数据重塑图解—Pivot, Pivot-Table, Stack and Unstack
Pivot
pivot函数用于创建一个新的派生表,该函数有三个参数:index, columns和values。你需要在原始表中指定这三个参数所对定的列名,接下来pivot函数会创建一个新的表格,其中行索引和列索引都是唯一标示值,表格中的数值由原始表中参数value对应的数据所表示。
from collections import OrderedDictfrom pandas import DataFrameimport pandas as pdimport numpy as nptable = OrderedDict(( # 有序字典("Item",['Item0','Item0','Item1','Item1']), # 相当于df中的一列("CType",['Gold','Bronze','Gold','Silver']),("USD",['1$','2$','3$','4$']),("EU",['1€','2€','3€','4€'])))d = DataFrame(table)
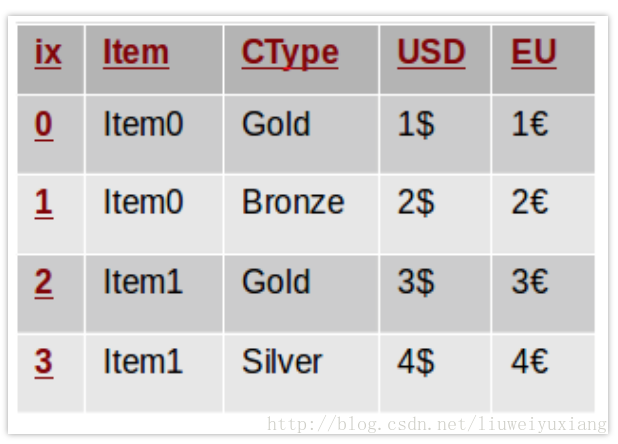
其中 item 表示商品名称,USD 表示商品的美元价格,EU 表示欧元价格,CType 表示每个客户对应的类别。在这个表格中,我们很难观测到商品的美元价格在不同的客户中是如何变化的。此时我们倾向于重塑表格,使得所有的价格信息都按行排列:
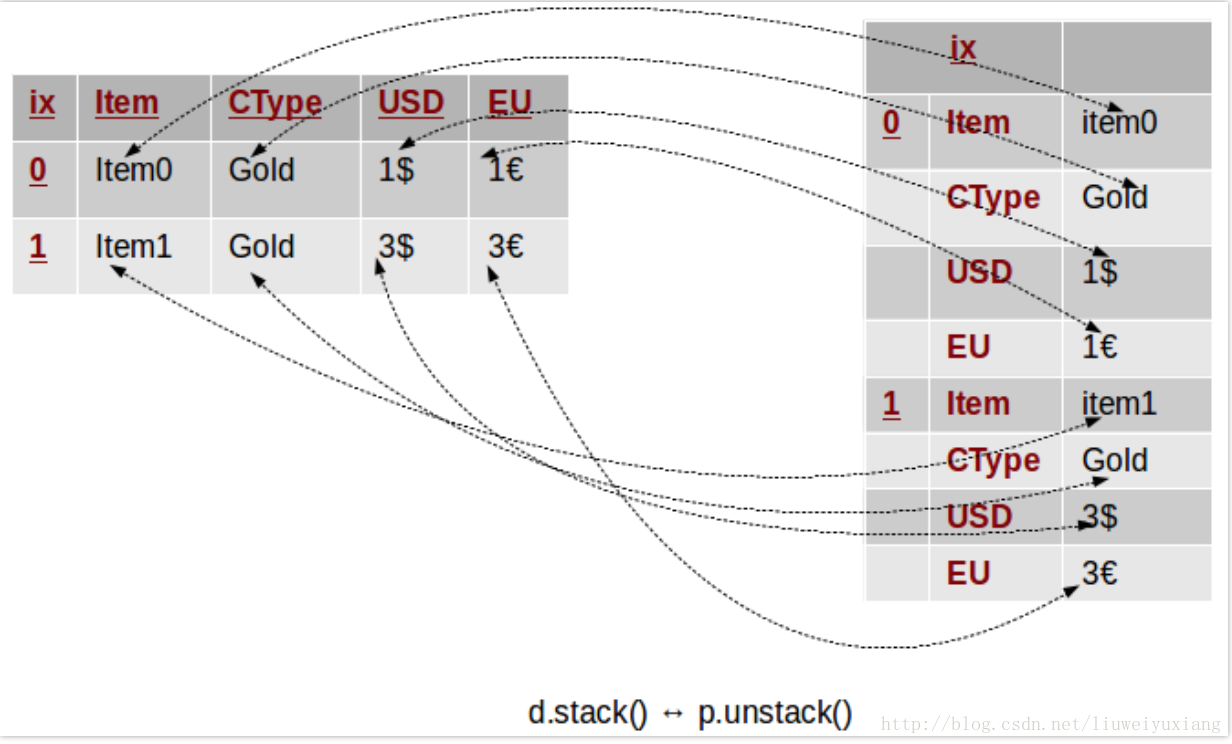
p = d.pivot(index='Item', columns='CType', values='USD')
上述命令创建了一个新的表格,其中列索引是 CType 中的唯一值,行索引是 Item 中的唯一值,表格中的数值由 USD 来填充。下图形象地展示了这个过程:

下述代码介绍了如何分别从原始表和新表中查询数据:
# Original DataFrame: Access the USD cost of Item0 for Gold customersprint(d[(d.Item=='Item0') & (d.CType=='Gold')].USD.values)# Pivoted DataFrame: Access the USD cost of Item0 for Gold customersprint(p[p.index=='Item0'].Gold.values)
需要注意的是,该数据透视表中没有包含欧元价格的任何信息。事实上,数据透视表是原始表格的简化版本,它只包含我们所关心的变量信息。
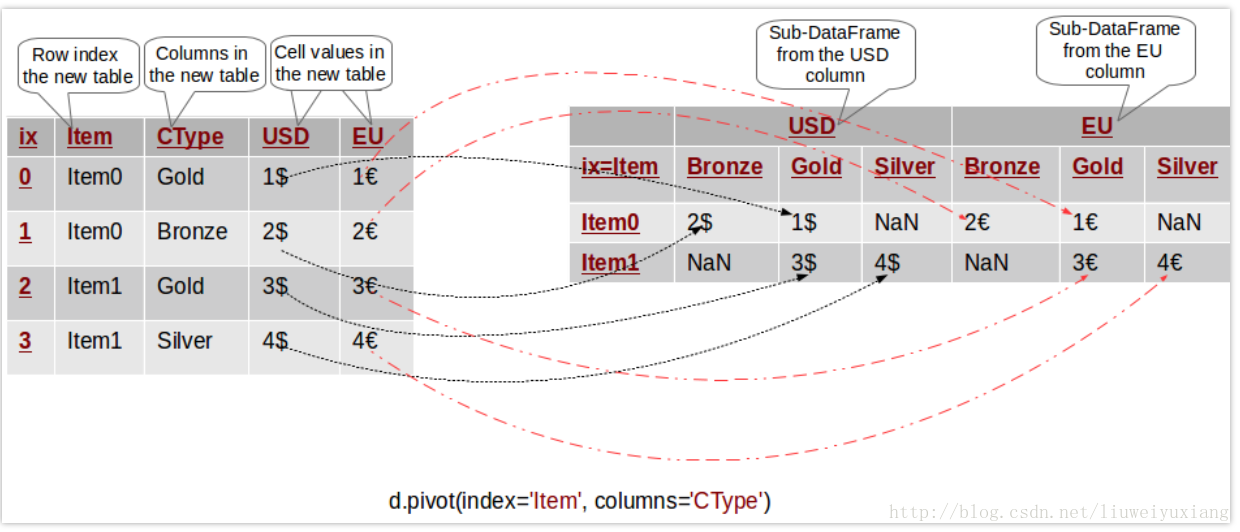
现在我们对上述案例进行拓展,我们想将每个商品的欧元价格信息也纳入数据透视表中(Pivoting By Multiple Columns)。这非常容易实现——我们只需将 values 参数删掉即可:
p = d.pivot(index='Item', columns='CType')
此时,Pandas会在新表格中创建一个分层列索引。你可以将分层索引想象成一个树形索引,每个行/列索引都由从最顶层的索引到底部索引的路径所组成。最顶层的索引由pivot函数中没有定义的参数所组成——比如本例中的 USD 和 EU,第二层索引表示对应列中的所有唯一值。下图形象地展示了该过程:
我们可以利用分层索引从原始表中过滤出某个变量的数据。比如p.USD将返回只包含 USD 数据的数据透视表,p.USD.Bronze将上述透视表中的第一列筛选出来。
# Original DataFrame: Access the USD cost of Item0 for Gold customersprint(d[(d.Item=='Item0')&(d.CType=='Gold')].USD.values)# Pivoted DataFrame: p.USD gives a "sub-DataFrame" with the USD values onlyprint(p.USD[p.USD.index=='Item0'].Gold.values)
常见错误
