Mysql学习之order by的工作原理
在你开发应用的时候,一定会经常碰到需要根据指定的字段排序来显示结果的需求。假设你要查询城市是“杭州”的所有人名字,并且按照姓名排序返回前 1000 个人的姓名、年龄。
查询语句为:
select city,name,age from t where city='杭州' order by name limit ;
全字段排序
为避免全表扫描,我们需要在 city 字段加上索引。
通常情况下,这个语句执行流程如下所示 :
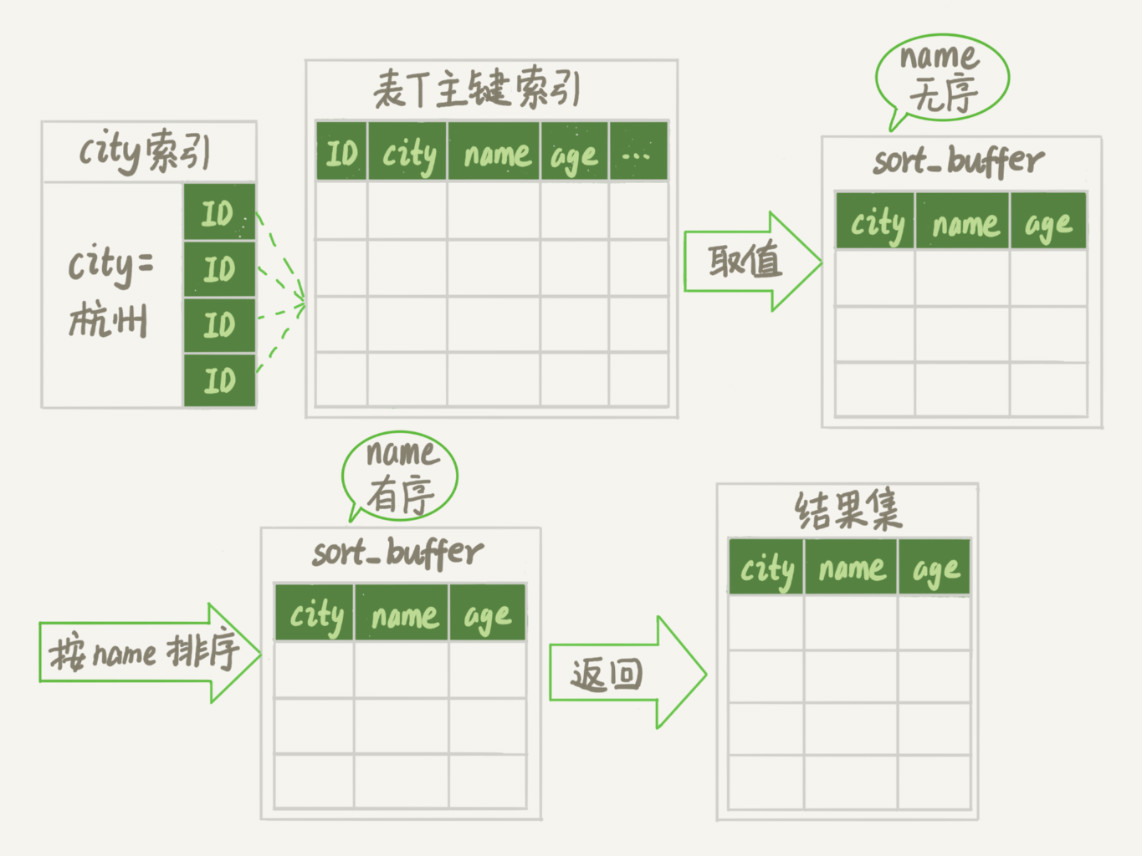
初始化 sort_buffer,确定放入 name、city、age 这三个字段;
从索引 city 找到第一个满足 city='杭州’条件的主键 id,也就是图中的 ID_X;
到主键 id 索引取出整行,取 name、city、age 三个字段的值,存入 sort_buffer 中;
从索引 city 取下一个记录的主键 id;
重复步骤 3、4 直到 city 的值不满足查询条件为止,对应的主键 id 也就是图中的 ID_Y;
对 sort_buffer 中的数据按照字段 name 做快速排序;
按照排序结果取前 1000 行返回给客户端。
我们暂且把这个排序过程,称为全字段排序,执行流程的示意图如下所示
图中“按 name 排序”这个动作,可能在内存中完成,也可能需要使用外部排序,这取决于排序所需的内存和参数 sort_buffer_size。
sort_buffer_size,就是 MySQL 为排序开辟的内存(sort_buffer)的大小。如果要排序的数据量小于 sort_buffer_size,排序就在内存中完成。但如果排序数据量太大,内存放不下,则不得不利用磁盘临时文件辅助排序。
这个算法有一个问题,就是如果查询要返回的字段很多的话,那么 sort_buffer 里面要放的字段数太多,这样内存里能够同时放下的行数很少,要分成很多个临时文件,排序的性能会很差。
rowid 排序
如果 MySQL 认为排序的单行长度太大会怎么做呢?
