Tutorial_6 运行结果
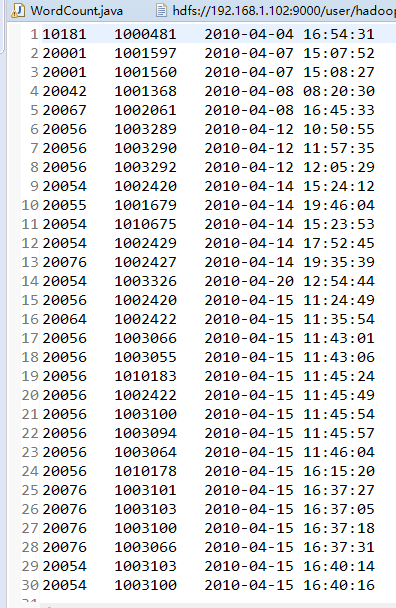
1.buyer_favorites.txt
2.代码
package mapreduce; import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer; import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class WordCount {
public WordCount() {
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
String input = "hdfs://192.168.1.102:9000/user/hadoop/input/buyer_favorite1.txt";
String output = "hdfs://192.168.1.102:9000/user/hadoop/output";
String[] otherArgs = new String[] { input, output }; /* 直接设置输入参数 */
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
} Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
} FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
} public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable(); public IntSumReducer() {
} public void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
int sum = 0; IntWritable val;
for (Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable) i$.next();
} this.result.set(sum);
context.write(key, this.result);
}
} public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text(); public TokenizerMapper() {
} public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString(), "\t"); while (itr.hasMoreTokens()) {
this.word.set(itr.nextToken().split(" ")[0]);
context.write(this.word, one);
} }
}
}
3.运行结果

4.遇到的问题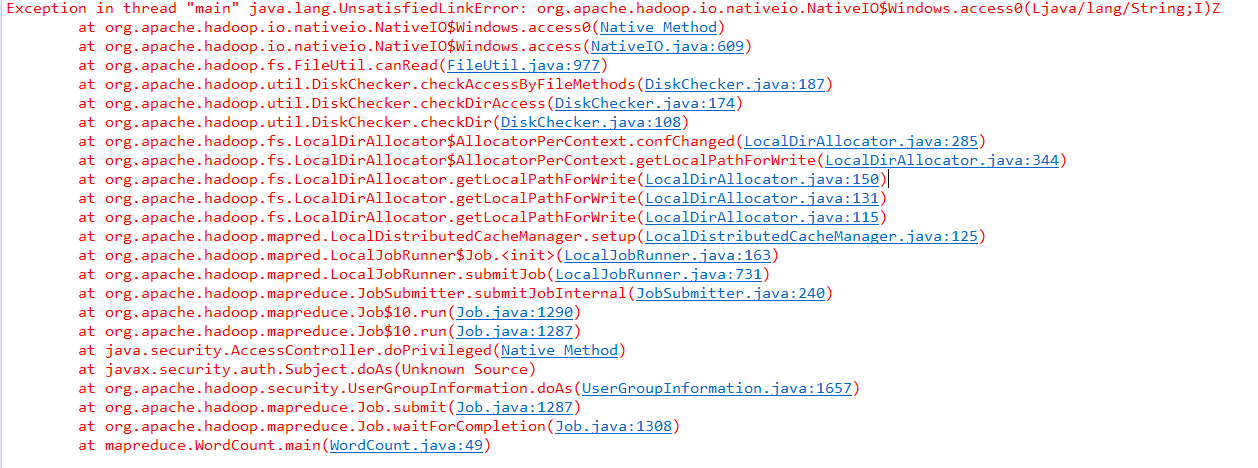
解决办法:
分析:
C:\Windows\System32下缺少hadoop.dll,把这个文件拷贝到C:\Windows\System32下面即可。
解决:
hadoop-common-2.2.0-bin-master下的bin的hadoop.dll放到C:\Windows\System32下,然后重启电脑,也许还没那么简单,还是出现这样的问题。(原博主是这么写的,实际上只是将hadoop.dll粘到了 C:\Windows\System32目录下就行了)
————————————————
声明:仅解决办法参考CSDN博客,文末附原文链接。
原文链接:https://blog.csdn.net/congcong68/article/details/42043093
Tutorial_6 运行结果的更多相关文章
- ASP.NET Aries 入门开发教程1:框架下载与运行
背景: 鉴于框架的使用者越来越多,文档太少,不少用户反映框架的入门门槛太高. 好吧,再辛苦下,抽时间写教程吧! 步骤1:下载框架源码 开源地址:https://github.com/cyq1162/A ...
- 在传统.NET Framework 上运行ASP.NET Core项目
新的项目我们想用ASP.NET Core来开发,但是苦于我们历史的遗产很多,比如<使用 JavaScriptService 在.NET Core 里实现DES加密算法>,我们要估计等到.N ...
