dfs时间复杂度分析
前言
之前一直想不明白dfs的时间复杂度是怎么算的,前几天想了下大概想明白了,现在记录一下。
存图方式都是链式前向星或邻接矩阵。主要通过几道经典题目来阐述dfs时间复杂度的计算方法。
$n$是图中结点的个数,$e$是图中边的个数。
深度优先遍历图的每一个结点
时间复杂度为:链式前向星:$O\left( n + e \right)$;邻接矩阵:$O\left( n \right)$
给定我们一个图(链式前向星存储),通过深度优先遍历的方式把图中每个结点遍历一遍。
首先,图中每个结点最多被遍历一次,这是因为当某个结点被遍历到后,就会对其进行标记,下次再搜索到该结点时就不会再从这个结点进行搜索,所以每个结点最多调用一次dfs函数,所以这里的时间复杂度为$O\left( n \right)$。遍历图的本质是遍历每个结点的邻接结点,也就是说,当从一个结点开始,去遍历其他结点时,都要对该结点的邻接结点遍历一次。因此对于每个结点来说,遍历其邻接结点的时间复杂度为$O\left( e_{i} \right)$,这里的$e_{i}$是指第$i$个结点与其邻接结点相连的边的数量。所以,遍历整一个图的时间复杂度就是把每一个结点进行深度优先遍历的时间复杂度加起来,也就是$O\left( n + e \right)$,即所有结点和所有边的数量。
如果图是用邻接矩阵进行存储,则时间复杂度为$O\left( n^{2} \right)$,这是因为每个结点都要对其邻接结点扫描一遍,也就是遍历矩阵的一行,即$O\left( n \right)$,又因为共有$n$个结点,所以时间复杂度就为$O\left( n^{2} \right)$。
下面给了深度优先遍历的一个例图。

深度优先遍历的代码:
- 1 #include <cstdio>
- 2 #include <cstring>
- 3 #include <algorithm>
- 4 using namespace std;
- 5
- 6 const int N = 1e5 + 10;
- 7
- 8 int head[N], e[N], ne[N], idx;
- 9 bool vis[N];
- 10
- 11 void add(int v, int w) {
- 12 e[idx] = w, ne[idx] = head[v], head[v] = idx++;
- 13 }
- 14
- 15 void dfs(int src) {
- 16 vis[src] = true;
- 17 printf("%d ", src);
- 18 for (int i = head[src]; i != -1; i = ne[i]) {
- 19 if (!vis[e[i]]) dfs(e[i]);
- 20 }
- 21 }
- 22
- 23 int main() {
- 24 int n, m;
- 25 scanf("%d %d", &n, &m);
- 26 memset(head, -1, sizeof(head));
- 27
- 28 // 输入边,建图
- 29 for (int i = 0; i < m; i++) {
- 30 int v, w;
- 31 scanf("%d %d", &v, &w);
- 32 add(v, w), add(v, w);
- 33 }
- 34
- 35 // 深度优先遍历,从1号结点开始搜索
- 36 dfs(1);
- 37
- 38 return 0;
- 39 }
以上图为例,这里给出运行的结果:

数字全排列问题
时间复杂度为$O\left( {n \cdot n!} \right)$
给定一个数字$n$,求出所有$1 \sim n$的一个全排列。
例如求$3$的一个全排列,这里画了个图方面理解(画线的部分是徒手画的,凑合着看吧...)。
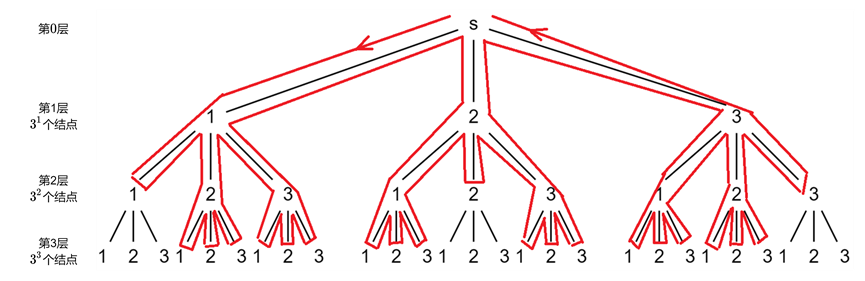