从上文的描述中我们可以看出:pivot方法至少需要两个参数—— index 和 columns。那么如果原始数据集中存在重复条目时,重塑过程将会发生什么问题呢?pivot函数如何确定数据透视表中的数值呢?下图形象地展示了这个问题:
在这个案例中,原始数据集中存在重复条目,此时pivot函数无法确定数据透视表中的数值,它会返回一个错误信息:ValueError: Index contains duplicate entries, cannot reshape
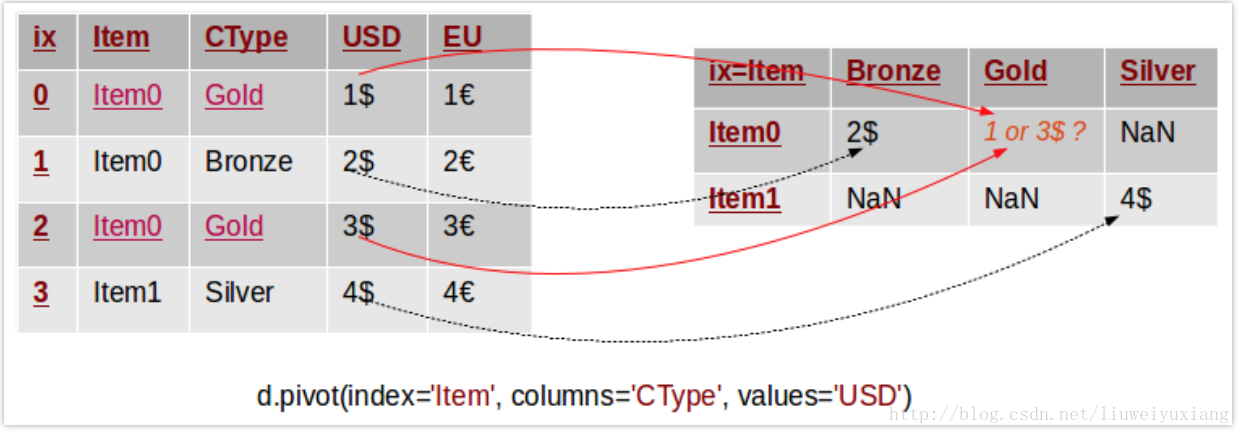
因此,我们在调用pivot方法前需要保证数据集中不存在重复条目,否则我们需要调用另外一个方法——pivot_table。
Pivot Table
pivot_table方法可以用来解决上述问题,与pivot相比,该方法可以汇总多个重复条目的数据。换句话说,在前面的例子中,我们可以用均值、中位数或者其他汇总函数来计算重复条目的数值。下图形象地展示了这个过程:
注意,在这个例子中,我们移除了数据集中的美元和欧元符号。原始数据集中存在两行重复条目,我们利用样本均值来填充数据透视表中的数据。pivot_table方法需要传递一个新的参数 aggfunc,该参数用于指明转换时所需的汇总函数。
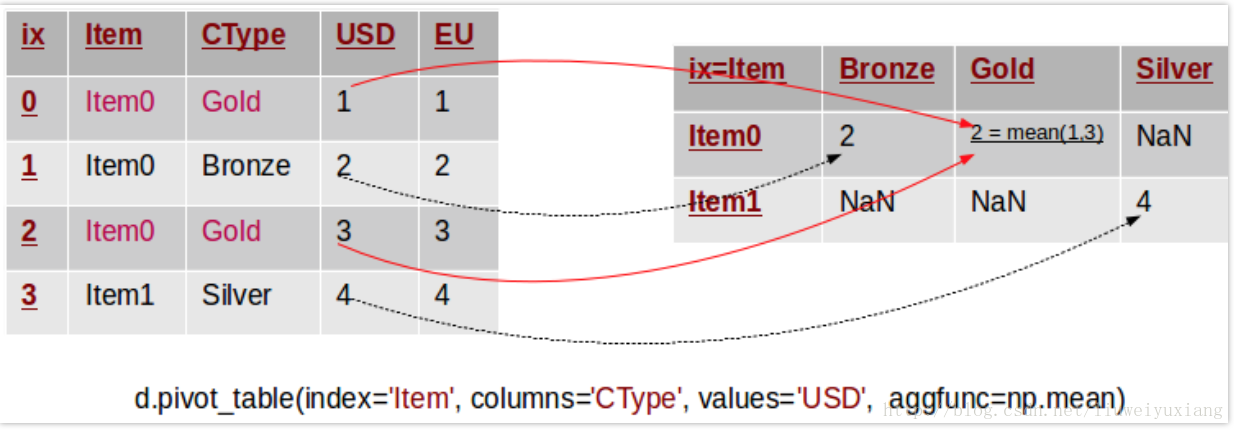
table = OrderDict((('Item',['Item0','Item0','Item0','Item1']),('CType',['Gold','Bronze','Gold','Silver']),('USD',[1,2,3,4]),('EU',[1.1,2.2,3.3,4.4])))d = DataFrame(table)p=d.pivot_table(index='Item',columns='CType',values='USD', aggfunc=np.mean)
