Kubernetes自动伸缩pod-HPA
在运维中,虽然能预先知道负载何时会飙升,或者如果负载的变化是较长时间内逐渐发生的,手动扩容也是可以接受的,但指望靠人工干预来处理突发而不可预测的流量增长,仍然不够理想。
幸运的是,Kubernetes可以监控pod,并在检测到CPU使用率或其他度量增长时自动对它们扩容。如果Kubernetes运行在云端基础架构之上,它甚至能在现有节点无法承载更多pod之时自动新建更多节点。本章将会解释如何让Kubernetes进行pod与节点级别的自动伸缩。
Kubernetes的自动伸缩特性在1.6与1.7版本之间经历了一次重写,因此注意可能很多关于此方面的内容有可能已经过时了。
1.pod的横向自动伸缩
横向pod自动伸缩是指由控制器管理的pod副本数量的自动伸缩。它由Horizontal控制器执行,通过创建一个HorizontalpodAutoscaler(HPA)资源来启用和配置Horizontal控制器。该控制器周期性检查pod度量,计算满足HPA资源所配置的目标数值所需的副本数量,进而调整目标资源(如Deployment、ReplicaSet、ReplicationController、StatefulSet等)的replicas字段。
1.1 了解自动伸缩的过程
自动伸缩的过程可以分为三个步骤:
- 获取被伸缩资源对象所管理的所有pod度量。
- 计算使度量数值到达(或接近)所指定目标数值所需的pod数量。
- 更新被伸缩资源的replicas字段。
下面就来看看这三个步骤。
获取pod度量
Autoscaler本身并不负责采集pod度量数据,而是从另外的来源获取。pod与节点度量数据是由运行在每个节点的kubelet之上,名为cAdvisor的agent采集的;这些数据将由集群级的组件Heapster聚合。HPA控制器向Heapster发起REST调用来获取所有pod度量数据。图15.1展示了度量数据的流动情况(注意所有连接都是按照箭头反方向发起的)。

注意:这里Heapster在1.8+已经废弃,由metrics-server来替代,可能在更高的版本metrics-server也会废弃,但是原理大致相同。具体可参考<prometheus监控文章>(后面还是用Heapster来作为例子举例)
这样的数据流意味着在集群中必须运Heapster(等聚合插件)才能实现自动伸缩。在尝试集群伸缩前,一定要启动Heapster(或类似)附加组件。
尽管并不需要直接查询Heapster,但是也可以在kube-system命名空间中找到Heapster的pod和Service。
关于Autoscaler采集度量数据方式的改变
在Kubernetes1.6版本之前,HPA直接从Heapster采集度量。在1,8版本中,如果用--horizontal-pod-autoscaler-use-rest-clients=true参数启动ControllerManager, Autoscaler就能通过聚合版的资源度量API拉取度量了。
核心API服务器本身并不会向外界暴露度量数据。从1.7版本开始,Kubernetes允许注册多个API服务器并使它们对外呈现为单个API服务器。这允许Kubernetes通过这些底层API服务器之一来对外暴露度量数据。
集群管理员负责选择集群中使用何种度量采集器。我们通常需要一层简单的转换组件将度量数据以正确的格式暴露在正确的API路径下。
