机器学习之K-近邻算法
机器学习可分为监督学习和无监督学习。有监督学习就是有具体的分类信息,比如用来判定输入的是输入[a,b,c]中的一类;无监督学习就是不清楚最后的分类情况,也不会给目标值。
K-近邻算法属于一种监督学习分类算法,该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
需要进行分类,分类的依据是什么呢,每个物体都有它的特征点,这个就是分类的依据,特征点可以是很多,越多分类就越精确。
机器学习就是从样本中学习分类的方式,那么就需要输入我们的样本,也就是已经分好类的样本,比如特征点是A , B2个特征,输入的样本甲乙丙丁,分别为[[1.0, 1.1], [1.0, 1.0], [0., 0.], [0.0, 0.1]]。 那么就开始输入目标值,当然也要给特征了,最终的目标就是看特征接近A的多还是B的多,如果把这些当做坐标,几个特征点就是几纬坐标,那么就是坐标之间的距离。那么问题来了,要怎么看接近A的多还是B的多。
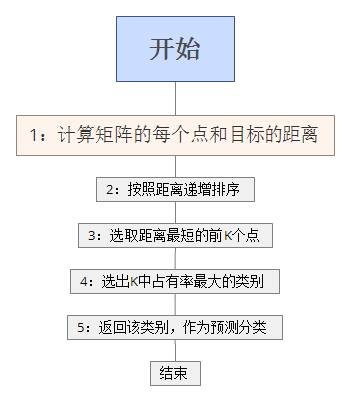
我就直接贴代码了,基于python,首先输入特征量labels和样本group。
一开始需要导入的模块
#coding=utf-8 #科学计算包
#from numpy import *
import numpy
#运算符模块
import operator
数据样本和分类模拟
#手动建立一个数据源矩阵group,和数据源的分类结果labels
def createDataSet():
group = numpy.array([[1.0, 1.1], [1.0, 1.0], [5., 2.], [5.0, 0.1]])
labels = ['A', 'A', 'B', 'B']
return group, labels
然后进行KNN算法。
# newInput为输入的目标,dataset是样本的矩阵,label是分类,k是需要取的个数
def kNNClassify(newInput, dataSet, labels, k):
#读取矩阵的行数,也就是样本数量
numSamples = dataSet.shape[0]
print 'numSamples: ' ,numSamples #变成和dataSet一样的行数,行数=原来*numSamples,列数=原来*1 ,然后每个特征点和样本的点进行相减
diff = numpy.tile(newInput, (numSamples, 1)) - dataSet
print 'diff: ',diff #平方
squaredDiff = diff ** 2
print "squaredDiff: ",squaredDiff #axis=0 按列求和,1为按行求和
squaredDist = numpy.sum(squaredDiff, axis = 1)
print "squaredDist: ",squaredDist #开根号,距离就出来了
distance = squaredDist ** 0.5
print "distance: ",distance #按大小逆序排列
sortedDistIndices = numpy.argsort(distance)
print "sortedDistIndices: ",sortedDistIndices classCount = {}
for i in range(k):
#返回距离(key)对应类别(value)
voteLabel = labels[sortedDistIndices[i]]
print "voteLabel: " ,voteLabel # 取前几个K值,但是K前几个值的大小没有去比较,都是等效的
classCount[voteLabel] = classCount.get(voteLabel, 0) + 1
print "classCount: " ,classCount
maxCount = 0
#返回占有率最大的
sortedClassCount=sorted(classCount.iteritems(),key=operator.itemgetter(1),reverse=True) return sortedClassCount[0][0]
最后进行测试
dataSet, labels = createDataSet() testX = numpy.array([0, 0])
k = 3
outputLabel = kNNClassify(testX, dataSet, labels, k)
print "Your input is:", testX, "and classified to class: ", outputLabel
可以发现输出
numSamples: 4
diff: [[-1. -1.1]
[-1. -1. ]
[-5. -2. ]
[-5. -0.1]]
squaredDiff: [[ 1.00000000e+00 1.21000000e+00]
[ 1.00000000e+00 1.00000000e+00]
[ 2.50000000e+01 4.00000000e+00]
[ 2.50000000e+01 1.00000000e-02]]
squaredDist: [ 2.21 2. 29. 25.01]
distance: [ 1.48660687 1.41421356 5.38516481 5.0009999 ]
sortedDistIndices: [1 0 3 2]
voteLabel: A
voteLabel: A
voteLabel: B
classCount: {'A': 2, 'B': 1}
Your input is: [0 0] and classified to class: A
这里我之前一直有个疑问,关于K的取值,结果也许跟K的取值产生变化,只要在K的取值范围内们所有特征点距离远近也就没有关系了。所以才叫K近邻分类算法
机器学习之K-近邻算法的更多相关文章
- 机器学习之K近邻算法(KNN)
机器学习之K近邻算法(KNN) 标签: python 算法 KNN 机械学习 苛求真理的欲望让我想要了解算法的本质,于是我开始了机械学习的算法之旅 from numpy import * import ...
