Feature Preprocessing on Kaggle
刚入手data science, 想着自己玩一玩kaggle,玩了新手Titanic和House Price的 项目, 觉得基本的baseline还是可以写出来,但是具体到一些细节,以至于到能拿到的出手的成绩还是需要理论分析的。
本文旨在介绍kaggle比赛到各种原理与技巧,当然一切源自于coursera,由于课程都是英文的,且都比较好理解,这里直接使用英文
Features: numeric, categorical, ordinal, datetime, coordinate, text
Numeric features
All models are divided into tree-based model and non-tree-based model. 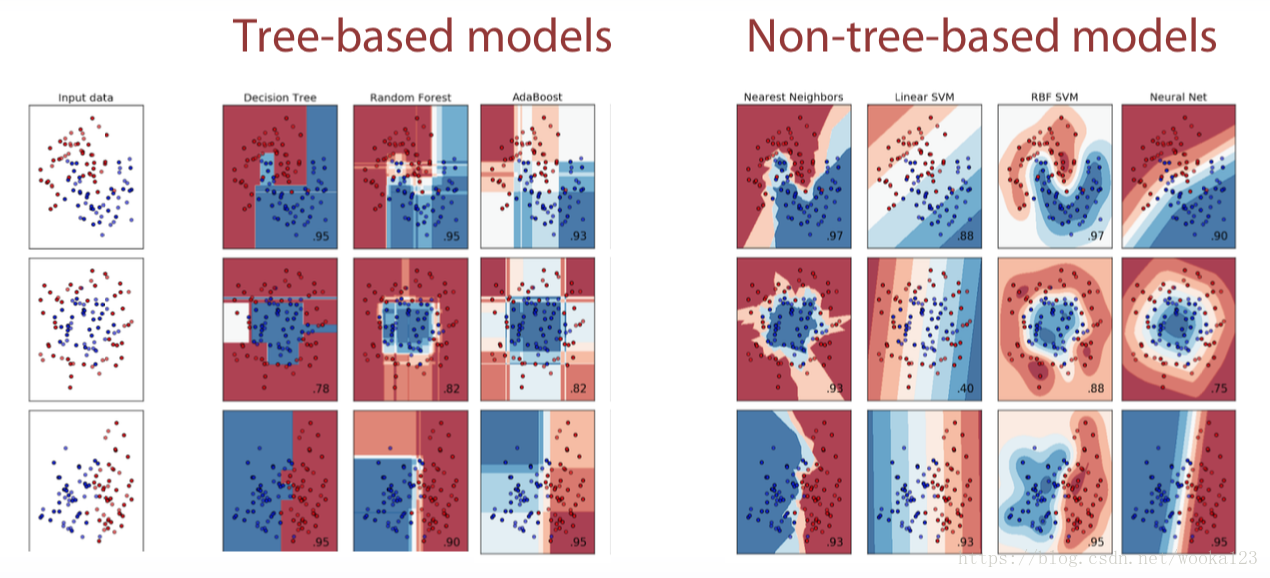
Scaling
For example: if we apply KNN algorithm to the instances below, as we see in the second row, we caculate the distance between the instance and the object. It is obvious that dimension of large scale dominates the distance.

Tree-based models doesn’t depend on scaling
Non-tree-based models hugely depend on scaling
How to do
sklearn:
- To [0,1]
sklearn.preprocessing.MinMaxScaler
X = ( X-X.min( ) )/( X.max()-X.min() ) To mean=0, std=1
sklearn.preprocessing.StandardScaler
X = ( X-X.mean( ) )/X.std()- if you want to use KNN, we can go one step ahead and recall that the bigger feature is, the more important it will be for KNN. So, we can optimize scaling parameter to boost features which seems to be more important for us and see if this helps
Outliers
The outliers make the model diviate like the red line.
