pig配置
下载Apache Pig
首先,从以下网站下载最新版本的Apache Pig:https://pig.apache.org/
步骤1
打开Apache Pig网站的主页。在News部分下,点击链接release page,如下面的快照所示。

步骤2
点击指定的链接后,你将被重定向到 Apache Pig Releases 页面。在此页面的Download部分下,单击链接,然后你将被重定向到具有一组镜像的页面。

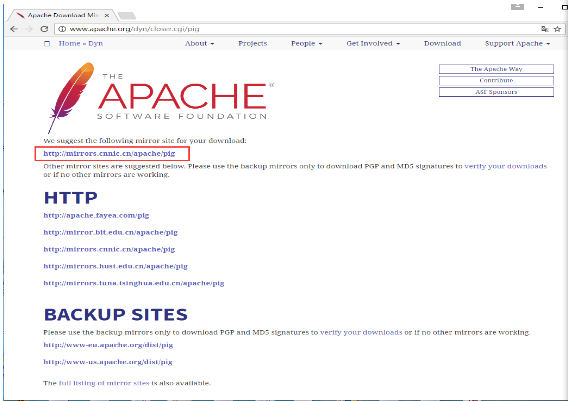
步骤3
选择并单击这些镜像中的任一个,如下所示
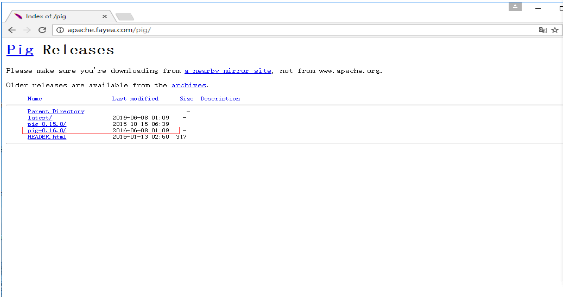
步骤4
这些镜像将带您进入 Pig Releases 页面。 此页面包含Apache Pig的各种版本。 单击其中的最新版本。
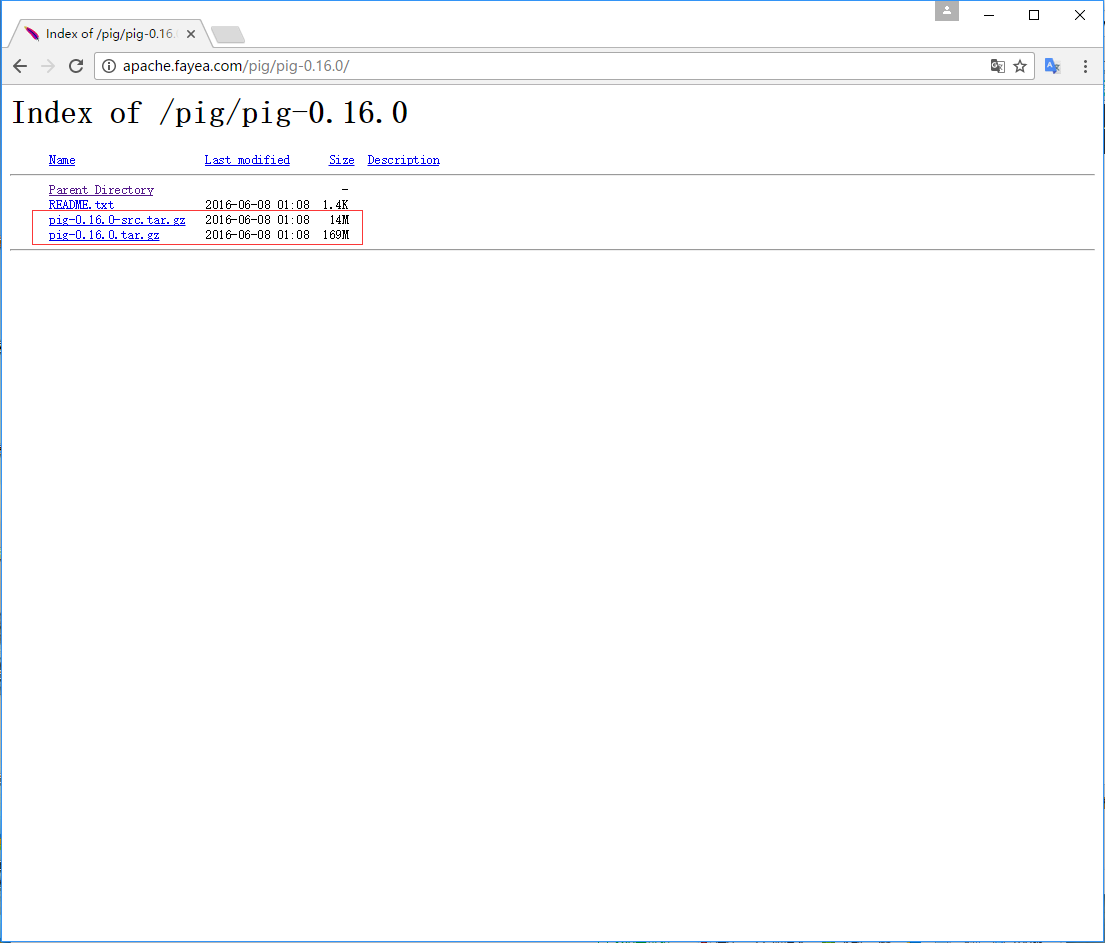
步骤5
在这些文件夹中,有发行版中的Apache Pig的源文件和二进制文件。下载Apache Pig 0.16, pig0.16.0-src.tar.gz 和 pig-0.16.0.tar.gz 的源和二进制文件的tar文件。
安装Apache Pig
下载Apache Pig软件后,按照以下步骤将其安装在Linux环境中。
步骤1
在安装了 Hadoop,Java和其他软件的安装目录的同一目录中创建一个名为Pig的目录。(在我们的教程中,我们在名为Hadoop的用户中创建了Pig目录)。
在此说明,下载tar包就够,src暂时并不需要
tar zxvf pig-0.15.0.tar.gz -C /home/hadoop/hadoop_home/
配置Apache Pig
安装Apache Pig后,我们必须配置它。要配置,我们需要编辑两个文件 - bashrc和pig.properties 。
.bashrc文件
在 .bashrc 文件中,设置以下变量
PIG_HOME 文件夹复制到Apache Pig的安装文件夹
PATH 环境变量复制到bin文件夹
PIG_CLASSPATH 环境变量复制到安装Hadoop的etc(配置)文件夹(包含core-site.xml,hdfs-site.xml和mapred-site.xml文件的目录)。
在此说明,同时不需要配置bashrc文件,和profile区别,详细搜索
export PIG_HOME=/home/Hadoop/Pig
export PATH=$PATH:/home/Hadoop/pig/bin
export PIG_CLASSPATH=$HADOOP_HOME/etc/hadoop##配置集群用,本地则不需要
注意空格的问题
source ~/.profile即可
启动集群的话,要把日志也启动
mr-jobhistory-daemon.sh start historyserver
pig配置的更多相关文章
- Hive集成HBase;安装pig
Hive集成HBase 配置 将hive的lib/中的HBase.jar包用实际安装的Hbase的jar包替换掉 cd /opt/hive/lib/ ls hbase-0.94.2* rm -rf ...
