python 基础(四) 正则,递归 生成器
字符串是编程时涉及到的最多的一种数据结构,对字符串进行操作的需求几乎无处不在。比如判断一个字符串是否是合法的Email地址,虽然可以编程提取@前后的子串,再分别判断是否是单词和域名,但这样做不但麻烦,而且代码难以复用。
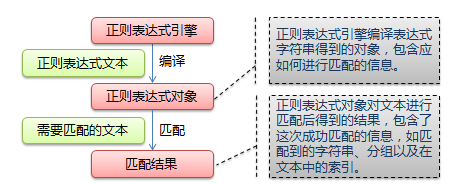
1、Python支持的正则表达式元字符和语法
| 语法 | 说明 | 表达式实例 | 完整匹配的字符串 |
| 字符 | |||
| 一般字符 | 匹配自己 | abc | abc |
| . | 匹配任意字符“\n”除外 DOTALL模式中(re.DOTALL)也能匹配换行符 |
a.b | abc或abc或a1c等 |
| [...] | 字符集[abc]表示a或b或c,也可以-表示一个范围如[a-d]表示a或b或c或d | a[bc]c | abc或adc |
| [^...] | 非字符集,也就是非[]里的之外的字符 | a[^bc]c | adc或aec等 |
| 预定义字符集(也可以系在字符集[...]中) | |||
| \d | 数字:[0-9] | a\dc | a1c等 |
| \D | 非数字:[^0-9]或[^\d] | a\Dc | abc等 |
| \s | 空白字符:[<空格>\t\n\f\v] | a\sc | a b等 |
| \S | 非空白字符:[^s] | a\Sc | abc等 |
| \w | 字母数字(单词字符)[a-zA-Z0-9] | a\wc | abc或a1c等 |
| \W | 非字母数字(非单词字符)[^\w] | a\Wc | a.c或a_c等 |
| 数量词(用在字符或(...)分组之后) | |||
| * | 匹配0个或多个前面的表达式。(注意包括0次) | abc* | ab或abcc等 |
| + | 匹配1个或多个前面的表达式。 | abc+ | abc或abcc等 |
| ? | 匹配0个或1个前面的表达式。(注意包括0次) | abc? | ab或abc |
| {m} | 匹配m个前面表达式(非贪婪) | abc{2} | abcc |
| {m,} | 匹配至少m个前面表达式(m至无限次) | abc{2,} | abcc或abccc等 |
| {m,n} | 匹配m至n个前面的表达式 | abc{1,2} | abc或abcc |
| 边界匹配(不消耗待匹配字符中的字符) | |||
| ^ | 匹配字符串开头,在多行模式中匹配每一行的开头 | ^abc | abc或abcd等 |
| $ | 匹配字符串结尾,在多行模式中匹配每一行的结尾 | abc$ | abc或123abc等 |
| \A | 仅匹配字符串开头 | \Aabc | abc或abcd等 |
| \Z | 仅匹配字符串结尾 | abc\Z | abc或123abc等 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 | ||
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 | ||
| 逻辑、分组 | |||
| | | 或左右表达式任意一个(短路)如果|没有在()中表示整个正则表达式(注意有括号和没括号的区别) | abc|def ab(c|d)ef |
abc或def abcef或abdef |
| (...) | 分组,可以用来引用,也可以括号内的被当做一组进行数量匹配后接数量词 | (abc){2}a | abcabca |
| (?P<name>...) | 分组别名,给分组起个名字,方便后面调用 | ||
| \<number> | 引用编号为<number>的分组匹配到的字符串(注意是配到的字符串不是分组表达式本身) | (\d)abc\1 | 1ab1或5ab5等 |
| (?=name) | 引用别名为name的分组匹配到的字符串(注意是配到的字符串不是分组表达式本身) | (?P<id>\d)abc(?P=id) | 1ab1或5ab5等 |
2、数量词的贪婪模式与分贪婪模式
3、python的re模块

1 import re
2
3 # 将正则表达式编译成Pattern对象
4 pattern = re.compile(r'hello')
5
6 # 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None
7 match = pattern.match('hello world!')
