缓存一致性性协议MESI笔记
概述
今天的笔记只是讲解一下MESI的概念和使用场景的介绍,MESI(Modified Exclusive Shared Or Invalid)也称为伊利诺斯协议,是一种广泛使用的支持协会策略的缓存一致性协议,这里的缓存一致性就是指CPU缓存的一致性。为了让读者明白其中的概念,我们先从CPU说起。
CPU多核
现代的CPU比内存系统快很多,2006年的cpu可以在一纳秒之内执行10条指令,尤其是多CPU,CPU多核。我们先讲解一些基础概念:
多核CPU和多CPU的区别主要在于性能和成本。多核CPU性能最好,但成本最高;多CPU成本小,便宜,但性能相对较差。一个CPU但是多核可以实现并行,单核就是CPU集成了一个运算核心; 双核是两个运算核心,相当于两个CPU同时工作; 四核是四个运算核心,相当于四个CPU同时工作; 简单的比喻: 完成同样的任务,由一条生产线来完成或由两条稍慢的生产线来完成或由四条更慢的生产线来完成,虽然生产线的生产速度慢,但由于同时进行的生产线多,所以任务的最终完成时间可能最短。
假如一个CPU运行多个程序,就意味着要经常进行进程上下文切换,这里说一句进程切换比线程切换成本要高出许多,即使单CPU是多核的,也只是多个处理器核心,其它设备都是公用的,所以多个线程就必然要经常进行进程上下文切换。一个现代CPU除了处理器核心之外还包括寄存器、L1L2L3缓存这些存储设备、浮点运算单元、整数运算单元等一些辅助运算设备以及内部总线等。一个多核的CPU也就是一个CPU上有多个处理器核心,这样有什么好处呢?比如说现在我们要在一台计算机上跑一个多线程的程序,因为是一个进程里的线程,所以需要一些共享一些存储变量,如果这台计算机都是单核单线程CPU的话,就意味着这个程序的不同线程需要经常在CPU之间的外部总线上通信,同时还要处理不同CPU之间不同缓存导致数据不一致的问题,所以在这种场景下多核单CPU的架构就能发挥很大的优势,通信都在内部总线,共用同一个缓存。
CPU缓存
