线性回归和正则化(Regularization)
python风控建模实战lendingClub(博主录制,包含大量回归建模脚本和和正则化解释,2K超清分辨率)
https://study.163.com/course/courseMain.htm?courseId=1005988013&share=2&shareId=400000000398149

微信扫二维码,免费学习更多python资源

转载http://blog.csdn.net/u013363719/article/details/22752893
http://www.cnblogs.com/jianxinzhou/p/4083921.html
1. The Problem of Overfitting
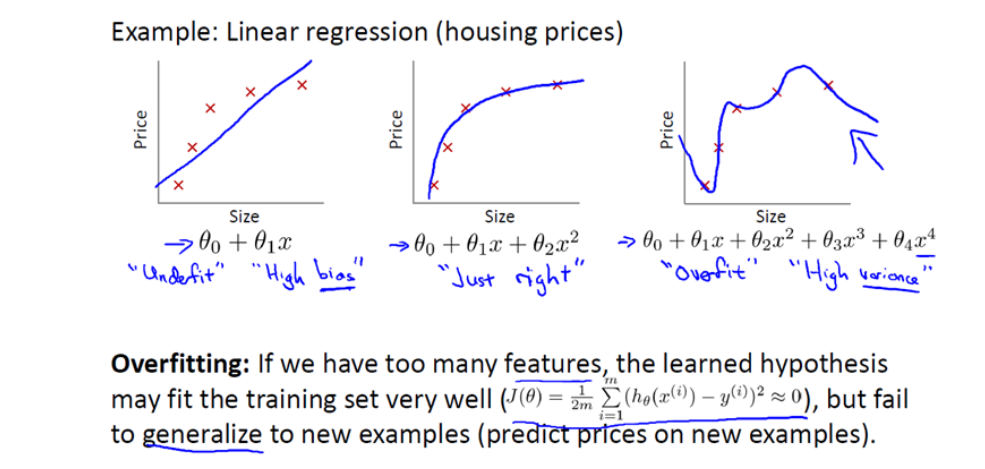
1
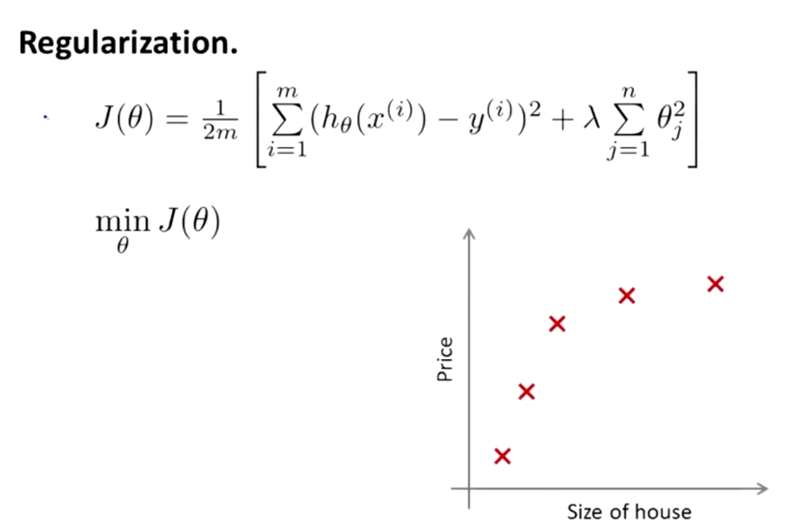
还是来看预测房价的这个例子,我们先对该数据做线性回归,也就是左边第一张图。
如果这么做,我们可以获得拟合数据的这样一条直线,但是,实际上这并不是一个很好的模型。我们看看这些数据,很明显,随着房子面积增大,住房价格的变化趋于稳定或者说越往右越平缓。因此线性回归并没有很好拟合训练数据。
我们把此类情况称为欠拟合(underfitting),或者叫作叫做高偏差(bias)。
这两种说法大致相似,都表示没有很好地拟合训练数据。高偏差这个词是 machine learning 的研究初期传下来的一个专业名词,具体到这个问题,意思就是说如果用线性回归这个算法去拟合训练数据,那么该算法实际上会产生一个非常大的偏差或者说存在一个很强的偏见。