- Sublime Text3配置在可交互环境下运行python快捷键
安装插件 在Sublime Text3下面写代码感觉很不错,但是写Python的时候遇到了一些问题. 用Sublime Text3打开python文件,或者在Sublime Text3下写好pytho ...
- hadoop 2.7.3本地环境运行官方wordcount-基于HDFS
接上篇<hadoop 2.7.3本地环境运行官方wordcount>.继续在本地模式下测试,本次使用hdfs. 2 本地模式使用fs计数wodcount 上面是直接使用的是linux的文件 ...
- hadoop 2.7.3本地环境运行官方wordcount
hadoop 2.7.3本地环境运行官方wordcount 基本环境: 系统:win7 虚机环境:virtualBox 虚机:centos 7 hadoop版本:2.7.3 本次先以独立模式(本地模式 ...
- Docker笔记一:基于Docker容器构建并运行 nginx + php + mysql ( mariadb ) 服务环境
首先为什么要自己编写Dockerfile来构建 nginx.php.mariadb这三个镜像呢?一是希望更深入了解Dockerfile的使用,也就能初步了解docker镜像是如何被构建的:二是希望将来 ...
- Linux scp 设置nohup后台运行
Linux scp 设置nohup后台运行 1.正常执行scp命令 2.输入ctrl + z 暂停任务 3.bg将其放入后台 4.disown -h 将这个作业忽略HUP信号 5.测试会话中断,任务继 ...
- 在docker中运行ASP.NET Core Web API应用程序(附AWS Windows Server 2016 widt Container实战案例)
环境准备 1.亚马逊EC2 Windows Server 2016 with Container 2.Visual Studio 2015 Enterprise(Profresianal要装Updat ...
- Android数据存储之Android 6.0运行时权限下文件存储的思考
前言: 在我们做App开发的过程中基本上都会用到文件存储,所以文件存储对于我们来说是相当熟悉了,不过自从Android 6.0发布之后,基于运行时权限机制访问外置sdcard是需要动态申请权限,所以以 ...
随机推荐
- 多尺度目标检测 Multiscale Object Detection
多尺度目标检测 Multiscale Object Detection 我们在输入图像的每个像素上生成多个锚框.这些定位框用于对输入图像的不同区域进行采样.但是,如果锚定框是以图像的每个像素为中心生成 ...
- 35 张图带你 MySQL 调优
这是 MySQL 基础系列的第四篇文章,之前的三篇文章见如下链接 138 张图带你 MySQL 入门 47 张图带你 MySQL 进阶!!! 炸裂!MySQL 82 张图带你飞 一般传统互联网公司很少 ...
- 单点突破:MySQL之日志
前言 开发环境:MySQL5.7.31 日志是 mysql 数据库的重要组成部分,记录着数据库运行期间各种状态信息.若数据库发生故障,可通过不同日志记录恢复数据库的原来数据.因此实际上日志系统直接决定 ...
- Spring Boot WebFlux-02——WebFlux Web CRUD 实践
第02课:WebFlux Web CRUD 实践 上一篇基于功能性端点去创建一个简单服务,实现了 Hello.这一篇用 Spring Boot WebFlux 的注解控制层技术创建一个 CRUD We ...
- Spring Boot 异步请求和异步调用,一文搞定
一.Spring Boot中异步请求的使用 1.异步请求与同步请求 特点: 可以先释放容器分配给请求的线程与相关资源,减轻系统负担,释放了容器所分配线程的请求,其响应将被延后,可以在耗时处理完成(例如 ...
- 学习JDK源码(一):String
用了好久的Java了,从来没有看过jdk的源码,趁着今天有点时间,拿出了jdk的源码看了下,今天先看了关于String的,毕竟开发中String类型使用最广泛.在我们下载安装jdk的时候,部分源码也已 ...
- 《手把手教你》系列基础篇之(三)-java+ selenium自动化测试- 启动三大浏览器(上)(详细教程)
1.简介 前边宏哥已经将环境搭建好了,今天就在Java项目搭建环境中简单地实践一下: 启动三大浏览器.按市场份额来说,全球前三大浏览器是:IE.Firefox.Chrome.因此宏哥这里主要介绍一下如 ...
- Windows批处理文件编写宝典
原贴:批处理新手入门导读 现在的教程五花八门,又多又杂.如何阅读,从哪里阅读,这些问题对新手来说,都比较茫然. 这篇文章的目的就是帮助新手理清学习顺序,快速入门.进步 1.如果你从来没有接触甚至没有听 ...
- 图解 Redis | 差点崩溃了,还好有主从复制
大家好,我是小林哥,又来图解 Redis 啦. 我在前两篇已经给大家图解了 AOF 和 RDB,这两个持久化技术保证了即使在服务器重启的情况下也不会丢失数据(或少量损失). 不过,由于数据都是存储在一 ...
- redis优化小建议
1.优化的一些小建议 1.尽量使用短的key 当然在精简的同时,不要为了key的"见名知意".对于value有些也可精简,比如性别使用0.1. 2.每个redis设置合理内存 每个 ...