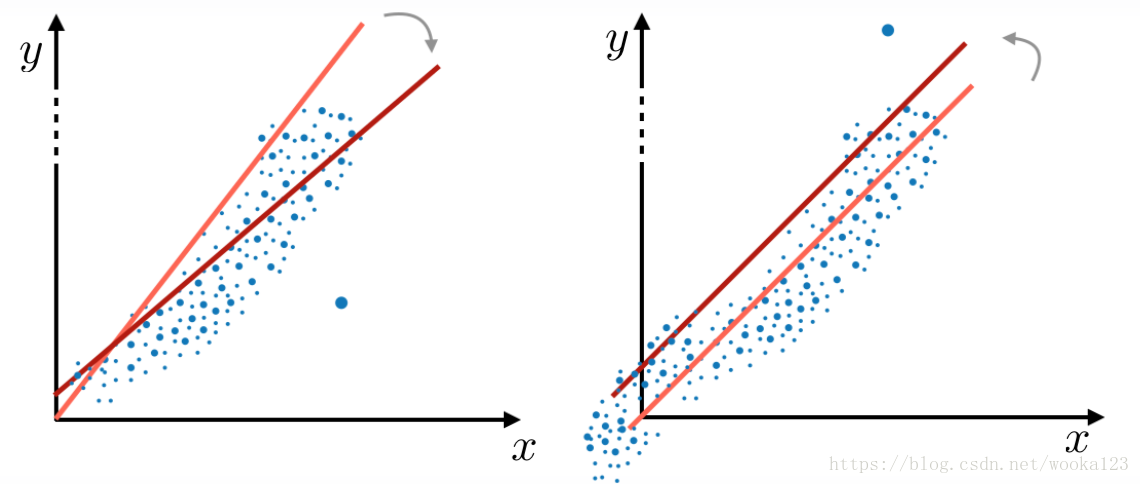
We can clip features values between teo chosen values of lower bound and upper bound
- Rank Transformation
If we have outliers, it behaves better than scaling. It will move the outliers closer to other objects
Linear model, KNN, Neural Network will benefit from this mothod.
rank([-100, 0, 1e5]) == [0,1,2]
rank([1000,1,10]) = [2,0,1]scipy:
scipy.stats.rankdata
Other method
- Log transform: np.log(1 + x)
- Raising to the power < 1: np.sqrt(x + 2/3)
Feature Generation
Depends on
a. Prior knowledge
b. Exploratory data analysis
Ordinal features
Examples:
- Ticket class: 1,2,3
- Driver’s license: A, B, C, D
- Education: kindergarden, school, undergraduate, bachelor, master, doctoral
Processing
1.Label Encoding
* Alphabetical (sorted)
[S,C,Q] -> [2, 1, 3]
sklearn.preprocessing.LabelEncoder
- Order of appearance
[S,C,Q] -> [1, 2, 3]
Pandas.factorize
This method works fine with two ways because tree-methods can split feature, and extract most of the useful values in categories on its own. Non-tree-based-models, on the other side,usually can’t use this feature effectively.
2.Frequency Encoding
[S,C,Q] -> [0.5, 0.3, 0.2]
encoding = titanic.groupby(‘Embarked’).size()
encoding = encoding/len(titanic)
titanic[‘enc’] = titanic.Embarked.map(encoding)from scipy.stats import rankdata
For linear model, it is also helpful.
if frequency of category is correlated with target value, linear model will utilize this dependency.
3.One-hot Encoding
pandas.get_dummies
It give all the categories of one feature a new columns and often used for non-tree-based model.
It will slow down tree-based model, so we introduce sparse matric. Most of libaraies can work with these sparse matrices directly. Namely, xgboost, lightGBM
Feature generation
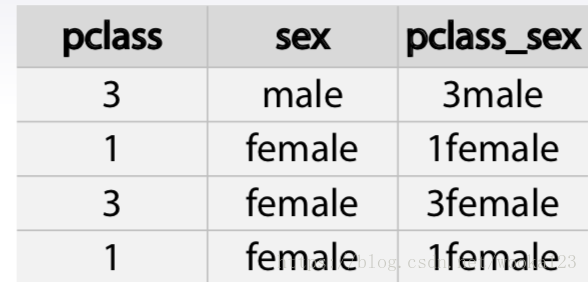
Interactions of categorical features can help linear models and KNN
By concatenating string
Datetime and Coordinates
Date and time
1.Periodicity
2.Time since
a. Row-independent moment
For example: since 00:00:00 UTC, 1 January 1970;
b. Row-dependent important moment
Number of days left until next holidays/ time passed after last holiday.
