Flink进入大厂面试准备,收藏这一篇就够了
1. Flink 的容错机制(checkpoint)
Checkpoint机制是Flink可靠性的基石,可以保证Flink集群在某个算子因为某些原因(如 异常退出)出现故障时,能够将整个应用流图的状态恢复到故障之前的某一状态,保证应用流图状态的一致性。Flink的Checkpoint机制原理来自“Chandy-Lamport algorithm”算法。
每个需要Checkpoint的应用在启动时,Flink的JobManager为其创建一个 CheckpointCoordinator(检查点协调器),CheckpointCoordinator全权负责本应用的快照制作。
CheckpointCoordinator(检查点协调器),CheckpointCoordinator全权负责本应用的快照制作。 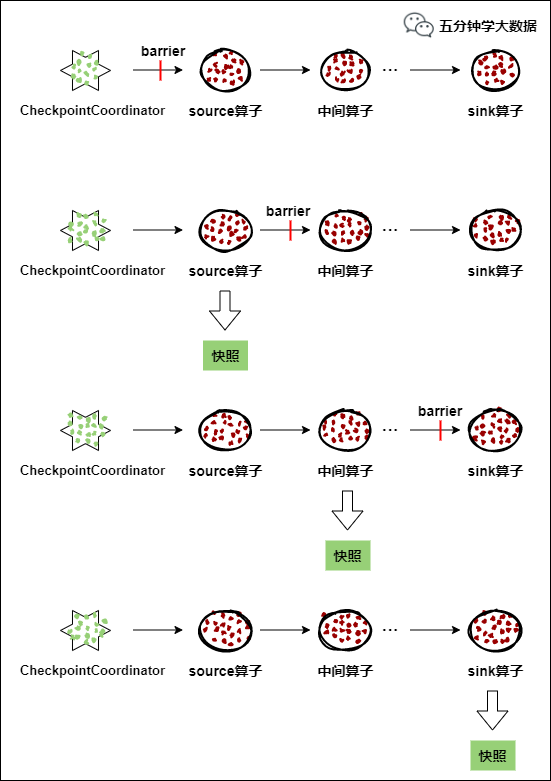
CheckpointCoordinator(检查点协调器) 周期性的向该流应用的所有source算子发送 barrier(屏障)。
当某个source算子收到一个barrier时,便暂停数据处理过程,然后将自己的当前状态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告自己快照制作情况,同时向自身所有下游算子广播该barrier,恢复数据处理
下游算子收到barrier之后,会暂停自己的数据处理过程,然后将自身的相关状态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告自身快照情况,同时向自身所有下游算子广播该barrier,恢复数据处理。
每个算子按照步骤3不断制作快照并向下游广播,直到最后barrier传递到sink算子,快照制作完成。
当CheckpointCoordinator收到所有算子的报告之后,认为该周期的快照制作成功; 否则,如果在规定的时间内没有收到所有算子的报告,则认为本周期快照制作失败。
文章推荐:
2. Flink Checkpoint与 Spark 的相比,Flink 有什么区别或优势吗
Spark Streaming 的 Checkpoint 仅仅是针对 Driver 的故障恢复做了数据和元数据的 Checkpoint。而 Flink 的 Checkpoint 机制要复杂了很多,它采用的是轻量级的分布式快照,实现了每个算子的快照,及流动中的数据的快照。
3. Flink 中的 Time 有哪几种
Flink中的时间有三种类型,如下图所示:
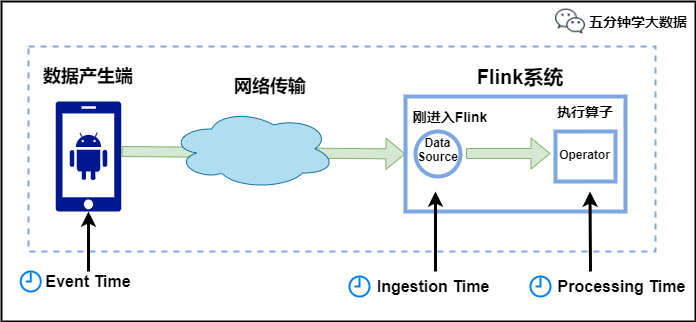
Event Time:是事件创建的时间。它通常由事件中的时间戳描述,例如采集的日志数据中,每一条日志都会记录自己的生成时间,Flink通过时间戳分配器访问事件时间戳。
Ingestion Time:是数据进入Flink的时间。
Processing Time:是每一个执行基于时间操作的算子的本地系统时间,与机器相关,默认的时间属性就是Processing Time。
例如,一条日志进入Flink的时间为2021-01-22 10:00:00.123,到达Window的系统时间为2021-01-22 10:00:01.234,日志的内容如下:
2021-01-06 18:37:15.624 INFO Fail over to rm2
对于业务来说,要统计1min内的故障日志个数,哪个时间是最有意义的?—— eventTime,因为我们要根据日志的生成时间进行统计。
4. 对于迟到数据是怎么处理的
Flink中 WaterMark 和 Window 机制解决了流式数据的乱序问题,对于因为延迟而顺序有误的数据,可以根据eventTime进行业务处理,对于延迟的数据Flink也有自己的解决办法,主要的办法是给定一个允许延迟的时间,在该时间范围内仍可以接受处理延迟数据:
设置允许延迟的时间是通过allowedLateness(lateness: Time)设置
保存延迟数据则是通过sideOutputLateData(outputTag: OutputTag[T])保存
获取延迟数据是通过DataStream.getSideOutput(tag: OutputTag[X])获取
文章推荐:
Flink 中极其重要的 Time 与 Window 详细解析
5. Flink 的运行必须依赖 Hadoop 组件吗
Flink可以完全独立于Hadoop,在不依赖Hadoop组件下运行。但是做为大数据的基础设施,Hadoop体系是任何大数据框架都绕不过去的。Flink可以集成众多Hadooop 组件,例如Yarn、Hbase、HDFS等等。例如,Flink可以和Yarn集成做资源调度,也可以读写HDFS,或者利用HDFS做检查点。
6. Flink集群有哪些角色?各自有什么作用
有以下三个角色:
JobManager处理器:
也称之为Master,用于协调分布式执行,它们用来调度task,协调检查点,协调失败时恢复等。Flink运行时至少存在一个master处理器,如果配置高可用模式则会存在多个master处理器,它们其中有一个是leader,而其他的都是standby。
TaskManager处理器:
也称之为Worker,用于执行一个dataflow的task(或者特殊的subtask)、数据缓冲和data stream的交换,Flink运行时至少会存在一个worker处理器。
Clint客户端:
Client是Flink程序提交的客户端,当用户提交一个Flink程序时,会首先创建一个Client,该Client首先会对用户提交的Flink程序进行预处理,并提交到Flink集群中处理,所以Client需要从用户提交的Flink程序配置中获取JobManager的地址,并建立到JobManager的连接,将Flink Job提交给JobManager
7. Flink 资源管理中 Task Slot 的概念
在Flink中每个TaskManager是一个JVM的进程, 可以在不同的线程中执行一个或多个子任务。
为了控制一个worker能接收多少个task。worker通过task slot(任务槽)来进行控制(一个worker至少有一个task slot)。
8. Flink的重启策略了解吗
Flink支持不同的重启策略,这些重启策略控制着job失败后如何重启:
- 固定延迟重启策略
固定延迟重启策略会尝试一个给定的次数来重启Job,如果超过了最大的重启次数,Job最终将失败。在连续的两次重启尝试之间,重启策略会等待一个固定的时间。
- 失败率重启策略
失败率重启策略在Job失败后会重启,但是超过失败率后,Job会最终被认定失败。在两个连续的重启尝试之间,重启策略会等待一个固定的时间。
- 无重启策略
Job直接失败,不会尝试进行重启。
9. Flink 是如何保证 Exactly-once 语义的
Flink通过实现两阶段提交和状态保存来实现端到端的一致性语义。分为以下几个步骤:
开始事务(beginTransaction)创建一个临时文件夹,来写把数据写入到这个文件夹里面
预提交(preCommit)将内存中缓存的数据写入文件并关闭
正式提交(commit)将之前写完的临时文件放入目标目录下。这代表着最终的数据会有一些延迟
丢弃(abort)丢弃临时文件
若失败发生在预提交成功后,正式提交前。可以根据状态来提交预提交的数据,也可删除预提交的数据。
文章推荐:
八张图搞懂 Flink 端到端精准一次处理语义 Exactly-once
10. 如果下级存储不支持事务,Flink 怎么保证 exactly-once