- 【机器学习】k近邻算法(kNN)
一.写在前面 本系列是对之前机器学习笔记的一个总结,这里只针对最基础的经典机器学习算法,对其本身的要点进行笔记总结,具体到算法的详细过程可以参见其他参考资料和书籍,这里顺便推荐一下Machine Le ...
- 第四十六篇 入门机器学习——kNN - k近邻算法(k-Nearest Neighbors)
No.1. k-近邻算法的特点 No.2. 准备工作,导入类库,准备测试数据 No.3. 构建训练集 No.4. 简单查看一下训练数据集大概是什么样子,借助散点图 No.5. kNN算法的目的是,假如 ...
- 机器学习之K近邻算法
K 近邻 (K-nearest neighbor, KNN) 算法直接作用于带标记的样本,属于有监督的算法.它的核心思想基本上就是 近朱者赤,近墨者黑. 它与其他分类算法最大的不同是,它是一种&quo ...
- 机器学习实战-k近邻算法
写在开头,打算耐心啃完机器学习实战这本书,所用版本为2013年6月第1版 在P19页的实施kNN算法时,有很多地方不懂,遂仔细研究,记录如下: 字典按值进行排序 首先仔细读完kNN算法之后,了解其是用 ...
- 【机器学习】K近邻算法——多分类问题
给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该类输入实例分为这个类. KNN是通过测量不同特征值之间的距离进行分类.它的的思路是:如 ...
- 机器学习2—K近邻算法学习笔记
Python3.6.3下修改代码中def classify0(inX,dataSet,labels,k)函数的classCount.iteritems()为classCount.items(),另外p ...
- 机器学习03:K近邻算法
本文来自同步博客. P.S. 不知道怎么显示数学公式以及排版文章.所以如果觉得文章下面格式乱的话请自行跳转到上述链接.后续我将不再对数学公式进行截图,毕竟行内公式截图的话排版会很乱.看原博客地址会有更 ...
- [机器学习] k近邻算法
算是机器学习中最简单的算法了,顾名思义是看k个近邻的类别,测试点的类别判断为k近邻里某一类点最多的,少数服从多数,要点摘录: 1. 关键参数:k值 && 距离计算方式 &&am ...
- 机器学习:k-NN算法(也叫k近邻算法)
一.kNN算法基础 # kNN:k-Nearest Neighboors # 多用于解决分裂问题 1)特点: 是机器学习中唯一一个不需要训练过程的算法,可以别认为是没有模型的算法,也可以认为训练数据集 ...
随机推荐
- 集群CLUSTER种类介绍
一.集群CLUSTER 介绍 计算机集群Cluster,可以把多台计算机 连接在一起使用,平分资源或互为保障.其好处不言而喻,群集中的每个计算机被称为一个节点,节点可添加可减少,在这些节点之上虚拟出一 ...
- The current identity (NT AUTHORITY/NETWORK SERVICE)
IIS错误提示: The current identity (NT AUTHORITY/NETWORK SERVICE) does not have write access to 'C:/WINDO ...
- JS学习:第二周——NO.4DOM库
DOM库封装练习 var utils = (function () { var flg = 'getComputedStyle' in window;//惰性思想的运用: function makeA ...
- RBAC权限模型
RBAC 现在大多数的管理系统都是基于RBAC开发的组织机构权限框架.所有的操作都是基于角色(Role)来完成的.我们先从需求的角度出发,来了解关于系统权限管理. 用户A和用户B都属于研发部,我们可以 ...
- PYTHON 写函数,检查获取传入列表或元组对象的所有奇数位索引对应的元素,并将其作为新列表返回给调用者
def a3(arg): ret = [ ] for i in range(len(arg)): if i % 2 == 1: ret.append(arg[i]) else: pass return ...
- 《转载》Java异常处理的10个最佳实践
本文转载自 ImportNew - 挖坑的张师傅 异常处理在编写健壮的 Java 应用中扮演着非常重要的角色.异常处理并不是功能性需求,它需要优雅地处理任何错误情况,比如资源不可用.非法的输入.nul ...
- typeScence
- [MySQL]show index from tb_name命令各列的含义
show index from table_name 这个命令有助于诊断性能低下的查询,尤其是查询是否使用了可用的索引. 下面介绍下 这个命令显示的结果列的含义: | Table | Non_uniq ...
- [Sass]混合宏的参数
[Sass]混合宏的参数--传一个不带值的参数 Sass 的混合宏有一个强大的功能,可以传参,那么在 Sass 中传参主要有以下几种情形: A) 传一个不带值的参数 在混合宏中,可以传一个不带任何值的 ...
- HttpUtil
1.发送doPost请求,在web那边使用request.setCharacterEncoding("UTF-8");保证中文不乱码,不需要第三方jar包 public stati ...