- PIG之 Hadoop 2.7.4 + pig-0.17.0 安装
首先: 参考 http://blog.csdn.net/zhang123456456/article/details/77621487 搭建好hadoop集群. 然后,在master节点安装pig. ...
- SpringBoot 之 配置文件、yaml语法、配置注入、松散绑定
配置文件 SpringBoot 有两种配置文件格式,二选一即可,官方推荐 yaml: application.properties key=value的格式 application.yaml key: ...
- PIG的配置
Pig是一个客户端应用程序,就算你要在Hadoop集群上运行Pig,也不需要在集群上装额外的东西.Pig的配置非常简单: 1.下载pig,网址http://pig.apache.org/ 2.在机器上 ...
- Hadoop 之Pig的安装的与配置之遇到的问题---待解决
1. 前提是hadoop集群已经配置完成并且可以正常启动:以下是我的配置方案: 首先配置vim /etc/hosts 192.168.1.64 xuegod64 192.168.1.65 xuegod ...
- pig安装配置
pig的安装配置很简单,只需要配置一下环境变量和指向hadoop conf的环境变量就行了 1.上传 2.解压 3.配置环境变量 Pig工作模式 本地模式:只需要配置PATH环境变量${PIG_HOM ...
- hbase、pig、hive配置与应用
------------------HBASE---------- [root@iClient~]#sudo yum install hbase #iClient安装Hbase客户端 [root@cM ...
- 大数据笔记(十七)——Pig的安装及环境配置、数据模型
一.Pig简介和Pig的安装配置 1.最早是由Yahoo开发,后来给了Apache 2.支持语言:PigLatin 类似SQL 3.翻译器 PigLatin ---> MapReduce(Spa ...
- pig安装配置及实例
一.前提 1. hadoop集群环境配置好(本人hadoop版本:hadoop-2.7.3) 2. windows基础环境准备: jdk环境配置.esclipse环境配置 二.搭建pig环境 1.下载 ...
随机推荐
- Tkinter Menubutton(菜单按钮)
Python - Tkinter Menubutton: 一个菜单按钮是一个下拉菜单,在屏幕上停留时间的一部分.菜单的小工具,可以显示该菜单按钮的选择,当用户点击它与每个menubutton时. ...
- 06_java之类概述
01引用数据类型_类 * A: 数据类型 * a: java中的数据类型分为:基本类型和引用类型 * B: 引用类型的分类 * a: Java为我们提供好的类,比如说:Scanner,Random等. ...
- SWFUpload初体验 For Struts1.x
SWFUpload是一个客户端文件上传工具,最初由Vinterwebb.se开发,它通过整合Flash与JavaScript技术为WEB开发者提供了一个具有丰富功能继而超越传统<input ty ...
- Java后端发送email实现
依赖的jar包 <dependency> <groupId>com.sun.mail</groupId> <artifactId>javax.mail& ...
- 基于 DirectX11 的 MMDViewer 03-渲染管线
准备工作: 开始搭建框架之前,你需要确保已经进行了 D3D 开发环境的搭建,相关教程可以阅读这篇文章.不了解 DirectX11 的人,这个作者有关 DirectX11 的教程最好阅读一下,虽然文章不 ...
- https 理解
这张图已经很明白,以下为翻译: 一.秘钥传输过程(确认秘钥相同) 1.请求服务端 2.服务端有公司要 3.公钥发给客户端 4.验证发过来的公钥crt,生成随机秘钥,并用此公钥加密 5.加密后的秘钥发给 ...
- java tomcat报错: Starting Tomcat v7.0 Server at localhost' has encountered a problem问题
运行web项目的时候出现下面错误: 出现这个问题的原因是 这个tomcat在其他项目中正在运行 关掉即可.
- 使用CreateJS绘制数字盒子
- 解剖Nginx·模块开发篇(3)ngx_http_hello_world_module 模块的基本函数实现
还记得我们定义过一个结构体如下吗? typedef struct { ngx_str_t output_words; } ngx_http_hello_world_loc_conf_t; 它就是 He ...
- 75. Sort Colors (Array)
Given an array with n objects colored red, white or blue, sort them so that objects of the same colo ...