最小化第t轮训练中的目标函数:
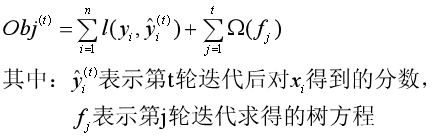
由于我们的目标是求ft(x),所以可以把与目标函数中与ft(x)无关的部分整合为一个常数项,简化这个目标函数:
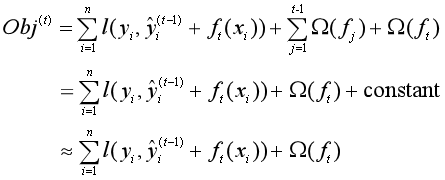
这个目标函数怎么最小化呢?注意到目标函数包含损失函数和模型复杂度两部分,所以分开来考虑。
2、改造损失函数
XGBoost的损失函数为:
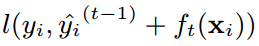
这个函数形式有些特殊,可以用泰勒公式来改造它。泰勒公式如下:
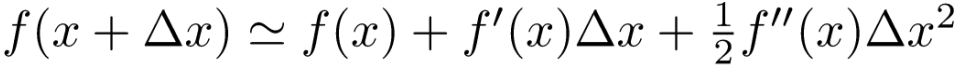
对照泰勒公式,可以把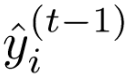 当作x,把
当作x,把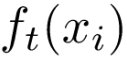 当作∆x,因为可以看作是残差的拟合值,是一个非常小的增量,那么
当作∆x,因为可以看作是残差的拟合值,是一个非常小的增量,那么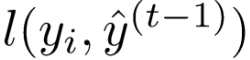 就相当于泰勒公式中的f(x)。
就相当于泰勒公式中的f(x)。
用gi表示对于的一阶偏导数,用hi表示二阶偏导数,那么就得到:
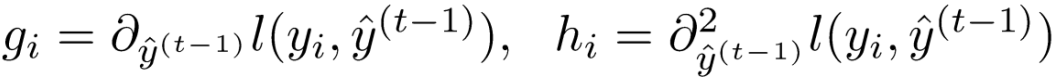
于是对损失函数进行改造,得到新的目标函数为:
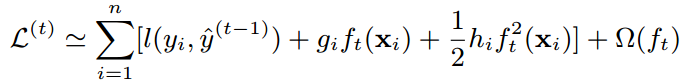
再一次把与ft(x)无关的常数项去掉,于是得到了第t轮迭代时,简化后的目标函数:
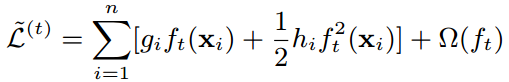
最后再用CART回归树的结构和叶子节点的权重来重新定义CART回归树。q表示树的结构,w表示叶子节点的权重,q(x)表示某个样本被分到的位置是第q(x)个叶子节点。
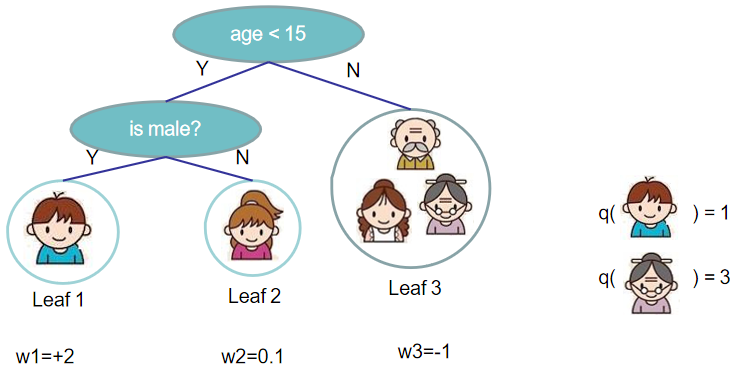
于是CART回归树可以定义为:
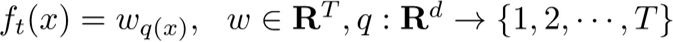
损失函数部分的改造到此完成。
3、定义模型复杂度
首先回顾一下,是用叶子节点的个数和叶子节点上权重的平滑程度(权重的L2范数)来描述模型的复杂度:
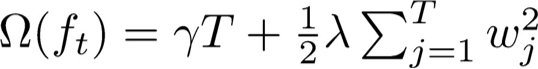
一棵CART回归树的模型复杂度的计算如下:
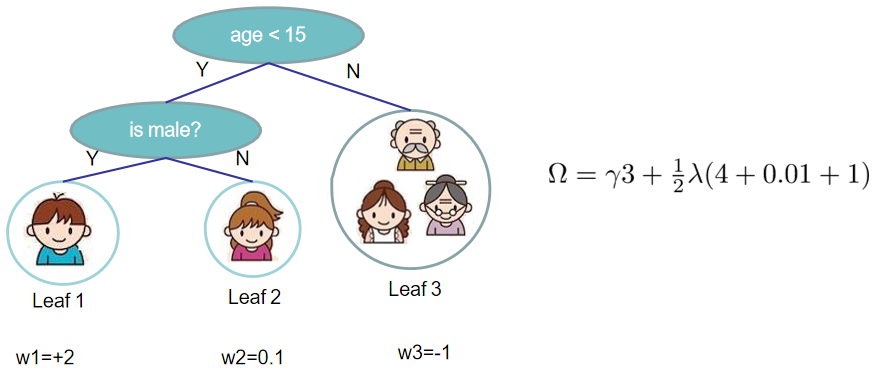
再把划分到第j个叶子节点上的样本集合定义为: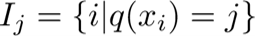 。比如上图中第3个叶子节点上的集合为I3,里面有3个样本。
。比如上图中第3个叶子节点上的集合为I3,里面有3个样本。
于是把CART回归树的新定义ft(x)=wq(x)代入目标函数中,并按照叶子节点来进行整理,得到新的目标函数:
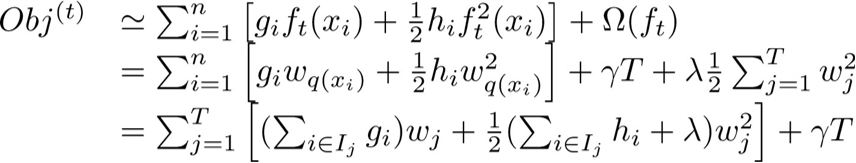
4、求解最优权重
别忘记前面说过的,我们假定树的结构已经确定了,先求叶子节点上的权重w。从上面目标函数的表达式中可以看到,如果T已经知道了,那么这就是一个关于权重wj的一元二次函数。此时用上初中的知识,一元二次函数的最小值点是这样求的:
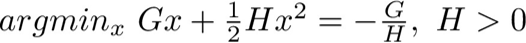
得到最小值点(-G/H)后,这个函数的最小值是这样求的:
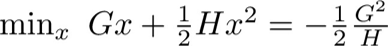
好,那就用上面这个初中知识来求解。
先用Gj和Hj分别表示每个叶子节点上的一阶梯度之和与二阶梯度之和:
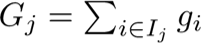
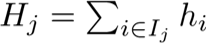
然后目标函数改造为(目标函数表示老是这样变来变去很辛苦):
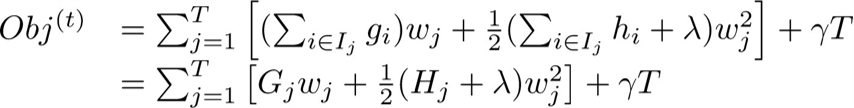
再用上初中数学知识,得到在第t轮迭代中,第t棵CART回归树上的最优权重w和目标函数值:
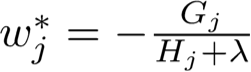
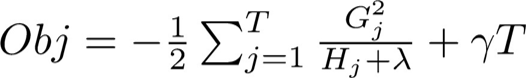
求解的案例如下图:
好的,也就是在第t轮迭代中,一棵CART树可能的结构有很多种,只要给定了它结构,我们就可以按照上面的方法去求叶子节点上的最优权重,并且得到目标函数值。如果有M种可能的结构,那么就会求出来M对(最优权重,目标函数值),然后从中选择目标函数值最小的那个结构,我们就真正完成了第t棵CART回归树的求解过程。问题是,树可能的结构实在太多了,甚至没办法枚举,怎么找到最优的树结构呢?