即高速缓冲存储器,是位于CPU与主内存间的一种容量较小但速度很高的存储器。由于CPU的速度远高于主内存,CPU直接从内存中存取数据要等待一定时间周期,Cache中保存着CPU刚用过或循环使用的一部分数据,当CPU再次使用该部分数据时可从Cache中直接调用,减少CPU的等待时间,提高了系统的效率。
现在我们来看一下每级的缓存的处理速度对比:
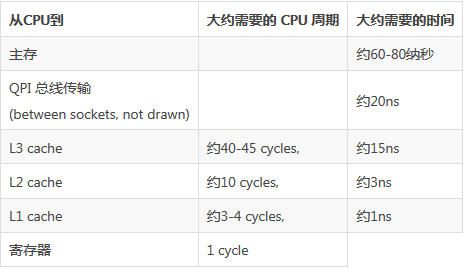
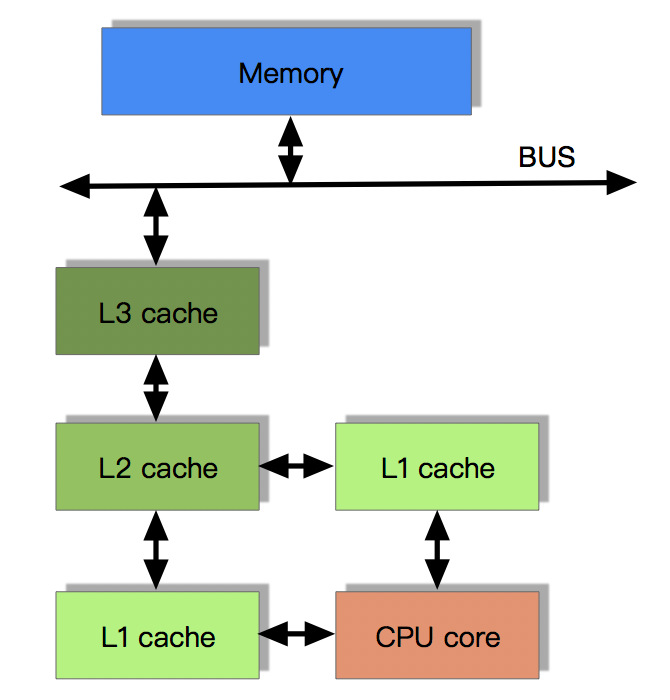
从上图可知,这里面产生了至少两个数量级的速度差距。在这样的问题下,cpu cache应运而生。CPU缓存是位于CPU与内存之间的临时存储器,它的容量比内存小的多但是交换速度却比内存要快得多。CPU高速缓存的出现主要是为了解决CPU运算速度与内存读写速度不匹配的矛盾,按照数据读取顺序和与CPU结合的紧密程度,CPU缓存可以分为一级缓存,二级缓存,如今主流CPU还有三级缓存,甚至有些CPU还有四级缓存。每一级缓存中所储存的全部数据都是下一级缓存的一部分,这三种缓存的技术难度和制造成本是相对递减的,所以其容量也是相对递增的。目前流行的多级缓存结构如下截图:
缓存行:缓存系统中是以缓存行为单位存储的。缓存行是2的整数幂个连续字节,一般为32-256个字节。最常见的缓存行大小是64字节。当多线程修改互相独立的变量时,如果这些变量共享一个缓存行,就会无意中影响彼此的性能,这就是伪共享。缓存行上的写竞争是运行在SMP系统中并行线程实现可伸缩性最重要的限制因素。有人将伪共享描述成无声的性能杀手,因为从代码中很难看清楚是否会出现伪共享。
伪共享问题:
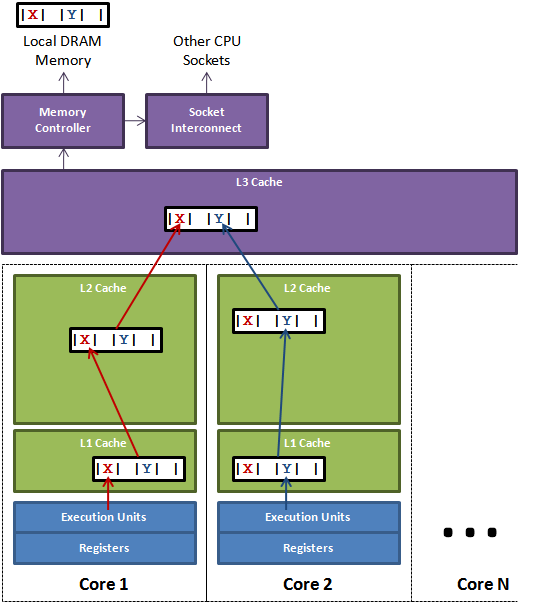
图中说明了伪共享的问题。在核心1上运行的线程想更新变量X,同时核心2上的线程想要更新变量Y。不幸的是,这两个变量在同一个缓存行中。每个线程都要去 竞争缓存行的所有权来更新变量。如果核心1获得了所有权,缓存子系统将会使核心2中对应的缓存行失效。当核心2获得了所有权然后执行更新操作,核心1就要 使自己对应的缓存行失效。这会来来回回的经过L3缓存,大大影响了性能。如果互相竞争的核心位于不同的插槽,就要额外横跨插槽连接,问题可能更加严重。
