云计算——实验一 HDFS与MAPREDUCE操作
1、虚拟机集群搭建部署hadoop
利用VMware、centOS-7、Xshell(secureCrt)等软件搭建集群部署hadoop
远程连接工具使用Xshell:
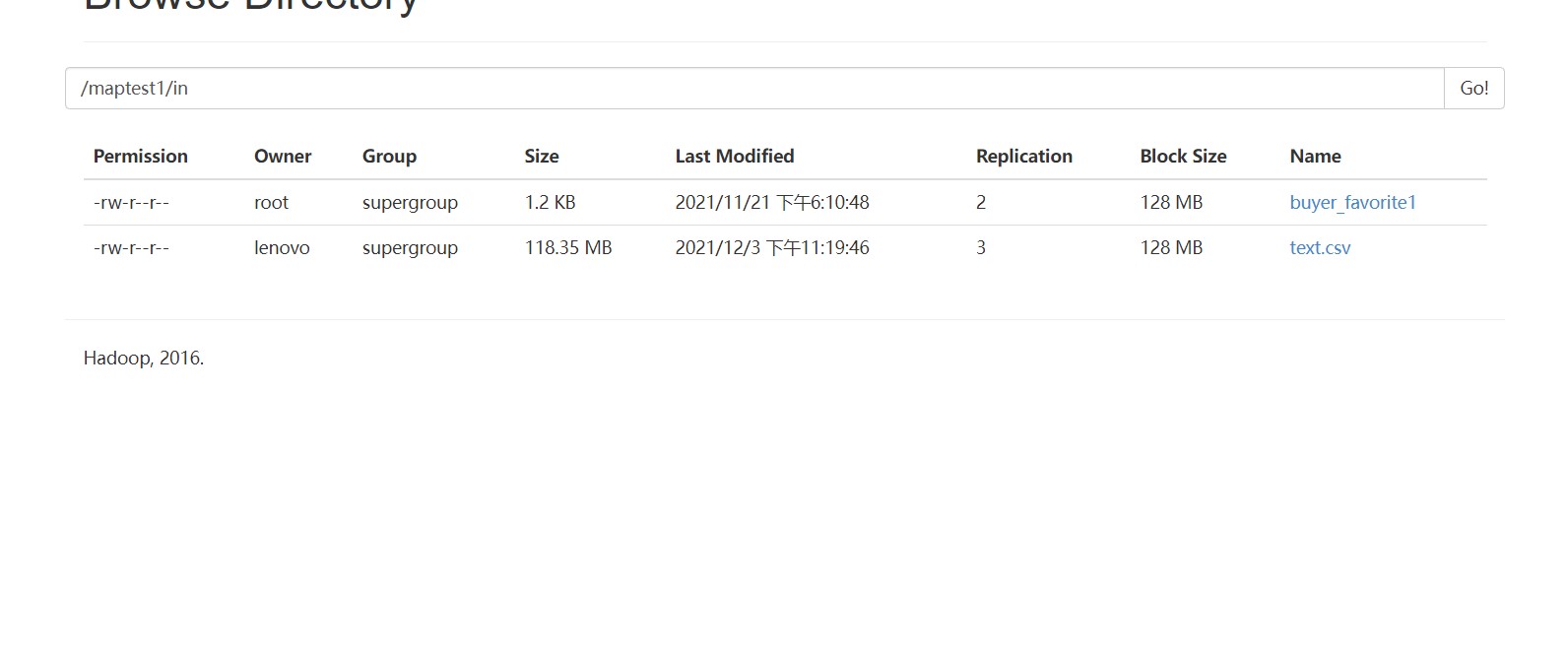
HDFS文件操作

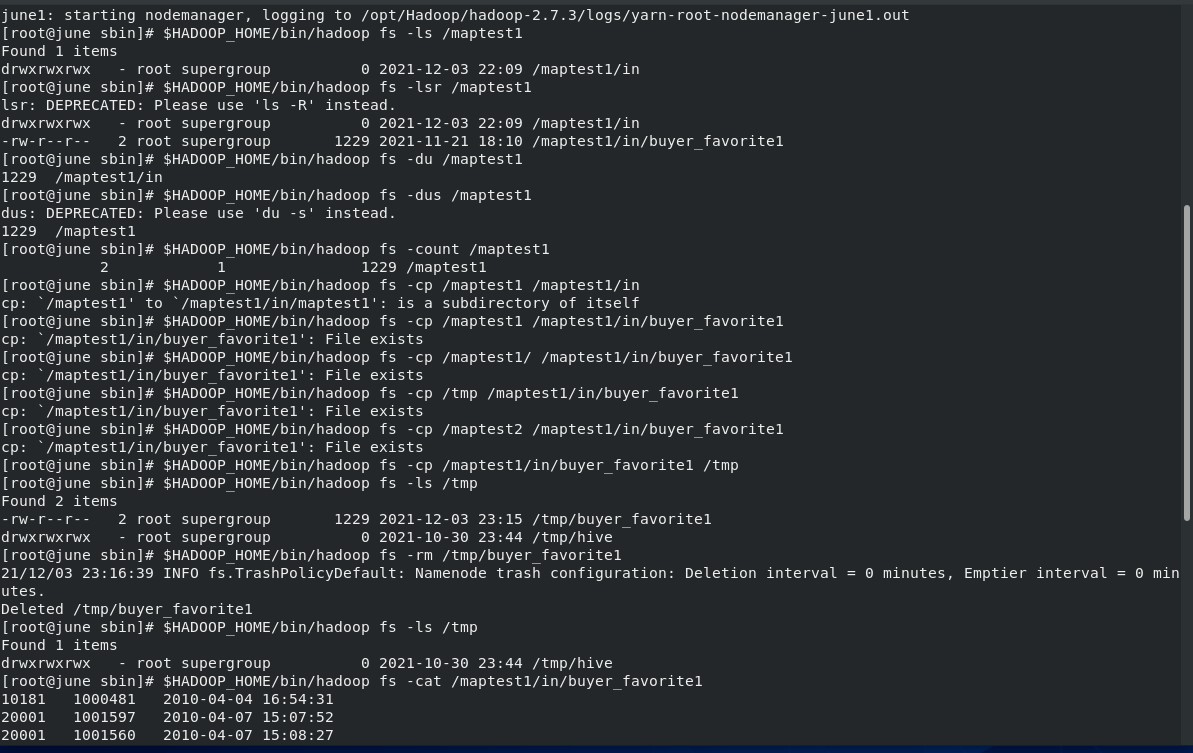
2.1 HDFS接口编程
调用HDFS文件接口实现对分布式文件系统中文件的访问,如创建、修改、删除等

三、MAPREDUCE并行程序开发
求每年最高气温
本实验是编写完成相关代码后,将该项目打包成jar包,上传至centos后利用hadoop命令进行运行。

import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Temperature {
/**
* 四个泛型类型分别代表:
* KeyIn Mapper的输入数据的Key,这里是每行文字的起始位置(0,11,...)
