MySql 缓冲池(buffer pool) 和 写缓存(change buffer) 转
应用系统分层架构,为了加速数据访问,会把最常访问的数据,放在缓存(cache)里,避免每次都去访问数据库。
操作系统,会有缓冲池(buffer pool)机制,避免每次访问磁盘,以加速数据的访问。
MySQL作为一个存储系统,同样具有缓冲池(buffer pool)机制,以避免每次查询数据都进行磁盘IO。
今天,和大家聊一聊InnoDB的缓冲池。
InnoDB的缓冲池缓存什么?有什么用?
缓存表数据与索引数据,把磁盘上的数据加载到缓冲池,避免每次访问都进行磁盘IO,起到加速访问的作用。
速度快,那为啥不把所有数据都放到缓冲池里?
凡事都具备两面性,抛开数据易失性不说,访问快速的反面是存储容量小:
(1)缓存访问快,但容量小,数据库存储了200G数据,缓存容量可能只有64G;
(2)内存访问快,但容量小,买一台笔记本磁盘有2T,内存可能只有16G;
因此,只能把“最热”的数据放到“最近”的地方,以“最大限度”的降低磁盘访问。
如何管理与淘汰缓冲池,使得性能最大化呢?
在介绍具体细节之前,先介绍下“预读”的概念。
什么是预读?
磁盘读写,并不是按需读取,而是按页读取,一次至少读一页数据(一般是4K),如果未来要读取的数据就在页中,就能够省去后续的磁盘IO,提高效率。
预读为什么有效?
数据访问,通常都遵循“集中读写”的原则,使用一些数据,大概率会使用附近的数据,这就是所谓的“局部性原理”,它表明提前加载是有效的,确实能够减少磁盘IO。
按页(4K)读取,和InnoDB的缓冲池设计有啥关系?
(1)磁盘访问按页读取能够提高性能,所以缓冲池一般也是按页缓存数据;
(2)预读机制启示了我们,能把一些“可能要访问”的页提前加入缓冲池,避免未来的磁盘IO操作;
InnoDB是以什么算法,来管理这些缓冲页呢?
最容易想到的,就是LRU(Least recently used)。
画外音:memcache,OS都会用LRU来进行页置换管理,但MySQL的玩法并不一样。
传统的LRU是如何进行缓冲页管理?
最常见的玩法是,把入缓冲池的页放到LRU的头部,作为最近访问的元素,从而最晚被淘汰。这里又分两种情况:
(1)页已经在缓冲池里,那就只做“移至”LRU头部的动作,而没有页被淘汰;
(2)页不在缓冲池里,除了做“放入”LRU头部的动作,还要做“淘汰”LRU尾部页的动作;

如上图,假如管理缓冲池的LRU长度为10,缓冲了页号为1,3,5…,40,7的页。
假如,接下来要访问的数据在页号为4的页中:

(1)页号为4的页,本来就在缓冲池里;
(2)把页号为4的页,放到LRU的头部即可,没有页被淘汰;
画外音:为了减少数据移动,LRU一般用链表实现。
假如,再接下来要访问的数据在页号为50的页中:
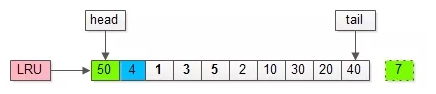
(1)页号为50的页,原来不在缓冲池里;
(2)把页号为50的页,放到LRU头部,同时淘汰尾部页号为7的页;
传统的LRU缓冲池算法十分直观,OS,memcache等很多软件都在用,MySQL为啥这么矫情,不能直接用呢?
这里有两个问题:
(1)预读失效;
(2)缓冲池污染;
什么是预读失效?
由于预读(Read-Ahead),提前把页放入了缓冲池,但最终MySQL并没有从页中读取数据,称为预读失效。
如何对预读失效进行优化?
要优化预读失效,思路是:
(1)让预读失败的页,停留在缓冲池LRU里的时间尽可能短;
(2)让真正被读取的页,才挪到缓冲池LRU的头部;
以保证,真正被读取的热数据留在缓冲池里的时间尽可能长。
具体方法是:
(1)将LRU分为两个部分:
新生代(new sublist)
老生代(old sublist)
(2)新老生代收尾相连,即:新生代的尾(tail)连接着老生代的头(head);
(3)新页(例如被预读的页)加入缓冲池时,只加入到老生代头部:
如果数据真正被读取(预读成功),才会加入到新生代的头部
如果数据没有被读取,则会比新生代里的“热数据页”更早被淘汰出缓冲池
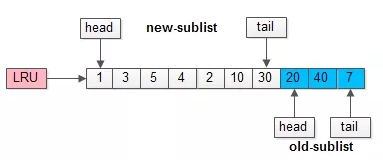
举个例子,整个缓冲池LRU如上图:
(1)整个LRU长度是10;
(2)前70%是新生代;
(3)后30%是老生代;
(4)新老生代首尾相连;