java中避免伪共享参数:-XX:-RestrictContended
但是现在大部分服务器都是多CPU,数据的读写就会变得异常复杂。我们在进行读写cache的时候,不能简单地读写,因为如果只修改本地cpu的cache,而不处理其他cpu上的同一个数据,那么就会造成一份数据多个不同副本,这就是数据冲突。而解决这个数据冲突的方法就是“缓存一致性协议MESI”。
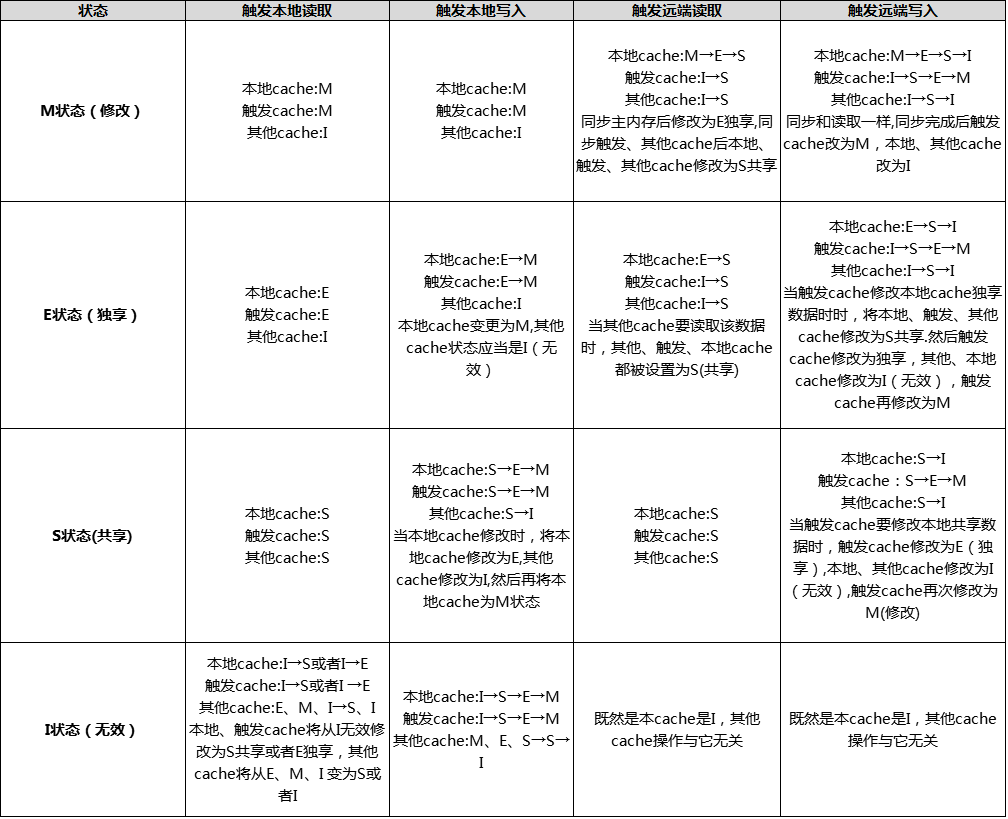
MESI协议中的状态
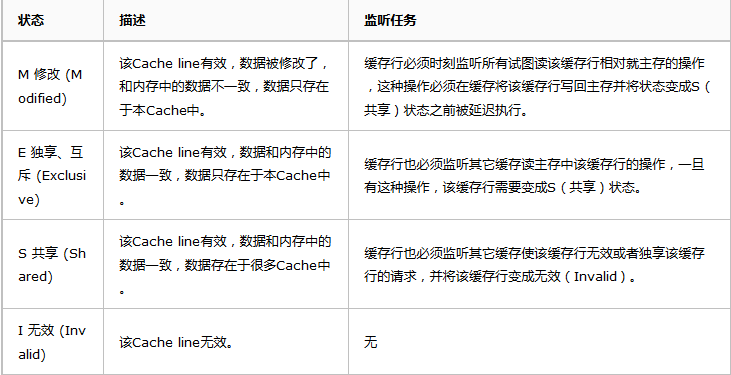
CPU中每个缓存行(caceh line)使用4种状态进行标记(使用额外的两位(bit)表示):
M: 被修改(Modified)
该缓存行只被缓存在该CPU的缓存中,并且是被修改过的(dirty),即与主存中的数据不一致,该缓存行中的内存需要在未来的某个时间点(允许其它CPU读取请主存中相应内存之前)写回(write back)主存。
当被写回主存之后,该缓存行的状态会变成独享(exclusive)状态。
E: 独享的(Exclusive)
该缓存行只被缓存在该CPU的缓存中,它是未被修改过的(clean),与主存中数据一致。该状态可以在任何时刻当有其它CPU读取该内存时变成共享状态(shared)。
同样地,当CPU修改该缓存行中内容时,该状态可以变成Modified状态。
S: 共享的(Shared)
该状态意味着该缓存行可能被多个CPU缓存,并且各个缓存中的数据与主存数据一致(clean),当有一个CPU修改该缓存行中,其它CPU中该缓存行可以被作废(变成无效状态(Invalid))。
I: 无效的(Invalid)
该缓存是无效的(可能有其它CPU修改了该缓存行)。