计算所需的pod数量
一旦Autoscaler获得了它所调整的资源(Deployment、ReplicaSet、ReplicationController或StatefulSet)所辖pod的全部度量,它便可以利用这些度量计算出所需的副本数量。它需要计算出一个合适的副本数量,以使所有副本上度量的平均值尽量接近配置的目标值。该计算的输入是一组pod度量(每个pod可能有多个),输出则是一个整数(pod副本数量)。
当Autoscaler配置为只考虑单个度量时,计算所需副本数很简单。只要将所有pod的度量求和后除以HPA资源上配置的目标值,再向上取整即可。实际的计算稍微复杂一些;Autoscaler还保证了度量数值不稳定、迅速抖动时不会导致系统抖动(thrash)。
基于多个pod度量的自动伸缩(例如:CPU使用率和每秒查询率[QPS])的计算也并不复杂。Autoscaler单独计算每个度量的副本数,然后取最大值(例如:如果需要4个pod达到目标CPU使用率,以及需要3个pod来达到目标QPS,那么Autoscaler将扩展到4个pod)。图15.2展示了这个示例。
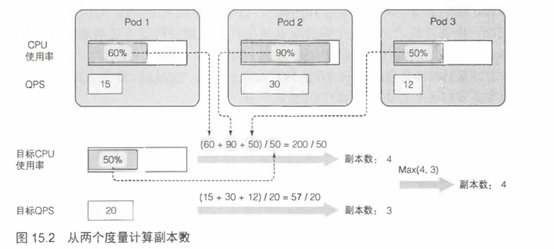
更新被伸缩资源的副本数
自动伸缩操作的最后一步是更新被伸缩资源对象(比如ReplicaSet)上的副本数字段,然后让ReplicaSet控制器负责启动更多pod或者删除多余的pod。
Autoscaler控制器通过Scale子资源来修改被伸缩资源的replicas字段。这样Autoscaler不必了解它所管理资源的细节,而只需要通过Scale子资源暴露的界面,就可以完成它的工作了(见图15.3)。

这意味着只要API服务器为某个可伸缩资源暴露了Scale子资源,Autoscaler即可操作该资源。目前暴露了Scale子资源的资源有:
- Deployment
- ReplicaSet
- ReplicationController
- StatefulSet
目前也只有这些对象可以附着Autoscaler。
了解整个自动伸缩过程
既然对自动伸缩过程的三个步骤都有所了解了,现在就用一张图表直观地感受一下自动伸缩过程中的各个组件,如图15.4所示。
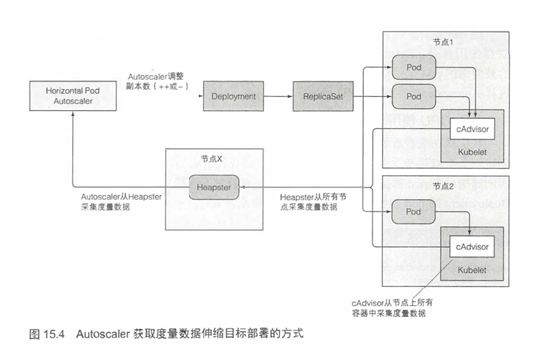
从pod指向cAdvisor,再经过Heapster,而最终到达HPA的箭头代表度量数据的流向。值得注意的是,每个组件从其他组件拉取数据的动作是周期性的(即cAdvisor用一个无限循环从pod中采集数据;Heapster与HPA控制器亦是如此)。这意味着度量数据的传播与相应动作的触发都需要相当一段时间,不是立即发生的。接下来实地观察Autoscaler行为时要注意这一点。
1.2 基于CPU使用率进行自动伸缩
可能你最想用以指导自动伸缩的度量就是pod中进程的CPU使用率了。假设用几个pod来提供服务,如果它们的CPU使用率达到了100%,显然它们己经扛不住压力了,要么进行纵向扩容(scale up),增加它们可用的CPU时间,要么进行横向扩容(scale out),增加pod数量。因为本章谈论的是HPA,所以仅仅关注横向扩容。这么一来,平均CPU使用率就应该下降了。
因为CPU使用通常是不稳定的,比较靠谱的做法是在CPU被压垮之前就横向扩容——可能平均负载达到或超过80%的时候就进行扩容。但这里有个问题,到底是谁的80%呢?