从本质上来说,pivot_table方法是pivot的通用版,该方法可以汇总重复条目的数据。
Stack/Unstack
实际上,轴向旋转(pivot)运算是堆叠(stack)过程的特例。首先假设原始数据集中的行列索引中均为层次索引。stack 过程表示将数据集的列旋转为行,同理 unstack 过程表示将数据的行旋转为列。下图形象地展示了该过程:
在这个例子中,我们看到原始数据集中的行列索引都由二级分层索引组成。堆叠过程主要是将最内层的列索引转换成最内层的行索引,然后再重新安排单元格中的数据。相反地,unstack 过程是讲最内层的行索引移到最内层的列索引中。
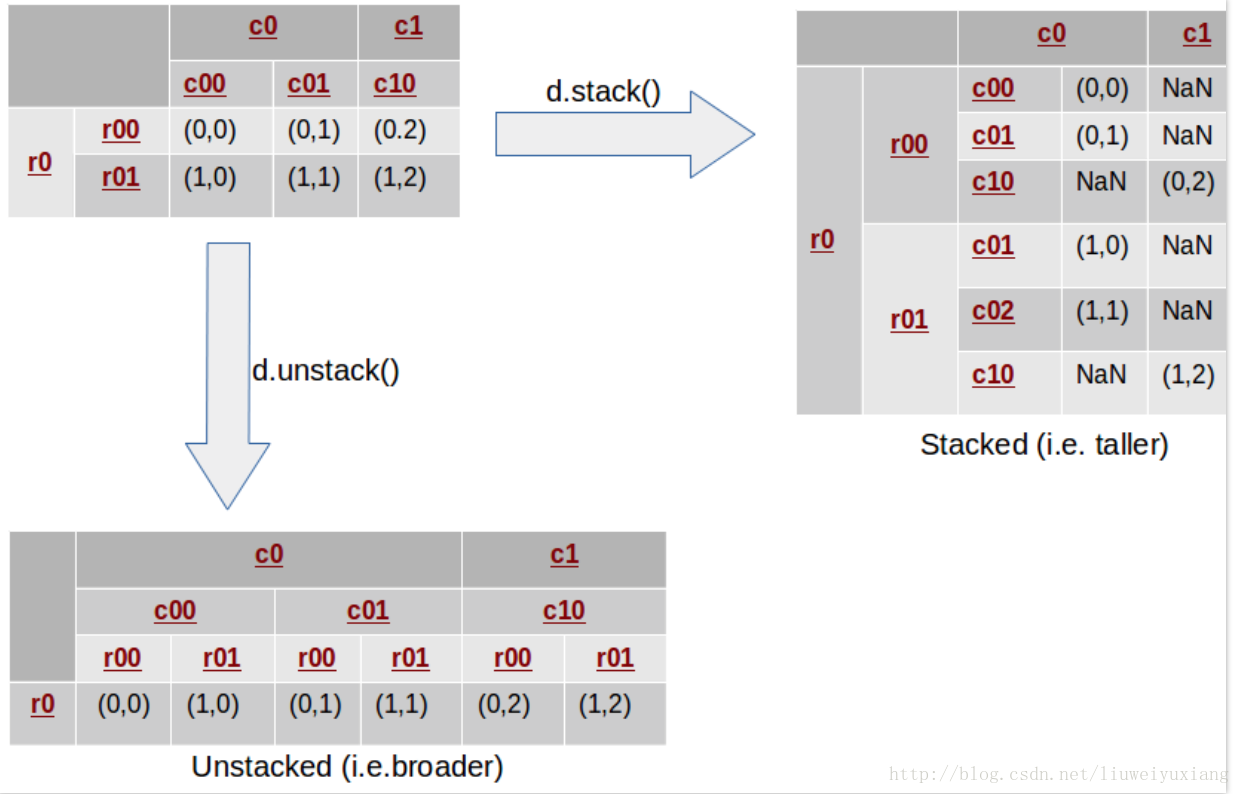
因此,我们可以发现 stack 使得数据集变得更长,unstack 使得数据集变得更宽。
# Row Multi-Indexrow_idx_arr = list(zip(['r0','r0'],['r-00','r-01']))row_idx = pd.MultiIndex.from_tuples(row_idx_arr)# Column Multi-Indexcol_idx_arr = lis(zip(['c0','c0','c1'], ['c-00','c-01','c-10']))col_idx = pd.MultiIndex.from_tuples(col_idx_arr)# Create the DataFramed = DataFrame(np.arange(6).reshape(2,3),index=row_idx, columns=col_idx)d = d.applymap(lambda x: (x // 3, x % 3))# Stack/Unstacks = d.stack()u = d.unstack()
事实上,Pandas允许我们利用 stack/unstack 处理任一等级的索引。因此虽然默认设定处理最内层的索引,但是在上述的例子中,我们也可以处理最外层的索引。