从$s$出发,第$1$层可以选择$3$个不同的结点,每个结点对应着一个分支。我们先看$s$最左边的那个分支,也就是对应数字$1$的那个分支。第$1$层选择“$1$”这个结点,接着遍历了$3$个邻接结点,对应$3$条边。其中由于$1$已经遍历过了,所有接下来只会从“$2$”和“$3$”开始遍历,而这两个结点都要把其邻接结点都遍历一遍来确定排列的最后一个数字选择哪个。第$1$层的结点“$2$”和“$3$”这两个分支的分析同上。
可以发现,每一个结点的邻接结点个数都是$3$,所以循环要执行$3$次来扫描完这$3$个邻接结点。且随着树的深度增加,每层可以选择的结点个数也会随着减小,即深度每增加$1$,该层可选择的结点个数就减$1$(因为上一层已经确定了一个数,每遍历一层都会少一个数的选择)。
所以我们来推导更一般的规律,假设求$n$的一个全排列。对应的搜索树大概是这个样子:

第$1$层可选择的结点有$n$个。然后对于第$2$层,由于上一层(第$1$层)有$n$个可选择的结点,而每个结点虽然有$n$个邻接结点,但因为在上一层已经确定了一个数,所以实际上下一层(第$2$层)能够选择的结点只有$n - 1$个。又因为上一层有$n$个结点,所以第$2$层可选择的结点个数为$n \cdot \left( n - 1 \right)$(主要是想强调虽然每个邻接结点会被遍历到,但并不是所有的邻接结点都被可以选择去进行下一层的dfs)。同理,在第$3$层中,上一层有$n \cdot \left( n - 1 \right)$个可选择的结点,每个结点实际可选择的邻接结点只有$n - 2$个,故第$3$层可选择的结点个数为$n \cdot \left( n - 1 \right) \cdot \left( n - 2 \right)$。以此类推,到第$n - 1$层,可选择的结点个数为$n \cdot \left( {n - 1} \right) \cdot \left( {n - 2} \right) \cdot ~\cdots~ \cdot 2 = n!$。最后一层不考虑,因为叶子结点没有邻接结点,不会进行遍历邻接结点这个操作。
所以时间复杂度就是所有可选择结点遍历其邻接结点的次数。设第$i$层的可选择结点的结点个数为$s_{i}$,每个结点都有$n$个邻接结点,因此所有可选择结点遍历其邻接结点的次数为$$O\left( {n \cdot {\sum\limits_{i = 0}^{n - 1}s_{i}} = n \cdot \left( {1 + n + n \cdot \left( {n - 1} \right) + \cdots + n!} \right)} \right) = O\left( {n \cdot n!} \right)$$
全排列问题的代码:
- 1 #include <cstdio>
- 2 #include <algorithm>
- 3 using namespace std;
- 4
- 5 const int N = 20;
- 6
- 7 int a[N];
- 8 bool vis[N];
- 9
- 10 void dfs(int u, int n) {
- 11 if (u == n) {
- 12 for (int i = 1; i <= n; i++) {
- 13 printf("%d ", a[i]);
- 14 }
- 15 printf("\n");
- 16
- 17 return;
- 18 }
- 19
- 20 for (int i = 1; i <= n; i++) {
- 21 if (!vis[i]) {
- 22 vis[i] = true;
- 23 a[u + 1] = i;
- 24 dfs(u + 1, n);
- 25 vis[i] = false;
- 26 }
- 27 }
- 28 }
- 29
- 30 int main() {
- 31 int n;
- 32 scanf("%d", &n);
- 33
- 34 // 从第0层开始搜索
- 35 dfs(0, n);
- 36
- 37 return 0;
- 38 }
比如求$4$的一个全排列,运行结果如下:

由于时间复杂度太高,因此为了能在$1s$内算出结果,一般$n$的取值不会超过$8$。
n-皇后问题
$n$皇后问题是指将$n$个皇后放在$ n \times n $的国际象棋棋盘上,使得皇后不能相互攻击到,即任意两个皇后都不能处于同一行、同一列或同一斜线上。现在给定整数$n$,求出所有的满足条件的棋子摆法。

方法一
时间复杂度为$O\left( 2^{n^{2}} \right)$
最纯粹的dfs,即考虑每一个格子放棋子还是不放棋子。
先贴出搜索树大概的样子:
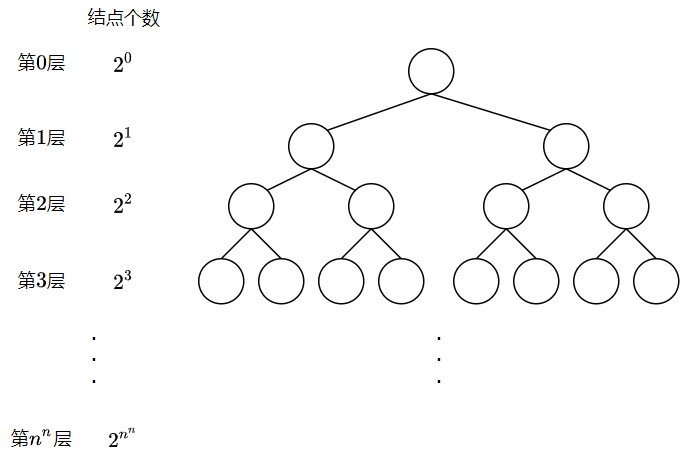
因为有$n^{n}$个格子,所有搜索树有$n^{n}$层(不算第$0$层),每个格子对应着搜索树中的那一层。当搜索完第$n^{n}$层,这意味着我们为每一个格子选择了放棋子或不放棋子,即确定一种方案(该方案不一定满足解的要求)。每层的结点对应着这个位置的格子,比如第$1$层的结点对应第$1$个格子,第$n$层的结点对应第$n$个格子,以此类推。又因为每个格子有放棋子或不放棋子这两种选择,对应着每个结点有两个邻接结点。
我们现在计算遍历每个节点的邻接结点的次数(先不考虑剪枝,也就是最糟糕的情况)。因为最后一层,即第$n^{n}$层的节点为叶子节点,没有邻接结点,所以只用考虑第$0 \sim n^{n} - 1$层的结点。然后,由于每个结点都有两个邻接结点,设第$i$层有$s_{i}$个结点,所以第$i$层的结点一共会遍历$2 \cdot s_{i}$次邻接结点。因此,所有结点的对邻接结点进行遍历次数为$$O\left( {2 \cdot {\sum\limits_{i = 0}^{n^{n} - 1}s_{i}} = 2 \cdot {\sum\limits_{i = 0}^{n^{n} - 1}2^{i}} = 2 \cdot \frac{1 - 2^{n^{n}}}{1 - 2} = 2 \cdot 2^{n^{2}} - 2} \right) = O\left( 2^{n^{2}} \right)$$
当然,实际上我们会通过剪枝的操作,把已经明确不会存在解的情况过滤掉,不会再从这个地方继续搜索下去。上面分析的是最糟糕的情况下的时间复杂度,所以实际上运行的效率会优于上面分析的时间复杂度。
$n$皇后问题的方法一的代码如下:
- 1 #include <cstdio>
- 2 #include <algorithm>
- 3 using namespace std;
- 4
- 5 const int N = 20;
- 6
- 7 char graph[N][N];
- 8 bool row[N], col[N], dg[N], udg[N];
- 9
- 10 void dfs(int x, int y, int cnt, int n) {
- 11 if (cnt == n) {
- 12 for (int i = 0; i < n; i++) {
- 13 printf("%s\n", graph[i]);
- 14 }
- 15 printf("\n");
- 16
- 17 return;
- 18 }
- 19
- 20 if (y == n) {
- 21 y = 0, x++;
- 22 if (x == n) return;
- 23 }
- 24
- 25 dfs(x, y + 1, cnt, n);
- 26
- 27 if (!row[x] && !col[y] && !dg[y - x + n] && !udg[y + x]) {
- 28 row[x] = col[y] = dg[y - x + n] = udg[y + x] = true;
- 29 graph[x][y] = 'Q';
- 30 dfs(x, y + 1, cnt + 1, n);
- 31 row[x] = col[y] = dg[y - x + n] = udg[y + x] = false;
- 32 graph[x][y] = '.';
- 33 }
- 34 }
- 35
- 36 int main() {
