彻底解决Hive小文件问题
最近发现离线任务对一个增量Hive表的查询越来越慢,这引起了我的注意,我在cmd窗口手动执行count操作查询发现,速度确实很慢,才不到五千万的数据,居然需要300s,这显然是有问题的,我推测可能是有小文件。
我去hdfs目录查看了一下该目录:

发现确实有很多小文件,有480个小文件,我觉得我找到了问题所在,那么合并一下小文件吧:
insert into test select * from table distribute by floor (rand()*5);
这里使用distribute by进行了一个小文件的合并,通过rand() * 5,保证了从map端输出的数据,最多到5个reducer,将小文件数量控制了下来,现在只有3个文件了。
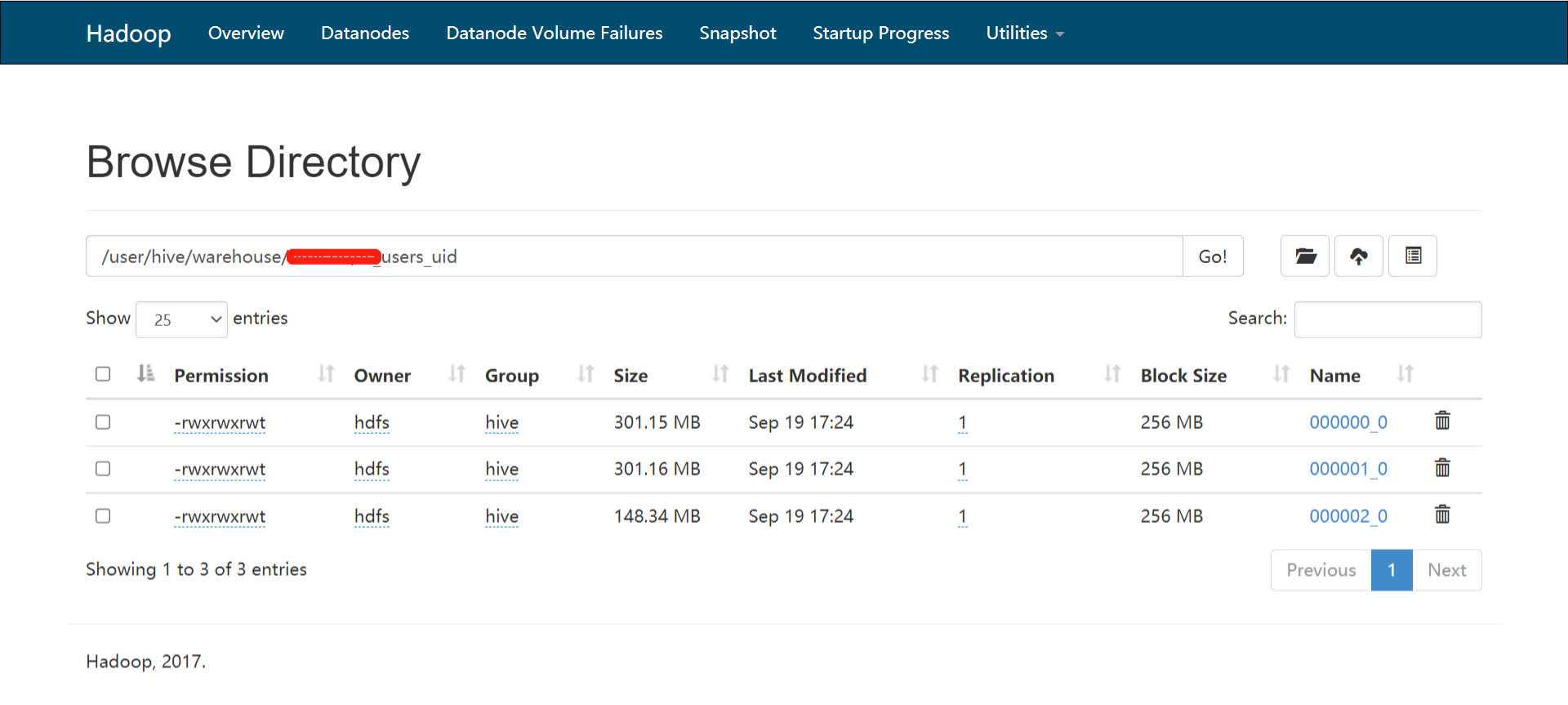
合并小文件后,再次做同样的查询,15s就完成了。确实忽略了,增量数据会导致小文件,应该在当初做的时候就做定时的小文件合并,而不是等到现在才发现。
因为这个表每天是有增量数据进去的,增量数据会单独生成一个文件,因为增量数据本身不大,日积月累就形成了大量小文件。不仅对namenode的内存造成压力,对map端的小文件合并也有很大压力。
小文件产生的原因
动态分区插入数据的时候,会产生大量的小文件;
数据源本身就包含有大量的小文件;
做增量导入,比如Sqoop数据导入,一些增量insert等;
分桶表,分桶表通常也会遇到小文件,本质上还是增量导入的问题;
可以修改的表,这种Hive表是可以进行修改的,通过配置
stored as orc TBLPROPERTIES ("transactional"="true"),这种表最坑,每天都会有一个快照,到后面10G大小的数据,表文件体积可以达到600G,时间越长越大;
小文件的问题有很多,实际中各种原因,由于自己的不小心,前期没有做好预防都会产生大量小文件,让线上的离线任务神不知鬼不觉,越跑越慢。
小文件的危害
- 给namenode内存中fsImage的合并造成压力,如果namenode内存使用完了,这个集群将不能再存储文件了;
- 虽然map阶段都设置了小文件合并,
org.apache.hadoop.hive.ql.io.CombineHiveInputFormat,太多小文件导致合并时间较长,查询缓慢;
小文件的解决方案
彻底解决小文件,分为了两个方向,一个是小文件的预防,一个是大量小文件问题已经出现了,我们该怎么解决。
1. 小文件的预防
网上有些解决方案,是调节参数,这些参数在我使用的Hive2是默认都开启了的:
//每个Map最大输入大小(这个值决定了合并后文件的数量)
set mapred.max.split.size=256000000;
//一个节点上split的至少的大小(这个值决定了多个DataNode上的文件是否需要合并)
set mapred.min.split.size.per.node=100000000;
//一个交换机下split的至少的大小(这个值决定了多个交换机上的文件是否需要合并)
set mapred.min.split.size.per.rack=100000000;
