python(十)、进程
一、基本概念
进程和线程是编程中非常重要的概念,它是并发和异步的基础性知识。
1.进程
概念:程序在并发环境中的执行过程。进程作为系统资源分配、调度、管理和独立运行的基本单位,决定了操作系统的四大特性:并发、异步、共享和虚拟。并发:在同一时段内执行多个任务。异步:执行多个任务时,任务彼此独立互不干扰。共享:系统资源可以供多个任务共享,而不被独占。虚拟:把多个物理设备绑定到一起,建立多个逻辑对应上的应用。
基本特征:动态性、并发性、调度性。动态性是指,进程是执行着的程序,是程序的运行状态和运行实体,进程随任务的创建而开始,随任务的结束而消失;而程序则是有序指令集合,能够作为一种资源进行存储,程序可以有多个进程。并发性是指,进程是可以并发执行的,系统中的多进程可以独立、不可预知地执行。调度性是指,进程是系统进行资源分配的最小单位。
程序并发执行时的特征:间断性、失去封闭性、不可再现性。
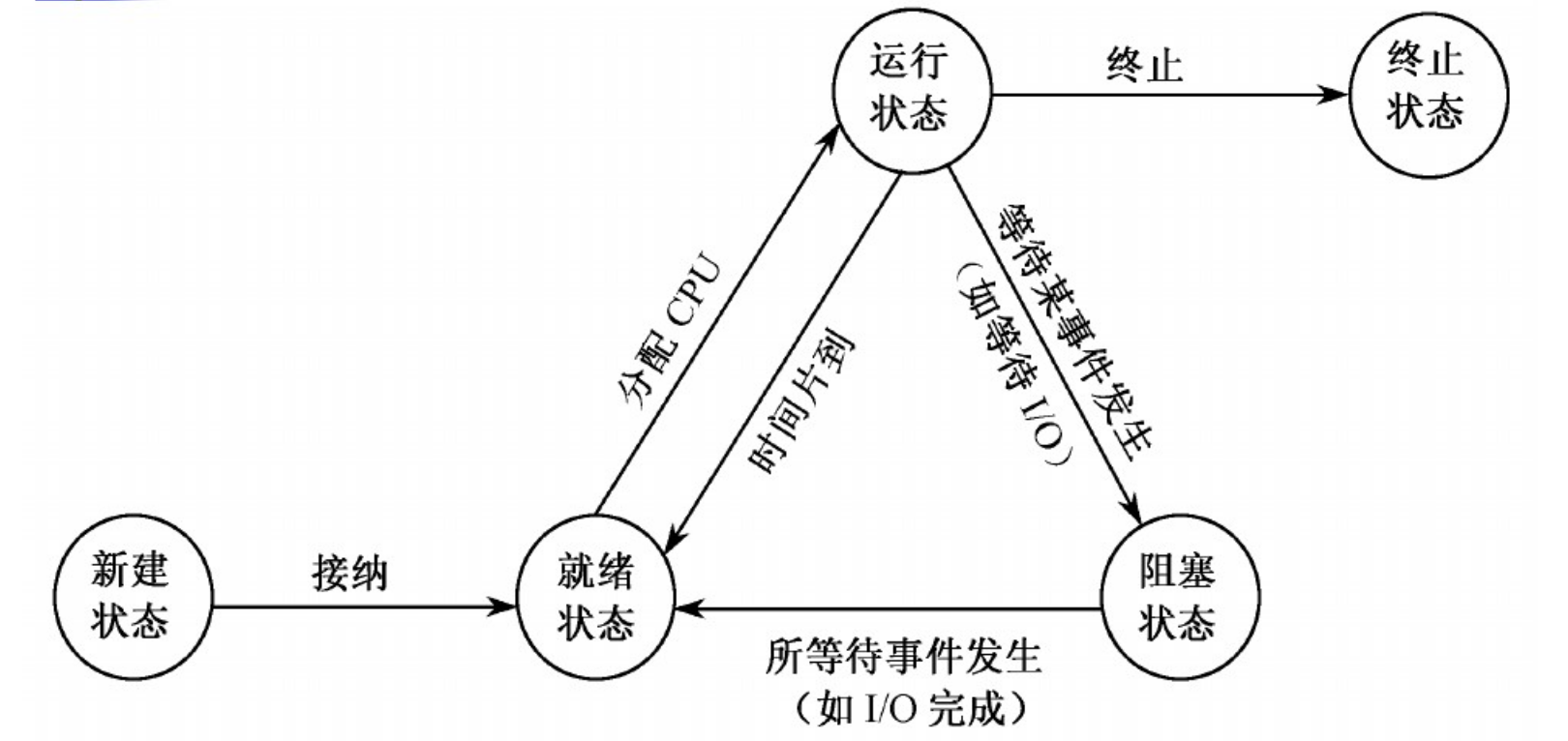
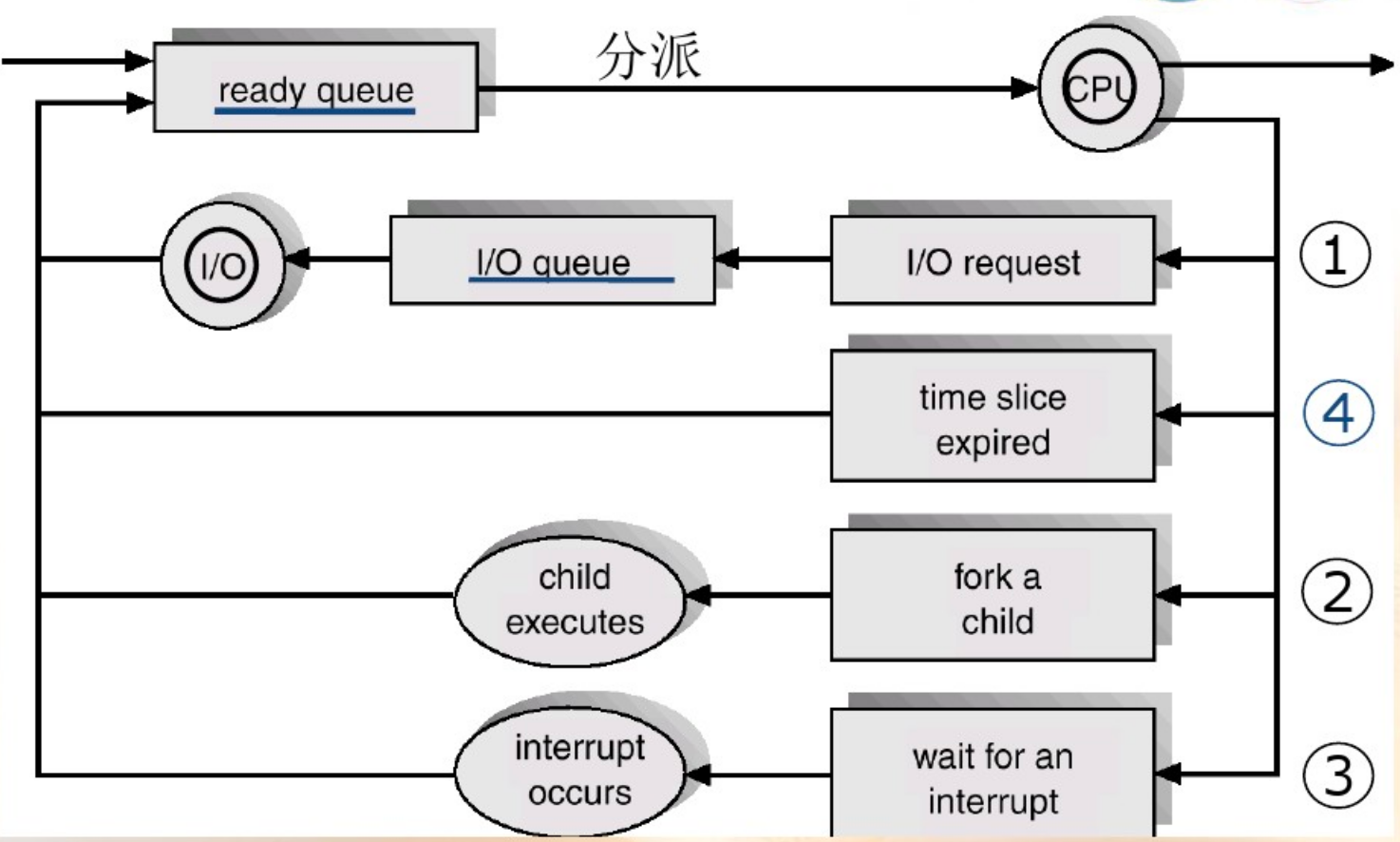
基本状态:新建状态、就绪状态、运行状态、阻塞状态、终止状态。它的转换关系如下图所示。就绪、运行和阻塞是常见的三种状态。处于阻塞状态时,如果程序可以继续运行,则需要转为就行状态,再进入运行状态。
进程调度的队列图:
PCB(Processing Control Block):进程控制块,通常是系统内存占用区中的一个连续存区(数据结构),主要表示进程状态。它存放着操作系统用于描述进程情况及控制进程运行所需的全部信息。操作系统是根据PCB来对并发执行的进程进行控制和管理的。PCB和进程的关系是一对一的。进程控制块主要包括该进程的以下信息:进程名、特征信息、进程状态信息、调度优先权、通信信息、现场保护区、资源需求、进程实体信息、族系关系等。每个进程有唯一的PCB,PCB是进程存在的唯一标志。