3.Difference betwenn dates
We can add date_diff feature which indicates number of days between these events
Coordicates
1.Interesting places from train/test data or additional data
Generate distance between the instance to a flat or an old building(Everything that is meanful)
2.Aggergates statistics
The price of surrounding building
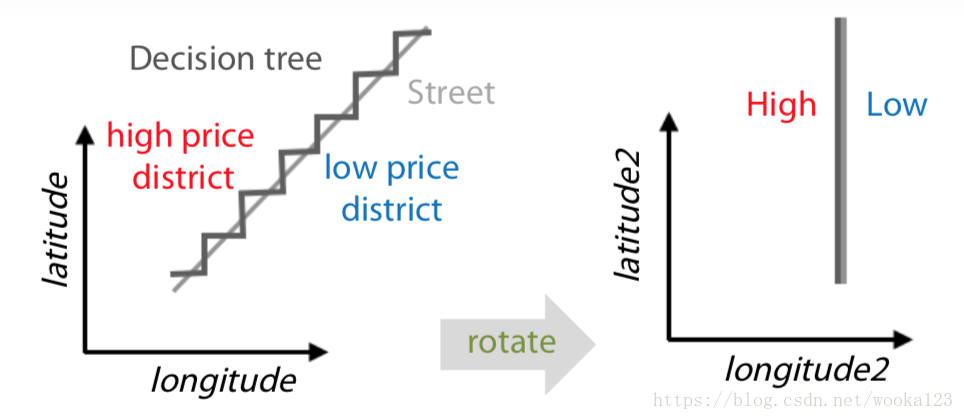
3.Rotation
Sometime it makes the model more precisely to classify the instances.
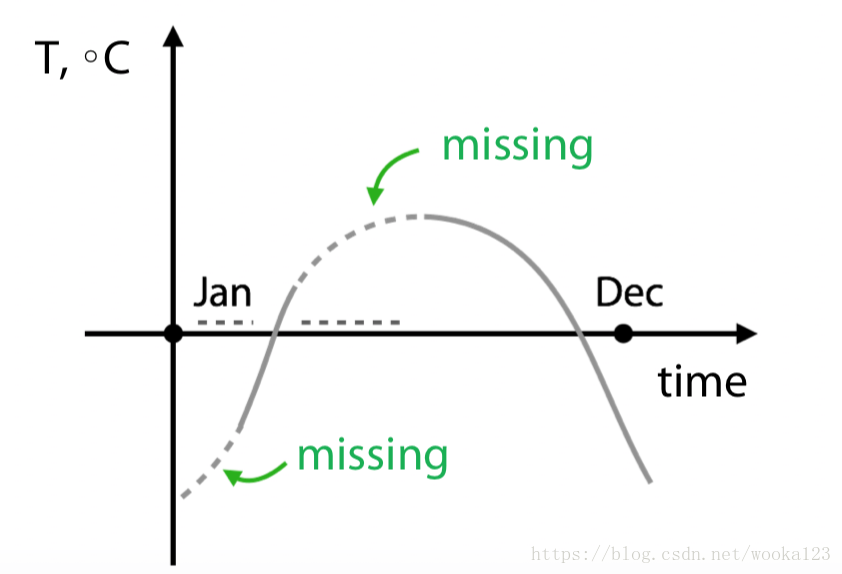
Missing data
Hidden Nan, numeric
When drawing a histgram, we see the following picture:
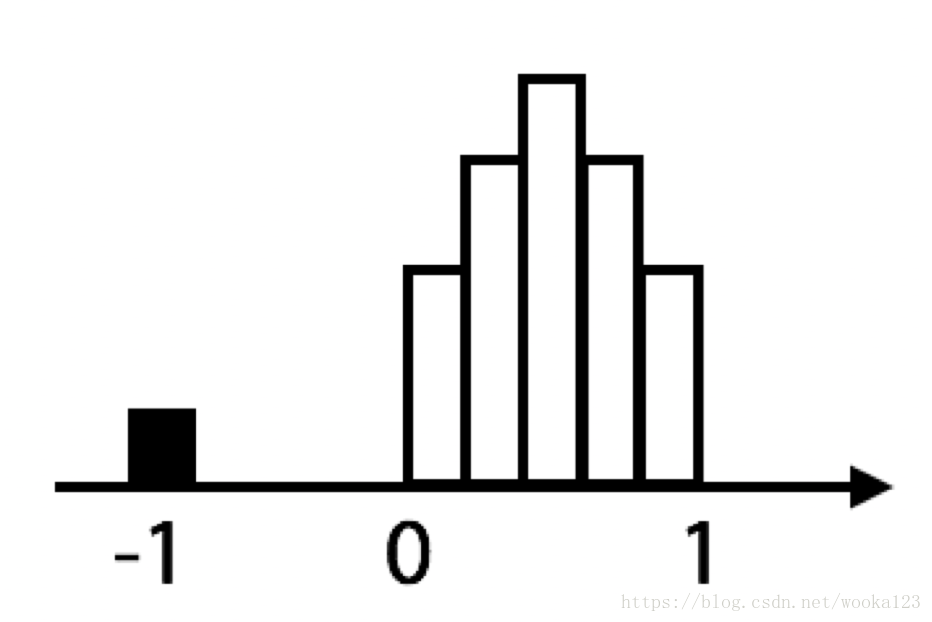
It is obivous that -1 is a hidden Nan which is no meaning for this feature.