接下来,我来修改一个参数,让 MySQL 采用另外一种算法。
SET max_length_for_sort_data = ;
max_length_for_sort_data,是 MySQL 中专门控制用于排序的行数据的长度的一个参数。它的意思是,如果单行的长度超过这个值,MySQL 就认为单行太大,要换一个算法。
新的算法放入 sort_buffer 的字段,只有要排序的列(即 name 字段)和主键 id。
但这时,排序的结果就因为少了 city 和 age 字段的值,不能直接返回了,整个执行流程就变成如下所示的样子:
初始化 sort_buffer,确定放入两个字段,即 name 和 id;
从索引 city 找到第一个满足 city='杭州’条件的主键 id,也就是图中的 ID_X;
到主键 id 索引取出整行,取 name、id 这两个字段,存入 sort_buffer 中;
从索引 city 取下一个记录的主键 id;
重复步骤 3、4 直到不满足 city='杭州’条件为止,也就是图中的 ID_Y;
对 sort_buffer 中的数据按照字段 name 进行排序;
遍历排序结果,取前 1000 行,并按照 id 的值回到原表中取出 city、name 和 age 三个字段返回给客户端。
这个执行流程的示意图如下:
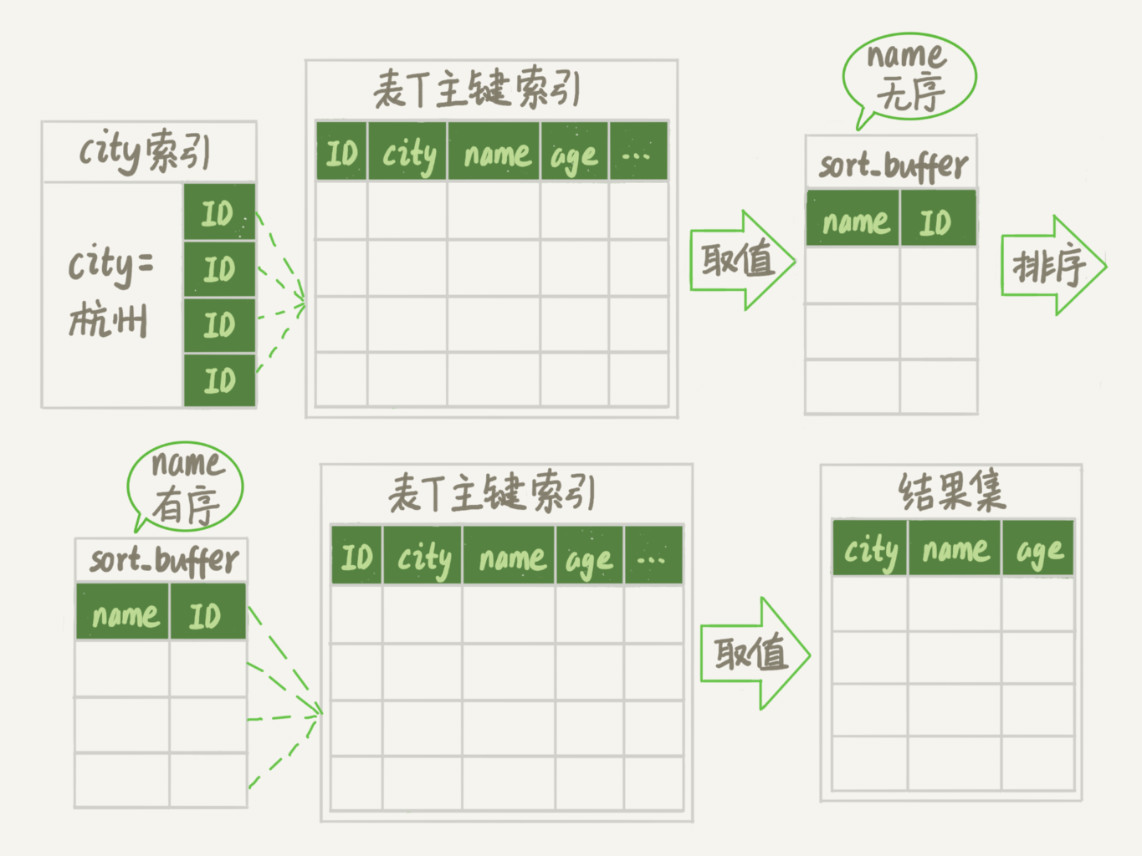
对比图 1 的全字段排序流程图你会发现,rowid 排序多访问了一次表 t 的主键索引,就是步骤 7。