//执行Map前进行小文件合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
//设置map端输出进行合并,默认为true
set hive.merge.mapfiles = true
//设置reduce端输出进行合并,默认为false
set hive.merge.mapredfiles = true
//设置合并文件的大小
set hive.merge.size.per.task = 256*1000*1000
//当输出文件的平均大小小于该值时,启动一个独立的MapReduce任务进行文件merge。
set hive.merge.smallfiles.avgsize=16000000
有些公司用的版本不同,低版本可能有些配置不一样,最好检查一下上面这些配置是否设置,然后根据自己的实际集群情况进行设置。
小文件的预防,主要还是要根据小文件的产生原因,来进行预防。
- 动态分区插入的时候,保证有静态分区,不要误判导致产生大量分区,大量分区加起来,自然就有大量小文件;
- 如果源表是有大量小文件的,在导入数据到目标表的时候,如果只是
insert into dis select * from origin的话,目标表通常也有很多小文件。如果有分区,比如dt, hour,可以使用distribute by dt, hour,保证每个小时的数据在一个reduce里面; - 类似
sqoop增量导入,还有hive一些表的查询增量导入,这些肯定是有小文件的,需要进行一周甚至一天定时任务的小文件合并。
2. 小文件的解决
上面是平时开发数据任务时候,小文件的预防,但如果由于我们的大意,小文件问题已经产生了,就需要解决了。通常就是insert overwrite了。
insert overwrite table test [partition(hour=...)] select * from test distribute by floor (rand()*5);
注:这个语句把test表的数据查询出来,overwrite覆盖test表,不用担心如果overwrite失败,数据没了,这里面是有事物性保证的,可以观察一下执行的时候,在test表hdfs文件目录下面有个临时文件夹。如果是分区表,加上partition,表示对该分区进行overwrite。
如果是orc格式存储的表,还可以使用alter table test [partition(...)] concatenate进行小文件的合并,不过这种方法仅仅适用于orc格式存储的表。
猜你喜欢
Hadoop3数据容错技术(纠删码)
Hadoop 数据迁移用法详解
Flink实时计算topN热榜
数仓建模分层理论
一文搞懂Hive的数据存储与压缩
大数据组件重点学习这几个
彻底解决Hive小文件问题的更多相关文章
- 数仓面试高频考点--解决hive小文件过多问题
本文首发于公众号:五分钟学大数据 小文件产生原因 hive 中的小文件肯定是向 hive 表中导入数据时产生,所以先看下向 hive 中导入数据的几种方式 直接向表中插入数据 insert into ...