Stacking 和 Unstacking 也可以运用到单层索引的数据集中,如下图所示:
1 Pandas中的数据重塑(reshape)功能
2 Reshaping in Pandas - Pivot, Pivot-Table, Stack and Unstack explained with Pictures
转自 https://blog.csdn.net/liuweiyuxiang/article/details/78220530
数据重塑图解—Pivot, Pivot-Table, Stack and Unstack的更多相关文章
- pandas学习(创建多层索引、数据重塑与轴向旋转)
pandas学习(创建多层索引.数据重塑与轴向旋转) 目录 创建多层索引 数据重塑与轴向旋转 创建多层索引 隐式构造 Series 最常见的方法是给DataFrame构造函数的index参数传递两个或 ...
- R语言数据重塑cbind+rbind+merge+ melt+cast
R语言中的数据重塑是关于变化的数据分为行和列的方式.大多数R地数据处理的时候是通过将输入的数据作为一个数据帧进行.这是很容易提取一个数据帧的行和列数据,但在某些情况,当我们需要的数据帧的格式是不同的来 ...
- MySQL触发器更新本表数据异常:Can't update table 'tbl' in stored function/trigger because it
MySQL触发器更新本表数据异常:Can't update table 'tbl' in stored function/trigger because it 博客分类: 数据库 MySQLJava ...
