深入理解和运用Pandas的GroupBy机制——理解篇
GroupBy是Pandas提供的强大的数据聚合处理机制,可以对大量级的多维数据进行透视,同时GroupBy还提供强大的apply函数,使得在多维数据中应用复杂函数得到复杂结果成为可能(这也是个人认为在实际业务分析中,数据量没那么大的情况下,Pandas相较于Excel透视表最有优势的一点)。
也正是因为它如此强大,所以对于很多初涉猎这部分内容的学习者来说,深入理解并熟练掌握GroupBy机制的运用有些困难,这篇文章力求基于我对“老鼠书”的理解,对GroupBy机制做一个全面的梳理。
# GroupBy使用的三种基本形式,先看看,结合后面的梳理一起有助于理解 #1
data.groupby([分组键1,分组键2……]).函数
#2
data.groupby([分组键1,分组键2……]).agg(参数)
#3
data.groupby([分组键1,分组键2……]).apply(参数)
深入理解GroupBy机制的底层逻辑:“分拆-应用-聚合”
先说结论:(1)“分拆-应用-聚合”是GroupBy机制的核心,其中“应用”又是整个流程的核心;(2)理解“应用”的关键在于,脑子里要有对于分拆之后一个个小group的抽象印象。
1、分拆
- 分拆:之所以叫GroupBy,正是因为有“Group”这个概念。我们用到Group,是因为需要按某个属性(字段)将数据区分为不同的Group,这个属性,我们通常称之为“分组键”,对每个Group进行操作(如 求和、求平均),否则直接对整个数据集进行操作就好,干嘛要麻烦到用GroupBy呢?
比如公司到年终要给表现最好的部门发激励,就需要计算不同部门今年的总收益,这时“部门”就是我们的“分组键”,不同的部门及其每个员工的收益就构成了一个个小的group。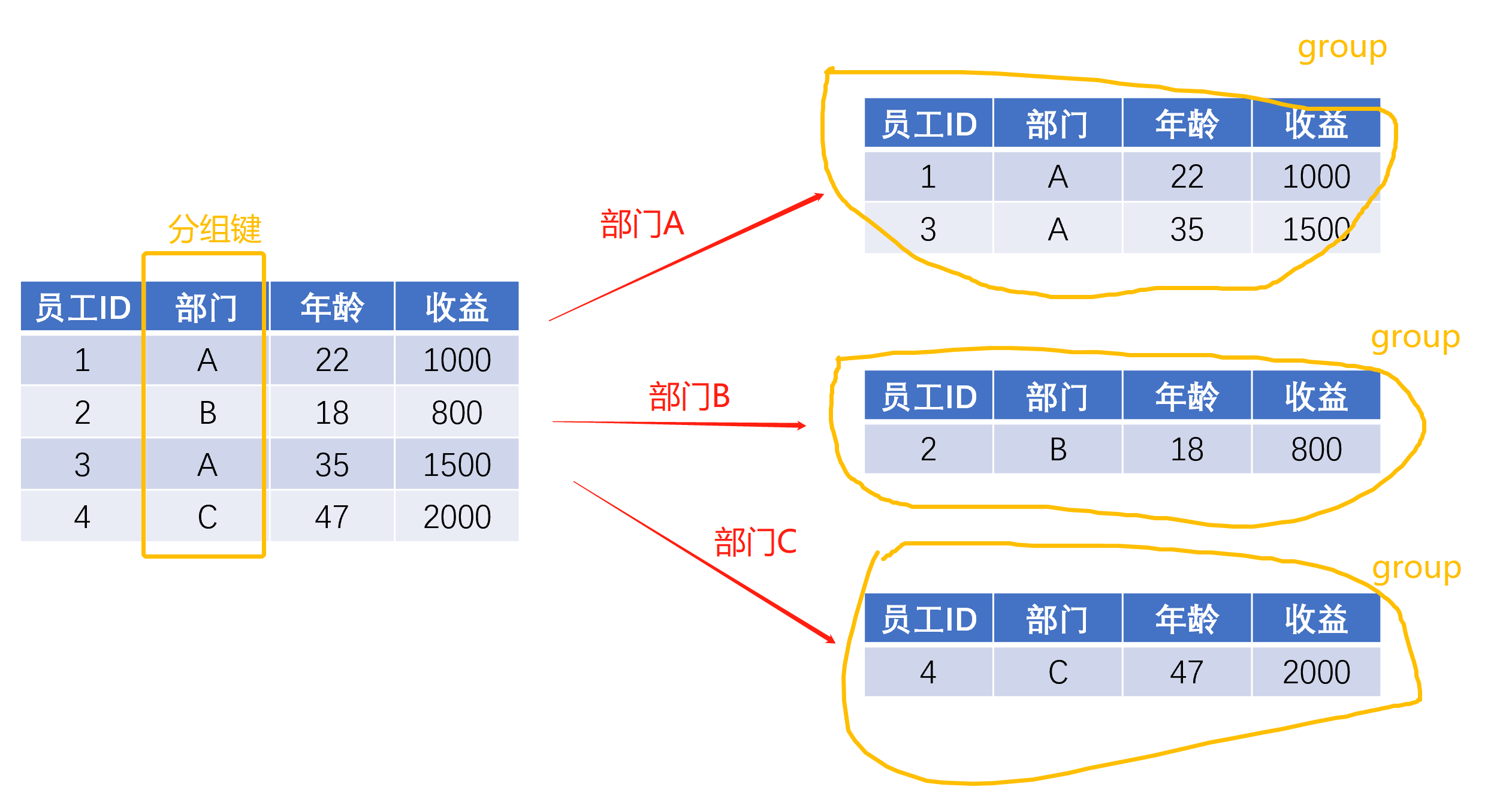
抽象理解的话,代码中的前半部分,也就是data.groupby([分组键1,分组键2……]),所起到的作用就将原数据集data按照你传入的分组键,切分为一个一个小小的group,每一个group都是原数据集的部分子集。
当看到data.groupby([分组键1,分组键2……])时,你可以理解为“分拆”的步骤已经执行好啦,现在我们已经有了一个个小group(在pandas中,data.groupby([分组键1,分组键2……])返回的是一个grouped对象,其实就是一个个小group的集合吧可以简单理解为)。
2、应用
- 应用:将数据切分为不同的Group并不是最终的目的,我们的目标是针对每个小的group执行一个操作,得到一个结果,这个过程就是"应用",也是整个GroupBy中最复杂、发挥coder聪明才智的空间最大的部分。这里的操作:
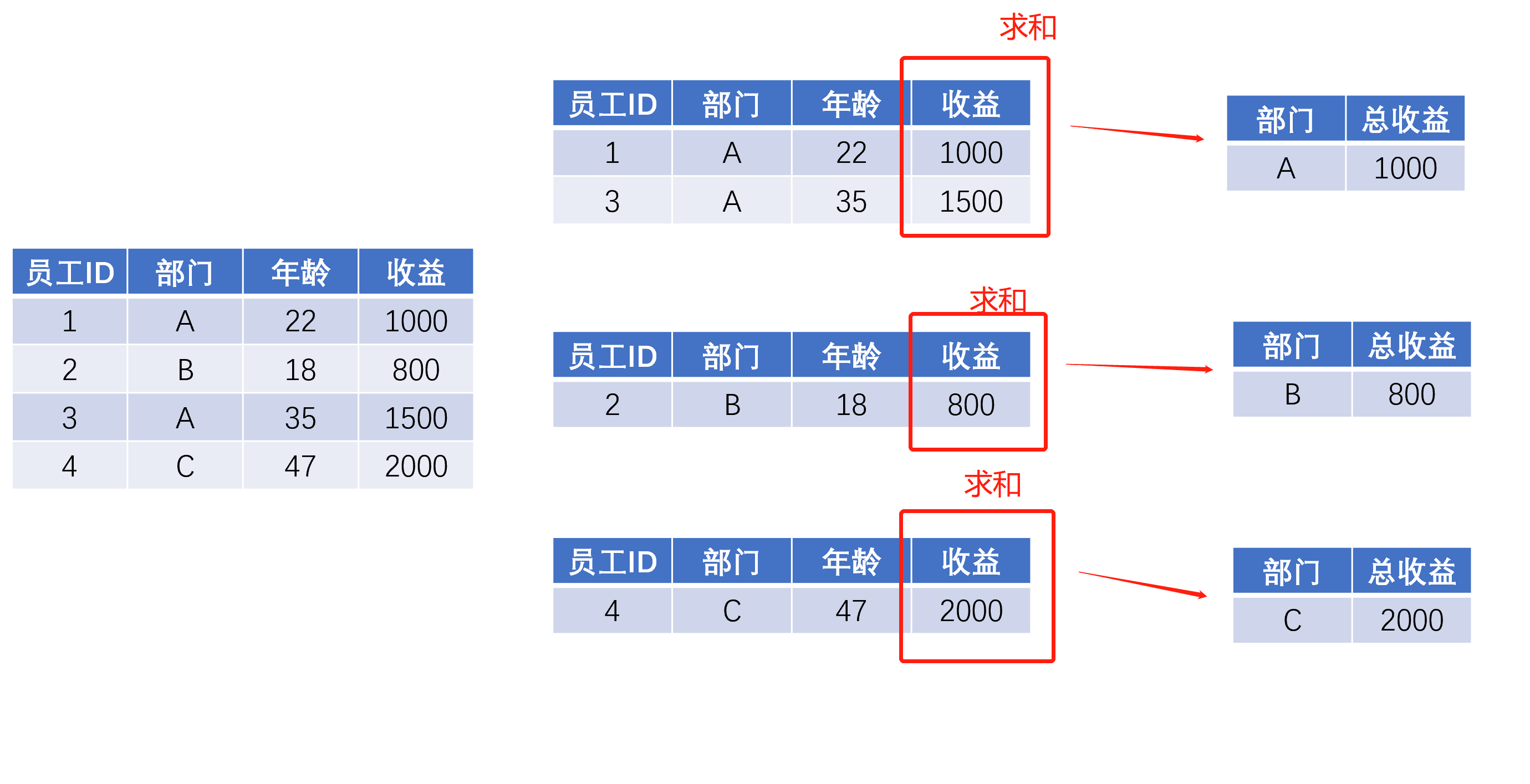
- 可以是最简单的描述性统计和汇总统计,比如 求和、求最大值、求最小值、求平均,得到的结果通常是一个标量值,也就是一个数。
- 还可以加入略复杂的要求,比如 同时返回每组最大值和最小值,得到的结果可以是一个Series / 列表 / 字典 / DataFrame / 甚至是任意你定义的对象类型了,在“运用篇”中我们会介绍一些看起来颇为复杂的操作。
继续前面公司年终发奖励的例子,老板提出了以下要求:(1)看看每个部门的总收益;(2)想看看每个部门的平均年龄和人均收益。
对于总收益,每个部门只返回一个数字就可以了,但是平均年龄和人均收益,对于每个部门来说,这两个数字构成的就是一个列表或者一个Series了。很多初学者往往就卡着这个地方,我个人认为还是对groupby的抽象理解不够。
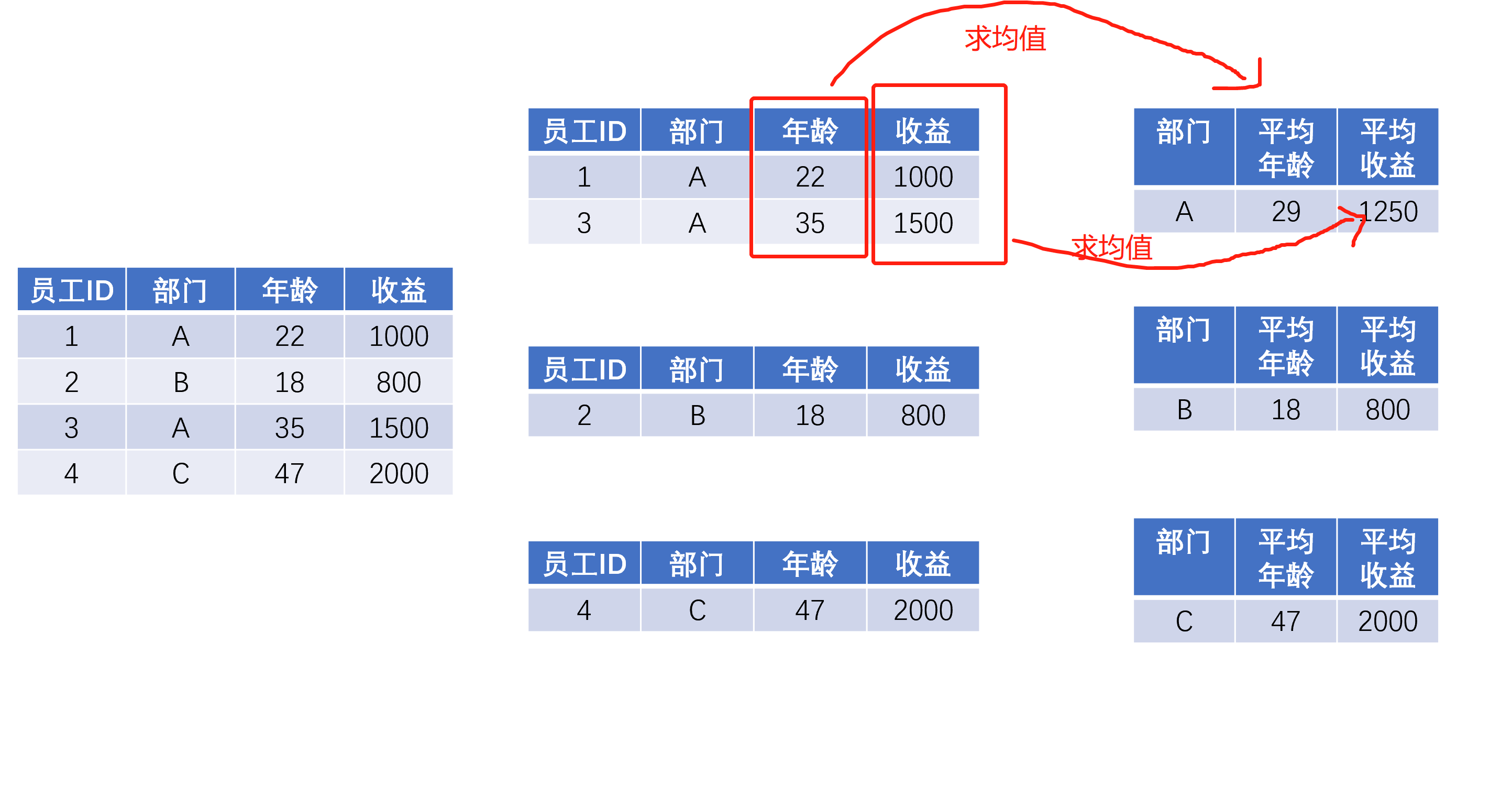
对“应用”操作的理解,如果脑子里有这么一个小group的集合,运用的难度会小很多,同时我们可以发现一些对“分拆”步骤的更深层次理解,能帮助我们更好地掌握“应用”:
- 分拆后的小group的列(columns)和原数据集是一样的;