- hive小文件合并设置参数
Hive的后端存储是HDFS,它对大文件的处理是非常高效的,如果合理配置文件系统的块大小,NameNode可以支持很大的数据量.但是在数据仓库中,越是上层的表其汇总程度就越高,数据量也就越小.而且这些 ...
- spark sql/hive小文件问题
针对hive on mapreduce 1:我们可以通过一些配置项来使Hive在执行结束后对结果文件进行合并: 参数详细内容可参考官网:https://cwiki.apache.org/conflue ...
- Hive小文件处理
小文件是如何产生的: 动态分区插入数据的时候,会产生大量的小文件,从而导致map数量的暴增 数据源本身就包含有大量的小文件 reduce个数越多,生成的小文件也越多 小文件的危害: 从HIVE角度来看 ...
- 解决HDFS小文件带来的计算问题
hive优化 一.小文件简述 1.1. HDFS上什么是小文件? HDFS存储文件时的最小单元叫做Block,Hadoop1.x时期Block大小为64MB,Hadoop2.x时期Block大小为12 ...
- 通过创建临时表合并hive小文件
#!/bin/bash #set -x DB=$1 #获取hive表定义 ret=$(hive -e "use ${DB};show tables;"|grep -v _es|gr ...
- 通过创建临时表合并某一个库的hive小文件
#!/bin/bash #需要指定hive中的库名 #set -x set -e DB=$1 if [ -z $1 ];then echo "Usage:$0 DbName" ex ...
- 合并hive/hdfs小文件
磁盘: heads/sectors/cylinders,分别就是磁头/扇区/柱面,每个扇区512byte(现在新的硬盘每个扇区有4K) 文件系统: 文件系统不是一个扇区一个扇区的来读数据,太慢了,所以 ...
- hive 处理小文件,减少map数
1.hive.merge.mapfiles,True时会合并map输出.2.hive.merge.mapredfiles,True时会合并reduce输出.3.hive.merge.size.per. ...
随机推荐
- 特殊回文数 BASIC-9
特殊回文数 代码 import java.util.Scanner; /*123321是一个非常特殊的数,它从左边读和从右边读是一样的. 输入一个正整数n, 编程求所有这样的五位和六位十进制数, 满足 ...
- IDEA Error:java: 无效的源发行版: 11错误
IDEA Error:java: 无效的源发行版: 11错误 今天在网上下载了一个项目到本地运行报错 Error: Java : 无效的源发行版: 11 ,上网查了很多找到问题所在.项目的 JDK(P ...
- spring-security oauth2.0简单集成
github地址:https://github.com/intfish123/oauth.git 需要2个服务,一个认证授权服务,一个资源服务 认证授权服务为客户端颁发令牌,资源服务用于客户端获取用户 ...
- noip模拟44[我想我以后会碰见计数题就溜走的]
noip模拟44 solutions 这一场抱零的也忒多了,我也只有45pts 据说好像是把几套题里面最难的收拾出来让我们考得 好惨烈啊,这次的考试我只有第一题骗了40pts,其他都抱零了 T1 Em ...
- 《手把手教你》系列技巧篇(二十)-java+ selenium自动化测试-元素定位大法之终卷(详细教程)
1.简介 这篇文章主要是对前边的文章中的一些总结和拓展.本来是不打算写着一篇的,但是由于前后文章定位元素的时间有点长,怕大家忘记了,就在这里简单做一个总结和拓展. 2.Selenium八种定位方式 S ...
- NOIP 模拟 $26\; \rm 幻魔皇$
题解 \(by\;zj\varphi\) 观察可发现一个点向它的子树走能到的白点,黑点数是一个斐波那契数列. 对于白色点对,可以分成两种情况: 两个白点的 \(lca\) 是其中一个白点 两个白点的 ...
- 在JavaScript中安全访问嵌套对象
大多数情况下,当我们使用JavaScript时,我们将处理嵌套对象,并且通常我们需要安全地访问最里面的嵌套值. 比如: const user = { id: 101, email: 'jack@dev ...
- IIS 站点一键导入 导出
C:\Windows\System32\inetsrv\appcmd list site /config /xml > c:\sites.xml C:\Windows\System32\inet ...
- 关于Junit中Assert已经过时
在junit4.12之后,Assert就过时了,提供了TestCase来取代: 同样在TestCase中原本比较常见的一些方法也已经取消了,例如:assertNotEquals.assertThat. ...
- jq的常用事件及其案例
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...