提示:一定把目标CPU使用率设置得远远低于100% (—定不要超过90%),以预留充分空间给突发的流量洪峰。
Kubernetes的资源管理文章中容器中的进程被保证能够使用该容器资源请求中所请求的CPU资源数量。但在没有其他进程需要CPU时,进程就能使用节点上所有可用的CPU资源。如果有人说“这个pod用了80%的CPU”,这时并不清楚对方的意思是80%的节点CPU,还是80%的guaranteed CPU(资源请求量),还是用资源限额给pod配置的硬上限的80%。
就Autoscaler而言,只有pod的保证CPU用量(CPU请求)才与确认pod的CPU使用有关。Autoscaler对比pod的实际CPU使用与它的请求,这意味着需要给被伸缩的pod设置CPU请求,不管是直接设置还是通过LimitRange对象间接设置,这样Autoscaler才能确定CPU使用率。(基于设置的Request来实现自动伸缩)
至于这里是基于requests和limit伸缩的,和同事之间一直都有争论,可以看下面的文档: https://github.com/kubernetes/community/blob/master/contributors/design-proposals/autoscaling/hpa-v2.md
基于CPU使用率创建HPA
现在来看看如何创建一个HPA,并让它基于CPU使用率来伸缩pod。现在创建一个类似Deployment,但正如我们讨论的,需要确保Deployment所创建的所有pod都指定了CPU资源请求,这样才有可能实现自动伸缩。需要给Deployment的pod模板添加一个CPU资源请求,如以下代码清单所示。
#代码15.1 设置了CPU请求的Deployment:deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: kubia
spec:
replicas: 3 #手动设置初始副本为3
template:
metadata:
name: kubia
labels:
app: kubia
spec:
containers:
- image: luksa/kubia:v1
name: nodejs
resources:
requests: #每个pod请求100毫核的CPU
cpu: 100m
这就是一个正常的Deployment对象--现在还没有启用自动伸缩。它会运行3个实例的kubia NodeJS应用,每个实例请求100毫核的CPU。
创建了Deployment之后,为了给它的pod启用横向自动伸缩,需要创建一个HorizontapodAutoscaler(HPA)对象,并把它指向该Deployment。可以给HPA准备YAMLmanifest,但有个办法更简单--还可以用kubectl autoscale命令:
$ kubectl autoscale deployment kubia --cpu-percent=30 --min=1 --max=5
deployment "kubia" autoscaled
这会创建HPA对象,并将叫作kubia的Deployment设置为伸缩目标。还设置了pod的目标CPU使用率为30%,指定了副本的最小和最大数量。Autoscaler会持续调整副本的数量以使CPU使用率接近30%,但它永远不会调整到少于1个或者多于5个。
提示:一定要确保自动伸缩的目标是Deployment而不是底层的ReplicaSet。这样才能确保预期的副本数量在应用更新后继续保持(记着Deployment会给每个应用版本创建一个新的ReplicaSet)。手动伸缩也是同样的道理。
看看HorizontalpodAutoscaler资源的定义,更深入地理解它,如以下代码清单所示。
#代码 15.2 —个 HorizontalpodAutoscaler 的 YAML 定义
$ kubecti get hpa.v2beta1.autoscaling kubia -o yaml
apiVersion: autoscaling/v2beta1 #HPA资源位于autoscaling这个API组中
kind: HorizontalPodAutoscaler
metadata:
name: kubia #每个HPA都有一个名称(并不一定非要像这里一样与Deployment名称一致)
...