第二幅图,我们在中间加入一个二次项,也就是说对于这幅数据我们用二次函数去拟合。自然,可以拟合出一条曲线,事实也证明这个拟合效果很好。
另一个极端情况是,如果在第三幅图中对于该数据集用一个四次多项式来拟合。因此在这里我们有五个参数θ0到θ4,这样我们同样可以拟合一条曲线,通过我们的五个训练样本,我们可以得到如右图的一条曲线。
一方面,我们似乎对训练数据做了一个很好的拟合,因为这条曲线通过了所有的训练实例。但是,这实际上是一条很扭曲的曲线,它不停上下波动。因此,事实上我们并不认为它是一个预测房价的好模型。
所以,我们把这类情况叫做过拟合(overfitting),也叫高方差(variance)。
与高偏差一样,高方差同样也是一个历史上的叫法。从第一印象上来说,如果我们拟合一个高阶多项式,那么这个函数能很好的拟合训练集(能拟合几乎所有的训练数据),但这也就面临函数可能太过庞大的问题,变量太多。
同时如果我们没有足够的数据集(训练集)去约束这个变量过多的模型,那么就会发生过拟合。
2
过度拟合的问题通常发生在变量(特征)过多的时候。这种情况下训练出的方程总是能很好的拟合训练数据,也就是说,我们的代价函数可能非常接近于 0 或者就为 0。
但是,这样的曲线千方百计的去拟合训练数据,这样会导致它无法泛化到新的数据样本中,以至于无法预测新样本价格。在这里,术语"泛化"指的是一个假设模型能够应用到新样本的能力。新样本数据是指没有出现在训练集中的数据。
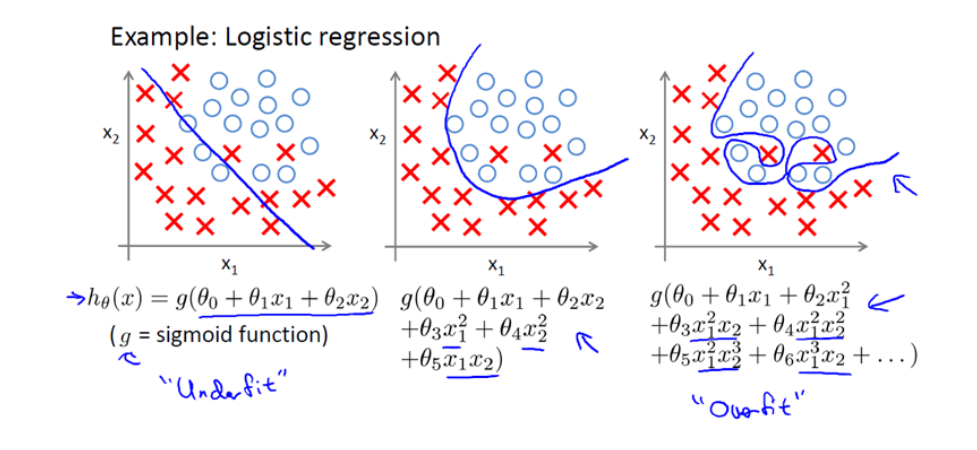
之前,我们看到了线性回归情况下的过拟合。类似的情况也适用于逻辑回归。
3
那么,如果发生了过拟合问题,我们应该如何处理?
过多的变量(特征),同时只有非常少的训练数据,会导致出现过度拟合的问题。因此为了解决过度拟合,有以下两个办法。