8
9 if match:
10 # 使用Match获得分组信息
11 print match.group()
hello
1 macth = re.match('hello', 'hello world')
2 if match:
3 print match.group()
4、re模块的常用方法
re.compile(strPattern[, flag])
match(string[, pos[, endpos]]) | re.match(pattern, string[, flags])
search(string[, pos[, endpos]]) | re.search(pattern, string[, flags])
>>> import re
>>> s = 'hello world'
>>> print(re.match('ello', s))
None
>>> print(re.search('ello',s ))
<_sre.SRE_Match object; span=(1, 5), match='ello'>
说明:可以看到macth只匹配开头,开头不匹配,就不算匹配到,search则可以从中间,只要能有匹配到就算匹配
findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags])
搜索string,以列表形式返回全部能匹配的子串。有点像search的扩展,把所有匹配的子串放到一个列表
参数:同match
返回值:所有匹配的子串,没有匹配则返回空列表
>>> import re
>>> s = 'one1two2three3four4'
>>> re.findall('\d+', s)
['1', '2', '3', '4']
split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]):
>>> import re
>>> s = 'one1two2three3four4'
>>> re.split('\d+', s)
['one', 'two', 'three', 'four', '']
sub(repl, string[, count]) | re.sub(pattern, repl, string[, count])
1 if __name__ == '__main__':
2 import re
3 s = '--(1.1+1+1-(-1)-(1+1+(1+1+2.2)))+-----111+--++--3-+++++++---+---1+4+4/2+(1+3)*4.1+(2-1.1)*2/2*3'
4 def replace_sign(expression):
5 '''
6 替换多个连续+-符号的问题,例如+-----,遵循奇数个负号等于正否则为负的原则进行替换
7 :param expression: 表达式,包括有括号的情况
8 :return: 返回经过处理的表达式
9 '''
10 def re_sign(m):
11 if m:
12 if m.group().count('-')%2 == 1:
13 return '-'
14 else:
15 return '+'
16 else:
17 return ''
18 expression = re.sub('[\+\-]{2,}', re_sign, expression)
19 return expression
20
21 s = replace_sign(s)
22 print(s)
1.迭代器&生成器
2.装饰器
1.基本装饰器
2.多参数装饰器(了解)
3.递归
4.算法基础:二分查找,二维数组转换,冒泡排序
5.正则表达式
迭代器&生成器
迭代器
迭代器是访问集合元素的一种方式。迭代器对象从集合的第一个元素开始访问,知道所有的元素都被访问结束。 迭代器只能往前不会后退, 另外,迭代器的一个大优点是不要求实现准备好整个迭代过程中所有的元素。迭代器仅仅在迭代到某个元素时才计算该元素。这个特性使 迭代器特别适用于便利一些巨大的或是无限的结合, 比如说几个G的日志文件。
特点:
1. 访问者不需要关心一个迭代器内部的结构,仅需要通过next()方法不断去取下一个内容
2.不能随机访问集合中的某个值,只能从头到尾依次访问
3.访问时不能回退
4.便于循环比较大的数据集合,节省内存。
生成一个迭代器如下:
注:迭代器不能随意访问集合中的某一个值,只能从头到尾依次访问,且访问时不能回退
生成器generator:
定义:一个函数调用时返回一个迭代器,那这个函数就叫生成器(generator),如果函数中包含yield语法,那这个函数就会变成生成器。
代码如下:
作用:这个yield的主要效果,就是可以中断函数运行状态,并保持中断状态,中断后, 代码可以继续往下执行,过一段时间后,还可以重新调用这个函数,从上次yield的下一句开始执行。
另外, 还可以通过yield实现在单线程的情况下实现并发运算的效果(实现异步):
代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
import timedef consumer(name): print('%s 要吃包子了'%name) while True: baozi = yield print('%s 包子来了,包子要被%s 吃掉了'%(baozi,name))def producer(name): C = consumer('A') C1 = consumer('B') C.__next__() C1.__next__() print('我要开始做包子啦') for i in range(10): time.sleep(1) print('%s 做了两个包子'%name) C.send(i) C1.send(i)producer('test') |
装饰器:
python装饰器见另一片文档。
递归
特点
递归算法是一种直接或者间接地调用自身方法的过程,它往往使算法的描述简介而且易于理解。
递归算法解决问题的特点::
(1) 递归就是在过程或函数里调用自身。
(2)在使用递归策略时,必须有一个明确的递归结束条件,称为递归出口