Fillna approaches
1.-999,-1,etc(outside the feature range)
It is useful in a way that it gives three possibility to take missing value into separate category. The downside of this is that performance of linear networks can suffer.
2.mean,median
Second method usually beneficial for simple linear models and neural networks. But again for trees it can be harder to select object which had missing values in the first place.
3.Reconstruct:
Isnull
Prediction
* Replace the missing data with the mean of medain grouped by another feature.
But sometimes it can be screwed up, like:
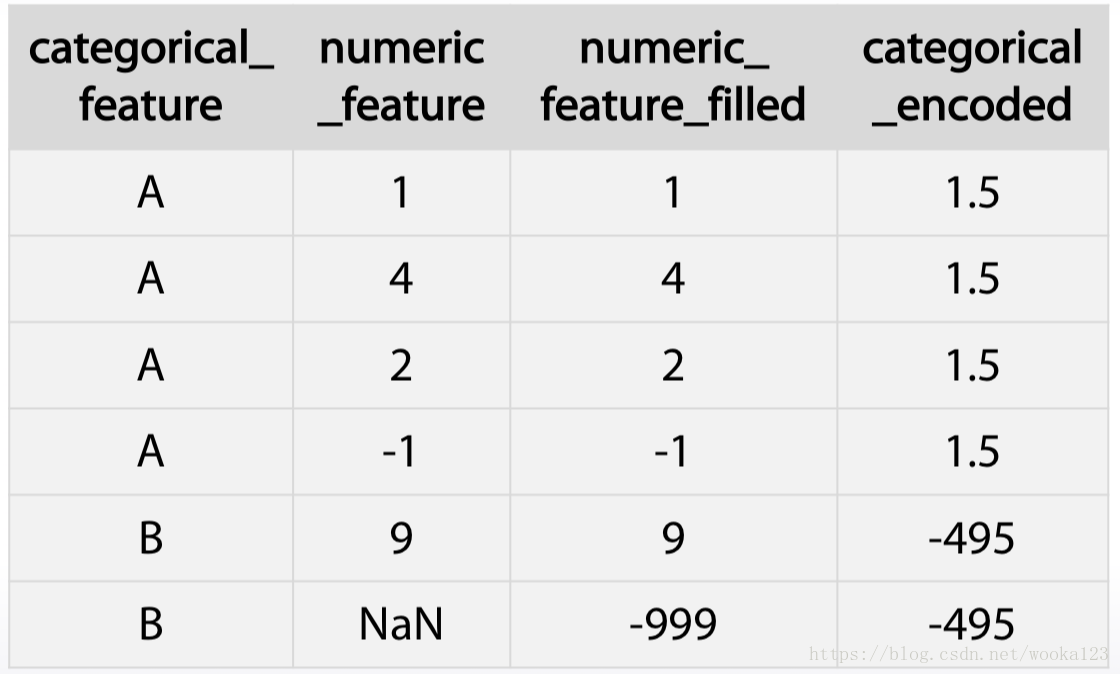
The way to handle this is to ignore missing values while calculating means for each category.