需要说明的是,最后的“结果集”是一个逻辑概念,实际上 MySQL 服务端从排序后的 sort_buffer 中依次取出 id,然后到原表查到 city、name 和 age 这三个字段的结果,不需要在服务端再耗费内存存储结果,是直接返回给客户端的。
全字段排序 VS rowid 排序
如果 MySQL 认为内存足够大,会优先选择全字段排序,把需要的字段都放到 sort_buffer 中,这样排序后就会直接从内存里面返回查询结果了,不用再回到原表去取数据。
对于 InnoDB 表来说,rowid 排序会要求回表多造成磁盘读,因此不会被优先选择。
联合索引
如果能够保证从 city 这个索引上取出来的行,天然就是按照 name 递增排序的话,是不是就可以不用再排序了呢?
所以,我们可以在这个市民表上创建一个 city 和 name 的联合索引
在这个索引里面,我们依然可以用树搜索的方式定位到第一个满足 city='杭州’的记录,并且额外确保了,接下来按顺序取“下一条记录”的遍历过程中,只要 city 的值是杭州,name 的值就一定是有序的。
这样整个查询过程的流程就变成了:
从索引 (city,name) 找到第一个满足 city='杭州’条件的主键 id;
到主键 id 索引取出整行,取 name、city、age 三个字段的值,作为结果集的一部分直接返回;
从索引 (city,name) 取下一个记录主键 id;