(3)递归算法截图通常显得很间接,但递归算法结题的运行效率极低,所以一般都不提倡用递归算法设计程序。
在递归调用的过程当中系统为每一层的返回点、局部变量等开辟了栈来存储。递归次数过程容易造成栈溢出等, 所以一般都提倡用递归算法设计程序。
要求
递归算法所体现的“重复” 一般有三个要求:
一是每次调用都在规模上都有所缩小(通常都是减半)
二是相邻两次重复之间有紧密的联系, 前一次要为后一次做准备(通常前一次的输出是为后一次的输入做铺垫)
三是在问题的规模极小时而不再进行递归调用,因而每次递归调用都是有条件的, 无条件出口的递归调用最后会陷入死循环。
示例代码如下:
在数据量比较大的情况下通过二分法查找某个数据
def searchdate(data_result,find_n):
mid = int(len(data_result)/2)
if len(data_result) >1:
if find_n < data_result[mid]:
print('find_n in [mid] left')
searchdate(data_result[:mid],find_n)
elif find_n > data_result[mid]:
print('find_n in [mid] right')
searchdate(data_result[mid:],find_n)
else:
print('find date in data_result [%s]' %data_result[mid])
if __name__ == '__main__':
dabc = list(range(1,99999))
searchdate(dabc,57668)
通过二分算法我们可以很快的实现数据查找, 特别是在数据量比较大的情况下, 效果会更好。
算法基础
1.生成一个4*4的二维数组并将其瞬时旋转90度
# 生成一个二维数组
date = [[aaa for aaa in range(4)] for bbb in range(4)]
name = '打印'
result = name.center(30, '*')
for i in date:
print(i)
for r_index, row in enumerate(date): # 循环遍历数组,并获取第一层的数组下标
for c_index in range(r_index, len(row)): # 根据第一层的下标,获取第二层
tmp = date[c_index][r_index] # 将要交换的元素先存到临时变量中
date[c_index][r_index] = row[c_index] # 元素交换
date[r_index][c_index] = tmp
print(result) for r in date:
print(r)
##################另外一种写法##################
data = [[aaa for aaa in range(4)] for bbb in range(4)]
for i in range(data.__len__()):
for k in range(data.__len__()):
if (i>k):
temp = data[i][k]
data[i][k]= data[k][i]
data[k][i]=temp for i in data:
print(i) ps:对于第一种写法目前还是不太能理解,后期需要在看一遍视频,加深一下
2. 斐波那契数列算法:
简单的来说斐波那契数列就是第三个数值等于第一个数值+第二个数值之和,如下:
1 2 3 5 8 13 21 34 ....
示例代码如下:
def calr(arg1,arg2,stop):
if arg1 == 0:
print(arg1,arg2)
arg3 = arg1 + arg2
print(arg3)
if arg3 <stop:
calr(arg2,arg3,stop) calr(0,1,789)
3.冒泡排序
将一个不规则的数组按从小到大的顺序进行排序
代码如下:
data = [10,4,33,21,54,3,8,11,5,22,2,1,17,13,6]
print("before sort:",data)
previous = data[0]
for j in range(len(data)):
tmp = 0
for i in range(len(data)-1):
if data[i] > data[i+1]:
tmp=data[i]
data[i] = data[i+1]
data[i+1] = tmp
print(data)
print("after sort:",data) ################另外一种写法###################
data = [11, 1231, 124, 24123, 554, 632, 591, 112, 109, 889, 100]
print('before sort:', data)
for i in range(len(data)):
for k in range(i):
if data[i] < data[k + 1]:
data[i], data[k + 1] = data[k + 1], data[i]
print('after sort:', data)
python 基础(四) 正则,递归 生成器的更多相关文章
- Python 基础 四 面向对象杂谈
Python 基础 四 面向对象杂谈 一.isinstance(obj,cls) 与issubcalss(sub,super) isinstance(obj,cls)检查是否obj是否是类 cls ...
- 【笔记】Python基础四:迭代器和生成器
一,迭代器协议和for循环工作机制 (一),迭代器协议 1,迭代器协议:对象必须提供一个next方法,执行该方法要么返回迭代中的下一项,要么就引起一个stopiteration异常,以终止迭代(只能往 ...
- python基础之迭代器、生成器、装饰器
一.列表生成式 a = [0,1,2,3,4,5,6,7,8,9] b = [] for i in a: b.append(i+1) print(b) a = b print(a) --------- ...