* ValueIn Mapper的输入数据的Value,这里是每行文字
* KeyOut Mapper的输出数据的Key,这里是每行文字中的“年份”
* ValueOut Mapper的输出数据的Value,这里是每行文字中的“气温”
*/
static class TempMapper extends
Mapper<LongWritable, Text, Text, IntWritable> {
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 打印样本: Before Mapper: 0, 2000010115
System.out.print("Before Mapper: " + key + ", " + value);
String line = value.toString();
String year = line.substring(0, 4);
int temperature = Integer.parseInt(line.substring(8));
context.write(new Text(year), new IntWritable(temperature));
// 打印样本: After Mapper:2000, 15
System.out.println(
"======" +
"After Mapper:" + new Text(year) + ", " + new IntWritable(temperature));
}
} static class TempReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int maxValue = Integer.MIN_VALUE;
StringBuffer sb = new StringBuffer();
//取values的最大值
for (IntWritable value : values) {
maxValue = Math.max(maxValue, value.get());
sb.append(value).append(", ");
}
// 打印样本: Before Reduce: 2000, 15, 23, 99, 12, 22,
System.out.print("Before Reduce: " + key + ", " + sb.toString());
context.write(key, new IntWritable(maxValue));
// 打印样本: After Reduce: 2000, 99
System.out.println(
"======" +
"After Reduce: " + key + ", " + maxValue);
}
} public static void main(String[] args) throws Exception {
//输入路径
String dst = "hdfs://localhost:9000/intput.txt";
//输出路径,必须是不存在的,空文件加也不行。
String dstOut = "hdfs://localhost:9000/output";
Configuration hadoopConfig = new Configuration(); hadoopConfig.set("fs.hdfs.impl",
org.apache.hadoop.hdfs.DistributedFileSystem.class.getName()
);
hadoopConfig.set("fs.file.impl",
org.apache.hadoop.fs.LocalFileSystem.class.getName()
);
Job job = new Job(hadoopConfig); //如果需要打成jar运行,需要下面这句
job.setJarByClass(NewMaxTemperature.class); //job执行作业时输入和输出文件的路径
FileInputFormat.addInputPath(job, new Path(dst));
FileOutputFormat.setOutputPath(job, new Path(dstOut)); //指定自定义的Mapper和Reducer作为两个阶段的任务处理类
job.setMapperClass(TempMapper.class);
job.setReducerClass(TempReducer.class); //设置最后输出结果的Key和Value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//执行job,直到完成
job.waitForCompletion(true);
System.out.println("Finished");
}
}
词频统计


import java.io.IOException; import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ @Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
//super.map(key, value, context);
//String[] words = StringUtils.split(value.toString());
String[] words = StringUtils.split(value.toString(), " ");
for(String word:words)
{
context.write(new Text(word), new LongWritable(1)); }
}
} reducer:
package cn.edu.bupt.wcy.wordcount; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> { @Override
protected void reduce(Text arg0, Iterable<LongWritable> arg1,
Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
// TODO Auto-generated method stub
//super.reduce(arg0, arg1, arg2);
int sum=0;
for(LongWritable num:arg1)
{
sum += num.get(); }
context.write(arg0,new LongWritable(sum)); }
} runner:
package cn.edu.bupt.wcy.wordcount; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class WordCountRunner { public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(WordCountRunner.class);
job.setJobName("wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[1]));
FileOutputFormat.setOutputPath(job, new Path(args[2]));
job.waitForCompletion(true);
} }
云计算——实验一 HDFS与MAPREDUCE操作的更多相关文章
- Linux实验:hdfs shell基本命令操作(一)
[实验目的] 1)熟练hdfs shell命令操作 2)理解hdfs shell和linux shell命令 [实验原理] 安装好hadoop环境之后,可以执行hdfs shell命令对hdfs 的空 ...
- Linux实验:hdfs shell基本命令操作(二)
[实验目的] 1)熟练hdfs shell命令操作 2)理解hdfs shell和linux shell命令[实验原理] 安装好hadoop环境之后,可以执行hdfs shell命令 ...
- 4 weekend110的hdfs&mapreduce测试 + hdfs的实现机制初始 + hdfs的shell操作 + 无密登陆配置
Hdfs是根/目录,windows是每一个盘符, 1 从Linux里传一个到,hdfs里去 2 从hdfs里下一个到,linux里去 想从hdfs里,下载到linux, 涨知识,记住,hdfs是建 ...
- 高可用,完全分布式Hadoop集群HDFS和MapReduce安装配置指南
原文:http://my.oschina.net/wstone/blog/365010#OSC_h3_13 (WJW)高可用,完全分布式Hadoop集群HDFS和MapReduce安装配置指南 [X] ...