- 37 int n;
- 38 scanf("%d", &n);
- 39
- 40 for (int i = 0; i < n; i++) {
- 41 for (int j = 0; j < n; j++) {
- 42 graph[i][j] = '.';
- 43 }
- 44 }
- 45
- 46 // 从(0, 0)这个位置的格子开始搜索
- 47 dfs(0, 0, 0, n);
- 48
- 49 return 0;
- 50 }
下面给出$4$个皇后的解:

由于时间复杂度太高,因此为了能在$1s$内算出结果,一般$n$的取值不会超过$9$。
方法二
时间复杂度为$O\left( {n \cdot n!} \right)$
这时我们要对上面方法进行进一步的优化。我们可以发现,根据题意,每一行都只会有一个皇后,所以我们可以枚举每一行。且每一列都只有一个皇后,因此在每一行选择了一个皇后后,记录该皇后所在的列号,在剩下的行中,每一行的皇后都不可以放置在前面已标记的列号上。也就是说,每枚举一行选择其中一列放置皇后后,下一行可放置皇后的列数都会减$1$,即放置的位置会减$1$。
是不是与前面全排列分析的很像,我们给出大致的搜索树:

没错,与上面的全排列的搜索树j几乎是一样的。
第$i$就代表棋盘的第$i$行,在以每个结点为根的子树中,根节点的$n$个邻接结点就代表$n$个列号。按照上面的分析,每次往下走一层,那么可选择的邻接结点都会减少一个。
这与全排列的分析是一样的,所以时间复杂度就是$O\left( {n \cdot n!} \right)$。
$n$皇后问题的方法二的代码如下:
- 1 #include <cstdio>
- 2 #include <algorithm>
- 3 using namespace std;
- 4
- 5 const int N = 20;
- 6
- 7 char graph[N][N];
- 8 bool row[N], col[N], dg[N], udg[N];
- 9
- 10 void dfs(int x, int n) {
- 11 if (x == n) {
- 12 for (int i = 0; i < n; i++) {
- 13 printf("%s\n", graph[i]);
- 14 }
- 15 printf("\n");
- 16
- 17 return;
- 18 }
- 19
- 20 for (int i = 0; i < n; i++) {
- 21 if (!col[i] && !dg[i - x + n] && !udg[i + x]) {
- 22 col[i] = dg[i - x + n] = udg[i + x] = true;
- 23 graph[x][i] = 'Q';
- 24 dfs(x + 1, n);
- 25 col[i] = dg[i - x + n] = udg[i + x] = false;
- 26 graph[x][i] = '.';
- 27 }
- 28 }
- 29 }
- 30
- 31 int main() {
- 32 int n;
- 33 scanf("%d", &n);
- 34
- 35 for (int i = 0; i < n; i++) {
- 36 for (int j = 0; j < n; j++) {
- 37 graph[i][j] = '.';
- 38 }
- 39 }
- 40
- 41 // 从第0行开始搜索
- 42 dfs(0, n);
- 43
- 44 return 0;
- 45 }
与方法一相比$n$取值会有所增加,为了能在$1s$内算出结果,$n$可以取到$13$。
记忆化搜索
时间复杂度为$O \left( n \right)$
这里给出一道例题来分析。