- Python基础之迭代器、生成器
一.迭代器: 1.迭代:每一次对过程的重复称为一次“迭代”,而每一次迭代得到的结果会作为下一次迭代的初始值.例如:循环获取容器中的元素. 2.可迭代对象(iterable): 1)定义:具有__ite ...
- python基础之迭代器与生成器
一.什么是迭代器: 迭代是Python最强大的功能之一,是访问集合元素的一种方式. 迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束. 迭代器是一个可以记住遍历的位置的对象. 迭代器的 ...
- python基础-装饰器,生成器和迭代器
学习内容 1.装饰器 2.生成器 3.迭代器 4.软件目录结构规范 一:装饰器(decorator) 1.装饰器定义:本质就是函数,用来装饰其他函数,即为其他函数添加附加功能. 2.装饰器原则:1)不 ...
- python基础8 -----迭代器和生成器
迭代器和生成器 一.迭代器 1.迭代器协议指的是对象必须提供一个next方法,执行该方法要么返回迭代中的下一项,要么就引起一个StopIteration异常,以终止迭代 (只能往后走不能往前退) 2. ...
- python 基础(四) 函数
函数 一.什么是函数? 函数是可以实现一些特定功能的 小方法 或者是小程序 优点: 提高 了代码的后期维护 增加了代码的重复使用率 减少了代码量 提高了代码可读性 二.函数的定义 使用 def关键+函 ...
- 【Python基础】迭代器、生成器
迭代器和生成器 迭代器 一 .迭代的概念 #迭代器即迭代的工具,那什么是迭代呢? #迭代是一个重复的过程,每次重复即一次迭代,并且每次迭代的结果都是下一次迭代的初始值 while True: #只是单 ...
- Python基础(四) 基础拾遗、数据类型进阶
一.基础拾遗 (一).变量作用域 外层变量,可以被内层变量直接调用:内层变量,无法被外层变量使用.这种说法在其它语言中适用,在python中除了栈以外,正常的变量作用域,只要执行声明并在内存中存在,该 ...
随机推荐
- JSP连接access数据库
一个用jsp连接Access数据库的代码. 要正确的使用这段代码,你需要首先在Access数据库里创建一username表,表里面创建两个字符型的字段,字段名分别为:uid,pwd,然后插入几条测试数 ...
- Optimizing Item Import Performance in Oracle Product Hub/Inventory
APPLIES TO: Oracle Product Hub - Version 12.1.1 to 12.1.1 [Release 12.1] Oracle Inventory Management ...
- 《java入门第一季》之类StringBuffer类初步
/* * 线程安全(多线程分析) * 安全 -- 同步 -- 数据是安全的 * 不安全 -- 不同步 -- 效率高一些 * 安全和效率问题是永远困扰我们的问题. * 安全:医院的网站,银行网站 * 效 ...
- HTML的TextArea中保存格式的问题
textarea在保存时格式是可以保存到数据库的,但是展示时因为/n和 不能互转导致页面不能按照刚开始的时候的格式展示,所以在页面展示的时候,要在值的外面嵌套一层 标签,即 < pre > ...
- Locally Weighted Linear Regression 局部加权线性回归-R实现
局部加权线性回归 [转载时请注明来源]:http://www.cnblogs.com/runner-ljt/ Ljt 作为一个初学者,水平有限,欢迎交流指正. 线性回归容易出现过拟合或欠拟合的问 ...
- 为神马精确Sprite的碰撞形状不通过简单的放大Sprite的尺寸来解决?
原因是SoftBodyDrawNode的绘制代码中已经没有完整的,一体化的(incorporate)缩放,旋转或者甚至是精灵的位置(scale,rotation,or even the sprite' ...
- 安卓笔记--- intent传递自定义类
<span style="font-family: Arial, Helvetica, sans-serif;">eat.setOnClickListener(new ...
- 解决Cell重用内容混乱的几种简单方法,有些方法会增加内存
重用实现分析 查看UITableView头文件,会找到NSMutableArray* visiableCells,和NSMutableDictnery* reusableTableCells两个结构 ...
- Mac OS X版本的sublime text 3安装汇编语言语法支持
sublime是个好东西,小巧.功能强大而且跨平台! 不过默认的语法里没有对asm的支持,这让本猫情何以堪- 下面介绍一下Mac OS X中如何给sublime安装汇编的语法和自动汇编命令补全支持. ...
- LeetCode(68)-Compare Version Numbers
题目: Compare two version numbers version1 and version2. If version1 > version2 return 1, if versio ...