注意:对于M和E 的状态而言总是精确的,他们在缓存行的真正状态是一致的,二S状态可能是非一致的,如果一个缓存将处于S状态的缓存行作废了,而另一个缓存实际上可能已经独享了该缓存行,但是该缓存却不会将该缓存行升迁为E状态,这是因为其它缓存不会广 播他们作废掉该缓存行的通知,同样由于缓存并没有保存该缓存行的copy的数量,因此(即使有这种通知)也没有办法确定自己是否已经独享了该缓存行。
从上面的意义看来E状态是一种投机性的优化:如果一个CPU想修改一个处于S状态的缓存行,总线事务需要将所有该缓存行的copy变成invalid状态,而修改E状态的缓存不需要使用总线事务。
MESI状态转换
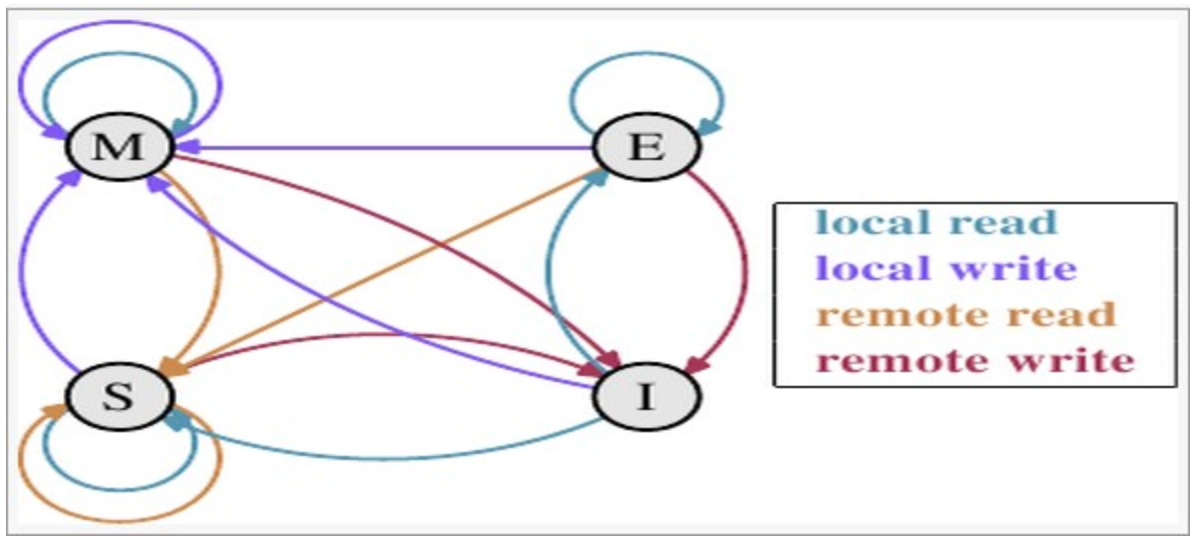
理解该图的前置说明:
1,触发事件:
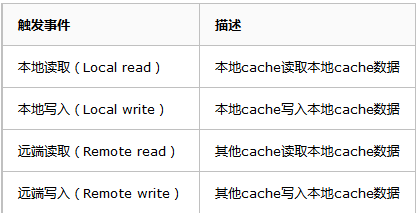
2,cache分类:
前提:所有的cache共同缓存了主内存中的某一条数据。
本地cache:指当前cpu的cache。
触发cache:触发读写事件的cache。
其他cache:指既除了以上两种之外的cache。
注意:本地的事件触发 本地cache和触发cache为相同。
上图的切换解释:
下图示意了,当一个cache line的调整的状态的时候,另外一个cache line 需要调整的状态。

MESI协议中的运行机制
假设有三个CPU A、B、C,对应三个缓存分别是cache a、b、 c。在主内存中定义了x的引用值为0。
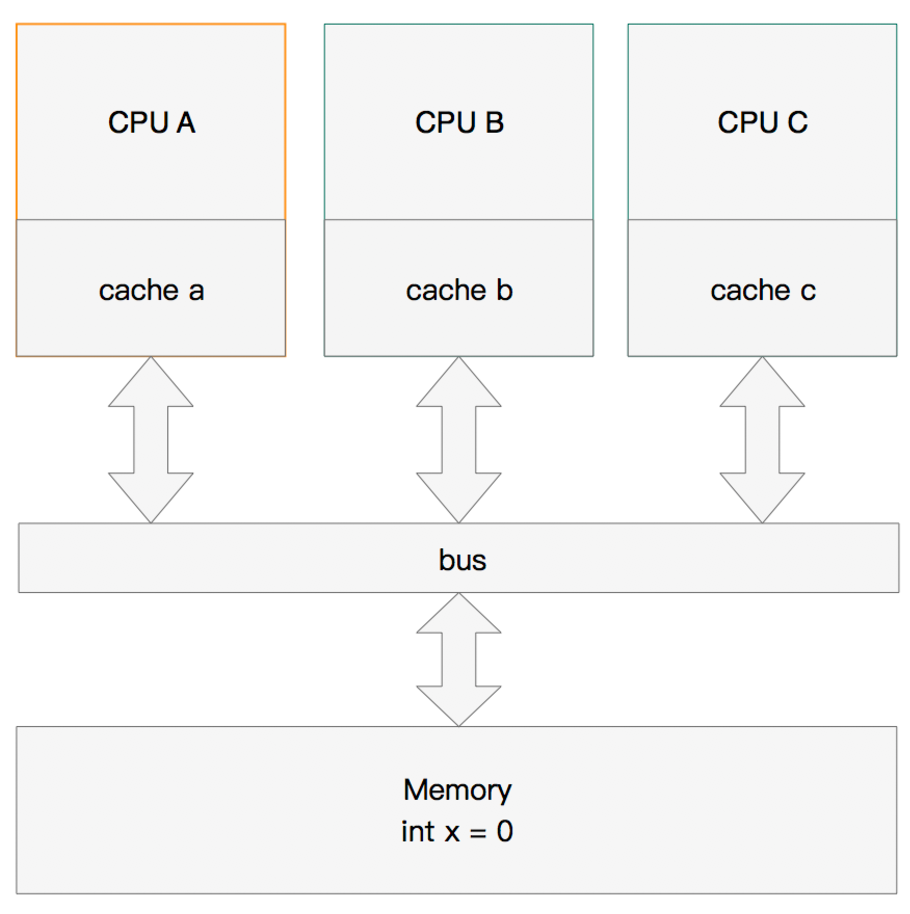
单核读取
那么执行流程是:
CPU A发出了一条指令,从主内存中读取x。
从主内存通过bus读取到缓存中(远端读取Remote read),这是该Cache line修改为E状态(独享)。
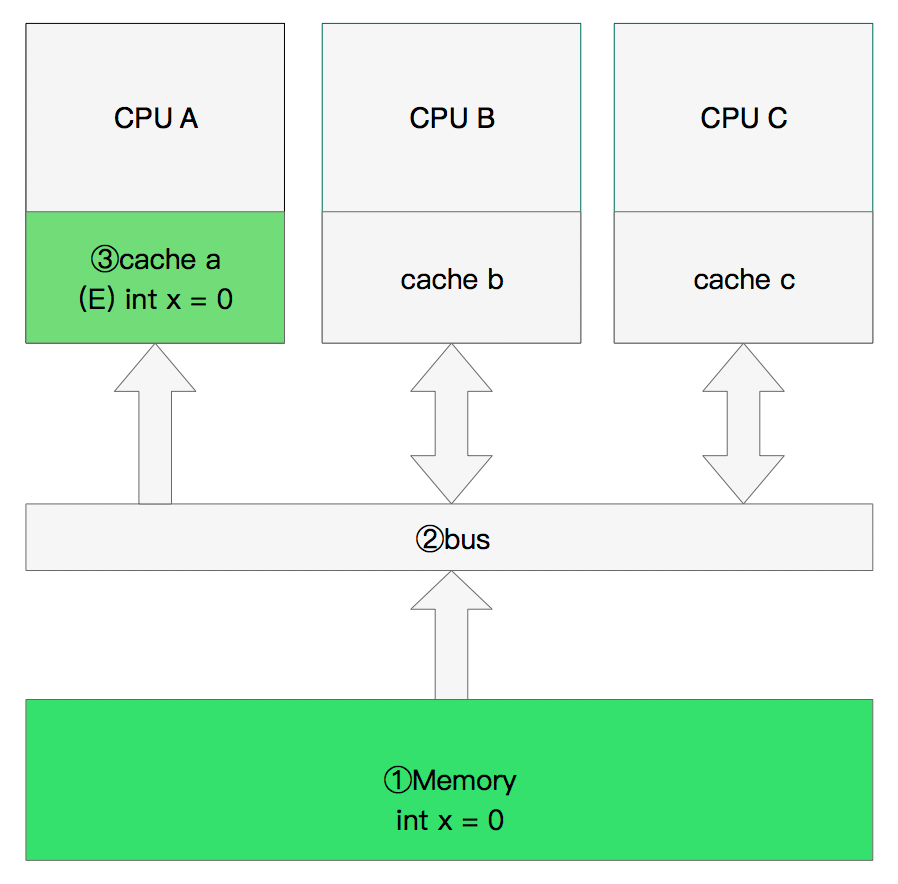
双核读取:
那么执行流程是:
CPU A发出了一条指令,从主内存中读取x。
CPU A从主内存通过bus读取到 cache a中并将该cache line 设置为E状态。