spec:
maxReplicas: 5
metrics: #想让Autoscaler调整pod数量以使每个pod都使用所请求CPU的30%
- resource:
name: cpu
targetAverageUtilization: 30
type: Resource
minReplicas: 1
scaleTargetRef: #该AutoScaler将作用于的目标资源
apiVersion: extensions/v1beta1
kind:Deployment
name: kubia
status:
currentMetrics: [] #Autoscaler的当前状态
currentReplicas: 3
descredReplicas: 0
观察第一个自动伸缩事件
cAdvisor获取CPU度量与Heapster收集这些度量都需要一阵子,之后Autoscaler才能采取行动。在这段时间里,如果用kubectl get显示HPA资源,TARGETS列就会显示〈unknown〉:
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS
kubia Deployment/kubia <unknown>/ 30% 1 5 0
因为在运行三个空无一请求的pod,它们的CPU使用率应该接近O,应该预期Autoscaler将它们收缩到1个pod,因为即便只有一个pod, CPU使用率仍然会低于30%的目标值。
确实,Autoscaler就是这么做的。它很快就把Deployment收缩到单个副本:
$ kubectl get deployment
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
kubia 1 1 1 1 23m
记住,Autoscaler只会在Deployment上调节预期的副本数量。接下来由Deployment控制器负责更新ReplicaSet对象上的副本数量,从而使ReplicaSet控制器删除多余的两个pod而留下一个。
可以使用 kubectl describe来观察HorizontalpodAutoscaler的更多信息,以及它底层控制器的工作,如以下代码清单所示。
#代码 15.3 用kubectl describe检查一个HorizontalpodAutoscaler
$ kubectl describe hpa
Name: kubia
NameSpace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Sat,03 Jun 2017 12:59:57 +0200
Reference: Deployment/kubia
Metrics: ( current/target )
resource cpu on pods
(as a percentage of request) 0%(0)/30%
Min replicas: 1
Max replicas: 5
Events:
from Reason Message
---- ------ -------
horizontal-pod-autoscaler SuccessfulRescale New size: 1; reason: All metrics below target
可以看到因为所有度量都低于目标值,HPA已经成功收缩到单个副本了。
触发一次自动扩容
以上有一次第一个自动伸缩事件(一个收缩事件现在要往pod发送请求,增加它的CPU使用率,随后应该看到Autoscaler检测到这一切并启动更多的pod。需要通过一个Service来暴露pod,以便用单一的URL访问到所有pod。这里使用kubectl expose:
$ kubectl expose deployment kubia --port=80 --target-port=8080
service "kubia" exposed
在向pod发送请求之前,可能希望在另一个终端里运行以下命令,来观察HPA与Deployment上发生了什么,如以下代码清单所示。
#代码15.4 并行观察多个资源
$ watch -n 1 kubectl get hpa,deployment
Every 1 .0s: kubectl get hpa,deployment
NAME REFERENCE TARGETS MINPODS MAXPODS AGE
hpa/kubia Deployment/kubia 0%/30% 1 5 45m
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deploy/kubia 1 1 1 1 56m
提示:用逗号分隔资源类型可以让kubectl get—次列举多个资源类型。
如果在使用macOS系统,需要将watch命令替换为一个循环,手动定期调用kubectl get,或者使用kubectl的--watch选项。需要注意的是,尽管kubectl get—次可以显示多个资源,带上前述的--watch选项之后就不能了,因此这种情况下需要使用两个终端来同时观察HPA与Deployment对象。
在运行产生负载的pod的同时,注意观察这两个对象的状态。在另一个终端里运行以下命令:
$ kubectl run -it --rm --restart=Never loadgenerator --image=busybox -- sh -c "while true; do wget -O - -q http://kubia.default; done"
这会运行一个pod重复请求kubia服务。在运行kubectl exex命令时见过几次-it选项了。如你所见,它对kubectl run也适用。它允许你将控制台附加到被观察的进程,不仅允许你直接观察进程的输出,而且在你按下CTRL+C组合键时还会直接终止进程。--rm选项使得pod在退出之后自动被删除;--rerestar=Nexer选项则使kubectl run命令直接创建一个非托管的pod,而不是通过一个你用不着的Deployment对象间接创建。对于需要在集群中执行命令,又不想在己有的pod之上运行的情形,这组选项很实用。它们不仅与本地运行的效果相同,甚至在运行结束之后还会把现场清理干净!
