Hadoop入门 集群常用知识与常用脚本总结
集群常用知识与常用脚本总结
集群启动/停止方式
1 各个模块分开启动/停止(常用)
配置ssh是前提
整体启动/停止HDFS
[ranan@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
[ranan@hadoop102 hadoop-3.1.3]$ sbin/stop-dfs.sh
整体启动/停止YARN
[ranan@hadoop102 hadoop-3.1.3]$ sbin/start-yarn.sh
[ranan@hadoop102 hadoop-3.1.3]$ sbin/stop-yarn.sh
2 各个服务组件逐一启动/停止
分别启动/停止HDFS
hdfs --daemon start datanode/namenode/secondarynamenode
hdfs --daemon stop datanode/namenode/secondarynamenode
分别启动/停止YARN
yarn --daemon start resourcemanager/nodemanager
yarn --daemon stop resourcemanager/nodemanager
编写Hadoop集群常用脚本
1 Hadoop集群启停脚本myhadoop.sh
当集群很多的时候,为了方便启停,自己编写脚本。
包含HDFS、YARN、Historyserver
先到存放全局环境变量的环境下/home/ranan/bin,编写脚本文件myhadoop.sh
注意:脚本中尽量写绝对路径
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop 集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop 集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
给脚本设置执行权限
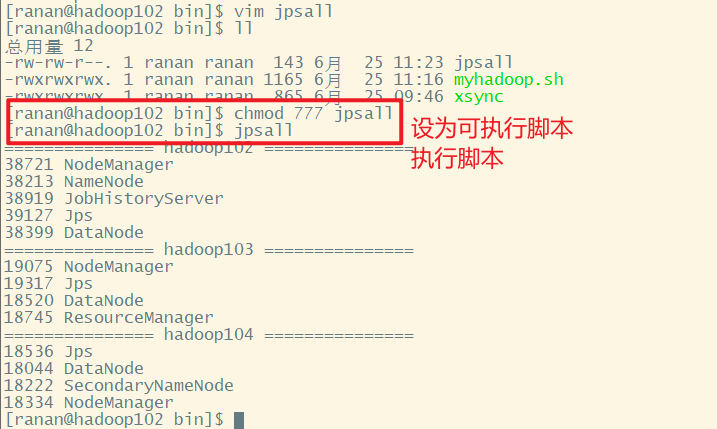
[ranan@hadoop102 bin]$ chmod 777 myhadoop.sh

2 查看三台服务器Java进程脚本 jpsall
由于每次查看进程都得到每台服务器上输入jps查看,比较麻烦,且如果服务器较多,十分耗时,于是想到编写一个脚本,查看所有服务器的进程情况。
到存放全局环境变量的环境下/home/ranan/bin,编写脚本文件jpsall
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo =============== $host ===============
ssh $host jps
done
给脚本设置执行权限
[ranan@hadoop102 bin]$ chmod 777 jpsall
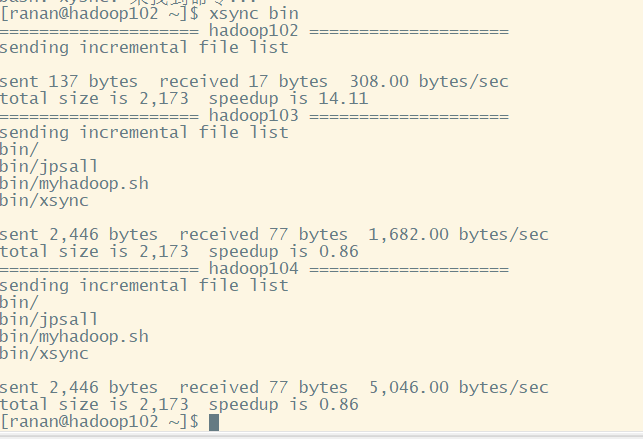
分发脚本
让三台服务器都可以使用脚本
[ranan@hadoop102 ~]$ xsync bin
常用端口说明(面试题)
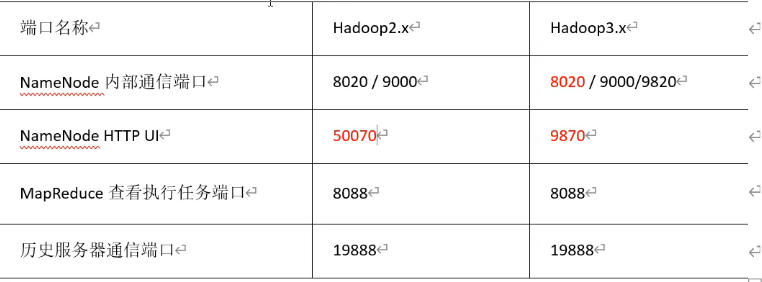
- hadoop3.x
- HDFS NameNode 内部通讯端口:8020/9000/9820
- HDFS NameNode 对用户的查询 端口:9870
- Yarn 查看任务运行情况端口:8088(没变)
- 历史服务器:19888(没变)
- hadoop2.x
- HDFS NameNode 内部通讯端口:8020/9000
- HDFS NameNode 对用户的查询 端口:50070
- Yarn 查看任务运行情况端口:8088
- 历史服务器:19888
常用的配置文件(面试题)
hadoop3.x
- core.site.xml
配置NameNode的内部通讯地址,hadoop数据存储在哪个目录下,配置HDFS网页登录使用的静态用户等。 - hdfs-site.xml
配置Namenode的Web访问地址,SecondaryNameNode的web访问地址等。 - yarn-site.xml
MR走什么协议,什么方式进行资源调度,指定ResourceManager部署在哪台节点服务器,日志的聚集等。 - mapred-site.xml
配置mapreduce运行在yarn,配置历史服务器等。 - workers
集群上有几个节点就配置几个主机名称,相当于连接。
- core.site.xml
hadoop2.x
- core.site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
- slaves
Hadoop入门 集群常用知识与常用脚本总结的更多相关文章
- Hadoop入门 集群崩溃的处理方法
目录 集群崩溃的处理方法 搞崩集群 错误示范 正确处理方法 1 回到hadoop的家目录 2 杀死进程 3 删除每个集群的data和logs 4 格式化 5 启动集群 总结 原因分析 集群崩溃的处理方 ...