- Treating values which do not present in trian data
Just generate new feature indicating number of occurrence in the data(freqency)
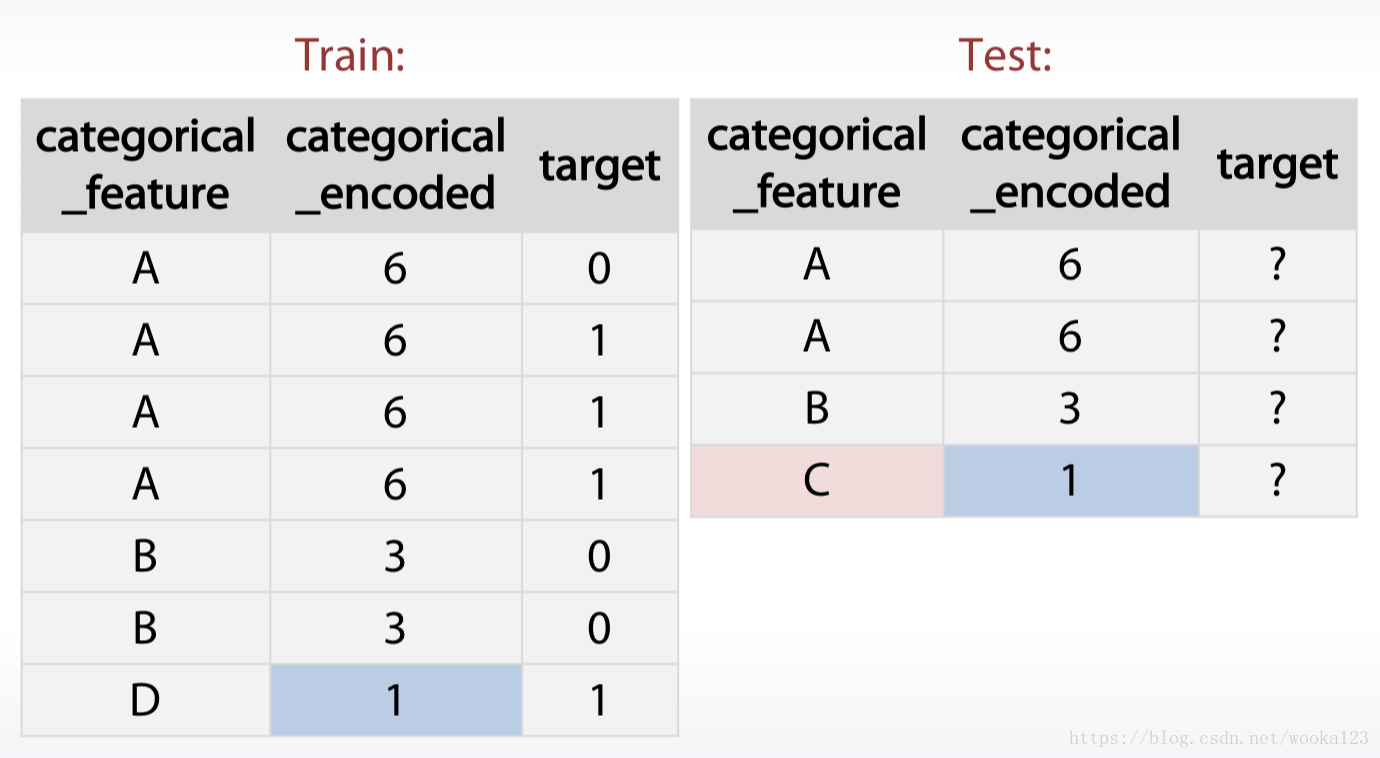
- Xgboost can handle Nan
4.Remove rows with missing values
This one is possible, but it can lead to loss of important samples and a quality decrease.
Text
Bag of words
Text preprocessing
1.Lowercase
2.Lemmatization and Stemming

3.Stopwords
Examples:
1.Articles(冠词) or prepositions
2.Very common words
sklearn.feature_extraction.text.CountVectorizer:
max_df
- max_df : float in range [0.0, 1.0] or int, default=1.0
When building the vocabulary ignore terms that have a document frequency strictly higher than the given threshold (corpus-specific stop words). If float, the parameter represents a proportion of documents, integer absolute counts. This parameter is ignored if vocabulary is not None.