- R语言 数据重塑
R语言数据重塑 R语言中的数据重塑是关于改变数据被组织成行和列的方式. 大多数时间R语言中的数据处理是通过将输入数据作为数据帧来完成的. 很容易从数据帧的行和列中提取数据,但是在某些情况下,我们需要的 ...
- MySQL数据库插入数据出现 ERROR 1526 (HY000): Table has no partition for value xxx
MySQL数据库插入数据出现ERROR 1526 (HY000): Table has no partition for value xxx工作的时候发现无法插入数据,报错:ERROR 1526 (H ...
- python pandas stack和unstack函数
在用pandas进行数据重排时,经常用到stack和unstack两个函数.stack的意思是堆叠,堆积,unstack即"不要堆叠",我对两个函数是这样理解和区分的. 常见的数据 ...
- Pandas 基础(12) - Stack 和 Unstack
这节的主题是 stack 和 unstack, 我目前还不知道专业领域是怎么翻译的, 我自己理解的意思就是"组成堆"和"解除堆". 其实, 也是对数据格式的一种 ...
- 利用Python进行数据分析(13) pandas基础: 数据重塑/轴向旋转
重塑定义 重塑指的是将数据重新排列,也叫轴向旋转. DataFrame提供了两个方法: stack: 将数据的列“旋转”为行. unstack:将数据的行“旋转”为列. 例如: 处理堆叠格式 ...
- R中的数据重塑函数
1.去除重复数据 函数:duplicated(x, incomparables = FALSE, MARGIN = 1,fromLast = FALSE, ...),返回一个布尔值向量,重复数据的第一 ...
随机推荐
- 数据绑定-绑定Servlet内置对象
数据绑定:获取用户提交的参数,绑定到入参的参数中,就叫数据绑定. 绑定Servlet内置对象: 测试:
- POJ题解Sorting It All Out-传递丢包+倍增
题目链接: http://poj.org/problem?id=1094 题目大意(直接从谷歌翻译上复制下来的): 描述 不同值的递增排序顺序是其中使用某种形式的小于运算符来将元素从最小到最大排序的顺 ...
- Centos7:mysql5.6安装,配置及使用(RPM方式)
1.首先安装好jdk环境,本机所用环境为jdk1.8 2.卸载MariaDB(Centos7自带)与Mysql 2.1卸载:MariaDB #rpm -qa | grep -i mariadb //查 ...
- python进阶资源
本文为不同阶段的Python学习者从不同角度量身定制了49个学习资源. 初学者 Welcome to Python.org https://www.python.org/ 官方Python站点提供了一 ...
- vue项目-axios封装、easy-mock使用
vue全家桶概括下来就是 项目构建工具(vue-cli) 路由(vue-router) 状态管理(vuex) http请求工具 vue有自己的http请求工具插件vue-resource,但是vue2 ...
- 使用CSS设置背景图片,图片比较大,完全显示在一个DIV中
做的时候想要边框为比较好看的样式,需要UI切图并且放在div中,看起来会好看点 像这样的,我随便挑选了一个,UI帮我切图出来 需要把这个图片填到相应的div里面,但是很显然碰到一个问题,图片太大,而且 ...
- 使用Django的ORM详细操作
1.自己动手创建数据库 create database 数据库名; 2.在Django项目中设置连接数据库的相关配置(告诉Django连接哪一个数据库) #在数据库相关的配置 DATABASES = ...
- Linux系统吃“内存”现象
而当我们使用free命令查看Linux系统内存使用情况时,会发现内存使用一直处于较高的水平,即使此时系统并没有运行多少软件.这正是Windows和Linux在内存管理上的区别,乍一看,Linux系统吃 ...
- 为Redis设置登录密码并使用密码登录
https://www.cnblogs.com/756623607-zhang/p/6859540.html 密码登录Redis redis-cli -h 127.0.0.1 -p 6379 -a & ...
- 《编译原理》-用例题理解-自底向上的语法分析,FIRSTVT,LASTVT集
<编译原理>-用例题理解-自底向上的语法分析,FIRSTVT,LASTVT集 上一篇:编译原理-用例题理解-自顶向下语法分析及 FIRST,FOLLOW,SELECT集,LL(1)文法 本 ...