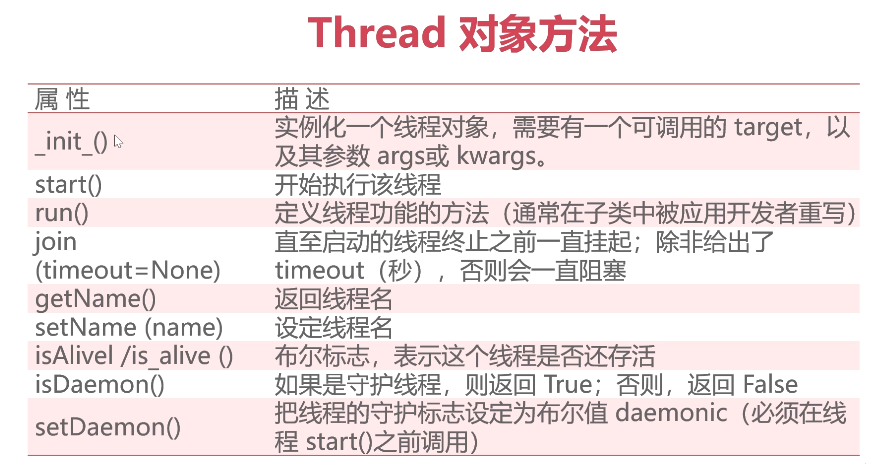
python16线程




python对于I/O密集型应用比较好,具体根据是什么类型应用来查看
对于cpu密集型应用可以借助python的一些扩展去实现


thread模块是比较早期的模块,thresding是比较新的模块,对thread模块进行了新的封装,



import threading def loop():
"""新线程执行的代码"""
loop_now_thread = threading.current_thread()
print("loop现在的线程是{}".format(loop_now_thread))
n = 0
while n <5:
print(n)
n += 1 def use_thread():
"""使用线程来实现"""
#当前正在执行的线程名称
now_thread = threading.current_thread()
print("现在的线程是{}".format(now_thread))
#设置线程
t = threading.Thread(target=loop,name="loop_thread")
t.start()
#挂起线程
t.join() if __name__ == "__main__":
use_thread() 结果:
现在的线程是<_MainThread(MainThread, started 15572)>
loop现在的线程是<Thread(loop_thread, started 3980)>
0
1
2
3
4
用类来实现:
import threading
import time class LoopThrea(threading.Thread):
n = 0
def run(self, n=None):
while self.n < 5:
print(self.n)
now_thread = threading.current_thread()
print("现在的线程是{}".format(now_thread))
time.sleep(1)
self.n += 1 if __name__ == "__main__":
t = LoopThrea(name = "quanzhiqiang_loop")
t.start()
t.join() 结果;
0
现在的线程是<LoopThrea(quanzhiqiang_loop, started 16708)>
1
现在的线程是<LoopThrea(quanzhiqiang_loop, started 16708)>
2
现在的线程是<LoopThrea(quanzhiqiang_loop, started 16708)>
3
现在的线程是<LoopThrea(quanzhiqiang_loop, started 16708)>
4
现在的线程是<LoopThrea(quanzhiqiang_loop, started 16708)>
import threading
import time balance = 0
def change_it(n):
global balance
balance = balance +n
time.sleep(2)
balance = balance -n
print("##################{0}#".format(balance))
time.sleep(1) class ChageBlance(threading.Thread): def __init__(self, num, *args, **kwargs):
super().__init__(*args, **kwargs)
self.num = num def run(self):
for i in range(100000):
change_it(self.num) if __name__ == "__main__":
t1 = ChageBlance(5)
t2 = ChageBlance(8)
t1.start()
t2.start()
t1.join()
t2.join()
print("aaaa{0}".format(balance))
结果:有时候不为零 ##################5###################0# ##################8#
##################0#
##################5###################0# ##################5###################0#