重复步骤 2、3,直到查到第 1000 条记录,或者是不满足 city='杭州’条件时循环结束。
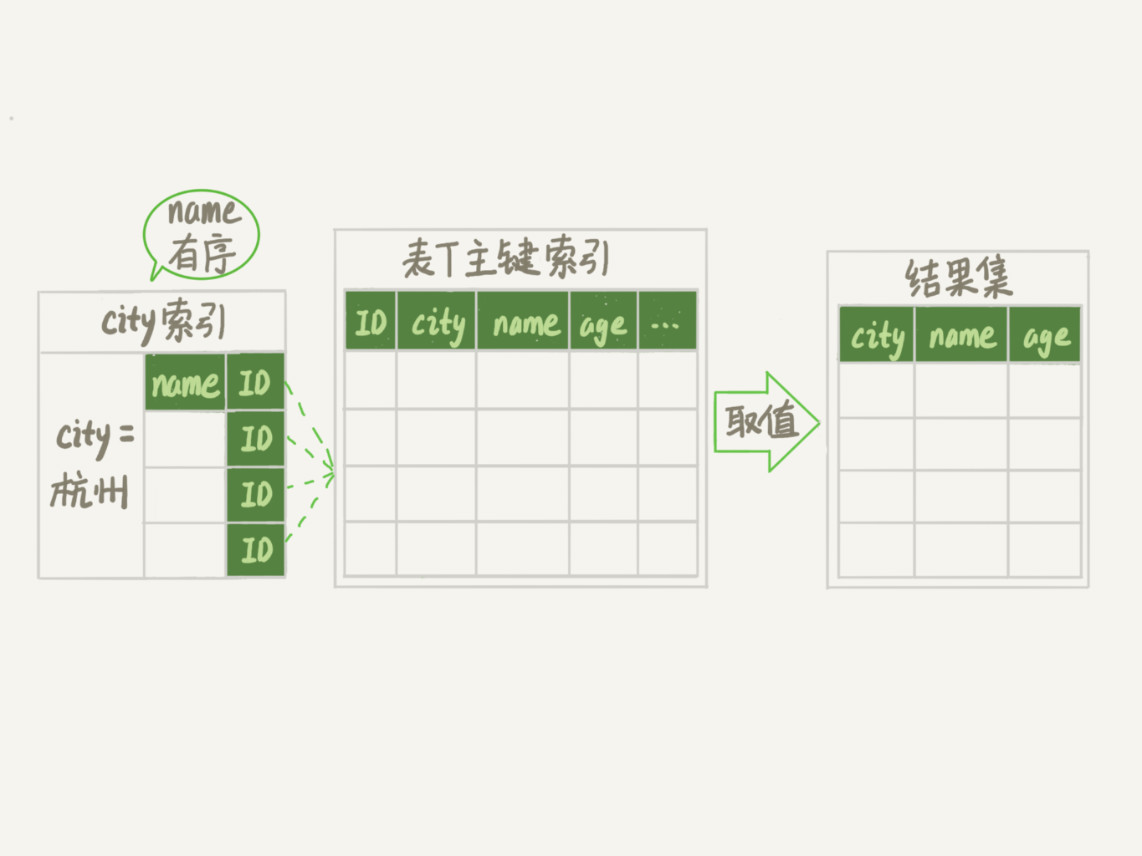
可以看到,这个查询过程不需要临时表,也不需要排序。接下来,我们用 explain 的结果来印证一下。

从图中可以看到,Extra 字段中没有 Using filesort 了,也就是不需要排序了。而且由于 (city,name) 这个联合索引本身有序,所以这个查询也不用把 4000 行全都读一遍,只要找到满足条件的前 1000 条记录就可以退出了。也就是说,在我们这个例子里,只需要扫描 1000 次。
覆盖索引是指,索引上的信息足够满足查询请求,不需要再回到主键索引上去取数据。
按照覆盖索引的概念,我们可以再优化一下这个查询语句的执行流程。
针对这个查询,我们可以创建一个 city、name 和 age 的联合索引
这样整个查询语句的执行流程就变成了:
从索引 (city,name,age) 找到第一个满足 city='杭州’条件的记录,取出其中的 city、name 和 age 这三个字段的值,作为结果集的一部分直接返回;
从索引 (city,name,age) 取下一个记录,同样取出这三个字段的值,作为结果集的一部分直接返回;
重复执行步骤 2,直到查到第 1000 条记录,或者是不满足 city='杭州’条件时循环结束。
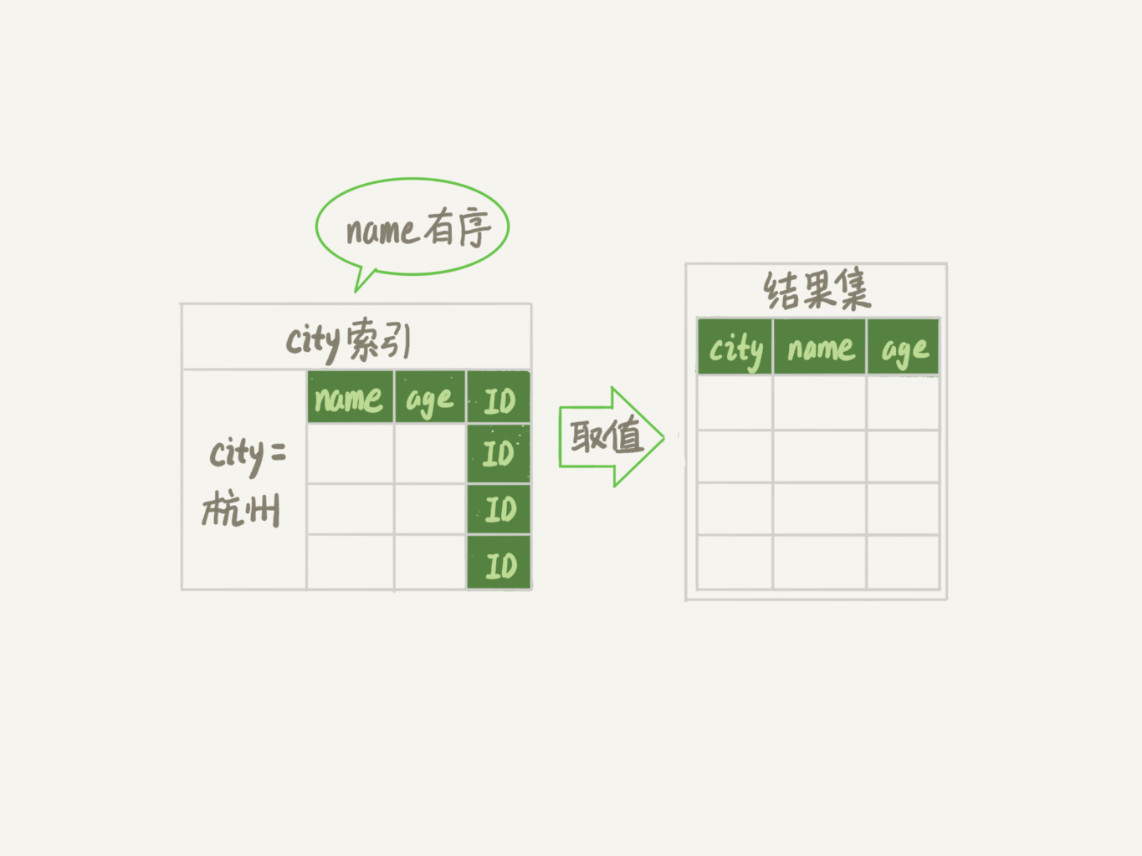