方法一:尽量减少选取变量的数量
具体而言,我们可以人工检查每一项变量,并以此来确定哪些变量更为重要,然后,保留那些更为重要的特征变量。至于,哪些变量应该舍弃,我们以后在讨论,这会涉及到模型选择算法,这种算法是可以自动选择采用哪些特征变量,自动舍弃不需要的变量。这类做法非常有效,但是其缺点是当你舍弃一部分特征变量时,你也舍弃了问题中的一些信息。例如,也许所有的特征变量对于预测房价都是有用的,我们实际上并不想舍弃一些信息或者说舍弃这些特征变量。
方法二:正则化
正则化中我们将保留所有的特征变量,但是会减小特征变量的数量级(参数数值的大小θ(j))。
这个方法非常有效,当我们有很多特征变量时,其中每一个变量都能对预测产生一点影响。正如我们在房价预测的例子中看到的那样,我们可以有很多特征变量,其中每一个变量都是有用的,因此我们不希望把它们删掉,这就导致了正则化概念的发生。
接下来我们会讨论怎样应用正则化和什么叫做正则化均值,然后将开始讨论怎样使用正则化来使学习算法正常工作,并避免过拟合。
2. Cost Function
1
在前面的介绍中,我们看到了如果用一个二次函数来拟合这些数据,那么它给了我们一个对数据很好的拟合。然而,如果我们用一个更高次的多项式去拟合,最终我们可能会得到一个曲线,它能很好地拟合训练集,但却并不是一个好的结果,因为它过度拟合了数据,因此,一般性并不是很好。
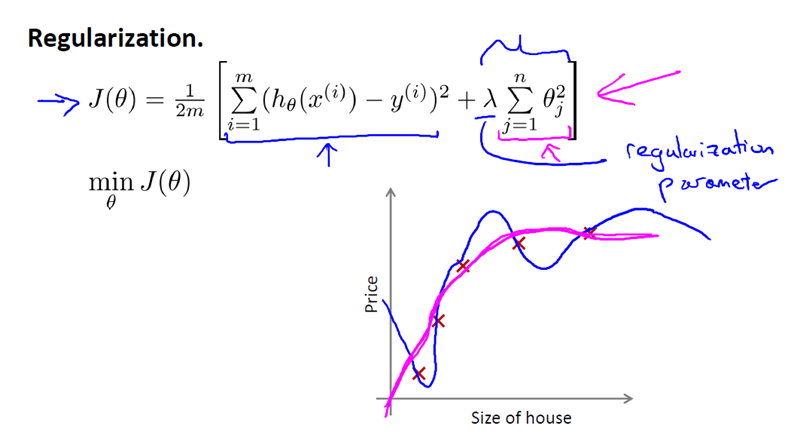
让我们考虑下面的假设,我们想要加上惩罚项,从而使参数 θ3 和 θ4 足够的小。
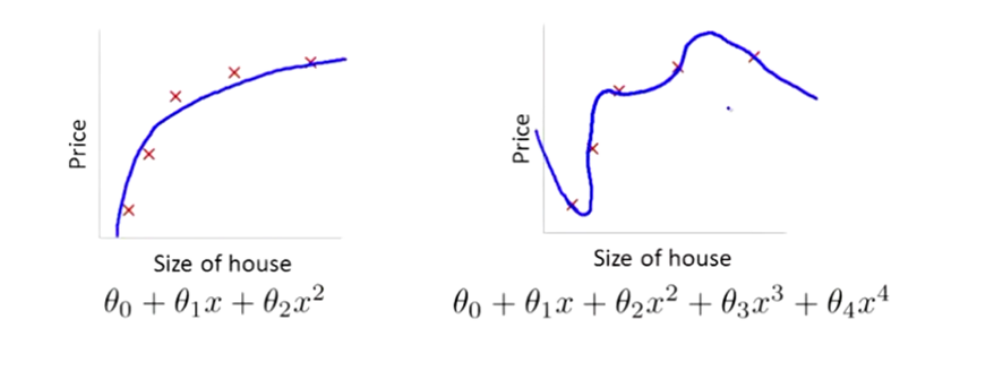
这里我的意思就是,上图的式子是我们的优化目标,也就是说我们需要尽量减少代价函数的均方误差。
对于这个函数我们对它添加一些项,加上 1000 乘以 θ3 的平方,再加上 1000 乘以 θ4 的平方,
1000 只是我随便写的某个较大的数字而已。现在,如果我们要最小化这个函数,那么为了最小化这个新的代价函数,我们要让 θ3 和 θ4 尽可能小。因为,如果你在原有代价函数的基础上加上 1000 乘以 θ3 这一项 ,那么这个新的代价函数将变得很大,所以,当我们最小化这个新的代价函数时, 我们将使 θ3 的值接近于 0,同样 θ4 的值也接近于 0,就像我们忽略了这两个值一样。如果我们做到这一点( θ3 和 θ4 接近 0 ),那么我们将得到一个近似的二次函数。
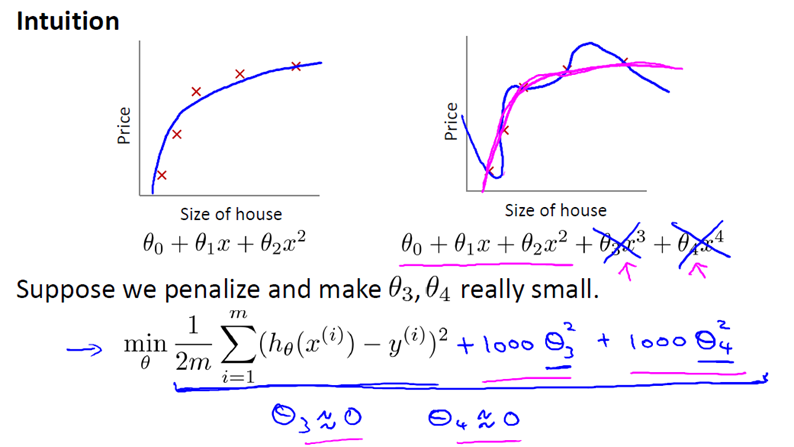
因此,我们最终恰当地拟合了数据,我们所使用的正是二次函数加上一些非常小,贡献很小项(因为这些项的 θ3、 θ4 非常接近于0)。显然,这是一个更好的假设。
2