进程队列:系统把所有PCB组织起来的方式大致分三种:线性方式、链式方式、索引方式。
进程创建与终止:进程创建原语:创建进程的主要任务是为其建立一个PCB(程序、数据、用户栈的进程映像模型),主要包含四个步骤:申请一个空闲的PCB;为新进程分配资源;初始化PCB;将新PCB插入进程队列。进程终止原语也分四个步骤:找到进程对应的PCB,终止该进程的运行;回收该进程所占用的全部资源;终止其所有子孙进程,回收它们占用的所有资源;将PCB从原来队列中清除。
进程间关系:互斥-竞争关系、同步-协作关系、通信-信息交流。互斥:逻辑上相互独立的进程由于竞争同一个资源而产生的相互竞争关系;同步:进程间共同完成一项任务时发生的相互作用的关系。互斥是一种同步。通信-进程间的数据交换。
进程互斥:
- 一次仅允许一个进程使用的资源称为临界资源(Critical Resource)。临界资源可以是硬件也可以是软件。如打印机只能同时由一个进程使用,那么它就是临界资源。
- 在每个进程中访问临界资源的那段程序称为临界区(Critical Section)。对于不同临界资源的临界区,它们之间不互斥。
- 进程互斥,就是对进程进入时临界区加以控制。进入前要申请,获准后进入,执行临界区程序后退出, 然后才可以执行其它代码。
- 临界区进入准则:
- 空闲让进:如果若干进程要求进入空闲的临界区,一次仅允许一个进程进入。
- 忙则等待:任何时候,处于临界区的进程不可多于一个。
- 有限等待:进入临界区的进程要在有限时间内退出。
- 让权等待:如果进程不能进入自己的临界区,则应让出CPU,避免进程出现“忙等”现象。
信号量:信号量是一种数据操作锁,与进程互斥相反,信号量规定多个进程可以同时操作同一资源。
二、python进程
根据multiprocessing的官方文档介绍,multiprocessing is a package that supports spawning processes using an API similar to the threading module,多进程是根据多线程仿写的,它没有GIL(Global Interpreter Lock)的限制,可以充分利用多核资源。
1.开启进程
开启进程有两种方式:函数式和类式。
from multiprocessing import Process
import os, time def say():
time.sleep(2)
print("子进程: ", os.getpid())
print("This is a subprocess.")
print("子进程结束.") if __name__ == '__main__':
print("主进程: ", os.getpid())
p = Process(target=say, args=())
p.start()
print("主进程结束.")
from multiprocessing import Process
import os, time class Say(Process):
def __init__(self):
super().__init__()
def run(self): # 重写类方法
time.sleep(2)
print("子进程: ", os.getpid())
print("This is a subprocess.")
print("子进程结束.") if __name__ == '__main__':
print("主进程: ", os.getpid())
p = Say()
p.start()
print("主进程结束.")
