mapreduce实验
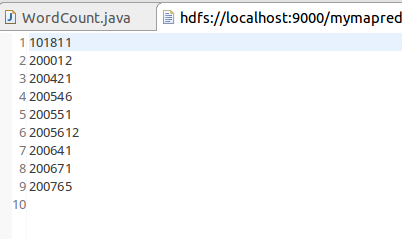
代码:
public class WordCount {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance();
job.setJobName("WordCount");
job.setJarByClass(WordCount.class);
job.setMapperClass(doMapper.class);
job.setReducerClass(doReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path in = new Path("hdfs://localhost:9000/mymapreduce1/in/buyer_favorite1");
Path out = new Path("hdfs://localhost:9000/mymapreduce1/out");
FileInputFormat.addInputPath(job, in);
FileOutputFormat.setOutputPath(job, out);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static class doMapper extends Mapper<Object, Text, Text, IntWritable>{
public static final IntWritable one = new IntWritable(1);
public static Text word = new Text();
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer tokenizer = new StringTokenizer(value.toString(), " ");
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
public static class doReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
result.set(sum);
context.write(key, result);
}
}
}
mapreduce实验的更多相关文章
- 实验六 MapReduce实验:二次排序
实验指导: 6.1 实验目的基于MapReduce思想,编写SecondarySort程序. 6.2 实验要求要能理解MapReduce编程思想,会编写MapReduce版本二次排序程序,然后将其执行 ...
- Mapreduce实验一:WordCountTest
1.确定Hadoop处于启动状态 [root@neusoft-master ~]# jps 23763 Jps3220 SecondaryNameNode3374 ResourceManager293 ...
- Mit6.824 Lab1-MapReduce
前言 Mit6.824 是我在学习一些分布式系统方面的知识的时候偶然看到的,然后就开始尝试跟课.不得不说,国外的课程难度是真的大,一周的时间居然要学一门 Go 语言,然后还要读论文,进而做MapRed ...
- 实验6:Mapreduce实例——WordCount
实验目的1.准确理解Mapreduce的设计原理2.熟练掌握WordCount程序代码编写3.学会自己编写WordCount程序进行词频统计实验原理MapReduce采用的是“分而治之”的 ...
- 大型数据库技术实验六 实验6:Mapreduce实例——WordCount
现有某电商网站用户对商品的收藏数据,记录了用户收藏的商品id以及收藏日期,名为buyer_favorite1. buyer_favorite1包含:买家id,商品id,收藏日期这三个字段,数据以“\t ...
- Hadoop大实验——MapReduce的操作
日期:2019.10.30 博客期:114 星期三 实验6:Mapreduce实例——WordCount 实验说明: 1. 本次实验是第六次上机,属于验证性实验.实验报告上交截止 ...
- 云计算——实验一 HDFS与MAPREDUCE操作
1.虚拟机集群搭建部署hadoop 利用VMware.centOS-7.Xshell(secureCrt)等软件搭建集群部署hadoop 远程连接工具使用Xshell: HDFS文件操作 2.1 HD ...
- mapreduce课上实验
今天我们课上做了一个关于数据清洗的实验,具体实验内容如下: 1.数据清洗:按照进行数据清洗,并将清洗后的数据导入hive数据库中: 2.数据处理: ·统计最受欢迎的视频/文章的Top10访问次数 (v ...
- Hadoop学习笔记—11.MapReduce中的排序和分组
一.写在之前的 1.1 回顾Map阶段四大步骤 首先,我们回顾一下在MapReduce中,排序和分组在哪里被执行: 从上图中可以清楚地看出,在Step1.4也就是第四步中,需要对不同分区中的数据进行排 ...
随机推荐
- centos7解决ssh登录速度慢的问题
先备份/etc/ssh/sshd_config,备份命令为 cp /etc/ssh/sshd_config /etc/ssh/sshd_config.bak 1.su ...
- vscode编写代码快速生成html模板
!(英文)+tab 自动生成HTML模板
- 05.Linux-CentOS系统普通用户SSH远程问题
问题:appuser用户SSH远程连接Linux服务器出现的问题: Connecting?to?localhost:22...Connection?established.To?escape?to?l ...
- 四 shell基本命令
一 内置命令 hlep 命令 帮助 help test help -s printf 显示内置命令的语法格式 echo 用来显示一行文字 echo "hello world&quo ...
- python常用函数 O
OrderedDict() 保持dict元素插入顺序. 例子: open(path) 可以对文件进行操作,有'r'读模式.'w'写模式.'a'追加模式.'b'二进制模式.'+'读/写模式等,操作完需要 ...
- HTML5:新元素来实现一下网页布局
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- center os7 安装mysql
安装mariadb MariaDB数据库管理系统是MySQL的一个分支,主要由开源社区在维护,采用GPL授权许可.开发这个分支的原因之一是:甲骨文公司收购了MySQL后,有将MySQL闭源的潜在风险, ...
- Center os vi
vi /etc/virc set nu 设置所有文件显示行号 :1,$s/after/befer/g 全局替换 :%s/after/befer/g 全局替换 yy 复制一行 p 粘贴 yw 复制一个 ...
- hibernate配置注意事项
1:多对一配置 private Set<DrawRecordModel> cjrecordsSet = new HashSet<DrawRecordModel>(); 正确 p ...
- 接触python的第1天:测试hello world
在python3.8的平台可以输入了hello world, ide还能当做计算器 >>> print("hello world") hello world &g ...