- 大数据开发实战:HDFS和MapReduce优缺点分析
一. HDFS和MapReduce优缺点 1.HDFS的优势 HDFS的英文全称是 Hadoop Distributed File System,即Hadoop分布式文件系统,它是Hadoop的核心子 ...
- hadoop之HDFS与MapReduce
Hadoop历史 雏形开始于2002年的Apache的Nutch,Nutch是一个开源Java 实现的搜索引擎.它提供了我们运行自己的搜索引擎所需的全部工具.包括全文搜索和Web爬虫. 随后在2003 ...
- HBase 相关API操练(三):MapReduce操作HBase
MapReduce 操作 HBase 在 HBase 系统上运行批处理运算,最方便和实用的模型依然是 MapReduce,如下图所示. HBase Table 和 Region 的关系类似 HDFS ...
- Hadoop平台上HDFS和MapReduce的功能
1.用自己的话阐明Hadoop平台上HDFS和MapReduce的功能.工作原理和工作过程. HDFS (1)第一次启动 namenode 格式化后,创建 fsimage 和 edits 文件.如果不 ...
- 7.MapReduce操作Hbase
7 HBase的MapReduce HBase中Table和Region的关系,有些类似HDFS中File和Block的关系.由于HBase提供了配套的与MapReduce进行交互的API如 Ta ...
随机推荐
- HTTPS握手-混合加解密过程
SSL协议通信过程 (1) 浏览器发送一个连接请求给服务器;服务器将自己的证书(包含服务器公钥S_PuKey).对称加密算法种类及其他相关信息返回客户端; (2) 客户端浏览器检查服务器传送到CA证书 ...
- 在react项目中实现表格导出为Excel
需求背景 数据表格有时需要增加导出Excel功能,大多数情况下都是后端出下载接口,前端去调用. 对于数据量少的数据,可以通过前端技术实现,减少后端工作. 实现方式 使用插件--xlsx 根据自己项目情 ...
- JAVA使用netty建立websocket连接
依赖 <!-- https://mvnrepository.com/artifact/commons-io/commons-io --> <dependency> <gr ...
- 【LeetCode】9. Palindrome Number 回文数
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 公众号:负雪明烛 本文关键词:回文数,回文,题解,Leetcode, 力扣,Python ...
- 【LeetCode】662. Maximum Width of Binary Tree 解题报告(Python)
[LeetCode]662. Maximum Width of Binary Tree 解题报告(Python) 标签(空格分隔): LeetCode 题目地址:https://leetcode.co ...
- idea使用教程-模板的使用
一.代码模板是什么 它的原理就是配置一些常用代码字母缩写,在输入简写时可以出现你预定义的固定模式的代码,使得开发效率大大提高,同时也可以增加个性化.最简单的例子就是在Java中输入sout会出现Sys ...
- <学习opencv>opencv数据类型
目录 Opencv数据类型: 基础类型概述 固定向量类class cv::Vec<> 固定矩阵类cv::Matx<> 点类 Point class cv::Scalar 深入了 ...
- CS5210完全替代AG6202|HDMI转VGA芯片+原理图|替代兼容AG6202
安格AG6202是一个HDMI转VGA不带音频解决方案,用于实现HDMI1.4高分辨率视频转VGA转换器.Capstone CS5210不管在性能上和设计参数上面都是可以完全替代安格AG6202,且 ...
- Java初学者作业——编写 Java 程序,在控制台中输入日期,计算该日期是对应年份的第几天。
返回本章节 返回作业目录 需求说明: 编写 Java 程序,在控制台中输入日期,计算该日期是对应年份的第几天. 实现思路: (1)声明变量 year.month和 date,用于存储日期中的年.月.日 ...
- Java高级程序设计笔记 • 【第6章 设计模式】
全部章节 >>>> 本章目录 6.1 设计模式 6.1.1 设计模式概述和分类 6.1.2 单列模式介绍 6.1.3 单例模式的实现 6.1.4 实践练习 6.2 单例模式 ...