import threading
import time my_lock = threading.Lock()
your_lock = threading.Lock()
balance = 0
def change_it(n):
global balance
try:
# 添加锁
my_lock.acquire()
#my_lock.acquire()如果再加如一个锁,就会出现死锁
balance = balance +n
time.sleep(2)
balance = balance -n
print("##################{0}#".format(balance))
#释放锁
finally:
my_lock.release()
time.sleep(1) class ChageBlance(threading.Thread): def __init__(self, num, *args, **kwargs):
super().__init__(*args, **kwargs)
self.num = num def run(self):
for i in range(100000):
change_it(self.num) if __name__ == "__main__":
t1 = ChageBlance(5)
t2 = ChageBlance(8)
t1.start()
t2.start()
t1.join()
t2.join()
print("aaaa{0}".format(balance)) 结果;
##################0#
##################0#
##################0#
##################0#
##################0#
##################0#
因为都是零,这是每个线程都加了锁,防止被修改
Rlock,在一个线程里面可以多次进行自锁
import threading
import time my_lock = threading.Lock()
your_lock = threading.RLock()
balance = 0
def change_it(n):
global balance
try:
# 添加锁
your_lock.acquire()
your_lock.acquire()
balance = balance +n
time.sleep(2)
balance = balance -n
print("##################{0}#".format(balance))
#释放锁R
finally:
your_lock.release()
your_lock.release()
time.sleep(1) class ChageBlance(threading.Thread): def __init__(self, num, *args, **kwargs):
super().__init__(*args, **kwargs)
self.num = num def run(self):
for i in range(100000):
change_it(self.num) if __name__ == "__main__":
t1 = ChageBlance(5)
t2 = ChageBlance(8)
t1.start()
t2.start()
t1.join()
t2.join()
print("aaaa{0}".format(balance)) 结果: ##################0#
##################0#
##################0#
##################0#
##################0#