CountVectorizer
The number of times a term occurs in a given document
sklearn.feature_extraction.text.CountVectorizer
TFiDF
In order to re-weight the count features into floating point values suitable for usage by a classifier
Term frequency
tf = 1 / x.sum(axis=1) [:,None]
x = x * tfInverse Document Frequency
idf = np.log(x.shape[0] / (x > 0).sum(0))
x = x * idf
N-gram
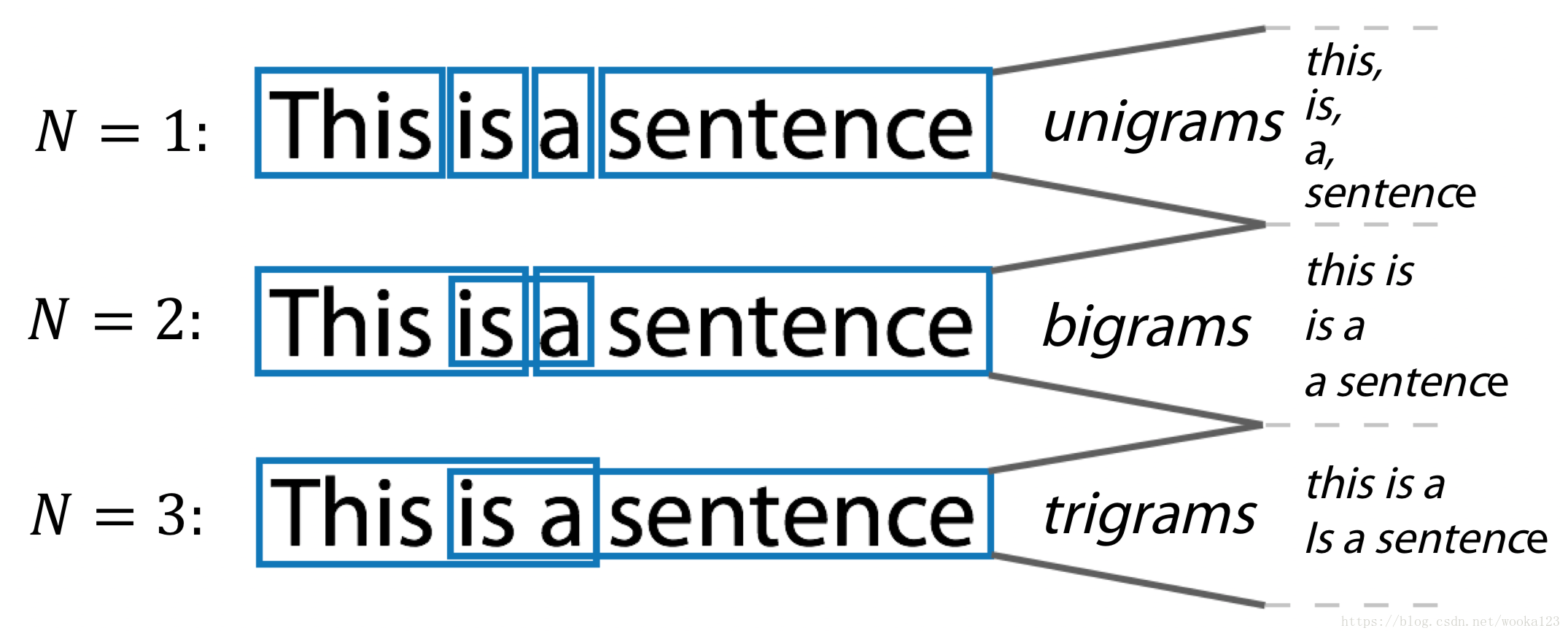
sklearn.feature_extraction.text.CountVectorizer:
Ngram_range, analyzer
- ngram_range : tuple (min_n, max_n)
The lower and upper boundary of the range of n-values for different n-grams to be extracted. All values of n such that min_n <= n <= max_n will be used.