更一般地,这里给出了正规化背后的思路。这种思路就是,如果我们的参数值对应一个较小值的话(参数值比较小),那么往往我们会得到一个形式更简单的假设。
在我们上面的例子中,我们惩罚的只是 θ3 和 θ4 ,使这两个值均接近于零,从而我们得到了一个更简单的假设,实际上这个假设大抵上是一个二次函数。
但更一般地说,如果我们像惩罚 θ3 和 θ4 这样惩罚其它参数,那么我们往往可以得到一个相对较为简单的假设。
实际上,这些参数的值越小,通常对应于越光滑的函数,也就是更加简单的函数。因此 就不易发生过拟合的问题。
我知道,为什么越小的参数对应于一个相对较为简单的假设,对你来说现在不一定完全理解,但是在上面的例子中使 θ3 和 θ4 很小,并且这样做能给我们一个更加简单的假设,这个例子至少给了我们一些直观感受。
来让我们看看具体的例子,对于房屋价格预测我们可能有上百种特征,与刚刚所讲的多项式例子不同,我们并不知道 θ3 和 θ4 是高阶多项式的项。所以,如果我们有一百个特征,我们并不知道如何选择关联度更好的参数,如何缩小参数的数目等等。
因此在正则化里,我们要做的事情,就是把减小我们的代价函数(例子中是线性回归的代价函数)所有的参数值,因为我们并不知道是哪一个或哪几个要去缩小。
因此,我们需要修改代价函数,在这后面添加一项,就像我们在方括号里的这项。当我们添加一个额外的正则化项的时候,我们收缩了每个参数。
顺便说一下,按照惯例,我们没有去惩罚 θ0,因此 θ0 的值是大的。这就是一个约定从 1 到 n 的求和,而不是从 0 到 n 的求和。但其实在实践中
这只会有非常小的差异,无论你是否包括这 θ0 这项。但是按照惯例,通常情况下我们还是只从 θ1 到 θn 进行正则化。
下面的这项就是一个正则化项
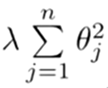
并且 λ 在这里我们称做正则化参数。
λ 要做的就是控制在两个不同的目标中的平衡关系。
第一个目标就是我们想要训练,使假设更好地拟合训练数据。我们希望假设能够很好的适应训练集。
而第二个目标是我们想要保持参数值较小。(通过正则化项)
而 λ 这个正则化参数需要控制的是这两者之间的平衡,即平衡拟合训练的目标和保持参数值较小的目标。从而来保持假设的形式相对简单,来避免过度的拟合。
对于我们的房屋价格预测来说,我们之前所用的非常高的高阶多项式来拟合,我们将会得到一个非常弯曲和复杂的曲线函数,现在我们只需要使用正则化目标的方法,那么你就可以得到一个更加合适的曲线,但这个曲线不是一个真正的二次函数,而是更加的流畅和简单的一个曲线。这样就得到了对于这个数据更好的假设。
再一次说明下,这部分内容的确有些难以明白,为什么加上参数的影响可以具有这种效果?但如果你亲自实现了正规化,你将能够看到这种影响的最直观的感受。
3