在集合-Nim游戏中,我们要对每个出现过的数求其sg值,而在搜索的过程中某个数字可能会出现多次,又因为在同一个游戏中每个数字的sg值都是一样的,所以如果对搜索过程中每一个数字都直接进行dfs来求其sg值,那么这就会就会重复搜索,浪费时间。因此我们可以开个数组来记录每次求得的某个数字的sg值。如果在搜索的过程中发现某个数字的sg是已经求得的,那么就可以直接从数组中得到结果,而不需要再从这个数字进行dfs。
这样一来,每个数字的sg值都只会被搜索一次,如果这个游戏中出现$n$个不同的数字,那么时间复杂度就是$O \left( n \right)$。
其实和这图的深度优先遍历很像,就是不让同一个数字(结点)进行重复遍历,保证最多被遍历一次。
以题目的测试样例,我们画出这个求sg值的图:

题目的AC代码如下:
- 1 #include <cstdio>
- 2 #include <cstring>
- 3 #include <unordered_set>
- 4 #include <algorithm>
- 5 using namespace std;
- 6
- 7 const int N = 110, M = 1e4 + 10;
- 8
- 9 int n, m;
- 10 int s[N], sg[M];
- 11
- 12 int getSG(int val) {
- 13 if (sg[val] != -1) return sg[val];
- 14
- 15 unordered_set<int> st;
- 16 for (int i = 0; i < n; i++) {
- 17 if (val - s[i] >= 0) st.insert(getSG(val - s[i]));
- 18 }
- 19
- 20 for (int i = 0; ; i++) {
- 21 if (st.count(i) == 0) return sg[val] = i;
- 22 }
- 23 }
- 24
- 25 int main() {
- 26 memset(sg, -1, sizeof(sg));
- 27
- 28 scanf("%d", &n);
- 29 for (int i = 0; i < n; i++) {
- 30 scanf("%d", s + i);
- 31 }
- 32 scanf("%d", &m);
- 33
- 34 int ret = 0;
- 35 while (m--) {
- 36 int val;
- 37 scanf("%d", &val);
- 38 ret ^= getSG(val);
- 39 }
- 40
- 41 printf("%s", ret ? "Yes" : "No");
- 42
- 43 return 0;
- 44 }
参考资料
Acwing:https://www.acwing.com/
最后,今天是2022-02-01,祝大家春节快乐!
dfs时间复杂度分析的更多相关文章
- BZOJ 3277 串 & BZOJ 3473 字符串 (广义后缀自动机、时间复杂度分析、启发式合并、线段树合并、主席树)
标签那么长是因为做法太多了... 题目链接: (bzoj 3277) https://www.lydsy.com/JudgeOnline/problem.php?id=3277 (bzoj 3473) ...
- C语言数组实现约瑟夫环问题,以及对其进行时间复杂度分析
尝试表达 本人试着去表达约瑟夫环问题:一群人围成一个圈,作这样的一个游戏,选定一个人作起点以及数数的方向,这个人先数1,到下一个人数2,直到数到游戏规则约定那个数的人,比如是3,数到3的那个人就离开这 ...
- 回溯和DFS效率分析
回溯和DFS效率分析 一.心得 多组数据记得初始化 两组样例,找圆点点的个数 6 9 ....#. .....# ...... ...... ...... ...... ...... #@...# . ...
- 斐波那契数列的三种C++实现及时间复杂度分析
本文介绍了斐波那契数列的三种C++实现并详细地分析了时间复杂度. 斐波那契数列定义:F(1)=1, F(2)=1, F(n)=F(n-1) + F(n-2) (n>2) 如何计算斐波那契数 F( ...
