Prefetch count--预取数量
一、前言
前面提到如果有多个消费者同时订阅同一个Queue中的消息,Queue中的消息会被平摊给多个消费者。这时如果每个消息的处理时间不同,就有可能会导致某些消费者一直在忙,而另外一些消费者很快就处理完手头工作并一直空闲的情况。我们可以通过设置prefetchCount来限制Queue每次发送给每个消费者的消息数,比如我们设置prefetchCount=1,则Queue每次给每个消费者发送一条消息;消费者处理完这条消息后Queue会再给该消费者发送一条消息。
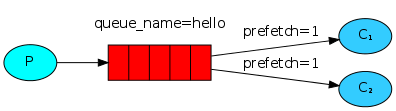
二、事例
生产端:
# -*- coding: UTF-8 -*- import pika connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost')) channel = connection.channel() # 声明队列,并进行队列持久化
channel.queue_declare(queue='task_queue', durable=True) # 信息内容
message = "Hello,World!" channel.basic_publish(exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode=2, # 消息持久化
))
print('[x] Sent %r' % message)
connection.close()
消费端:
# -*- coding: UTF-8 -*- import pika
import time
import random connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost')) channel = connection.channel() # 声明一个队列,并队列持久化
channel.queue_declare(queue='task_queue', durable=True)
print(' [*] Waiting for messages. To exit press CTRL+C') def callback(ch, method, properties, body):
print('[x] Received %r' % body)
time.sleep(random.randint(1, 20))
print('[x] Done')
# 当消息处理完成后,主动通知rabbitmq,之后rabbitmq才会删除
# 队列中的这条消息
ch.basic_ack(delivery_tag=method.delivery_tag) # prefetch_count = 1 如果消费者中有一条消息没有
# 处理完,就不会继续给这个消费者发送新消息
channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback,
queue='task_queue') # 永远收下去,没有就在这卡住
channel.start_consuming()
可以运行多个consumer,让它们不断接受消息,可以看到只有当consumer中的消息处理完成了,才会接受下一个消息。
Prefetch count--预取数量的更多相关文章
- rabbitmq qos prefetch count的设置与作用
因为原来使用了MQ作为rpc机制,随着客户交易量越来越大,很多服务器推送行情的压力很大,最近打算重写为批量模式,又重新看了下qos和prefetch设置的作用以确定优化的具体细节. 消费者在开启ack ...
- 快速入门分布式消息队列之 RabbitMQ(2)
目录 目录 前文列表 RabbitMQ 的特性 Message Acknowledgment 消息应答 Prefetch Count 预取数 RPC 远程过程调用 vhost 虚拟主机 插件系统 最后 ...
- 【RabbitMQ】Concurrency、Prefetch、exclusive
分布式消息中间件 RabbitMQ是用Erlang语言编写的分布式消息中间件,常常用在大型网站中作为消息队列来使用,主要目的是各个子系统之间的解耦和异步处理.消息中间件的基本模型是典型的生产者-消费者 ...
- mysql, count函数容易曲解的地方
统计count(*), 数量为9行; 统计count(abandonAddTime), 数量为8; 统计count(abandonUserName), 数量为9行; count(), 不能统计null ...
- oracle库两个表关联查询时用 count 报错【我】
oracle数据库,需要对两个表进行关联查询(根据两个字段),结果发现关联后不能改为 count 获取数量,报错如下: 同样的sql换到另外一个数据库就可以(只是因为数据量在千万级,所以很慢,用时40 ...
- prefetch 和 preload 及 webpack 的相关处理
使用预取和预加载是网站性能和用户体验提升的一个很好的途径,本文介绍了使用 prefetch 和 prefetch 进行预取和预加载的方法,并使用 webpack 进行实现 Link 的链接类型 < ...
- JMS ActiveMQ研究文档
1. 背景 当前,CORBA.DCOM.RMI等RPC中间件技术已广泛应用于各个领域.但是面对规模和复杂度都越来越高的分布式系统,这些技术也显示出其局限性:(1)同步通信:客户发出调用后,必须等待服务 ...
- PJSUA2开发文档--第十二章 PJSUA2 API 参考手册
12 PJSUA2 API 参考手册 12.1 endpoint.hpp PJSUA2基本代理操作. namespace pj PJSUA2 API在pj命名空间内. 12.1.1 class En ...
- Spring Boot属性文件配置文档(全部)
This sample file is meant as a guide only. Do not copy/paste the entire content into your applicatio ...
随机推荐
- 【RL系列】从蒙特卡罗方法步入真正的强化学习
蒙特卡罗方法给我的感觉是和Reinforcement Learning: An Introduction的第二章中Bandit问题的解法比较相似,两者皆是通过大量的实验然后估计每个状态动作的平均收益. ...
- [笔记] FreeBSD使用小技巧
非交互式添加用户 sed直接修改文件 sed -i '' 's/a/b/' file sed添加一行 sed '1a\ newline' file sed '1s/.*/&\'$'\nnewl ...
- Python3 迭代器和生成器
想要搞明白什么是迭代器,首先要了解几个名词:容器(container).迭代(iteration).可迭代对象(iterable).迭代器(iterator).生成器(generator). 看图是不 ...
- USACO 1.3.4 Prime Cryptarithm 牛式(模拟枚举)
Description 下面是一个乘法竖式,如果用我们给定的那n个数字来取代*,可以使式子成立的话,我们就叫这个式子牛式. * * * x * * ------- * * * * * * ------ ...
- 按照Right-BICEP要求设计四则运算3程序的单元测试用例
按照Right-BICEP要求: Right——结果是否正确? B——是否所有的边界条件都是正确的? I——能查一下反响关联吗? C——能用其它手段交叉检查一下吗? E——你是否可以强制错误条件发生? ...
- mininet实验 脚本实现控制交换机行为
写在前面 本文参考 通过这个实验,我学习到了另一种下流表的方式. 下流表有两种方式(我目前了解): 通过controller下发. 通过OvS提供的API直接向OvS交换机下流表. 本实验脚本已经把相 ...
- 404 Note Found· 第七次作业 - 需求分析报告
目录 组队后的团队项目的整体计划安排 项目logo及思维导图 项目logo 思维导图 产品思维导图 产品思维导图-引导 产品思维导图-后端数据处理.存储 产品思维导图-短信识别 产品思维导图-智能分析 ...
- Hexo博客搭建全解
[原创,转载请附网址:http://dongshuyan.top] 欢迎来到莫与的博客,第一篇记录了一下怎么写一篇博客,以方便之后写博客~ #从配置说起下载安装Git与Node.js略过 1.安装he ...
- 关于mysql无法添加中文数据的问题以及解决方案
今天弄了一天的mysql数据库,就是被一个mysql数据库乱码的问题给缠住了.现在记录一下这个问题,虽然这个问题不是什么太大的事情,但还是记录一下. 问题是这样的: 1.先在mysql的安装文件当中, ...
- inotify 工具 是一种强大的、细粒度的、异步文件系统监控机制
前言:Inotify是一种强大的.细粒度的.异步文件系统监控机制,它满足各种各样的文件监控需要,可以监控文件系统的访问属性.读写属性.权限属性.删除创建.移动等操作,也就是可以监控文件发生的一切变化. ...