CPU B发出了一条指令,从主内存中读取x。
CPU B试图从主内存中读取x时,CPU A检测到了地址冲突。这时CPU A对相关数据做出响应。此时x 存储于cache a和cache b中,x在chche a和cache b中都被设置为S状态(共享)。
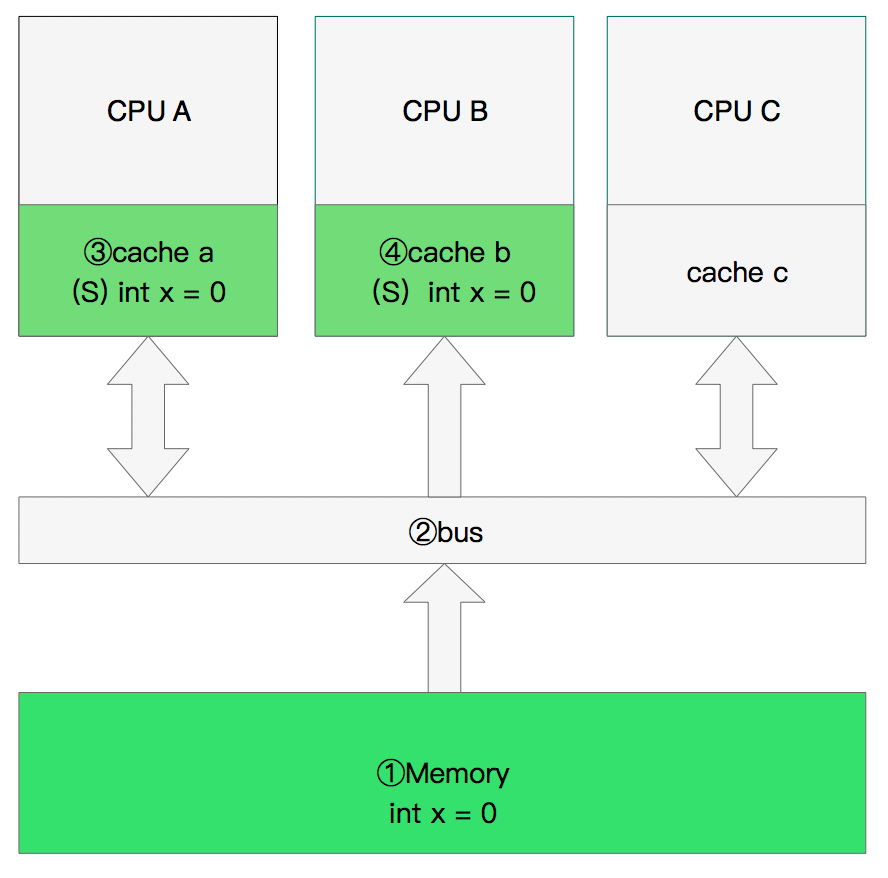
修改数据
那么执行流程是:
CPU A 计算完成后发指令需要修改x.
CPU A 将x设置为M状态(修改)并通知缓存了x的CPU B, CPU B将本地cache b中的x设置为I状态(无效)
CPU A 对x进行赋值。

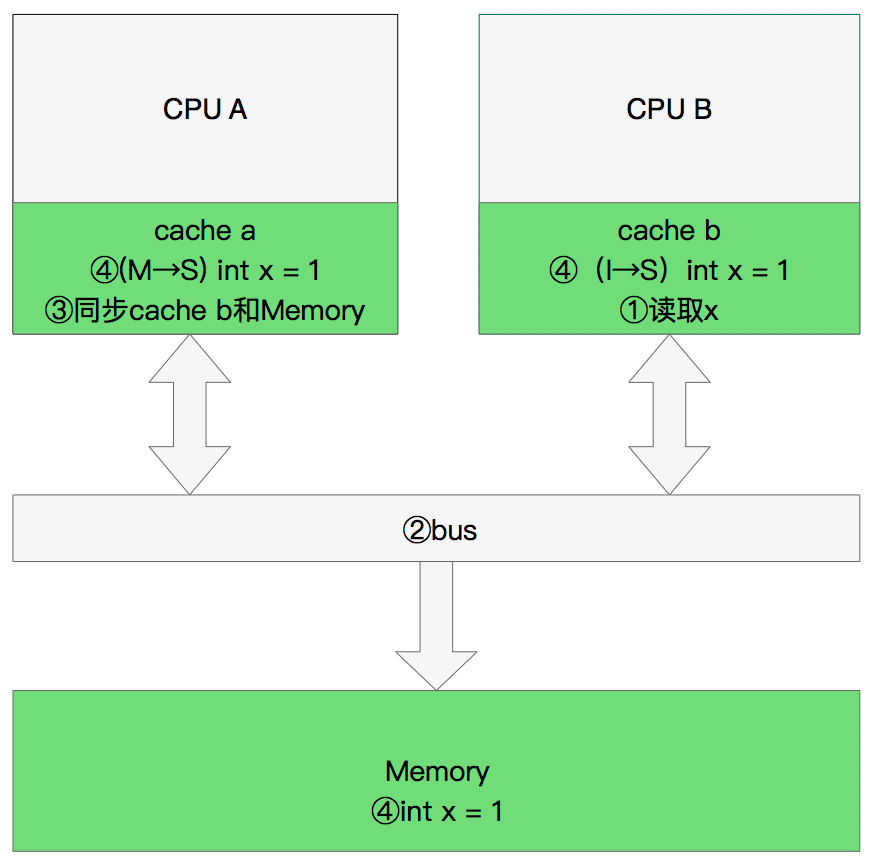
同步数据:
那么执行流程是:
CPU B 发出了要读取x的指令。
CPU B 通知CPU A,CPU A将修改后的数据同步到主内存时cache a 修改为E(独享)
CPU A同步CPU B的x,将cache a和同步后cache b中的x设置为S状态(共享)。
MESI优化和他们引入的问题
缓存的一致性消息传递是要时间的,这就使其切换时会产生延迟。当一个缓存被切换状态时其他缓存收到消息完成各自的切换并且发出回应消息这么一长串的时间中CPU都会等待所有缓存响应完成。可能出现的阻塞都会导致各种各样的性能问题和稳定性问题。
CPU切换状态阻塞解决-存储缓存(Store Bufferes)
比如你需要修改本地缓存中的一条信息,那么你必须将I(无效)状态通知到其他拥有该缓存数据的CPU缓存中,并且等待确认。等待确认的过程会阻塞处理器,这会降低处理器的性能。应为这个等待远远比一个指令的执行时间长的多。
Store Bufferes
为了避免这种CPU运算能力的浪费,Store Bufferes被引入使用。处理器把它想要写入到主存的值写到缓存,然后继续去处理其他事情。当所有失效确认(Invalidate Acknowledge)都接收到时,数据才会最终被提交。
这么做有两个风险。