在正则化线性回归中,如果正则化参数值 λ 被设定为非常大,那么将会发生什么呢?
我们将会非常大地惩罚参数θ1 θ2 θ3 θ4 … 也就是说,我们最终惩罚θ1 θ2 θ3 θ4 … 在一个非常大的程度,那么我们会使所有这些参数接近于零。

如果我们这么做,那么就是我们的假设中相当于去掉了这些项,并且使我们只是留下了一个简单的假设,这个假设只能表明房屋价格等于 θ0 的值,那就是类似于拟合了一条水平直线,对于数据来说这就是一个欠拟合 (underfitting)。这种情况下这一假设它是条失败的直线,对于训练集来说这只是一条平滑直线,它没有任何趋势,它不会去趋向大部分训练样本的任何值。
这句话的另一种方式来表达就是这种假设有过于强烈的"偏见" 或者过高的偏差 (bais),认为预测的价格只是等于 θ0 。对于数据来说这只是一条水平线。
因此,为了使正则化运作良好,我们应当注意一些方面,应该去选择一个不错的正则化参数
λ 。当我们以后讲到多重选择时我们将讨论一种方法来自动选择正则化参数 λ
,为了使用正则化,接下来我们将把这些概念应用到到线性回归和逻辑回归中去,那么我们就可以让他们避免过度拟合了。
3. Regularized Linear Regression
之前我们已经介绍过,岭回归的代价函数如下:

对于线性回归(的求解),我们之前运用了两种学习算法,一种基于梯度下降,一种基于正规方程。
1
梯度下降,如下:
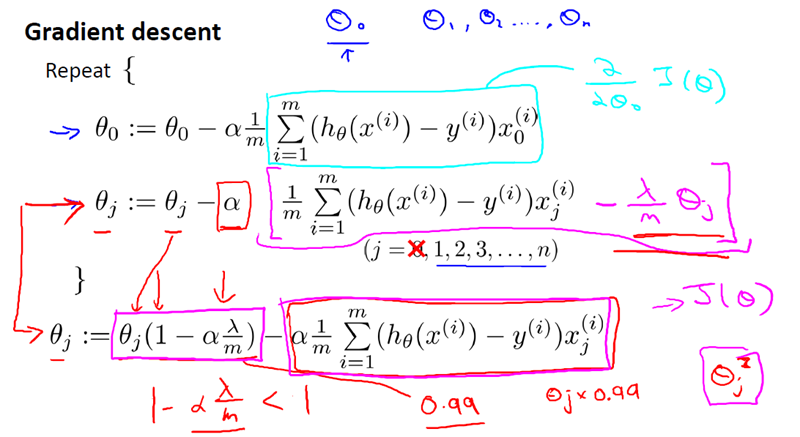
2
正规方程,如下:

3
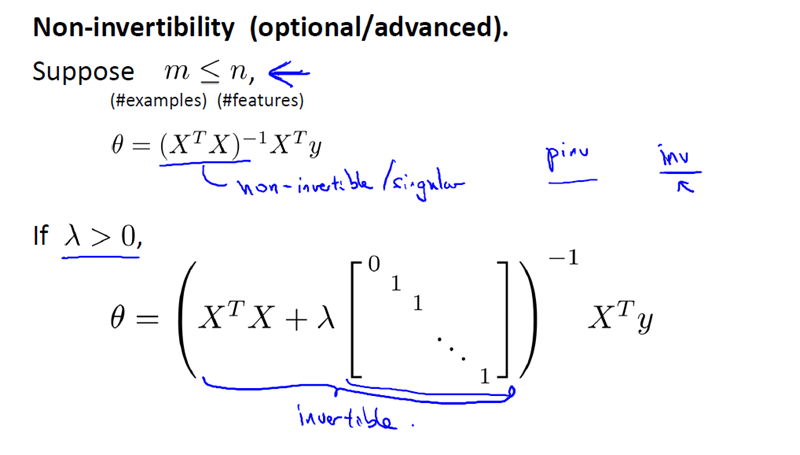
现在考虑 M(即样本量), 比 N(即特征的数量)小或等于N。
通过之前的博文,我们知道如果你只有较少的样本,导致特征数量大于样本数量,那么矩阵 XTX 将是不可逆矩阵或奇异(singluar)矩阵,或者用另一种说法是这个矩阵是退化(degenerate)的,那么我们就没有办法使用正规方程来求出 θ 。
幸运的是,正规化也为我们解决了这个问题,具体的说只要正则参数是严格大于零,实际上,可以证明如下矩阵:
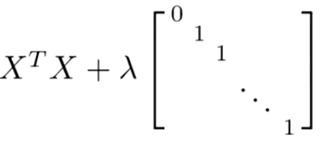
将是可逆的。因此,使用正则还可以照顾任何 XTX 不可逆的问题。
所以,你现在知道如何实现岭回归,利用它,你就可以避免过度拟合,即使你在一个相对较小的训练集里有很多特征。这应该可以让你在很多问题上更好的运用线性回归。
在接下来的视频中,我们将把这种正则化的想法应用到 Logistic 回归,这样我们就可以让 logistic 回归也避免过度拟合,从而表现的更好。
4. Regularized Logistic Regression
Regularized Logistic Regression 实际上与 Regularized Linear Regression 是十分相似的。
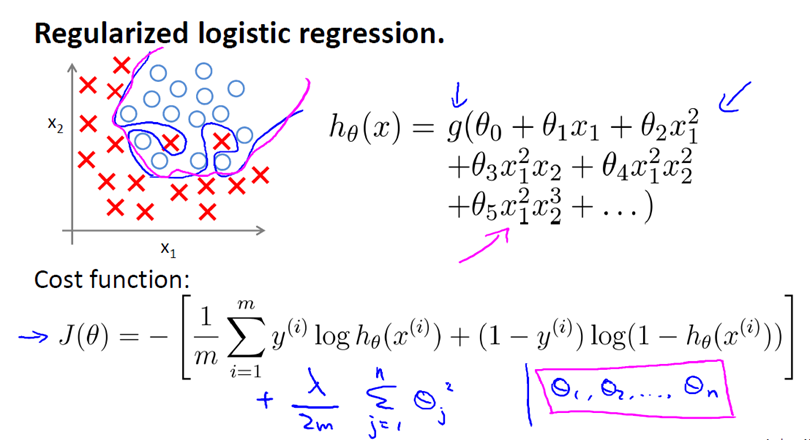
同样使用梯度下降:

如果在高级优化算法中,使用正则化技术的话,那么对于这类算法我们需要自己定义costFunction。
For those methods what we needed to do was to define the function that's called the cost function.