这是下一步要解决的问题,作者首先采用了贪婪算法。
5、确定最优的树结构
如何确定树的结构包含了如下三个问题:
一是对于每个特征,如何选择最佳的分裂点,比如特征是年龄,是按年龄是否大于15来划分左右子节点,还是按照年龄是否大于35来划分?
二是找到了每个特征的最佳分裂点后,如何在当前节点上选择最优的特征,比如选择年龄来划分,还是性别?
三是如何确定这棵树的深度,也就是树长到哪一层就要停止生长了?
用贪婪算法来解决这些问题。
首先解决第一个问题。从树的深度为0开始(也就是整棵树只有1个叶节点,那就是根节点),先考虑某个特征,把所有的样本按特征的取值进行排序,然后线性扫描所有的分裂点。比如特征取年龄,把所有人(样本)按年龄从小到大排序,然后从左到右线性扫描所有的分裂点,比如{15, 20, 25,...}。接下来对于每个分裂点,都计算分裂前后目标函数值的变化。GL表示左子节点上所有样本的一阶梯度之和,HL表示二阶梯度之和。
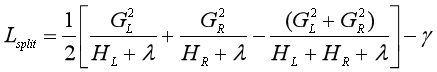
上面这个表达式是不分裂的目标函数值,减去分裂后的目标函数值而得到的,也就是目标函数的减少程度,把这个值称为增益(gain),如果值为正,表明用特征进行分裂后,有助于降低目标函数值。这个不够形象,可以看下图:
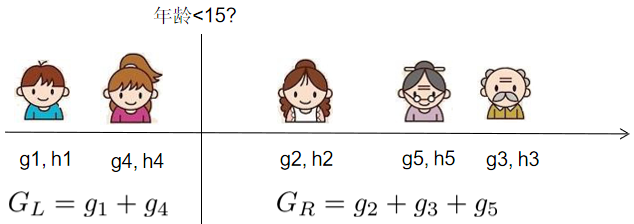
上图展示了以年龄以15作为分裂点时的情况,线性扫描的意思就是我们再计算以20、25、30等所有其他分裂点时的增益,然后进行比较,分裂后使得增益最大的,就是最佳的分裂点。
以上是从根节点开始分裂的情况,接下来随着树的生长,在每一个内部节点上,也是这么做,对于某个特征,线性扫描所有的分裂点,取最佳分裂点。
于是第一个问题就解决了。
其次解决第二个问题。还是从根节点开始,遍历所有的特征,按照第一步的方法,找到每一个特征的最佳分裂点及其对应的增益,然后对所有特征按增益进行排序,取出增益最大的那个特征,就是最优的特征,同时也得到了这个特征的最优分裂点。所以,选择的依据还是下面这个值:
然后随着树的生长,在每一个内部节点上,都选择一个最优的特征及其最佳分裂点,划分左右子节点。
于是第二个问题就解决了。
最后解决第三个问题。这个其实我也不是太明白,还是说说自己的理解,可能也不对。我认为树的深度就是由最小化目标函数得到的,因为目标函数会在减少训练损失和降低模型复杂度之间进行权衡,从而给生成的CART回归树一个合理的深度。
另外作者也提到了一个问题,其解决方案会影响树的深度。
这个问题就是,在树的生长过程中,可能在某个节点上选择特征进行分裂时,增益为负,也就是说分裂后目标函数值反而变大了,这与我们最小化目标函数的初衷是相悖的。作者提出了两种解决方法:一是早停,这类似于预剪枝,一旦在该节点分裂后增益为负,那就停止生长,得到最终的树结构,但这种方法的问题在于,如果不早停,后续的划分可能会带来性能的提升;二是后剪枝,先让树自动生长到最大深度,生成一棵完整的树,然后回过头来,从下往上减掉那些分裂后使得增益为负的叶子节点。
用贪婪算法寻找最佳特征和最佳分裂点的完整流程如下:

五、XGBoost防止过拟合
XGBoost为了进一步防止过拟合,除了在目标函数中加入模型复杂度之外,还用到了另外两种方法,进行“三重保护”。
第一种方法是加入收缩系数(Shrinkage),类似于学习率。回顾前面的内容,在第t轮迭代时,会把学习到的第t棵CART回归树加入到模型当中,得到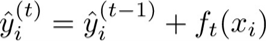 。加入收缩系数后,模型变为:
。加入收缩系数后,模型变为: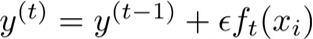 。这个收缩系数和逻辑回归中梯度下降的学习率作用差不多,就是不让步子迈得太大,不要一步就把目标函数优化到底,而是一点一点地进行优化,减少每一棵树对模型的影响,给未来的树留下余地。
。这个收缩系数和逻辑回归中梯度下降的学习率作用差不多,就是不让步子迈得太大,不要一步就把目标函数优化到底,而是一点一点地进行优化,减少每一棵树对模型的影响,给未来的树留下余地。
第二种方法是子采样(Sub-Sampling),也就是每轮计算不使用全部样本。子采样在随机森林中也用到了,而XGBoost进一步用列采样,被证明比行采样能更好地防止过拟合。
六、回顾总结
论文当中还有确定树结构的近似算法,反正我是看晕了。我觉得把以上的内容理解了,对于用XGBoost来解决问题而言,已经可以了。
学习到这,可以来回答开头的几个问题,检验学习成果了。
1、XGBoost的基学习器是CART回归树。
2、XGBoost模型中的参数是K棵CART回归树的方程。
3、XGBoost的目标函数由损失函数和模型复杂度构成。
4、XGBoost根据分裂前后目标函数的减少值,即增益(gain)来衡量每个特征和特征的分裂点的优劣,再用贪婪算法或近似算法来选择特征和分裂点的。增益的公式为:
5、XGBoost采用三种办法来防止过拟合:
一是在目标函数中加入模型复杂度的正则化项,模型复杂度用叶子节点的个数和叶子节点上权重的平滑程度来共同度量,即
二是学习到第t棵CART回归树的方程后,给它乘上一个收缩系数,再加入到模型当中去,减少这棵树对模型整体的影响,即:
三是用子采样(Sub-Sampling)的方法,每次按一定的百分比仅抽取部分样本进行学习。
再啰嗦几句,参考资料中有陈天奇XGBoost论文和PPT的下载地址,之所以分享出来,是因为虽然google和百度好用,但我还是找了一阵子,所以希望方便他人。
参考资料:
1、Chen T , Guestrin C :《XGBoost: A Scalable Tree Boosting System》
链接:https://pan.baidu.com/s/1SC3FlhOP_vb8nvSQXLVF1Q 提取码:sgxj
2、陈天奇XGBoost ppt:《Introduction to Boosted Trees》
链接:https://pan.baidu.com/s/1O1Ml0sylyXDWmWaPg4Rneg 提取码:vajm
3、http://djjowfy.com/2017/08/01/XGBoost的原理/
Boosting(提升方法)之XGBoost的更多相关文章
- Boosting(提升方法)之AdaBoost
集成学习(ensemble learning)通过构建并结合多个个体学习器来完成学习任务,也被称为基于委员会的学习. 集成学习构建多个个体学习器时分两种情况:一种情况是所有的个体学习器都是同一种类型的 ...
- Boosting(提升方法)之GBDT
一.GBDT的通俗理解 提升方法采用的是加法模型和前向分步算法来解决分类和回归问题,而以决策树作为基函数的提升方法称为提升树(boosting tree).GBDT(Gradient Boosting ...
- 提升方法(boosting)详解
提升方法(boosting)详解 提升方法(boosting)是一种常用的统计学习方法,应用广泛且有效.在分类问题中,它通过改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类的性 ...