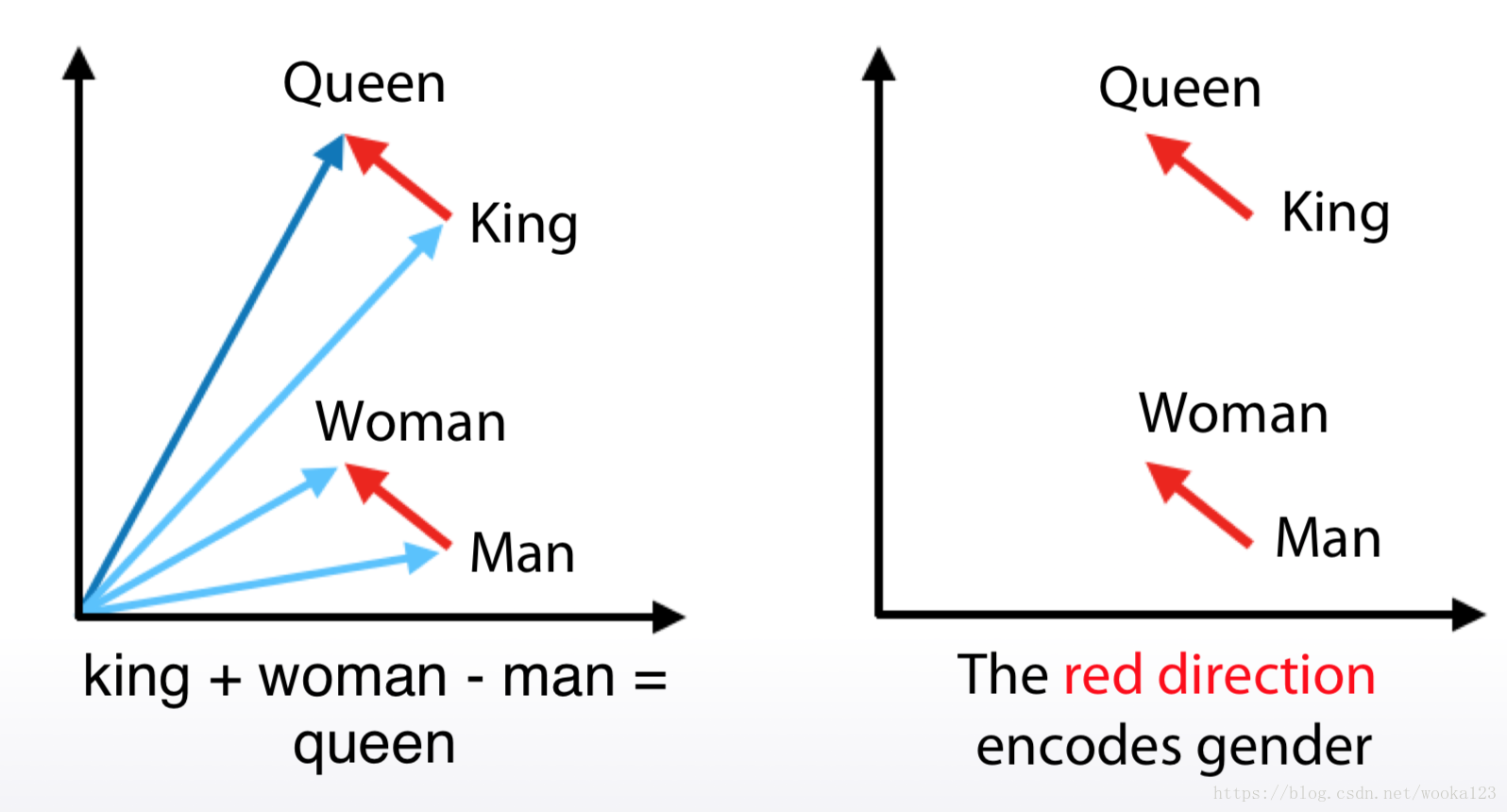
Embeddings(~word2vec)
It converts each word to some vector in some sophisticated space, which usually have several hundred dimensions
a. Relatively small vectors
b. Values in vector can be interpreted only in some cases
c. The words with similar meaning often have similar
embeddings
Example:
Feature Preprocessing on Kaggle的更多相关文章
- Kaggle教程——大神教你上分
本文记录笔者在观看Coursera上国立经济大学HLE的课程 How to win a data science competetion中的收获,和大家分享.课程的这门课的讲授人是Kaggle的大牛, ...
- [Feature] Final pipeline: custom transformers
有视频:https://www.youtube.com/watch?v=BFaadIqWlAg 有代码:https://github.com/jem1031/pandas-pipelines-cust ...