观察Autoscaler扩容Deployment
随着负载生成pod的运行,可以观察到它一开始都在请求目前唯一的pod。与此前一样,度量更新需要一些时间,但等到它们更新的时候就可以看到Autoscaler增加副本数了。pod的CPU使用率一开始升高到了108%,使得Autoscaler增加pod数量到4。于是单个pod的CPU使用率降低到了74%,并最终稳定在26%左右。
可以再次用kubectl describe检查Autoscaler事件,看看它都在干嘛(以下代码清单仅仅展示了最关键的部分信息)。
#代码15.5 —个HPA的事件列表
From Reason Message
----- -------- ---------
h-p-a SuccessfulRescale New size:1;reason: All metrics below target
h-p-a SuccessfulRescale New size:4;reason: cpu resource utilization (percentage of request) above target
一开始只有一个pod时,平均CPU使用率达到了108%,超过了100%,有没有感觉奇怪?记着,容器的CPU使用率是它实际的CPU使用除以它的CPU请求。CPU请求定义了容器可用的最少而非最多CPU资源数量,因此一个容器可能使用的CPU比请求的还要多,从而使百分比超过100%。
在进入下一个话题之前,先做一些简单的计算,看看Autoscaler是如何得出需要4个副本的结论的。最开始只有1个副本处理请求,它的CPU使用率飙升到了108%。用目标CPU使用率百分比30去除108,得到了3.6;Autoscaler将它向上取整,得到了4。如果用4去除108,你会得到27% ;如果Autoscaler扩容到4个pod,它们的平均CPU使用率预期应该在27%左右,这很接近目标值30%,也跟实际观察到的CPU使用率几乎吻合。
了解伸缩操作的最大速率
在这个实验中,CPU使用率飘升到了108%,但通常来讲,初始的CPU使用率尖峰可能更高。然而即使初始平均CPU使用率确实更高(比方说150%),需要5个副本才能达到30%的目标,Autoscaler在第一步仍然只会扩容到4个pod。这是因为Autoscaler在单次扩容操作中可增加的副本数受到限制。如果当前副本数大于2,Autoscaler单次操作至多使副本数翻倍;如果副本数只有1或2, Autoscaler最多扩容到4个副本。
另外,Autoscaler两次扩容操作之间的时间间隔也有限制。目前,只有当3分钟内没有任何伸缩操作时才会触发扩容,缩容操作频率更低一一5分钟。记住这一点,这样你再看到度量数据很明显应该触发伸缩却没有触发的时候,就不会感到奇怪了。
修改一个已有HPA对象的目标度量值
作为这一节的结束,再来做最后一个练习。可能一开始设置的目标值30%有点太低了,现在把它提高到60%。将使用kubectl edit命令来完成这项工作。文本编辑器打开之后,把targetAverageUtilization字段改为60,如以下代码清单所示。
#代码15.6 通过编辑HPA资源来提高目标CPU使用率
...
spec:
maxReplicas: 5
metrics:
- resource:
name: cpu
targetAverageUtilization: 60 #将这里的30改成60
type: Resource
正如大多数其他资源一样,在修改资源之后,Autoscaler控制器会检测到这一变更,并执行相应动作。也可以先删除HPA资源再用新的值创建一个,因为删除HPA资源只会禁用目标资源的自动伸缩(本例中为一个Deployment),而它的伸缩规模会保持在删除资源的时刻。在为Deployment创建一个新的HPA资源之后,自动伸缩过程就会继续进行。
1.3 基于内存使用进行自动伸缩
上面配置了横向AutoScaler让CPU保持在设定水平,但基于pod的内存使用来自动伸缩呢?