- 分拆后的小group的分组键对应的列的值都是相等的,比如 第一个小group里面,部门都是A;第二个则部门都是B
- 分拆形成的小group的个数,取决于原数据集中分组键对应的列的值去重后的个数,比如 上图中 原数据集中有4个数据,但是只有A、B、C 3个部门,所以最终拆出来的小group就有3个。
3、聚合
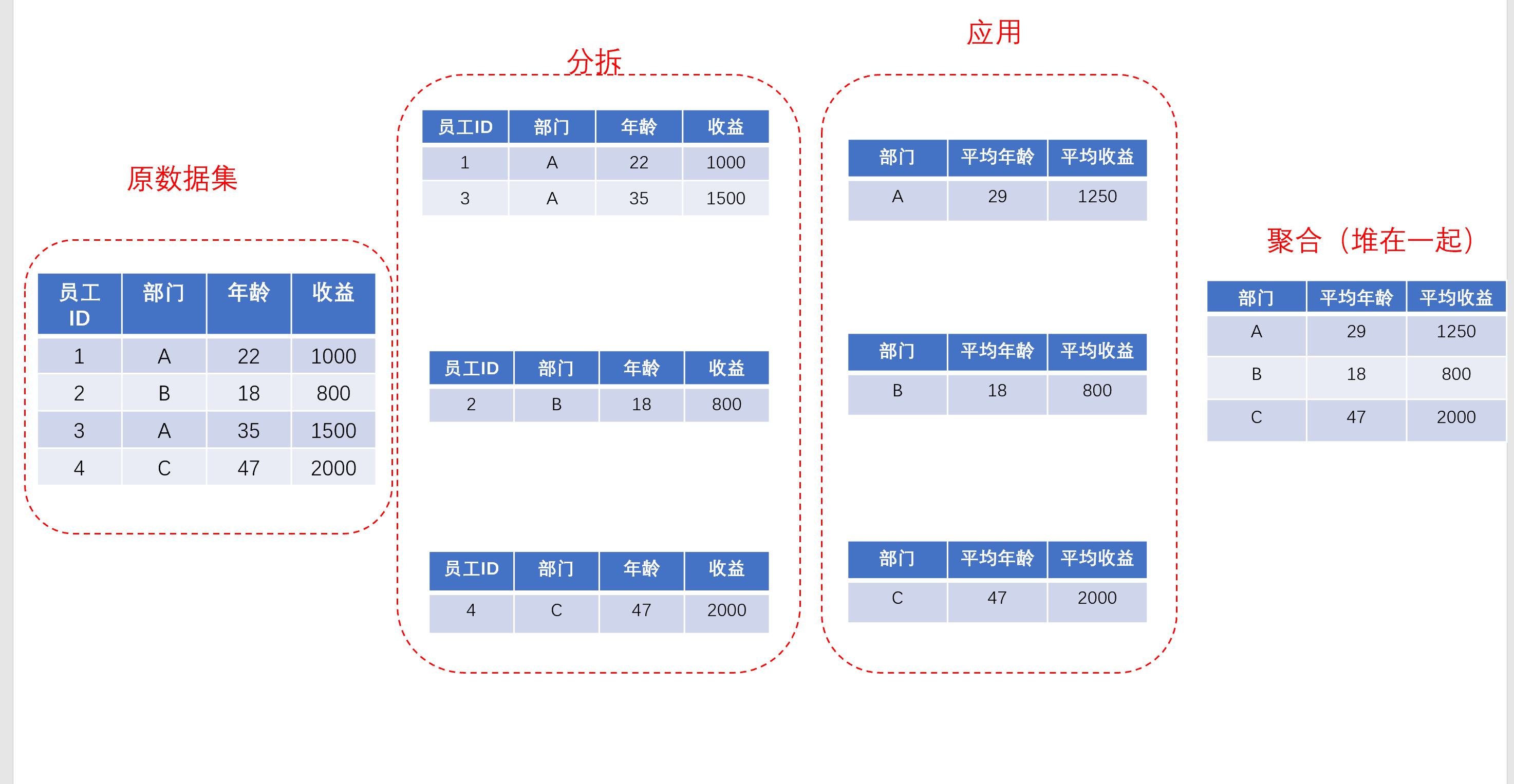
- 聚合:聚合相对来说比较好理解一些了,从前面的图中我们可以看到,“应用”是对每一个小group执行了一种或简单或复杂的操作,但是不可能就这么返回给你,所以需要把这些数据给聚合起来,构成一个可读性更高的数据形式给你。
简单来说,你可以认为,在这里,pandas对“应用”完成后的每个小group的操作结果,做了一个concat,也就是轴向上的聚合,也就是从上到下把他们像“堆俄罗斯方块”一样堆起来(如果不熟悉pd.concat,先回去复习下吧~)
在pandas中,堆叠起来的数据要么是Series,要么是DataFrame,也就是说,无论中间对每个小group的操作操作有多复杂,最后返回的结果无外乎就是Series和DataFrame,对于做数据处理的我们还是颇为友好的。
总结
总结一下,从抽象的“道”层面,在不涉及具体代码的情况下,我们去理解groupby主要是通过“分拆-应用-聚合”三个环节。
在最开始使用groupby的时候,每次能够先在脑海中将这三个环节模拟一遍,能够帮助你更快速地掌握“术”层面的代码语法;
在这三个环节中,最重要的是应用环节,而应用环节的关键在于,你要能清楚的感知到你要处理的一个个小的group是什么样子的;其次是分拆环节,分拆环节是源头,而且在实际应用的过程中还涉及到多种多样的生成分组键的方式,对于初学者来说也很容易头皮发麻;最后是聚合,像俄罗斯方块一样(准确的来说就是pd.concat)把每一个小group的结果堆起来。
理解篇就先到这里,咱们运用篇再见~~~
深入理解和运用Pandas的GroupBy机制——理解篇的更多相关文章
- pandas之groupby分组与pivot_table透视
一.groupby 类似excel的数据透视表,一般是按照行进行分组,使用方法如下. df.groupby(by=None, axis=0, level=None, as_index=True, so ...
- 通俗理解Android事件分发与消费机制
深入:Android Touch事件传递机制全面解析(从WMS到View树) 通俗理解Android事件分发与消费机制 说起Android滑动冲突,是个很常见的场景,比如SliddingMenu与Li ...