- [ML] Load and preview large scale data
Ref: [Feature] Preprocessing tutorial 主要是 “无量纲化” 之前的部分. 加载数据 一.大数据源 http://archive.ics.uci.edu/ml/ht ...
- scikit-learn:class and function reference(看看你究竟掌握了多少。。)
http://scikit-learn.org/stable/modules/classes.html#module-sklearn.decomposition Reference This is t ...
- 以股票案例入门基于SVM的机器学习
SVM是Support Vector Machine的缩写,中文叫支持向量机,通过它可以对样本数据进行分类.以股票为例,SVM能根据若干特征样本数据,把待预测的目标结果划分成“涨”和”跌”两种,从而实 ...
- Machine Learning : Pre-processing features
from:http://analyticsbot.ml/2016/10/machine-learning-pre-processing-features/ Machine Learning : Pre ...
- 逻辑回归应用之Kaggle泰坦尼克之灾(转)
正文:14pt 代码:15px 1 初探数据 先看看我们的数据,长什么样吧.在Data下我们train.csv和test.csv两个文件,分别存着官方给的训练和测试数据. import pandas ...
- kaggle Titanic心得
Titanic是kaggle上一个练手的比赛,kaggle平台提供一部分人的特征,以及是否遇难,目的是预测另一部分人是否遇难.目前抽工作之余,断断续续弄了点,成绩为0.79426.在这个比赛过程中,接 ...
- Kaggle竞赛 —— 泰坦尼克号(Titanic)
完整代码见kaggle kernel 或 NbViewer 比赛页面:https://www.kaggle.com/c/titanic Titanic大概是kaggle上最受欢迎的项目了,有7000多 ...
随机推荐
- 通向从容之道——Getting things done读书笔记
一.主要的两个目的: 1. 抓住所有一切需要处理的事情: 2. 训练自己在接受一切"输入信息"的前期作出决定. 二.目前的问题: ...
- mobile angualar ui的简单使用
最近做一个微信App形式的业务平台,之前从别人的推荐文中知道了mobile angualar ui这个东西,这次纯做mobile Web就试用了一下,之前PCWeb中用过AngularJS,Hybri ...
- Visual Studio 2017 15.7 下的.NET Core
Visual Studio 2017 15.7版本发布,对.NET Core项目的主要相关改变如下, 同时对Xamarin.Android和iOS项目的支持上也做了较大改进. 一. .NET Core ...
- 大型三甲医院信息管理系统源码 His系统功能齐全 完整可用
详情请点击查看 开发环境 :Asp.net + VS2005 + C# + SQL2010(含三种数据库access,oracle,sql server) 采用了BS+ActiveX + Web ...
- Java多线程:线程与进程
实际上,线程和进程的区别,在学OS时必然是学习过的,所缺的不过是一些总结. 1. 进程 2. 线程 3. 进程与线程 4. 多进程与多线程对比 5. Java多进程与多线程 5.1. Java多进程 ...
- GitHub学习笔记:分支管理
GitHub对于每个开发版本都需要有一个分支,默认的分支是master往往被大家保留下来作为主分支,分支类似于进程的一个指针,往往在master这个稳定的主干版本上分出一个或多个正在开发的分支版本,开 ...
- Python零散函数
1. python json.dumps() json.dump()的区别 注意cat ,是直接输出文件的内容 load和loads都是实现"反序列化",区别在于(以Python为 ...
- Python_FTP通讯软件
ftpServer.py import socket import threading import os import struct #用户账号.密码.主目录 #也可以把这些信息存放到数据库中 us ...
- mybatis查询异常-Error querying database. Cause: java.lang.ClassCastException: org.apache.ibatis.executor.ExecutionPlaceholder cannot be cast to java.util.List
背景,mybatis查询的时候直接取的sqlsession,没有包装成SqlSessionTemplate,没有走spring提供的代理. 然后我写的获取sqlsession的代码没有考虑到并发的情况 ...
- mysql为何不支持开窗函数?
引用 在开窗函数出现之前存在着非常多用 SQL 语句非常难解决的问题,非常多都要通过复杂的相关子查询或者存储过程来完毕.为了解决这些问题,在2003年ISO SQL标准增加了开窗函数,开窗函数的使用使 ...