当类继承定义开启子类时,run()方法最终调用target方法,并将args和kwargs传递进去,从而开启一个线程。
multiprocessing supports three ways to start a process。spawn、fork、forkserver。spawn只会使用部分父进程的资源(重开python解释器进程,速度慢),fork会继承父进程的全部资源(容易泄密),相较于前两个,forkserver会在需要启动子进程时由父进程向forserver请求创建新的子进程,它效率高并且不必继承所有资源。
import multiprocessing as mp def foo(q):
q.put('hello') if __name__ == '__main__':
ctx = mp.get_context('forkserver')
q = ctx.Queue()
p = ctx.Process(target=foo, args=(q,))
p.start()
print(q.get())
p.join() # 守护进程
2.进程的几种类型
守护进程setDaemon(True):父进程执行结束,子进程立刻结束(被强制终止),那么该子进程被称为守护进程。
孤儿进程(不做任何设置):父进程结束,子进程仍在继续执行,那么子进程被称为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。孤儿进程没有危害。
阻塞进程(join):父进程在所有子进程执行结束后,再执行结束。
僵尸进程:使用os.folk()创建的子进程,在其父进程退出时,如果没有调用wait或waitpid获取子进程的状态信息,那么子进程在退出后仍会将文件描述符遗留在系统内存里。这时它不能被init进程回收,会占用系统内存。僵尸进程需要避免。
3.进程通信
multiprocessing supports two types of communication channel between processes: Queue and Pipe。进程间通信的方式有两种,即通过队列或者管道。
管道是进程间直接通信,队列则借助共享存储器空间来实现。远程通信则通过socket实现。
multiprocessing.Queue是仿写的queue.Queue。它是线程和进程安全的。
举个例子: 开启两个进程一个队列,一个进程不断地往队列中添加url,另一个进程从队列中取出url,下载天龙八部章节。
from multiprocessing import Process, Queue
import urllib
from bs4 import BeautifulSoup def url_maker(q):
num = 2024334
for i in range(5):
url = "https://www.ybdu.com/xiaoshuo/10/10237/{}.html".format(num)
q.put(url)
print(url)
num += 1
q.put("over") def url_parse(q):
count = 0
while True:
url = q.get() # 从列表中获取url
if url == "over":
break
else:
count += 1
html = urllib.request.urlopen(url) # 请求html
html_bytes = html.read() # 读取字节数据
soup = BeautifulSoup(html_bytes, "html.parser")
string = soup.find("div", attrs={"class": "contentbox", "id": "htmlContent"}).get_text() # 获取小说内容
lines = string.split()
with open("天龙八部.txt", mode="a", encoding="utf-8") as f: # 写入文件
f.write("第 {} 章".format(count) + "\r\n")
print("已下载第{}章...".format(count))
for i, line in enumerate(lines[: -6]):
f.write(" " + line + "\r\n") if __name__ == '__main__':
q = Queue()
p1 = Process(target=url_maker, args=(q,))
p2 = Process(target=url_parse, args=(q,))
p1.start()
p2.start()
p1.join()
p2.join()
改写成子类式:
from multiprocessing import Process, Queue
import urllib
from bs4 import BeautifulSoup class UrlMaker(Process): # 传参的时候也可以global,甚至target都可以另写
def __init__(self):
super().__init__()
def run(self):
num = 2024334
for i in range(5):
url = "https://www.ybdu.com/xiaoshuo/10/10237/{}.html".format(num)
q.put(url)
print(url)
num += 1
q.put("over") class UrlParser(Process):
def __init__(self, file):
super().__init__()
self.file = file
def run(self):
count = 0
while True:
url = q.get() # 从列表中获取url
if url == "over":
break
else:
count += 1
html = urllib.request.urlopen(url) # 请求html
html_bytes = html.read() # 读取字节数据