这个我们自定义的 costFunction 的输入为向量 θ ,返回值有两项,分别是代价函数 jVal 以及 梯度gradient。
总之我们需要的就是这个自定义函数costFunction,针对Octave而言,我们可以将这个函数作为参数传入到
fminunc 系统函数中(fminunc 用来求函数的最小值,将@costFunction作为参数代进去,注意 @costFunction
类似于C语言中的函数指针),fminunc返回的是函数 costFunction 在无约束条件下的最小值,即我们提供的代价函数 jVal
的最小值,当然也会返回向量 θ 的解。
上述方法显然对正则化逻辑回归是适用的。
5. 尾声
通过最近的几篇文章,我们不难发现,无论是线性回归问题还是逻辑回归问题都可以通过构造多项式来解决。但是,你将逐渐发现其实还有更为强大的非线性分类器可以用来解决多项式回归问题。下篇文章中,我们将会讨论。
1.线性回归介绍

X指训练数据的feature,beta指待估计得参数。
详细见http://zh.wikipedia.org/wiki/%E4%B8%80%E8%88%AC%E7%BA%BF%E6%80%A7%E6%A8%A1%E5%9E%8B
使用最小二乘法拟合的普通线性回归是数据建模的基本方法。

令最小二乘项的偏导为0(为0时RSS项最小),求Beta估计值,得到最小二乘的向量形式。

最小二乘其实就是找出一组参数beta使得训练数据到拟合出的数据的欧式距离最小。如下图所示,使所有红点(训练数据)到平面的距离之和最小。

图来源(ESL p45)
最小二乘的几何解释:找到一个投影矩阵,使得y到feature矩阵的线性子空间距离最短。如下图所示

在线性模型中,存在过拟合问题(下图右一):

所以针对过拟合问题,通常会考虑两种途径来解决:
a) 减少特征的数量:
-人工的选择保留哪些特征;
-模型选择
b) 正则化
-保留所有的特征,但是降低参数θj的量/值;
3. 在这里我们介绍正则化方法
主要是岭回归(ridge regression)和lasso回归。通过对最小二乘估计加入惩罚约束,使某些系数的估计非常小或为0。
岭回归在最小化RSS的计算里加入了一个收缩惩罚项(正则化的l2范数)

对误差项进行求偏导,令偏导为零得:
Lasso回归

lasso是在RSS最小化的计算中加入一个l1范数作为罚约束:
-

为什么加了惩罚因子就会使得参数变低或零呢?根据拉格朗日乘法算子,这个问题可以转换成一个带约束的求极小值问题。

其收敛示意图如下所示,左是Ridge回归,右是lasso回归。黑点表示最小二乘的收敛中心,蓝色区域是加了乘法项的约束,其交点就是用相应regularization得到的系数在系数空间的表示。

python信用评分卡建模(附代码,博主录制)

