data lake 新式数据仓库
Data lake - Wikipedia https://en.wikipedia.org/wiki/Data_lake
数据湖
Azure Data Lake Storage Gen2 预览版简介 | Microsoft Docs https://docs.microsoft.com/zh-cn/azure/storage/data-lake-storage/introduction
Azure Data Lake Storage Gen2 是适用于大数据分析的可高度缩放、具有成本效益的 Data Lake 解决方案。它将大规模执行和经济高效的特点融入到高性能文件系统的功能中,帮助加快见解产生的时间。Data Lake Storage Gen2 扩展了 Azure Blob 存储功能,并且针对分析工作负载进行了优化。存储数据后即可通过现有的 Blob 存储和兼容 HDFS 的文件系统接口访问这些数据,而无需更改程序或复制数据。Data Lake Storage Gen2 是最为全面的可用 Data Lake。

大数据高级分析
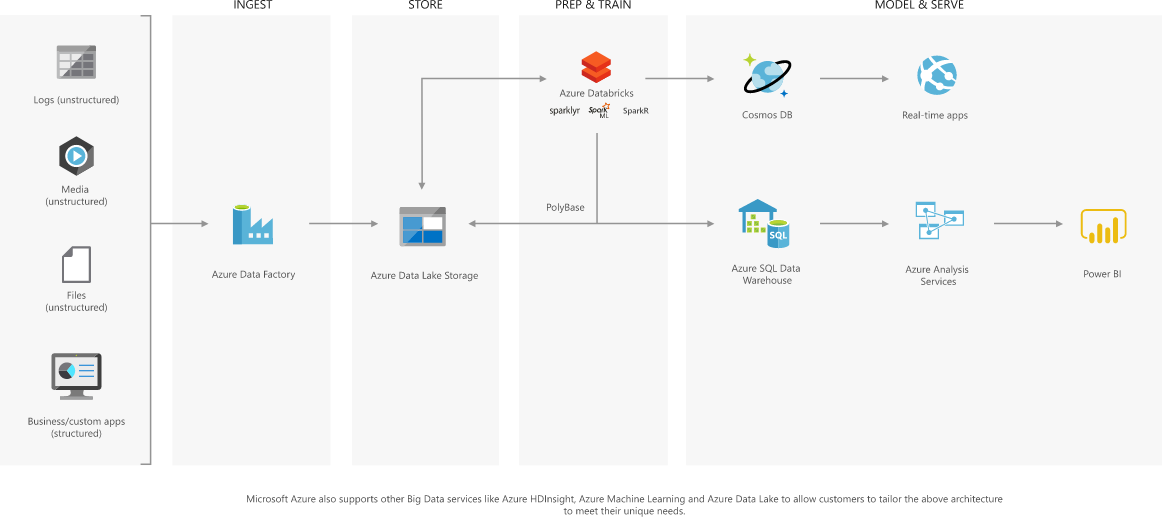
实时分析

Data lake
Jump to navigationJump to search
A data lake is a system or repository of data stored in its natural format,[1] usually object blobs or files. A data lake is usually a single store of all enterprise data including raw copies of source system data and transformed data used for tasks such as reporting, visualization, analytics and machine learning. A data lake can include structured data from relational databases (rows and columns), semi-structured data (CSV, logs, XML, JSON), unstructured data (emails, documents, PDFs) and binary data (images, audio, video). [2]
A data swamp is a deteriorated data lake that is either inaccessible to its intended users or is providing little value.[3][4]
Contents
Background
James Dixon, then chief technology officer at Pentaho, allegedly coined the term[5] to contrast it with data mart, which is a smaller repository of interesting attributes derived from raw data.[6] In promoting data lakes, he argued that data marts have several inherent problems, such as information siloing. PricewaterhouseCoopers said that data lakes could "put an end to data silos.[7] In their study on data lakes they noted that enterprises were "starting to extract and place data for analytics into a single, Hadoop-based repository." Hortonworks, Google, Oracle, Microsoft, Zaloni, Teradata, Cloudera, and Amazon now all have data lake offerings. [8]
Examples
One example of technology used to host a data lake is the distributed file system used in Apache Hadoop. Many companies also use cloud storage services such as Azure Data Lake and Amazon S3.[9] There is a gradual academic interest in the concept of data lakes, for instance, Personal DataLake[10] at Cardiff University to create a new type of data lake which aims at managing big data of individual users by providing a single point of collecting, organizing, and sharing personal data.[11] An earlier data lake (Hadoop 1.0) had limited capabilities with its batch oriented processing (MapReduce) and was the only processing paradigm associated with it. Interacting with the data lake meant you had to have expertise in Java with map reduce and higher level tools like Apache Pig and Apache Hive (which by themselves were batch oriented).