- STL堆排序&时间复杂度分析
1. 逻辑&时间复杂度分析 pop 和 initialize 的时间复杂度请参考: [DSAAinC++] 大根堆的pop&remove&initialize 将数组初始化为一 ...
- maxHBLT的合并&初始化&时间复杂度分析
1. 定义 [extened binary tree] 扩充二叉树是有 external node (用来代替空子树, 也就是 nullptr) 的 binary tree. 对应地, 其他 node ...
- <数据结构基础学习>(二)简单的时间复杂度分析
一.简单的复杂度分析 O(1) O(n) O(logn) O(logn) O(n^2) 大O描述的是算法的运行事件和输入数据之间的关系 Eg: 数组求和 public static int sum(i ...
- 轮廓问题/Outline Problem-->改进的算法及时间复杂度分析
前面写过一篇关于轮廓算法的文章,是把合并建筑和合并轮廓是分开对待的,并且为了使轮廓合并的时候算法简单,对x坐标使用了double类型,然后对整形的x坐标数据进行合并.这样做是为了使得需找拐点的算法容易 ...
- BZOJ 2734 [HNOI2012]集合选数 (状压DP、时间复杂度分析)
题目链接 https://www.lydsy.com/JudgeOnline/problem.php?id=2734 题解 嗯早就想写的题,昨天因为某些不可告人的原因(大雾)把这题写了,今天再来写题解 ...
随机推荐
- 【LeetCode】792. Number of Matching Subsequences 解题报告(Python)
[LeetCode]792. Number of Matching Subsequences 解题报告(Python) 作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://f ...
- Brute-force Algorithm(hdu3221)
Brute-force Algorithm Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Ot ...
- 1048 - Conquering Keokradong
1048 - Conquering Keokradong PDF (English) Statistics Forum Time Limit: 1 second(s) Memory Limit: ...
- isEmpty 和 isBlank 的区别
一般使用Apache commons-lang3 工具包: commons-lang3 是专业的工具包,功能非常齐全.强大. 1.isEmpty 判断字符串是否为空字符串,只要有一个任意字符(包括空白 ...
- uniapp滑动操作
<view @touchmove="handletouchmove" @touchstart="handletouchstart" @touchend=& ...
- CS学习资料百度云链接
CS学习资料百度云链接 [0]Springboot微服务开发天气预报系统视频教程https://pan.baidu.com/s/1joz7flyztCq8oklBlsz8dQ提取密码:cpz7 [1] ...
- 编写Java程序,实现一个简单的echo程序(网络编程TCP实践练习)
首先启动服务端,客户端通过TCP的三次握手与服务端建立连接: 然后,客户端发送一段字符串,服务端收到字符串后,原封不动的发回给客户端. ECHO 程序是网络编程通信交互的一个经典案例,称为回应程序,即 ...
- 编写Java程序,在维护英雄数据的业务过程中复用数据库操作封装类
返回本章节 返回作业目录 需求说明: 继续完善英雄信息系统,将HeroAccess类中数据库连接相关代码独立出来,并将其封闭成数据库操作工具类DbConnection,便于管理和代码复用. 在Hero ...
- Unity——卡通渲染实现
效果展示: 原模型: 一.简单分析 卡通渲染又叫非真实渲染(None-Physical Rendering-NPR),一般日漫里的卡通风格有几个特点: 1.人物有描边 2.有明显的阴影分界线,没有太平 ...
- 《手把手教你》系列技巧篇(五十三)-java+ selenium自动化测试-上传文件-上篇(详细教程)
1.简介 在实际工作中,我们进行web自动化的时候,文件上传是很常见的操作,例如上传用户头像,上传身份证信息等.所以宏哥打算按上传文件的分类对其进行一下讲解和分享. 2.为什么selenium没有提供 ...