KIP-5:Apache Kylin深度集成Hudi
- Q1. What are you trying to do? Articulate your objectives using absolutely no jargon.
- Q2. What problem is this proposal NOT designed to solve?
- Q3. How is it done today, and what are the limits of current practice?
- Q4. What is new in your approach and why do you think it will be successful?
- Q5. Who cares? If you are successful, what difference will it make?
- Q6. What are the risks?
- Q7. How long will it take?
- Q8. How does it work?
Q1. What are you trying to do? Articulate your objectives using absolutely no jargon.
- 对于Hudi数据湖源端集成
- 将企业数据湖中以Hudi格式存储的数据集作为Kylin的源端输入
- 对于Kylin cube重新构建&合并优化
- 支持Kylin的Cuboid使用Hudi格式存储
- 使用Hudi的增量查询视图加速和优化Kylin cube重新构建过程,仅解析上次cube构建后变更的数据
- 使用Hudi的Compaction功能加速和优化Kylin Cube合并过程(针对增量cuboid文件),或者使用Hudi的Upsert功能来合并多个cuboid文件,类似Upsert到MOR表,并支持Select查询
Q2. What problem is this proposal NOT designed to solve?
- 不支持Hudi的其他类型的数据源(例如Kafka)不在此范围内
- 流式CubeEnginer不在此范围内
Q3. How is it done today, and what are the limits of current practice?
- 当前无论输入格式是否为Hudi,Kylin都使用Beeline JDBC机制直接连接到Hive源
- 当前的实现无法利用Hudi的原生和高级功能(例如增量查询、读优化视图查询等),Kylin可以从较小的增量cuboid合并和更快的源数据提取中受益
Q4. What is new in your approach and why do you think it will be successful?
对于Hudi Source集成
- 新的方法
- 使用Hudi的原生优化视图查询和MOR表来加速Kylin的cube构建过程
- 为什么会成功
- Hudi已在大数据领取和技术栈中发布并成熟,许多公司已经在Data Lake/Raw/Curated数据层中使用了Hudi
- Hudi lib已经与Spark DF/Spark SQL集成,可以使用Kylin的Spark Engine查询Hudi数据源
- Hudi的Parquet基础文件和Avro日志以及索引元数据等都可以通过Hive的外部表和输入格式定义进行连接,Kylin可以利用它们进行提取
Hudi作为Cuboid存储
- 新的方法
- 使用Hudi的原生增量视图查询优化Kylin的cube重建过程,以仅捕获变更的数据并仅重新计算和更新必要的cuboid文件
- 使用Hudi的upsert功能来操作cuboid文件,以优化Kylin的cube合并过程;而不是以前的join和shuffle方式
- 为什么会成功
- Hudi根据记录的PK支持upsert,每个cuboid的维度key-id都可以视为PK
- 这样当进行重建和合并操作时,它可以直接更新以前的cuboid文件,或基于PK合并多个cuboid文件并将它们压缩为Parquet文件
Q5. Who cares? If you are successful, what difference will it make?
- 如果在Kylin中启用了新的集成功能,从事数据挖掘/探索/报告等工作的数据科学家将有更快的cube集构建时间
- 正在开发DW/DM层数据建模的数据工程师将最大程度地减少cube上的单元测试/性能测试的实现和交付工作
Q6. What are the risks?
没有其他风险,因为它只是配置Hudi源类型的替代选择,其他Kylin的组件和管道也不会受到影响
Q7. How long will it take?
N/A
Q8. How does it work?
总体架构设计的逻辑图如下:
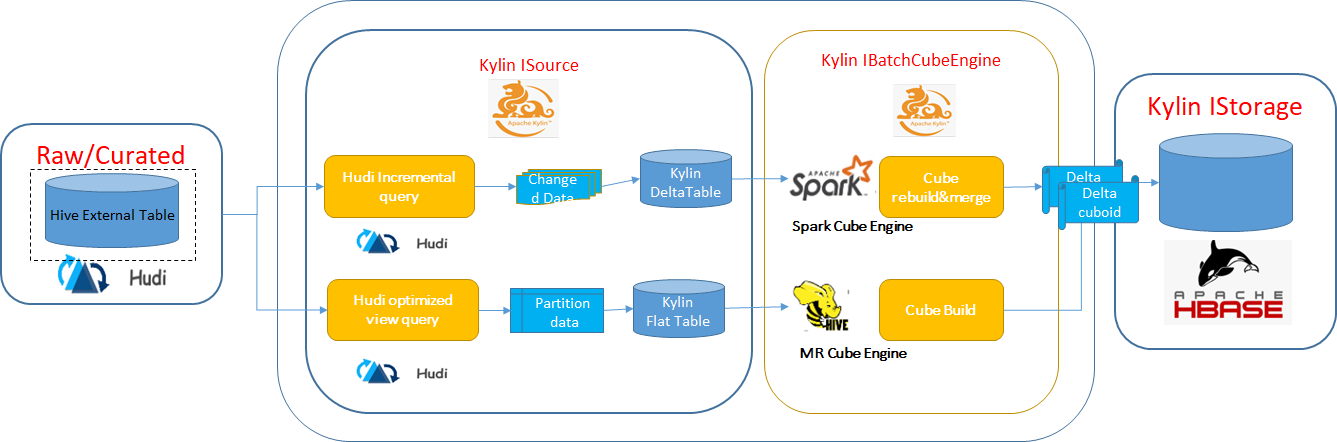
对于Hudi源集成
- 在kylin.property中为Hudi源类型添加新的配置项(例如:isHudiSouce = true,HudiType = MOR)
- 使用Hudi原生客户端API添加新的ISouce接口和实现
- 在配置单元外部表中使用Hudi客户端API查询优化视图及提取源Hudi数据集
对于Hudi cuboid存储
- 在kylin.property中为cuboid的Hudi存储类型添加新的配置项(例如isHudiCuboidStorage = true)
- 使用Hudi编写API添加新的ITarget接口和实现,以实现内部存储和cuboid文件的操作
对于使用新的Hudi源类型cube重建
- 使用Hudi的增量查询API仅从Cube段的时间戳的最后时间提取变更的数据
- 使用Hudi的upsert API合并cuboid的变更数据和以前的历史数据
对于新的Hudi Cuboid存储类型cube合并
- 使用Hudi upsert API合并2个cuboid文件
Reference
Hudi framework: https://hudi.apache.org/docs/
hive/spark integration support for Hudi: https://hudi.apache.org/docs/querying_data.html
KIP-5:Apache Kylin深度集成Hudi的更多相关文章
- 官方教程:Apache Kylin和Superset集成,使用开源组件,完美打造OLAP系统
本文转自Apache Kylin公众号apachekylin. Superset 是一个数据探索和可视化平台,设计用来提供直观的,可视化的,交互式的分析体验. Superset 提供了两种分析数据源的 ...