基于内存的自动伸缩比基于CPU的困难很多。主要原因在于,扩容之后原有的pod需要有办法释放内存。这只能由应用完成,系统无法代劳。系统所能做的只有杀死并重启应用,希望它能比之前少占用一些内存;但如果应用使用了跟之前一样多的内存,Autoscaler就会扩容、扩容,再扩容,直到达到HPA资源上配置的最大pod数量。显然没有人想要这种行为。基于内存使用的自动伸缩在Kubernetes1.8中得到支持,配置方法与基于CPU的自动伸缩完全相同。这里不做演示。
1.4 基于其他自定义度量进行自动伸缩
上面有基于CPU使用率,伸缩pod很简单;最早的时候只有这一种可用的自动伸缩方案。要使Autoscaler使用应用自定义的度量来进行自动伸缩决策,这一过程十分复杂。最早的Autoscaler设计并不能轻易支持单纯基于CPU伸缩以外的场景,这驱使Kubernetes自动伸缩特别小组(SIG)完全重新设计了Autoscaler。
如果好奇最初的Autoscaler使用自定义度量究竟有多难,邀你阅读博Kubernetes autoscaling based on custom metrics without using a host port",可登录http://medium.eom/@marko.luksa在线浏览。幸运的是新版Kubernetes没有这些问题。
在此不用完整例子展开说明,而是快速过一下如何配置Autoscaler使用不同的度量源。先观察一下在前一个例子中是如何定义要使用的度量的。以下代码清单展示了之前的HPA对象是怎么被配置为使用CPU使用率度量的。
#代码15.7 配置为基于CPU自动伸缩的HorizontalpodAutoscaler
spec:
maxReplicas: 5
metrics:
- type: Resource #定义metric类型
resource:
name: cpu #使用情况会被监控的资源
targetAverageUtilization: 30 #资源的目标使用量
如你所见,metrics字段允许定义多个度量供使用。在代码清单中使用了单个度量。每个条目都指定相应度量的类型---本例中为一个Resource度量。可以在HPA对象中使用三种度量:
- 定义metric类型
- 使用情况会被监控的资源
- 资源的目标使用量
了解Resource度量类型
Resource类型使Autoscaler基于一个资源度量做出自动伸缩决策,在容器的资源请求中指定的那些度量即为一例。这一类型的使用方式己经看过了,所以重点关注另外两种类型。
了解Pods度量类型
Pods类型用来引用任何其他种类的(包括自定义的)与pod直接相关的度量。上文提过的每秒查询次数(QPS),或者消息队列中的消息数量(当消息队列服务运行在pod之中)都属于这种度量。要配置Autoscaler使用pod的QPS度量,HPA对象的metrics字段中就需要包含以下代码清单所示的条目。
#代码15.8 在HPA中引用一个自定义pod度量
...
spec:
metrics:
- type: Pods #定义一个pod的度量
resource:
metricName: qps #度量的名称
targetAverageValue: 100 #所有被涵盖的pod内的目标平均值
代码中的示例配置Autoscaler,使该HPA控制的ReplicaSet(或其他)控制器下所辖pod的平均QPS维持100的水平。
了解Object度量类型
Object度量类型被用来让Autoscaler基于并非直接与pod关联的度量来进行伸缩。比方说,你可能希望基于另一个集群对象,比如Ingress对象,来伸缩pod。这度量可能是代码清单15.8中的QPS,可能是平均请求延迟,或者完全是不相干的其他东西。
与此前的例子不同,使用Object度量类型时,Autoscaler只会从这单个对象中获取单个度量数据;在此前的例子中,Autoscaler需要从所有下属pod中获取度量,并使用它们的平均值。需要在HPA对象的定义中指定目标对象与目标值。以下代码清单即为一例。
#代码15.9 在HPA中引用其他对象的度量
spec:
metrics:
- type: Object #使用某个特定对象的度量
resource:
metricName: latencyMillis #度量的名称
target:
apiVersion: extensions/v1beta1 #autoscaler需要从中获取度量的特定对象
kind: Ingress
name: frontend
targetValue: 20 #Autoscaler应该使该度量尽量接近这个值