端到端的 exactly-once 对 sink 要求比较高,具体实现主要有幂等写入和事务性写入两种方式。
幂等写入的场景依赖于业务逻辑,更常见的是用事务性写入。而事务性写入又有预写日志(WAL)和两阶段提交(2PC)两种方式。
如果外部系统不支持事务,那么可以用预写日志的方式,把结果数据先当成状态保存,然后在收到 checkpoint 完成的通知时,一次性写入 sink 系统。
11. Flink是如何处理反压的
Flink 内部是基于 producer-consumer 模型来进行消息传递的,Flink的反压设计也是基于这个模型。Flink 使用了高效有界的分布式阻塞队列,就像 Java 通用的阻塞队列(BlockingQueue)一样。下游消费者消费变慢,上游就会受到阻塞。
12. Flink中的状态存储
Flink在做计算的过程中经常需要存储中间状态,来避免数据丢失和状态恢复。选择的状态存储策略不同,会影响状态持久化如何和 checkpoint 交互。Flink提供了三种状态存储方式:MemoryStateBackend、FsStateBackend、RocksDBStateBackend。
13. Flink是如何支持流批一体的
这道题问的比较开阔,如果知道Flink底层原理,可以详细说说,如果不是很了解,就直接简单一句话:Flink的开发者认为批处理是流处理的一种特殊情况。批处理是有限的流处理。Flink 使用一个引擎支持了 DataSet API 和 DataStream API。
14. Flink的内存管理是如何做的
Flink 并不是将大量对象存在堆上,而是将对象都序列化到一个预分配的内存块上。此外,Flink大量的使用了堆外内存。如果需要处理的数据超出了内存限制,则会将部分数据存储到硬盘上。Flink 为了直接操作二进制数据实现了自己的序列化框架。
15. Flink CEP 编程中当状态没有到达的时候会将数据保存在哪里
在流式处理中,CEP 当然是要支持 EventTime 的,那么相对应的也要支持数据的迟到现象,也就是watermark的处理逻辑。CEP对未匹配成功的事件序列的处理,和迟到数据是类似的。在 Flink CEP的处理逻辑中,状态没有满足的和迟到的数据,都会存储在一个Map数据结构中,也就是说,如果我们限定判断事件序列的时长为5分钟,那么内存中就会存储5分钟的数据,这在我看来,也是对内存的极大损伤之一。
文章推荐:
Flink进入大厂面试准备,收藏这一篇就够了的更多相关文章
- MySQL优化/面试,看这一篇就够了
原文链接:http://www.zhenganwen.top/articles/2018/12/25/1565048860202.html 作者:Anwen~链接:https://www.nowcod ...
- 解密国内BAT等大厂前端技术体系-携程篇(长文建议收藏)
1 引言 为了了解当前前端的发展趋势,让我们从国内各大互联网大厂开始,了解他们的最新动态和未来规划.这是解密大厂前端技术体系的第四篇,前三篇已经讲述了阿里.腾讯.百度在前端技术这几年的技术发展. 这一 ...
- 《大厂面试》京东+百度一面,不小心都拿了Offer
你知道的越多,你不知道的越多 点赞再看,养成习惯 本文 GitHub https://github.com/JavaFamily 已收录,有一线大厂面试点思维导图,也整理了很多我的文档,欢迎Star和 ...
- 深度解析互联网大厂面试难题自定义@EnableXX系列
深度解析互联网大厂面试难题自定义@EnableXX系列 其实是一个@Import的设计技巧 创建注解@EnableXX(任何名称注解都行,只是这个名字好一些) XXConfiguration类不能 ...
- 大厂面试官问你META-INF/spring.factories要怎么实现自动扫描、自动装配?