- 直播 | Apache Kylin & Apache Hudi Meetup
千呼万唤始出来,Meetup 直播终于来啦- 本次线上 Meetup 由 Apache Kylin 与 Apache Hudi 社区联合举办,将于 3 月 14 日晚进行直播,邀请到来自丁香园.腾讯. ...
- Apache Kylin 概述
1 Kylin是什么 今天,随着移动互联网.物联网.AI等技术的快速兴起,数据成为了所有这些技术背后最重要,也是最有价值的"资产".如何从数据中获得有价值的信息?这个问题驱动了相关 ...
- [转帖]Apache Kylin 概述
Apache Kylin 概述 https://www.cnblogs.com/xiaodf/p/11671095.html 1 Kylin是什么 今天,随着移动互联网.物联网.AI等技术的快速兴起, ...
- 【转】使用Apache Kylin搭建企业级开源大数据分析平台
http://www.thebigdata.cn/JieJueFangAn/30143.html 本篇文章整理自史少锋4月23日在『1024大数据技术峰会』上的分享实录:使用Apache Kylin搭 ...
- NoSql存储日志数据之Spring+Logback+Hbase深度集成
NoSql存储日志数据之Spring+Logback+Hbase深度集成 关键词:nosql, spring logback, logback hbase appender 技术框架:spring-d ...
- 大数据分析神兽麒麟(Apache Kylin)
1.Apache Kylin是什么? 在现在的大数据时代,越来越多的企业开始使用Hadoop管理数据,但是现有的业务分析工具(如Tableau,Microstrategy等)往往存在很大的局限,如难以 ...
- 大数据分析界的“神兽”Apache Kylin有多牛?【转】
本文作者:李栋,来自Kyligence公司,也是Apache Kylin Committer & PMC member,在加入Kyligence之前曾就职于eBay.微软. 1.Apache ...
- 使用Apache Kylin搭建企业级开源大数据分析平台
转:http://www.thebigdata.cn/JieJueFangAn/30143.html 我先做一个简单介绍我叫史少锋,我曾经在IBM.eBay做过大数据.云架构的开发,现在是Kylige ...
随机推荐
- Postman报文进行解密之RSA私钥解密
接口返回的数据也是加密的,需要对数据解密才能看到返回的数据是否正确,就需要用RSA解密. 返回数据的解析可以在postman的Tests进行后置处理,获取加密后的返回数据: var data = JS ...
- SQLFlow使用中的注意事项--设置篇
SQLFlow 是用于追溯数据血缘关系的工具,它自诞生以来以帮助成千上万的工程师即用户解决了困扰许久的数据血缘梳理工作. 数据库中视图(View)的数据来自表(Table)或其他视图,视图中字段(Co ...
- WTM Blazor,Blazor开发利器
Blazor从诞生到现在也有一段时间了,之前一直在观望,从dotnet5中Blazor的进步以及即将到来的dotnet6中的规划来看,Blazor的前途还是光明的,所以WtmBlazor来了! Bla ...
- 游戏视野系统算法 (FOV using recursive shadowcasting)
原理 http://www.roguebasin.com/index.php?title=FOV_using_recursive_shadowcasting python代码实现 http://www ...
- mysql unique key
create table b1(id int,name char unique)这样name字段就唯一了 或者create table b1(id int,name char,unique(id),u ...
- Java集合详解(一):全面理解Java集合
概述 Java所有集合类都在java.util包下,支持并发的集合在java.util.concurrent(juc)包下. 集合与数组区别: 数组大小是固定的,集合大小可以根据使用情况进行动态扩容. ...
- JMeter四种参数化方式
JMeter参数化是指把固定的数据动态化,这样更贴合实际的模拟用户请求,比如模拟多个不同账号.JMeter一共有四种参数化方式,分别是: CSV Data Set Config Function He ...
- 交互-通过axios拦截器添加token认证
通过axios拦截器添加token认证 一.通过axios请求拦截器添加token,保证拥有获取数据的权限 通常访问接口需要相关权限,通常是需要携带token如下所示 那如何在请求头中添加token? ...
- [bug] 安装MySQL8.0.15 失败,提示This application requires Visual Studio 2015 x64 Redistributable
参考 https://blog.csdn.net/weixin_44092289/article/details/88045666
- [bug]mysql: The server time zone value 'Öйú±ê׼ʱ¼ä' is unrecognized or represents more than one time zone
原因: 时区设置有误 解决: 在mysql中修改时区设置: 或 在JDBC代码中增加时区设置: Connection c = DriverManager.getConnection("jdb ...