scaleTargetRef: #autoscaler将要管理的可伸缩资源
apiVersion: extensions/v1beta1
kind: Deployment
name: kubia
该例中HPA被配置为使用Ingress对象frontend的latencyMillis度量,目标值为20。HPA会监控该Ingress对象的度量,如果该度量超过了目标值太多,autoscaler便会对kubia Deployment资源进行扩容了。
1.5 确定哪些度量适合用于自动伸缩
需要明白,不是所有度量都适合作为自动伸缩的基础。正如之前提到的,pod中容器的内存占用并不是自动伸缩的一个好度量。如果增加副本数不能导致被观测度量平均值的线性(或者至少接近线性)下降,那么autoscaler就不能正常工作。
比方说,如果只有一个pod实例,度量数值为X,这时autoscaler扩容到了2个副本,度量数值就需要落在接近X/2的位置。每秒查询次数(QPS)就是这么一种自定义度量,对web应用而言即为应用每秒接收的请求数。增大副本数总会导致QPS成比例下降,因为同样多的请求数现在被更多数量的pod处理了。
在决定基于应用自有的自定义度量来伸缩它之前,一定要思考pod数量增加或减少时,它的值会如何变化。
1.6 缩容到0个副本
HPA目前不允许设置minReplicas字段为0,所以autoscaler永远不会缩容到0个副本,即便pod什么都没做也不会。允许pod数量缩容到0可以大幅提升硬件利用率:如果运行的服务几个小时甚至几天才会收到一次请求,就没有道理留着它们一直运行,占用本来可以给其他服务利用的资源;然而一旦客户端请求进来了,你仍然还想让这些服务马上可用。
这叫空载(idling)与解除空载(un-idling),即允许提供特定服务的pod被缩容到0副本。在新的请求到来时,请求会先被阻塞,直到pod被启动,从而请求被转发到新的pod为止。
Kubernetes目前暂时没有提供这个特性,但在未来会实现。可以检查Kubernetes文档来看看空载特性有没有被实现。
2.pod的纵向自动伸缩
横向伸缩很棒,但并不是所有应用都能被横向伸缩。对这些应用而言,唯一的选项是纵向伸缩——给它们更多CPU和(或)内存。因为一个节点所拥有的资源通常都比单个pod请求的要多,应该几乎总能纵向扩容一个Pod,对不对?
因为pod的资源请求是通过pod manifest的字段配置的,纵向伸缩pod将会通过改变这些字段来实现。这里说的是“将会”,因为目前还不可能改变己有pod的资源请求和限制。什么时候有这个功能还不确定。
2.1 自动配置资源请求
这是一个实验性的特性,如果新创建的pod的容器没有明确设置CPU与内存请求,该特性即会代为设置。这一特性由一个叫作InitialResources的准入控制(Admission Control)插件提供。当一个没有资源请求的pod被创建时,该插件会根据pod容器的历史资源使用数据(随容器镜像、tag而变)来设置资源请求。
可以不用指定资源请求就部署pod,而靠Kubernetes来最终得出每个容器的资源需求有多少。实质上,Kubesnetes是在纵向伸缩这些pod。比方说,如果一个容器总是内存不足,下次创建一个包含该容器镜像的pod的时候,它的内存资源请求就会被自动调高了。
2.2 修改运行中pod的资源请求
有朝一日,同样的机制也会用于修改己有pod的资源请求,这意味着在pod运行的同时也可以被该机制纵向伸缩。什么时候也不确定。
Kubernetes自动伸缩pod-HPA的更多相关文章
- Kubernetes 自动伸缩 auto-scaling
使用 Kubernetes 的客户能够迅速响应终端用户的请求,交付软件也比以往更快.但是,当你的服务增长速度比预期更快时,计算资源不够时,该怎么处理呢? 此时可以很自豪地说: Kubernetes 1 ...
- 基于Prometheus,Alermanager实现Kubernetes自动伸缩
到目前为止Kubernetes对基于cpu使用率的水平pod自动伸缩支持比较良好,但根据自定义metrics的HPA支持并不完善,并且使用起来也不方便. 下面介绍一个基于Prometheus和Aler ...
- Kubernetes Pod水平自动伸缩(HPA)
HPA简介 HAP,全称 Horizontal Pod Autoscaler, 可以基于 CPU 利用率自动扩缩 ReplicationController.Deployment 和 ReplicaS ...