soup = BeautifulSoup(html_bytes, "html.parser")
string = soup.find("div", attrs={"class": "contentbox", "id": "htmlContent"}).get_text() # 获取小说内容
lines = string.split()
with open(self.file, mode="a", encoding="utf-8") as f: # 写入文件
f.write("第 {} 章".format(count) + "\r\n")
print("已下载第{}章...".format(count))
for i, line in enumerate(lines[: -6]):
f.write(" " + line + "\r\n") if __name__ == '__main__':
q = Queue()
p1 = UrlMaker()
p2 = UrlParser("天龙八部1.txt")
p1.start()
p2.start()
p1.join()
p2.join()
官网给定的Pipe的例子: 貌似这货不能用while True循环以及I/O操作。
from multiprocessing import Process, Pipe def f(conn):
conn.send([42, None, 'hello'])
conn.close() if __name__ == '__main__':
parent_conn, child_conn = Pipe() # Pipe性能高于Queue
p = Process(target=f, args=(child_conn,))
p.start()
print(parent_conn.recv()) # prints "[42, None, 'hello']"
p.join()
再看官网给的详细介绍:
When using multiple processes, one generally uses message passing for communication between processes and avoids having to use any synchronization primitives like locks.
(多进程一般会使用消息传递进行彼此间通信,并且避免使用像锁这样的同步原语),进程互斥有自己的原语(取得锁 -- do something -- 释放锁)。
For passing messages one can use Pipe() (for a connection between two processes) or a queue (which allows multiple producers and consumers).
(可以使用Pipe在一对一进程间传递消息,使用queue多对多进程间传递消息)
The Queue, SimpleQueue and JoinableQueue types are multi-producer, multi-consumer FIFO queues modelled on the queue.Queue class in the standard library.
(基于标准库中的queue.Queue类,Queue, SimpleQueue和JoinableQueue都是多对多的先进先出的队列模型)
If you use JoinableQueue then you must call JoinableQueue.task_done() for each task removed from the queue or else the semaphore used to count the number of unfinished tasks may eventually overflow, raising an exception.
JoinableQueue 队列仅有两个方法:task_done()和join(),以生产者消费者模型说明这个队列的用法。
from multiprocessing import Process, JoinableQueue
import os, time
import numpy as np def func1(q):
while True:
num = np.random.randint(1, 4)
for i in range(num):
q.get("包子")
q.task_done() # 每一次取数据是一个task,都需要调用task_done()回调给队列,告诉队列进程已获取到该值
print("消费者%s消费了 --%d-- 个包子." % (os.getpid(), num))
time.sleep(1) def func2(q):
num = np.random.randint(5, 15)
for i in range(num):
q.put("包子")
print("生产者%s生产了 --%d-- 个包子." % (os.getpid(), num))
time.sleep(2)
q.join() # 如果写q.join(),会使生产者进程一直阻塞到队列中所有的数据都被取走位置;不写的话生产完就结束了 if __name__ == '__main__':
q = JoinableQueue()
processes = []
for i in range(3):
p = Process(target=func2, args=(q,), name="生产者")
processes.append(p)
for i in range(5):
p = Process(target=func1, args=(q,), name="消费者")
processes.append(p)
for p in processes:
p.start()
p.join()
Note that one can also create a shared queue by using a manager object – see Managers.