当然,这里并不是说要为了每个查询能用上覆盖索引,就要把语句中涉及的字段都建上联合索引,毕竟索引还是有维护代价的。这是一个需要权衡的决定。
Mysql学习之order by的工作原理的更多相关文章
- 《Mysql - Order By 的工作原理?》
一:概述 - order by 用于 SQL 语句中的排序. - 以 select city,name,age from t where city='杭州' order by name limit ...
- android学习11——Handler,Looper,MessageQueue工作原理
Message是Handler接收和处理的消息对象. 每个线程只能拥有一个Looper.它的loop方法读取MessageQueue中的消息,读到消息之后就把消息交给发送该消息的Handler进行处理 ...
- AngularJS学习笔记3——AngularJS的工作原理
个人觉得,要很好的理解AngularJS的运行机制,才能尽可能避免掉到坑里面去.在这篇文章中,我将根据网上的资料和自己的理解对AngularJS的在启动后,每一步都做了些什么,做一个比较清楚详细的解析 ...
- ELK学习实验011:Logstash工作原理
Logstash事件处理管道包括三个阶段:输入→过滤器→输出.输入会生成事件,过滤器会对其进行修改,输出会将它们发送到其他地方.输入和输出支持编解码器,使您可以在数据进入或退出管道时对其进行编码或解码 ...