Criticism
In June 2015, David Needle characterized "so-called data lakes" as "one of the more controversial ways to manage big data".[12] PricewaterhouseCoopers were also careful to note in their research that not all data lake initiatives are successful. They quote Sean Martin, CTO of Cambridge Semantics,
| “ | We see customers creating big data graveyards, dumping everything into HDFS [Hadoop Distributed File System] and hoping to do something with it down the road. But then they just lose track of what’s there. The main challenge is not creating a data lake, but taking advantage of the opportunities it presents.[7] |
” |
They describe companies that build successful data lakes as gradually maturing their lake as they figure out which data and metadata are important to the organization. One other criticism about the data lake is that the concept is fuzzy and arbitrary. It refers to any tool or data management practice that does not fit into the traditional data warehouse architecture. The data lake has been referred to as a technology such as Hadoop. The data lake has been labeled as a raw data reservoir or a hub for ETL offload. The data lake has been defined as a central hub for self-service analytics. The concept of the data lake has been overloaded with meanings, which puts the usefulness of the term into question.[13]
data lake 新式数据仓库的更多相关文章
- 构建企业级数据湖?Azure Data Lake Storage Gen2不容错过(上)
背景 相较传统的重量级OLAP数据仓库,“数据湖”以其数据体量大.综合成本低.支持非结构化数据.查询灵活多变等特点,受到越来越多企业的青睐,逐渐成为了现代数据平台的核心和架构范式. 数据湖的核心功能, ...
- 构建企业级数据湖?Azure Data Lake Storage Gen2实战体验(中)
引言 相较传统的重量级OLAP数据仓库,“数据湖”以其数据体量大.综合成本低.支持非结构化数据.查询灵活多变等特点,受到越来越多企业的青睐,逐渐成为了现代数据平台的核心和架构范式. 因此数据湖相关服务 ...
- 构建企业级数据湖?Azure Data Lake Storage Gen2实战体验(下)
相较传统的重量级OLAP数据仓库,“数据湖”以其数据体量大.综合成本低.支持非结构化数据.查询灵活多变等特点,受到越来越多企业的青睐,逐渐成为了现代数据平台的核心和架构范式. 作为微软Azure上最新 ...
- Azure Data Lake Storage Gen2实战体验
相较传统的重量级OLAP数据仓库,“数据湖”以其数据体量大.综合成本低.支持非结构化数据.查询灵活多变等特点,受到越来越多企业的青睐,逐渐成为了现代数据平台的核心和架构范式. 作为微软Azure上最新 ...
- 场景4 Data Warehouse Management 数据仓库
场景4 Data Warehouse Management 数据仓库 parallel 4 100% —> 必须获得指定的4个并行度,如果获得的进程个数小于设置的并行度个数,则操作失败 para ...
- Data Lake Analytics的Geospatial分析函数
0. 简介 为满足部分客户在云上做Geometry数据的分析需求,阿里云Data Lake Analytics(以下简称:DLA)支持多种格式的地理空间数据处理函数,符合Open Geospatial ...
- Data Lake Analytics + OSS数据文件格式处理大全
0. 前言 Data Lake Analytics是Serverless化的云上交互式查询分析服务.用户可以使用标准的SQL语句,对存储在OSS.TableStore上的数据无需移动,直接进行查询分析 ...
- Modern Data Lake with Minio : Part 2
转自: https://blog.minio.io/modern-data-lake-with-minio-part-2-f24fb5f82424 In the first part of this ...
- Modern Data Lake with Minio : Part 1
转自:https://blog.minio.io/modern-data-lake-with-minio-part-1-716a49499533 Modern data lakes are now b ...
随机推荐
- redis 做为缓存服务器 注项!
作为缓存服务器,如果不加以限制内存的话,就很有可能出现将整台服务器内存都耗光的情况,可以在redis的配置文件里面设置: # maxmemory <bytes> #限定最多使用1.5GB内 ...
- Java的==与equals之辨,简单解释,很清楚
"=="和equals方法究竟有什么区别? (单独把一个东西说清楚,然后再说清楚另一个,这样,它们的区别自然就出来了,混在一起说,则很难说清楚) ==操作符专门用来比较两个变量的值 ...
- 人工打jar包
(一)将可执行程序打成一个jar包 其中Yoyo为入口程序,因此将当前目录下workhard和Book.class.testEx.class.Yoyo.class打成一个jar包的命令如下: jar ...
- python把中文文档变为拼音
缘由 新看到的一篇文章,被吓尿.Text Understanding from Scratch,认为word的cnn抽象能力还不够好,使用character来做cnn效果更佳.结果是,由于论文的使用的 ...
- na+mb与gcd
蒜头君和花椰妹在玩一个游戏,他们在地上将 nn 颗石子排成一排,编号为 11 到 nn.开始时,蒜头君随机取出了 22 颗石子扔掉,假设蒜头君取出的 22 颗石子的编号为 aa, bb.游戏规则如下, ...
- 上传绕过WAF几种常见的姿势
1:WTS-WAF 绕过上传原内容:Content-Disposition: form-data; name="up_picture"; filename="xss.ph ...
- 当心文件 I/O 有错误
当心文件 I/O 有错误. #include <iostream> #include <iostream> #include <numeric> #include ...
- 手机游戏运营主要的指标是什么? 7天活跃, 14天活跃 ARPU ?如何提升游戏 app 的虚拟道具的收入?
数据采集越细,手段越丰富,所获得的数据也就更加详实,虽然手机游戏没有网游那么复杂,但也需要数据化运营,而且是必要的,是优化游戏收入的关键,大家最主要关心的是下面三类数据的指标 1. 用户数量首先,在移 ...
- hdu 3336:Count the string(数据结构,串,KMP算法)
Count the string Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) ...
- RabbitMQ之Queues-5
工作队列的主要任务是:避免立刻执行资源密集型任务,然后必须等待其完成.相反地,我们进行任务调度:我们把任务封装为消息发送给队列.工作进行在后台运行并不断的从队列中取出任务然后执行.当你运行了多个工作进 ...