Managers实例化时创建了一个服务进程,以供其它两个或多个进程间的通信。manager returned by Manager() will support types list, dict, Namespace, Lock, RLock, Semaphore, BoundedSemaphore, Condition, Event, Barrier, Queue, Value and Array等。
from multiprocessing import Process, Manager
import time def func1(dic):
for i in range(5):
dic.get("包子")
print("消费者正在消费第%d个包子." % i)
time.sleep(1) def func2(dic):
for i in range(5):
dic[i] = "包子 %d " % i
print("--生产者生产了5个包子.--") if __name__ == '__main__':
with Manager() as manager:
dic = manager.dict()
p1 = Process(target=func2, args=(dic,), name="生产者")
p2 = Process(target=func1, args=(dic,), name="消费者")
p1.start()
p2.start()
p1.join()
p2.join()
3.进程同步(Lock、RLock、Condition、Sepmhore)
先看一段代码:
from multiprocessing import Process
def desc():
global num
f = open("test.txt", )
for i in range(1000):
# print("desc-----: ", num)
num -= 1
print("----------num------------", num)
def add():
global num
for i in range(1000):
print("add: ", num)
num += 1
print("----------num------------", num)
if __name__ == '__main__':
num = 0
p1 = Process(target=desc)
p1.start()
p1.join()
print(num) # 打印结果为:
----------num------------ -1000
可以看出: 在创建子进程时,将global资源给了子进程,然后两个进程就彼此独立了。主进程有个num,子进程有个num,各自计算num值没有交互。印证了进程间的独立性。另一方面,也说明了进程间通信必须依赖第三方内存(硬盘)空间(Queue、Pipe、Manager等)。
同样地,下面代码最后打印了三个进程各自的num值,并且从循环打印中可以看出,除了创建进程时的复制资源,进程运行时各自的循环没有交互。
from multiprocessing import Process def desc():
global num
for i in range(10):
print("desc-----: ", num)
num -= 1
print("----------num------------", num) def add():
global num
for i in range(10):
print("add: ", num)
num += 1
print("----------num------------", num) if __name__ == '__main__':
num = 0
p1 = Process(target=desc)
p2 = Process(target=add)
p1.start()
p2.start()
p1.join()
p2.join()
print(num)
进程同步,实质上是让彼此独立的进程被顺序执行,即由并发转成串行。假如要顺序的写一个文件,那么可以用互斥锁的方式实现(实现了串行),当然它也可以一个进程实现。
from multiprocessing import Process, Lock lock = Lock() # lock是全局变量,它对每个创建的进程进行管理
class Write1(Process):
def __init__(self):
super().__init__() # 这里可以self.lock = lock,但是不能用self.lock = Lock()
def run(self):
f = open("test.txt", mode="a", encoding="utf8")
lock.acquire()
for i in range(1000):
f.write("1111\r\n")
lock.release()
f.close()
class Write2(Process):
def __init__(self):
super().__init__()
def run(self):
f = open("test.txt", mode="a", encoding="utf8")
lock.acquire()
for i in range(1000):
f.write("22222222222222222\r\n")
lock.release()
f.close()
if __name__ == '__main__':
t1 = Write1()
t2 = Write2()
t1.start()
t2.start()
t1.join()
t2.join()
Condition是建立在RLock和Lock之上的进程同步类。它使得进程同步看起来扩展性更好一些。
from multiprocessing import Process, Condition
import time cond = Condition()
class P1(Process):
def __init__(self, cond):
super().__init__()
self.cond = cond
self.name = "孙先生"
def run(self):
with self.cond:
print("{}: 哟,美女呦。".format(self.name))
self.cond.notify() self.cond.wait()
print("{}: 红了好像更好呀。".format(self.name)) class P2(Process):
def __init__(self, cond):
super().__init__()
self.cond = cond
self.name = "段小姐"
def run(self):