- obj-c编程01[扩展学习01]:对象消息机制工作原理
obj-c中的类就像C语言中的struct.NSObject类声明一个成员变量isa,因为NSObject类是整个继承树的根,所以每个类中都有一个isa其指向创建的对象.在类结构中有实例变量(成员变量 ...
- python爬虫学习之Scrapy框架的工作原理
一.Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网 ...
- 数电学习笔记之CMOS传输门工作原理
CMOS 传输门从结构上看是由一个PMOS和一个NMOS管组成 先简单粗略讲讲PMOS管和NMOS管导通与截止吧 首先我们MOS管有三个极,源极(S:Source).漏极(D:Drain)和栅极(G: ...
- Android之view的工作原理2
学习内容 View的底层工作原理,比如View的测量流程.布局流程以及绘制流程:以及常见的View回调方法:熟悉掌握前面的知识后,自定义View的时候也会更加的得心应手. 4.1 初识ViewRoot ...
- How Javascript works (Javascript工作原理) (十四) 解析,语法抽象树及最小化解析时间的 5 条小技巧
个人总结:读完这篇文章需要15分钟,文章介绍了抽象语法树与js引擎解析这些语法树的过程,提到了懒解析——即转换为AST的过程中不直接进入函数体解析,当这个函数体需要执行的时候才进行相应转换.(因为有的 ...
随机推荐
- UTF-8和GBK编码之间的区别(页面编码、数据库编码区别)以及在实际项目中的应用
第一节:UTF-8和GBK编码概述 UTF-8 (8-bit Unicode Transformation Format) 是一种针对Unicode的可变长度字符编码,又称万国码,它包含全世界所有国家 ...
- Emgu.CV.CvInvoke”的类型初始值设定项引发异常
http://zhidao.baidu.com/link?url=VHkw3qZxp7HumQX_r-4ljPiy-N4A7yNK1Xn5q6tjPb16WvBGy6RFKrmKEhtgJ2PACAk ...
- 洛谷P1106 删数问题
题目描述 键盘输入一个高精度的正整数N,去掉其中任意k个数字后剩下的数字按原左右次序将组成一个新的正整数.编程对给定的N和k,寻找一种方案使得剩下的数字组成的新数最小. 输出应包括所去掉的数字的位置和 ...
- 洛谷P1199 三国游戏
题目描述 小涵很喜欢电脑游戏,这些天他正在玩一个叫做<三国>的游戏. 在游戏中,小涵和计算机各执一方,组建各自的军队进行对战.游戏中共有 N 位武将(N为偶数且不小于 4),任意两个武将之 ...
- json数据的格式
JSON的具体形式 1.对象是一个无序的“‘名称/值’对”集合.一个对象以“{”开始,以“}”结束.每个“名称”后跟一个“:”,“‘名称/值’对”之间使用“,”分隔. 举个例子: { name:&qu ...
- C++ 局部静态变量,全局变量,全局静态变量,局部变量的区别和联系
C++变量根据定义位置的不同,具有不同的作用域,作用域可分为6种:全局作用域,局部作用域,语句作用域,类作用域,命名作用域和文件作用域. 从作用域看: 全局变量具有全局作用域.全局变量只需在一个源文件 ...
- 协程-遇到I/O自动切换
参考博客:http://www.cnblogs.com/alex3714/articles/5248247.html 一.前言 Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步 ...
- JSTL获取当日时间与数据时间比较
<jsp:useBean id="now" class="java.util.Date" /> <fmt:formatDate value=& ...
- c++ virtual总结
virtual-关键字用于修饰成员函数时,有以下特性 1.用于修饰的基类的成员函数,被修饰的基类成员函数-其派生类的同名成员函数也默认带有virtual 关键字2.当virtual 用于修饰析构函数( ...
- 浅析 Spring Aop
aop也是Spring里比较重要的一个点,最近把源码看了下,这里总结一下 使用上主要就下面的点注意下: 相关的Annotaion Around Before After AfterReturning ...