- 组合方法(ensemble method) 与adaboost提升方法
组合方法: 我们分类中用到非常多经典分类算法如:SVM.logistic 等,我们非常自然的想到一个方法.我们是否可以整合多个算法优势到解决某一个特定分类问题中去,答案是肯定的! 通过聚合多个分类器的 ...
- js 变量提升+方法提升
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8&quo ...
- 机器学习理论提升方法AdaBoost算法第一卷
AdaBoost算法内容来自<统计学习与方法>李航,<机器学习>周志华,以及<机器学习实战>Peter HarringTon,相互学习,不足之处请大家多多指教! 提 ...
- Gradient Boosting, Decision Trees and XGBoost with CUDA ——GPU加速5-6倍
xgboost的可以参考:https://xgboost.readthedocs.io/en/latest/gpu/index.html 整体看加速5-6倍的样子. Gradient Boosting ...
- 统计学习方法c++实现之七 提升方法--AdaBoost
提升方法--AdaBoost 前言 AdaBoost是最经典的提升方法,所谓的提升方法就是一系列弱分类器(分类效果只比随机预测好一点)经过组合提升最后的预测效果.而AdaBoost提升方法是在每次训练 ...
- 提升方法-AdaBoost
提升方法通过改变训练样本的权重,学习多个分类器(弱分类器/基分类器)并将这些分类器进行线性组合,提高分类的性能. AdaBoost算法的特点是不改变所给的训练数据,而不断改变训练数据权值的分布,使得训 ...
随机推荐
- springboot~为Money类型添加最大值和最小值的注解校验
在spring框架里,为我们集成了很多校验注解,直接在字段上添加对应的注解即可,这些注解基本都是简单保留类型的,即int,long,float,double,String等,而如果你自己封装了新的类, ...
- udp服务端收发数据流程
1.创建服务端的socket以便开始通讯.2.绑定ip以及端口号,这样客户端才能找到这个程序.3.因为本地网卡不止一个所以尽量不写死,一般用""空来表示所有本地网卡.4.接下来开始 ...
- 源码安装xadmin及使用
xadmin是django的第三方后台 我们也可以使用pip来安装,但是推荐使用源码安装. 因为有些新功能以及发布在GitHub上,但是还未发布到pypi上,我们就可以提取使用这些功能. 一.安装 1 ...
- 手把手教你如何安装Pycharm——靠谱的Pycharm安装详细教程
今天小编给大家分享如何在本机上下载和安装Pycharm,具体的教程如下: 1.首先去Pycharm官网,或者直接输入网址:http://www.jetbrains.com/pycharm/downlo ...
- Python + Appium 环境搭建
---恢复内容开始--- Appium自动化公司内部测试培训1-环境搭建 课程目的 一.Python + Appium 环境搭建 课程内容 1 安装前准备工作 搭建环境所需要的安装文件已经下载好 ...
- arcEngine开发之查询的相关接口
属性查询 IQueryDef 首先这个接口不能直接创建,可以由 IFeatureWorkspace 接口的CreateQueryDef创建. 这个接口有两个属性必须设置(帮助文档是这样说明的,但是实际 ...
- 升讯威微信营销系统开发实践:(4)源代码结构说明 与 安装部署说明( 完整开源于 Github)
GitHub:https://github.com/iccb1013/Sheng.WeixinConstruction因为个人精力时间有限,不会再对现有代码进行更新维护,不过微信接口比较稳定,经测试至 ...
- springMVC(spring)+WebSocket案例(获取请求参数)
开发环境(最低版本):spring 4.0+java7+tomcat7.0.47+sockjs 前端页面要引入: <script src="http://cdn.jsdelivr.ne ...
- PAT1136:A Delayed Palindrome
1136. A Delayed Palindrome (20) 时间限制 400 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue ...
- JSP中的隐含对象
什么是JSP中隐含对象:容器自动创建,在JSP文件中可以直接使用的对象. 作用:JSP预先创建的这些对象可以简化对HTTP的请求,响应信息的访问. JSP中的隐含对象: 输入输出对象:request. ...