- 【图解ASP.NET MVC运行机制理解-简易版】
很多盆友咨询ASP.NET MVC的机制.网上也有好多.但是都是相当深奥.看的云里雾里的.我今天抽空,整理个简易版本.把处理流程走一遍. 当然,这个只是处理请求的一部分环节.百度的面试题“客户端从浏览 ...
- android的事件分发机制理解
android的事件分发机制理解 1.事件触发主要涉及到哪些层面的哪些函数(个人理解的顺序,可能在某一层会一次回调其它函数) activity中的dispatchTouchEvent .layout中 ...
- 《深入理解mybatis原理》 Mybatis初始化机制具体解释
对于不论什么框架而言.在使用前都要进行一系列的初始化,MyBatis也不例外. 本章将通过下面几点具体介绍MyBatis的初始化过程. 1.MyBatis的初始化做了什么 2. MyBatis基于XM ...
- ECshop中的session机制理解
ECshop中的session机制理解 在网上找了发现都是来之一人之手,也没有用自己的话去解释,这里我就抛砖引玉,发表一下自己的意见,还希望能得到各界人士的指导批评! 此session机制不需 ...
- 理解WebSocket心跳及重连机制(五)
理解WebSocket心跳及重连机制 在使用websocket的过程中,有时候会遇到网络断开的情况,但是在网络断开的时候服务器端并没有触发onclose的事件.这样会有:服务器会继续向客户端发送多余的 ...
- pandas获取groupby分组里最大值所在的行,获取第一个等操作
pandas获取groupby分组里最大值所在的行 10/May 2016 python pandas pandas获取groupby分组里最大值所在的行 如下面这个DataFrame,按照Mt分组, ...
- Java ClassLoader加载机制理解 实际例子
针对 Java ClassLoader加载机制理解, 做了个如何自定制简单的ClassLoader,并成功加载指定的类. 不废话,直接上代码. package com.chq.study.cl; im ...
随机推荐
- MySql分表、分库、分片和分区的区别
一.前言 数据库的数据量达到一定程度之后,为避免带来系统性能上的瓶颈.需要进行数据的处理,采用的手段是分区.分片.分库.分表. 二.分片(类似分库) 分片是把数据库横向扩展(Scale Out)到多个 ...
- 边缘使用 K8s 门槛太高?OpenYurt 这个功能帮你快速搭建集群!
OpenYurt作为阿里巴巴首个开源的边缘云原生项目,涉及到边缘计算和云原生两个领域.然而,许多边缘计算的开发者并不熟悉云原生相关的知识.为了降低 OpenYurt 的使用门槛,帮助更多地开发者快速上 ...
- PHP中的PDO操作学习(二)预处理语句及事务
今天这篇文章,我们来简单的学习一下 PDO 中的预处理语句以及事务的使用,它们都是在 PDO 对象下的操作,而且并不复杂,简单的应用都能很容易地实现.只不过大部分情况下,大家都在使用框架,手写的机会非 ...
- ecshop transport.js IE报错(608行),对象不支持此属性或方法 的解决办法
解决办法: 将if (this.hasOwnProperty(k)) { 改为: if (this.hasOwnProperty && this.hasOwnProperty(k)) ...
- django中csrf_token处理方式
第一:先在HTML中加入{% csrf_token %} $.ajax({ url: '{% url "ceshi:list" %}', type: 'post', dataTyp ...
- Redis-Cluster分片扩容
redis分片分片场景在业务量相对较小的时候,可以将所有数据都存到一台机器上,只使用redis单机模式,不存在分片问题.如果业务的数据量超过一台物理机器的内存大小时,则会面对扩展问题,需要多台机器去存 ...
- requests访问页面时set-cookie获取cookie
import requests headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/ ...
- 鸿蒙内核源码分析(中断概念篇) | 海公公的日常工作 | 百篇博客分析OpenHarmony源码 | v43.02
百篇博客系列篇.本篇为: v43.xx 鸿蒙内核源码分析(中断概念篇) | 海公公的日常工作 | 51.c.h .o 硬件架构相关篇为: v22.xx 鸿蒙内核源码分析(汇编基础篇) | CPU在哪里 ...
- Kronecker product
Kronecker product 的基本运算 结合律 \begin{equation} \mathrm{A} \otimes (\mathrm{B + C}) = \mathrm{A} \otime ...
- Dapr + .NET Core实战(九)本地调试
前几节开发Dapr应用程序时,我们使用 dapr cli 来启动dapr服务,就像这样: dapr run --dapr-http-port 3501 --app-port 5001 --app-id ...