第一、就是处理器会尝试从存储缓存(Store buffer)中读取值,但它还没有进行提交。这个的解决方案称为Store Forwarding,它使得加载的时候,如果存储缓存中存在,则进行返回。
第二、保存什么时候会完成,这个并没有任何保证。
举例说明:
1 value = 3;
2
3 void exeToCPUA(){
4 value = 10;
5 isFinsh = true;
6 }
7 void exeToCPUB(){
8 if(isFinsh){
9 //value一定等于10?!
10 assert value == 10;
11 }
12 }
试想一下开始执行时,CPU A保存着finished在E(独享)状态,而value并没有保存在它的缓存中。(例如,Invalid)。在这种情况下,value会比 finished更迟地抛弃存储缓存。完全有可能CPU B读取finished的值为true,而value的值不等于10。
即isFinsh的赋值在value赋值之前。
这种在可识别的行为中发生的变化称为重排序(reordings)。注意,这不意味着你的指令的位置被恶意(或者好意)地更改。它只是意味着其他的CPU会读到跟程序中写入的顺序不一样的结果。
硬件内存模型
执行失效也不是一个简单的操作,它需要处理器去处理。另外,存储缓存(Store Buffers)并不是无穷大的,所以处理器有时需要等待失效确认的返回。这两个操作都会使得性能大幅降低。为了应付这种情况,引入了失效队列。它们的约定如下:
对于所有的收到的Invalidate请求,Invalidate Acknowlege消息必须立刻发送。
Invalidate并不真正执行,而是被放在一个特殊的队列中,在方便的时候才会去执行。
处理器不会发送任何消息给所处理的缓存条目,直到它处理Invalidate。
即便是这样处理器已然不知道什么时候优化是允许的,而什么时候并不允许。干脆处理器将这个任务丢给了写代码的人。这就是内存屏障(Memory Barriers)。