线性回归和正则化(Regularization)的更多相关文章
- zzL1和L2正则化regularization
最优化方法:L1和L2正则化regularization http://blog.csdn.net/pipisorry/article/details/52108040 机器学习和深度学习常用的规则化 ...
- 7、 正则化(Regularization)
7.1 过拟合的问题 到现在为止,我们已经学习了几种不同的学习算法,包括线性回归和逻辑回归,它们能够有效地解决许多问题,但是当将它们应用到某些特定的机器学习应用时,会遇到过拟合(over-fittin ...
- [DeeplearningAI笔记]改善深层神经网络1.4_1.8深度学习实用层面_正则化Regularization与改善过拟合
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.4 正则化(regularization) 如果你的神经网络出现了过拟合(训练集与验证集得到的结果方差较大),最先想到的方法就是正则化(re ...
- 斯坦福第七课:正则化(Regularization)
7.1 过拟合的问题 7.2 代价函数 7.3 正则化线性回归 7.4 正则化的逻辑回归模型 7.1 过拟合的问题 如果我们有非常多的特征,我们通过学习得到的假设可能能够非常好地适应训练集( ...
- (五)用正则化(Regularization)来解决过拟合
1 过拟合 过拟合就是训练模型的过程中,模型过度拟合训练数据,而不能很好的泛化到测试数据集上.出现over-fitting的原因是多方面的: 1) 训练数据过少,数据量与数据噪声是成反比的,少量数据导 ...
- [笔记]机器学习(Machine Learning) - 03.正则化(Regularization)
欠拟合(Underfitting)与过拟合(Overfitting) 上面两张图分别是回归问题和分类问题的欠拟合和过度拟合的例子.可以看到,如果使用直线(两组图的第一张)来拟合训,并不能很好地适应我们 ...
- CS229 5.用正则化(Regularization)来解决过拟合
1 过拟合 过拟合就是训练模型的过程中,模型过度拟合训练数据,而不能很好的泛化到测试数据集上.出现over-fitting的原因是多方面的: 1) 训练数据过少,数据量与数据噪声是成反比的,少量数据导 ...
- [C3] 正则化(Regularization)
正则化(Regularization - Solving the Problem of Overfitting) 欠拟合(高偏差) VS 过度拟合(高方差) Underfitting, or high ...
- Machine Learning--week3 逻辑回归函数(分类)、决策边界、逻辑回归代价函数、多分类与(逻辑回归和线性回归的)正则化
Classification It's not a good idea to use linear regression for classification problem. We can use ...
随机推荐
- 转载Google TPU论文
选自 Google Drive 作者:Norman P. Jouppi 等 痴笑@矽说 编译 该论文将正式发表于 ISCA 2017 从去年七月起,Google就号称了其面向深度学习的专用集成电路(A ...
- Linux Exploit系列之七 绕过 ASLR -- 第二部分
原文地址:https://github.com/wizardforcel/sploitfun-linux-x86-exp-tut-zh/blob/master/7.md 这一节是简单暴力的一节,作者讲 ...
- linux中查看文件夹结构的小工具
tree命令是Linux/UNIX系统中常用的命令,可以非常方便地查看文件夹的结构,并且以树形目录的形式展示 在Ubuntu中安装 sudo apt-get install tree 在CentOS中 ...
- laravel 使用 intervention/image 的注意方法
出错NotSupportedException in AbstractEncoder.php line 151: Encodingformat (tmp) is not supported. 这个只是 ...
- win10 安装ubuntu16.04双系统
安装了两天的ubuntu系统,很是头疼,发现网上的内容,比较繁杂,因此,写此博客,进行综合整理,总结了安装方法.方便大家安装,减少搜索. 电脑是老师的电脑,配置为: 主板:微星 CPU:英特尔i5 7 ...
- libcyusb
https://github.com/hmaarrfk/libcyusb/blob/master/include/cyusb.h
- Kendo UI for jQuery使用教程:使用MVVM初始化(一)
[Kendo UI for jQuery最新试用版下载] Kendo UI目前最新提供Kendo UI for jQuery.Kendo UI for Angular.Kendo UI Support ...
- スワコゥのパーフェクトコード教室 ~ Style of suwakow's for OI Codes
"みんなー! スワコゥのコード教室はじまるよー!" "大家!\(\color{grey}{\text{suwakow}}\)的码风教室开始了哟!" " ...
- qt5--QEvent事件
QEvent事件是负责事件分发,包括所有事件返回值为true,用户自己处理事件,不向下分发:false系统处理事件---必须有返回值 查看所有事件,在Qt助手中搜索QEvent::Type #incl ...
- JavaScript基础——JavaScript常量和变量(笔记)
JavaScript常量和变量(笔记) Javascript代码严格区分大小写. javascript暂不支持constant关键字,不允许用户自定义常量. javascript使用var关键字声明变 ...