- Hadoop入门 集群时间同步
集群时间同步 如果服务器在公网环境(能连接外网),可以不采用集群时间同步.因为服务器会定期和公网时间进行校准. 如果服务器在内网环境,必须要配置集群时间同步,否则时间久了,会产生时间偏差,导致集群执行 ...
- Hadoop基础-HDFS集群中大数据开发常用的命令总结
Hadoop基础-HDFS集群中大数据开发常用的命令总结 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本盘博客仅仅列出了我们在实际生成环境中常用的hdfs命令,如果想要了解更多, ...
- (Linux环境Kafka集群安装配置及常用命令
Linux环境Kafka集群安装配置及常用命令 Kafka 消息队列内部实现原理 Kafka架构 一.下载Kafka安装包 二.Kafka安装包的解压 三.设置环境变量 四.配置kafka文件 4.1 ...
- hadoop+spark集群搭建入门
忽略元数据末尾 回到原数据开始处 Hadoop+spark集群搭建 说明: 本文档主要讲述hadoop+spark的集群搭建,linux环境是centos,本文档集群搭建使用两个节点作为集群环境:一个 ...
- 使用Docker在本地搭建Hadoop分布式集群
学习Hadoop集群环境搭建是Hadoop入门必经之路.搭建分布式集群通常有两个办法: 要么找多台机器来部署(常常找不到机器) 或者在本地开多个虚拟机(开销很大,对宿主机器性能要求高,光是安装多个虚拟 ...
- 分布式计算(一)Ubuntu搭建Hadoop分布式集群
最近准备接触分布式计算,学习分布式计算的技术栈和架构知识.目前的分布式计算方式大致分为两种:离线计算和实时计算.在大数据全家桶中,离线计算的优秀工具当属Hadoop和Spark,而实时计算的杰出代表非 ...
- 超快速使用docker在本地搭建hadoop分布式集群
超快速使用docker在本地搭建hadoop分布式集群 超快速使用docker在本地搭建hadoop分布式集群 学习hadoop集群环境搭建是hadoop入门的必经之路.搭建分布式集群通常有两个办法: ...
- 一脸懵逼学习Hadoop分布式集群HA模式部署(七台机器跑集群)
1)集群规划:主机名 IP 安装的软件 运行的进程master 192.168.199.130 jdk.hadoop ...
随机推荐
- 基础篇:JAVA集合,面试专用
没啥好说的,在座的各位都是靓仔 List 数组 Vector 向量 Stack 栈 Map 映射字典 Set 集合 Queue 队列 Deque 双向队列 关注公众号,一起交流,微信搜一搜: 潜行前行 ...
- 从0到1使用Kubernetes系列(五):Kubernetes Scheduling
前述文章介绍了Kubernetes基本介绍,搭建Kubernetes集群所需要的工具,如何安装,如何搭建应用.本篇介绍怎么使用Kubernetes进行资源调度. Kubernetes作为一个容器编排调 ...
- 文件上传漏洞Bypass总结
文件上传漏洞Bypass总结 前端JS验证文件类型: 上传后缀jpg,抓包改为php后缀 ======================================================= ...
- STM32程序异常——中断处理要谨慎
问题背景 最近有一个新项目(车载项目),板子上除了原来的ARM + STM32F030K6Tx又多了一个8bit的mcu的单片机,这可真是嵌入式全家福了. 系统的主要核心工作是由arm来完成,但是在开 ...
- vim vi 高亮第80列 Python PEP8规范 行最大长度设置
命令模式下 :set cc=80 或者 打开 vim的配置 文件 .vimrc vim ~/.vimrc 接着你会看到你的配置文件 在配置文件中加上这样行配置代码 set cc=80 ok 现在退出v ...
- poj 3537 Crosses and Crosses (SG)
题意: 1 × n 个格子,每人每次选一个格子打上叉(不得重复),如果一个人画完叉后出现了连续的三个叉,则此人胜. 给n,判断先手胜还是先手败. 思路: 假设选择画叉的位置是i,则对方只能在前[1,i ...
- Zabbix 4.4 离线安装 使用mariadb的踩坑,无法停止服务
先分享一个网站,之前就没注意过有这个网站,不知道是啥时候开放的.里面分享了N多zabbix的模板. https://share.zabbix.com/ 报错如下 Unsupported charset ...
- js 基本用法和语法
js 基础用法 点击事件 <!-- 第一种点击事件方式 --> <!-- <div class="div" onclick="aler ...
- Spark记录(二):Spark程序的生命周期
本文以Spark执行模式中最常见的集群模式为例,详细的描述一下Spark程序的生命周期(YARN作为集群管理器). 1.集群节点初始化 集群刚初始化的时候,或者之前的Spark任务完成之后,此时集群中 ...
- Typecho 反序列化漏洞 分析及复现
0x00 漏洞简介 CVE-2018-18753 漏洞概述: typecho 是一款非常简洁快速博客 CMS,前台 install.php 文件存在反序列化漏洞,通过构造的反序列化字符串注入可以执行任 ...