写屏障 Store Memory Barrier(a.k.a. ST, SMB, smp_wmb)是一条告诉处理器在执行这之后的指令之前,应用所有已经在存储缓存(store buffer)中的保存的指令。
读屏障Load Memory Barrier (a.k.a. LD, RMB, smp_rmb)是一条告诉处理器在执行任何的加载前,先应用所有已经在失效队列中的失效操作的指令。
1 void executedOnCpu0() {
2 value = 10;
3 //在更新数据之前必须将所有存储缓存(store buffer)中的指令执行完毕。
4 storeMemoryBarrier();
5 finished = true;
6 }
7 void executedOnCpu1() {
8 while(!finished);
9 //在读取之前将所有失效队列中关于该数据的指令执行完毕。
10 loadMemoryBarrier();
11 assert value == 10;
12 }
现在确实安全了。完美无暇。
总结
这篇随笔主要介绍了MESI机制,主要是概念,同时感谢网络大神的分享:
https://www.cnblogs.com/yanlong300/p/8986041.html
https://zhuanlan.zhihu.com/p/43624414
https://www.cnblogs.com/z00377750/p/9180644.html
缓存一致性性协议MESI笔记的更多相关文章
- 并发研究之CPU缓存一致性协议(MESI)
CPU缓存一致性协议MESI CPU高速缓存(Cache Memory) CPU为何要有高速缓存 CPU在摩尔定律的指导下以每18个月翻一番的速度在发展,然而内存和硬盘的发展速度远远不及CPU.这就造 ...
- 一篇文章让你明白CPU缓存一致性协议MESI
CPU高速缓存(Cache Memory) CPU为何要有高速缓存 CPU在摩尔定律的指导下以每18个月翻一番的速度在发展,然而内存和硬盘的发展速度远远不及CPU.这就造成了高性能能的内存和硬盘价格及 ...