with self.cond:
self.cond.wait()
print("{}: 呦,哟,哟,脸都红了啦。".format(self.name))
time.sleep(5)
self.cond.notify() self.cond.wait()
print("{}: 讨厌啦。".format(self.name))
self.cond.notify() if __name__ == '__main__':
p1 = P1(cond)
p2 = P2(cond)
print("p1和p2开始处理同一个事情")
p2.start()
p1.start()
4.进程池
进程池创建耗费CPU时间,并且为了维持系统稳定性,就有了进程池。进程池维持固定数量的进程数,当有任务时,进程池来调配进程处理task。它支持函数式数据的并行(串行)处理,也可以调配阻塞和非阻塞模式。所谓阻塞,即用户态向内核态发送处理请求没有立刻得到相应。所谓非阻塞,即不管内核态有没有处理完用户态请求,都要在请求超时之前返回一个状态码给用户态,用户态得到状态码可以继续执行其它任务,当内核态处理完数据时,会激活用户态事先传过来的回调函数,从而能够通知用户态超时任务已经处理完毕。用户态就可以继续执行之前的超时任务了。
multiprocess.Pool模块使用一个队列和一组线程来管理进程池。
同样以爬取天龙八部章节为例。
from multiprocessing import Process, Queue, Pool
import urllib
from bs4 import BeautifulSoup class UrlMaker(Process): # 传参的时候也可以global,甚至target都可以另写
def __init__(self, number):
super().__init__()
self.number = number
def run(self):
num = 2024334
for i in range(self.number):
url = "https://www.ybdu.com/xiaoshuo/10/10237/{}.html".format(num)
q.put(url)
print(url)
num += 1
q.put("over") def urlParser(file):
url = q.get() # 从列表中获取url
if url == "over":
return {
"code": False,
}
else:
html = urllib.request.urlopen(url) # 请求html
html_bytes = html.read() # 读取字节数据
soup = BeautifulSoup(html_bytes, "html.parser")
title = soup.find("div", attrs={"class": "h1title"}).h1.get_text()
string = soup.find("div", attrs={"class": "contentbox", "id": "htmlContent"}).get_text() # 获取小说内容
lines = string.split()
with open(file, mode="a", encoding="utf-8") as f: # 写入文件
f.write(title + "\r\n")
for i, line in enumerate(lines[: -6]):
f.write(" " + line + "\r\n")
return {
"code": True,
"url": url,
"title": title,
} def callback(msg):
if msg["code"]:
print("Process handled url: {}, title: {}.".format(msg["url"], msg["title"]))
else:
print("All urls had parsed.") if __name__ == '__main__':
q = Queue() # 创建一个队列,用于存放要请求的url
pool = Pool(3) # 创建一个进程池,用于取出url并解析和下载正文内容
p1 = UrlMaker(10) # 创建一个进程,用于向url队列中添加url
for i in range(20):
pool.apply_async(func=urlParser, args=("天龙八部1.txt",), callback=callback) # pool.apply_async: 异步非阻塞模式, 如果用pool.apply,则是阻塞模式(等价于pool.map)
# func支持函数,和args一起会创建一个进程
# callback参数是回调函数,回调函数的参数就是func执行的结果
# 它本身是一个ApplyResult对象,即 result=pool.apply_async(func, args, callback);result有自己的一些状态码
# result.get():返回结果,如果有必要则等待结果到达。
# result.ready():如果调用完成,返回True。
# result.successful():如果调用完成且没有引发异常,返回True。
# result.wait([timeout]):等待结果变为可用。
# result.terminate():立即终止所有工作进程,同时不执行任何清理或结束任何挂起工作。
p1.start()
p1.join()
pool.close() # 等待进程执行结束时关闭进程
pool.join() # 进程池对象pool常用的方法: apply_async、apply、close、join
python(十)、进程的更多相关文章
- Python之进程
进程 进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础.在早期面向进程设计的计算机结构中,进程是程序的基本执行实体:在当代 ...
- {Python之进程} 背景知识 什么是进程 进程调度 并发与并行 同步\异步\阻塞\非阻塞 进程的创建与结束 multiprocess模块 进程池和mutiprocess.Poll
Python之进程 进程 本节目录 一 背景知识 二 什么是进程 三 进程调度 四 并发与并行 五 同步\异步\阻塞\非阻塞 六 进程的创建与结束 七 multiprocess模块 八 进程池和mut ...
- python开发进程:共享数据&进程池
一,共享数据 展望未来,基于消息传递的并发编程是大势所趋 即便是使用线程,推荐做法也是将程序设计为大量独立的线程集合 通过消息队列交换数据.这样极大地减少了对使用锁定和其他同步手段的需求, 还可以扩展 ...