利用线程池,减少创建线程和销毁线程所带来的系统性能消耗

另外i一个也是线程池,只不过更加厉害

import time
import threading
from concurrent.futures.thread import ThreadPoolExecutor
from multiprocessing.dummy import Pool def run(n):
time.sleep(2)
print(threading.current_thread().name,n) def main():
t1 = time.time()
for n in range(5):
run(n) print(time.time() - t1) def main_use_thread():
ls = []
t1 = time.time()
for count in range(10):
for i in range(10):
t = threading.Thread(target=run,args=(i,))
ls.append(t)
t.start() for l in ls:
l.join()
print(time.time() - t1) def main_use_pool():
t1 = time.time()
n_list = range(100)
pool = Pool(10)
pool.map(run,n_list)
pool.close()
pool.join()
print(time.time() - t1) def main_use_thread():
t1 = time.time()
n_list = range(100)
with ThreadPoolExecutor(max_workers=10) as executor:
executor.map(run,n_list)
print(time.time() - t1) if __name__ == "__main__":
#main()
#下面的执行都是使用十个线程去处理的,效率比较高
#main_use_thread()
#main_use_pool()这个24秒
main_use_thread()#这个20秒
map函数:
map是python内置函数,会根据提供的函数对指定的序列做映射。 map()函数的格式是: map(function,iterable,...)
第一个参数接受一个函数名,后面的参数接受一个或多个可迭代的序列,返回的是一个集合。 把函数依次作用在list中的每一个元素上,得到一个新的list并返回。注意,map不改变原list,而是返回一个新list。 通过map还可以实现类型转换
将元组转换为list: map(int,(1,2,3)) # 结果如下:
[1,2,3]
将字符串转换为list: map(int,'1234') # 结果如下:
[1,2,3,4]
提取字典中的key,并将结果放在一个list中: map(int,{1:2,2:3,3:4}) # 结果如下
[1,2,3]
python16线程的更多相关文章
- [ 高并发]Java高并发编程系列第二篇--线程同步
高并发,听起来高大上的一个词汇,在身处于互联网潮的社会大趋势下,高并发赋予了更多的传奇色彩.首先,我们可以看到很多招聘中,会提到有高并发项目者优先.高并发,意味着,你的前雇主,有很大的业务层面的需求, ...
- [高并发]Java高并发编程系列开山篇--线程实现
Java是最早开始有并发的语言之一,再过去传统多任务的模式下,人们发现很难解决一些更为复杂的问题,这个时候我们就有了并发. 引用 多线程比多任务更加有挑战.多线程是在同一个程序内部并行执行,因此会对相 ...
- 多线程爬坑之路-学习多线程需要来了解哪些东西?(concurrent并发包的数据结构和线程池,Locks锁,Atomic原子类)
前言:刚学习了一段机器学习,最近需要重构一个java项目,又赶过来看java.大多是线程代码,没办法,那时候总觉得多线程是个很难的部分很少用到,所以一直没下决定去啃,那些年留下的坑,总是得自己跳进去填 ...
- Java 线程
线程:线程是进程的组成部分,一个进程可以拥有多个线程,而一个线程必须拥有一个父进程.线程可以拥有自己的堆栈,自己的程序计数器和自己的局部变量,但不能拥有系统资源.它与父进程的其他线程共享该进程的所有资 ...
- C++实现线程安全的单例模式
在某些应用环境下面,一个类只允许有一个实例,这就是著名的单例模式.单例模式分为懒汉模式,跟饿汉模式两种. 首先给出饿汉模式的实现 template <class T> class sing ...
- 记一次tomcat线程创建异常调优:unable to create new native thread
测试在进行一次性能测试的时候发现并发300个请求时出现了下面的异常: HTTP Status 500 - Handler processing failed; nested exception is ...
- Android线程管理之ThreadLocal理解及应用场景
前言: 最近在学习总结Android的动画效果,当学到Android属性动画的时候大致看了下源代码,里面的AnimationHandler存取使用了ThreadLocal,激起了我很大的好奇心以及兴趣 ...
- C#多线程之线程池篇3
在上一篇C#多线程之线程池篇2中,我们主要学习了线程池和并行度以及如何实现取消选项的相关知识.在这一篇中,我们主要学习如何使用等待句柄和超时.使用计时器和使用BackgroundWorker组件的相关 ...
- C#多线程之线程池篇2
在上一篇C#多线程之线程池篇1中,我们主要学习了如何在线程池中调用委托以及如何在线程池中执行异步操作,在这篇中,我们将学习线程池和并行度.实现取消选项的相关知识. 三.线程池和并行度 在这一小节中,我 ...
随机推荐
- python的虚拟环境Anaconda使用
Anaconda 使用conda常用命令 1.首先在所在系统中安装Anaconda.可以打开命令行输入conda -V检验是否安装以及当前conda的版本. 2.conda常用的命令. 1)con ...
- [敏捷软工团队博客]Beta阶段事后分析
设想和目标 我们的软件要解决什么问题?是否定义得很清楚?是否对典型用户和典型场景有清晰的描述? 我们的软件要解决的问题是:现在的软工课程的作业分布在博客园.GitHub上,没有一个集成多种功能的一体化 ...
- 需求存在,功能存在——Alpha阶段性总结
0.Alpha开发成果 题士Alpha发布报告 题士开发记录 1.任务划分 Alpha阶段大致将任务划分为Design,Develop和Test三类 Design型任务包含页面UI设计和接口API设计 ...
- NOIP模拟22
T1d 一道垃圾贪心,写个堆优化或者桶就行 1 #include<bits/stdc++.h> 2 #define int long long 3 using namespace std; ...
- 线路由器频段带宽是是20M好还是40M好
无线路由器频段带宽还是40M好. 40M的信号强,速度快. 1.20MHz在11n的情况下能达到144Mbps带宽.穿透性不错.传输距离较远 40MHz在11n的情况下能达到300Mbps带宽.穿 ...
- DC综合与Tcl语法结构概述
转载:https://www.cnblogs.com/IClearner/p/6617207.html 1.逻辑综合的概述 synthesis = translation + logic optimi ...
- Vivado Synth/Place Faild但是没有给出error信息
最近遇到一个现象,以前可以编译通过的工程,修改之后发现Synthesis编译报错,而且没有给出error信息,以前也出现过无故place 失败但是没有给出error信息的现象,查看错误日志输出文件,出 ...
- 面试官问我JVM内存结构,我真的是
面试官:今天来聊聊JVM的内存结构吧? 候选者:嗯,好的 候选者:前几次面试的时候也提到了:class文件会被类加载器装载至JVM中,并且JVM会负责程序「运行时」的「内存管理」 候选者:而JVM的内 ...
- 有关unsigned和有符号类型的区别
相信大家对于unsigned这个玩意并不陌生,但是有的时候却会被它搞懵,比如下面: #include<iostream> using std::cout; using std::cin; ...
- Java学习(十九)
先学了字体分类 大概是这种效果: 一般把这些大类放在font-family的最后使用,防止字体呈现的效果不够好. 今天把final关键字学完了 也要几点要注意,我觉得比较重要的就是public sta ...