- 简述伪共享和缓存一致性MESI
什么是伪共享 计算机系统中为了解决主内存与CPU运行速度的差距,在CPU与主内存之间添加了一级或者多级高速缓冲存储器(Cache),这个Cache一般是集成到CPU内部的,所以也叫 CPU Cache ...
- 10 张图打开 CPU 缓存一致性的大门
前言 直接上,不多 BB 了. 正文 CPU Cache 的数据写入 随着时间的推移,CPU 和内存的访问性能相差越来越大,于是就在 CPU 内部嵌入了 CPU Cache(高速缓存),CPU Cac ...
- Java内存模型(二)volatile底层实现(CPU的缓存一致性协议MESI)
CPU的缓存一致性协议MESI 在多核CPU中,内存中的数据会在多个核心中存在数据副本,某一个核心发生修改操作,就产生了数据不一致的问题,而一致性协议正是用于保证多个CPU cache之间缓存共享数据 ...
- 关于缓存一致性协议、MESI、StoreBuffer、InvalidateQueue、内存屏障、Lock指令和JMM的那点事
前言 事情是这样的,一位读者看了我的一篇文章,不认同我文章里面的观点,于是有了下面的交流. 可能是我发的那个狗头的表情,让这位读者认为我不尊重他.于是,这位读者一气之下把我删掉了,在删好友之前,还叫我 ...
- 多线程之:MESI-CPU缓存一致性协议
MESI(Modified Exclusive Shared Or Invalid)(也称为伊利诺斯协议,是因为该协议由伊利诺斯州立大学提出)是一种广泛使用的支持写回策略的缓存一致性协议,该协议被应用 ...
- CPU缓存一致性协议—MESI详解
MESI(也称伊利诺斯协议)是一种广泛使用的支持写回策略的缓存一致性协议,该协议被应用在Intel奔腾系列的CPU中. MESI协议中的状态 CPU中每个缓存行使用的4种状态进行标记(使用额外的两位b ...
- C和C++中的volatile、内存屏障和CPU缓存一致性协议MESI
目录 1. 前言2 2. 结论2 3. volatile应用场景3 4. 内存屏障(Memory Barrier)4 5. setjmp和longjmp4 1) 结果1(非优化编译:g++ -g -o ...
随机推荐
- 【论文笔记】 Denoising Implicit Feedback for Recommendation
Denoising Implicit Feedback for Recommendation Authors: 王文杰,冯福利,何向南,聂礼强,蔡达成 WSDM'21 新加坡国立大学,中国科学技术大学 ...
- Excel.CurrentWorkbook数据源(Power Query 之 M 语言)
数据源: 任意超级表 目标: 将超级表中的数据加载到Power Query编辑器中 操作过程: 选取超级表中任意单元格(选取普通表时会自动增加插入超级表的步骤)>数据>来自表格/区域 M公 ...
- 私有化 : _x: 单前置下划线,私有化属性或方法;__xx:双前置下划线;__xx__:双前后下划线;属性property
私有化 xx: 公有变量 _x: 单前置下划线,私有化属性或方法,from somemodule import *禁止导入,类对象和子类可以访问 __xx:双前置下划线,避免与子类中的属性命名冲突,无 ...
- 【LeetCode】557. Reverse Words in a String III 解题报告(Java & Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 Java解法 Python解法 日期 题目地址:ht ...
- 【LeetCode】773. Sliding Puzzle 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 题目地址: https://leetcode.com/problems/sliding- ...
- 【LeetCode】380. Insert Delete GetRandom O(1) 解题报告(Python)
[LeetCode]380. Insert Delete GetRandom O(1) 解题报告(Python) 作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxu ...
- 【LeetCode】676. Implement Magic Dictionary 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 字典 汉明间距 日期 题目地址:https://le ...
- C. Arpa's loud Owf and Mehrdad's evil plan
C. Arpa's loud Owf and Mehrdad's evil plan time limit per test 1 second memory limit per test 256 me ...
- TensorFlow.NET机器学习入门【5】采用神经网络实现手写数字识别(MNIST)
从这篇文章开始,终于要干点正儿八经的工作了,前面都是准备工作.这次我们要解决机器学习的经典问题,MNIST手写数字识别. 首先介绍一下数据集.请首先解压:TF_Net\Asset\mnist_png. ...
- CS5211设计EDP转LVDSA转接屏|替代LT7211|DP转LVDS屏驱动 转接板
LT7211是一种用于虚拟现实/显示应用的高性能C/DP1.2至LVDS芯片. 对于DP1.2输入,LT7211可以配置为1.2.4车道,还支持车道交换功能.自适应均衡使其适用于长电缆应用,最大带宽可 ...