- 【Python】使用Supervisor来管理Python的进程
来源 : http://blog.csdn.net/xiaoguaihai/article/details/44750073 1.问题描述 需要一个python的服务程序在后台一直运行,不能让 ...
- Python:进程
由于GIL的存在,python一个进程同时只能执行一个线程.因此在python开发时,计算密集型的程序常用多进程,IO密集型的使用多线程 1.多进程创建: #创建方法1:将要执行的方法作为参数传给Pr ...
- python 守护进程 daemon
python 守护进程 daemon # -*-coding:utf-8-*- import sys, os '''将当前进程fork为一个守护进程 注意:如果你的守护进程是由inetd启动的,不要这 ...
- Python的进程与线程--思维导图
Python的进程与线程--思维导图
- Python之进程 3 - 进程池和multiprocess.Poll
一.为什么要有进程池? 在程序实际处理问题过程中,忙时会有成千上万的任务需要被执行,闲时可能只有零星任务.那么在成千上万个任务需要被执行的时候,我们就需要去创建成千上万个进程么?首先,创建进程需要消耗 ...
- Python守护进程和脚本单例运行
Python 守护进程 守护进程简介 进程运行有时候需要脱离当前运行环境,尤其是Linux和Unix环境中需要脱离Terminal运行,这个时候就要用到守护进程.守护进程可以脱离当前环境要素来执行,这 ...
随机推荐
- python UI自动化测试
为了减小维护成本: 1.UI自动化测试需要有较为稳定的环境 2.代码设计合理,那么我们就需要面向对象的设计一个框架,将重复的代码模块化 一.首先总结一下 UI自动化大概要哪些模块 1.config(配 ...
- server2012/win8 卸载.net framework 4.5后 无法进入系统桌面故障解决
故障:服务器装的是windows2012 standard(2012版本从低到高依次为Foundation.Essentials.StandardDatacenter,以及它们的升级版R2),由于要安 ...
- gitlab下载安装及部署
初次操作成功,记录一下 1. 安装依赖软件 yum -y install policycoreutils openssh-server openssh-clients postfix 2.设置 ...
- [Web UI]对比Angular/jQueryUI/Extjs:没有一个框架是万能的
Angular不能做什么?对比Angular/jQueryUI/Extjs 框架就好比兵器,你得明白你手里拿的是屠龙刀还是倚天剑,刀法主要是砍,剑法主要是刺.对于那些职业喷子和脑残粉,小僧送你们两个字 ...
- hdu 4081 Qin Shi Huang's National Road System 树的基本性质 or 次小生成树思想 难度:1
During the Warring States Period of ancient China(476 BC to 221 BC), there were seven kingdoms in Ch ...
- poj1273&&hdu1532
题解: 双倍经验 dinic模板题 然后ff过不了... 代码: #include<cstdio> #include<cstring> #include<algorith ...
- spring 核心接口之 Ordered
Spring中提供了一个Ordered接口.从单词意思就知道Ordered接口的作用就是用来排序的.Spring框架是一个大量使用策略设计模式的框架,这意味着有很多相同接口的实现类,那么必定会有优先级 ...
- LeetCode OJ:Valid Sudoku(有效数独问题)
Determine if a Sudoku is valid, according to: Sudoku Puzzles - The Rules. The Sudoku board could be ...
- CSS3径向渐变linear-gradient
语法: 选择器{ background:linear-gradien(线性渐变的方向,起点颜色,终点颜色): } 第一个参数:[可选参数,默认从上到下] 线性渐变的方向:top,bottom,left ...
- 【移动互联网开发】Zepto 使用中的一些注意点 【转】
前段时间完成了公司一个产品的 HTML5 触屏版,开发中使用了 Zepto 这个著名的 DOM 操作库. 为什么不是 jQuery 呢?因为 jQuery 的目标是兼容所有主流浏览器,这就意味着它的大 ...