- k8s 自动伸缩 pod(HPA)
上一篇简单说了一下使用 kubeadm 安装 k8s.今天说一下 k8s 的一个神奇的功能:HPA (Horizontal Pod Autoscaler). HPA 依赖 metrics-server ...
- 基于Kubernetes的hpa实现pod实例数量的自动伸缩
Pod 是在 Kubernetes 体系中,承载用户业务负载的一种资源.Pod 们运行的好坏,是用户们最为关心的事情.在业务流量高峰时,手动快速扩展 Pod 的实例数量,算是玩转 Kubernetes ...
- kubernetes之Pod水平自动伸缩(HPA)
https://k8smeetup.github.io/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/ Horizon ...
- kubernetes云平台管理实战:HPA水平自动伸缩(十一)
一.自动伸缩 1.启动 [root@k8s-master ~]# kubectl autoscale deployment nginx-deployment --max=8 --min=2 --cpu ...
- k8s Pod的自动水平伸缩(HPA)
我们知道,当访问量或资源需求过高时,使用:kubectl scale命令可以实现对pod的快速伸缩功能 但是我们平时工作中我们并不能提前预知访问量有多少,资源需求多少. 这就很麻烦了,总不能为了需求总 ...
- Kubernetes 弹性伸缩全场景解读(二)- HPA 的原理与演进
前言 在上一篇文章 Kubernetes 弹性伸缩全场景解析 (一):概念延伸与组件布局中,我们介绍了在 Kubernetes 在处理弹性伸缩时的设计理念以及相关组件的布局,在今天这篇文章中,会为大家 ...
随机推荐
- Qt事件与常用事件处理、过滤
转载: https://blog.csdn.net/apollon_krj/article/category/6939539 https://blog.csdn.net/qq_41072190/art ...
- x小结:certutil -hashfile D:\1.exe MD5
在Win7上,MD5不要使用小写,在Win10上没有这个问题 x小结:certutil -hashfile D:\1.exe MD5certutil -hashfile D:\1.exe SHA1ce ...
- 使用find命令查找大文件
使用find命令查找大文件 find命令是Linux系统管理员工具库中最强大的工具之一.它允许您根据不同的标准(包括文件大小)搜索文件和目录. 例如,如果在当前工作目录中要搜索大小超过100MB的文件 ...
- nginx rewite重定向详解及实例解析
静态和动态最大的区别是是否调用数据库. 什么是rewrite 将浏览器发送到服务器的请求重写,然后再返回给用户. 就是修改url,提高用户体验 rewrite的用途 80强转443 (优化用户体验) ...
- Ansible流程控制
Ansible流程控制 数据库操作问题: 数据库的操作问题,python需要依耐的模块MySQL-python . 数据库的操作 # 设置root的密码在,root的密码设置之后,创建用户和创建数据库 ...
- rpm包名详解-rpm命令使用方法
linux软件包管理-rpm mount # 挂载 1.将光盘镜像插入光驱 2.创建挂载目录 mkdir /guangqu 3.挂载到/guangqu [root@gong ~]# mount /de ...
- 1.3Linux 终端命令格式
Linux 终端命令格式 目标 了解终端命令格式 知道如何查阅终端命令帮助信息 01. 终端命令格式 bashcommand [-options] [parameter] 说明: command:命令 ...
- Python 递归函数详解
递归函数的概念: 直接或间接的调用自身的函数,称为递归函数. 每调用一次自身,相当于复制一份该函数,只不过参数有变化,参数的变化,就是重要的结束条件 下面是一个递归函数的实例: #coding=utf ...
- fdisk 磁盘分区命令
fdisk fdisk磁盘分区命令 -v 打印 fdisk 的版本信息并退出.-l 列出指定设备的分区表信息并退出. 如果没有给出设备,那么使用那些在 /proc/partitions ( ...
- golang快速入门(四)
提示:本系列文章适合有其他语音基础并对Go有持续冲动的读者 一.golang获取HTTP请求 1.在golang标准库中提供了net包来处理网络连接,通过http.Get创建http请求并返回服务器响 ...