大厂面试官问你META-INF/spring.factories要怎么实现自动扫描.自动装配? 很多程序员想面试进互联网大厂,但是也有很多人不知道进入大厂需要具备哪些条件,以及面试官会问哪些问题, ...
- 大厂面试官最常问的@Configuration+@Bean(JDKConfig编程方式)
大厂面试官最常问的@Configuration+@Bean(JDKConfig编程方式) 现在大部分的Spring项目都采用了基于注解的配置,采用了@Configuration 替换标签的做法.一 ...
- 4000字干货长文!从校招和社招的角度说说如何准备Java后端大厂面试?
插个题外话,为了写好这篇文章内容,我自己前前后后花了一周的时间来总结完善,文章内容应该适用于每一个学习 Java 的朋友!我觉得这篇文章的很多东西也是我自己写给自己的,比如从大厂招聘要求中我们能看到哪 ...
- 经验总结:超详细的 Linux C/C++ 学习路线!大厂面试指南
❝ 文章每周持续更新,「三连」让更多人看到是对我最大的肯定.可以微信搜索公众号「 后端技术学堂 」第一时间阅读(一般比博客早更新一到两篇) ❞ 最近在知乎经常被邀请回答类似如何学习C++和C++后台开 ...
- 【大厂面试02期】Redis过期key是怎么样清理的?
PS:本文已收录到1.1K Star数开源学习指南--<大厂面试指北>,如果想要了解更多大厂面试相关的内容,了解更多可以看 http://notfound9.github.io/inter ...
随机推荐
- IDEA 快速上手指南(全配置)(Day_23)
Idea快速入门指南 1.安装 1.1.安装 我们使用的是2017.3.4版本: 双击打开, 选择一个目录,最好不要中文和空格: 然后选择桌面快捷方式,请选择64位: 然后选择安装: 开始安装: 然后 ...
- String、Stringbuilder、StringBuffer异同
相同点: String.Stringbuilder.StringBuffer 都可以操作字符串 String 是被final修饰的,容量定长 Stringbuilder 和 Stringbuilder ...
- Go语言安装配置
一.Go语言下载 官方下载地址:https://golang.google.cn/dl/ 选择自己需要的版本下载即可. 二.Go语言安装 下载完成之后,双击go1.16.4.windows-amd64 ...
- Splunk 8.2.0 发布 (macOS, Linux, Windows)
强烈鄙视 CSDN 用户 CIAS(账号:hanzheng260561728),盗用本站资源,删除原文链接,并且用于收费下载!!! 请访问原文链接:https://sysin.org/article/ ...
- [leetcode] 90. 子集 II.md
90. 子集 II 78. 子集题的扩展,其中的元素可能会出现重复了 我们仍沿用78题的代码,稍作改动即可: 此时需要对nums先排个序,方便我们后面跳过选取相同的子集. 跳过选取相同的子集.当选取完 ...
- Go语言的函数07---闭包练习(ATM存取款)
package main import "fmt" /* @ATM(闭包练习) ·写一个Atm(函数),返回存款,取款两个内层函数 ·存款,取款两个函数,都以一个金额为参数,返回存 ...
- CAP 超详细名词解释
目录 引言 概述 分布式 一致性 ACID中的一致性 可用性 分区容错性 可用性与分区容错性,傻傻分不清 问题1:分区容错性说分区故障正常工作,什么叫正常工作?这个正常工作是指满足可用性吗? 问题2: ...
- sql优化_隐式-显示转换
======== 测试表1信息 =======SQL> select count(*) from tb_test; COUNT(*)---------- 3000000 SQL&g ...
- 再有人问你HashMap,把这篇文章甩给他
搞定HashMap 作为一个Java从业者,面试的时候肯定会被问到过HashMap,因为对于HashMap来说,可以说是Java==集合中的精髓==了,如果你觉得自己对它掌握的还不够好,我想今天这篇文 ...
- SpringCloud Alibaba实战(7:nacos注册中心管理微服务)
源码地址:https://gitee.com/fighter3/eshop-project.git 持续更新中-- 在上一节我们已经完成了Nacos Server的本地部署,这一节我们学习如何将Nac ...