假如有一个页号为50的新页被预读加入缓冲池:
(1)50只会从老生代头部插入,老生代尾部(也是整体尾部)的页会被淘汰掉;
(2)假设50这一页不会被真正读取,即预读失败,它将比新生代的数据更早淘汰出缓冲池;
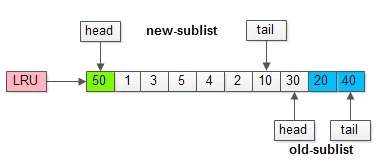
假如50这一页立刻被读取到,例如SQL访问了页内的行row数据:
(1)它会被立刻加入到新生代的头部;
(2)新生代的页会被挤到老生代,此时并不会有页面被真正淘汰;
改进版缓冲池LRU能够很好的解决“预读失败”的问题。
画外音:但也不要因噎废食,因为害怕预读失败而取消预读策略,大部分情况下,局部性原理是成立的,预读是有效的。
新老生代改进版LRU仍然解决不了缓冲池污染的问题。
什么是MySQL缓冲池污染?
当某一个SQL语句,要批量扫描大量数据时,可能导致把缓冲池的所有页都替换出去,导致大量热数据被换出,MySQL性能急剧下降,这种情况叫缓冲池污染。
例如,有一个数据量较大的用户表,当执行:
select * from user where name like "%shenjian%";
虽然结果集可能只有少量数据,但这类like不能命中索引,必须全表扫描,就需要访问大量的页:
(1)把页加到缓冲池(插入老生代头部);
(2)从页里读出相关的row(插入新生代头部);
(3)row里的name字段和字符串shenjian进行比较,如果符合条件,加入到结果集中;
(4)…直到扫描完所有页中的所有row…
如此一来,所有的数据页都会被加载到新生代的头部,但只会访问一次,真正的热数据被大量换出。
怎么这类扫码大量数据导致的缓冲池污染问题呢?
MySQL缓冲池加入了一个“老生代停留时间窗口”的机制:
(1)假设T=老生代停留时间窗口;
(2)插入老生代头部的页,即使立刻被访问,并不会立刻放入新生代头部;
(3)只有满足“被访问”并且“在老生代停留时间”大于T,才会被放入新生代头部;
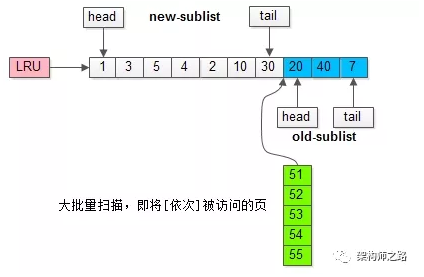
继续举例,假如批量数据扫描,有51,52,53,54,55等五个页面将要依次被访问。
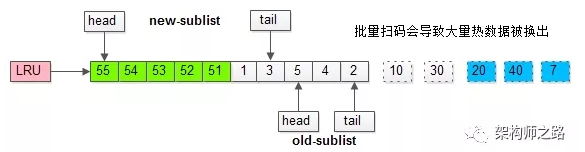
如果没有“老生代停留时间窗口”的策略,这些批量被访问的页面,会换出大量热数据。
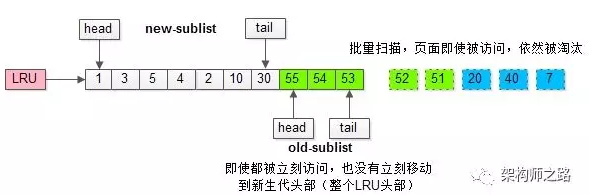
加入“老生代停留时间窗口”策略后,短时间内被大量加载的页,并不会立刻插入新生代头部,而是优先淘汰那些,短期内仅仅访问了一次的页。
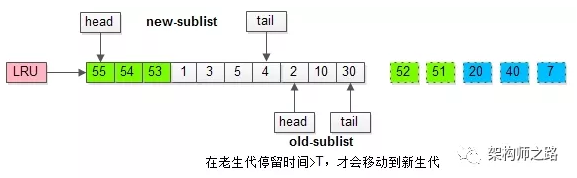
而只有在老生代呆的时间足够久,停留时间大于T,才会被插入新生代头部。
上述原理,对应InnoDB里哪些参数?
有三个比较重要的参数。
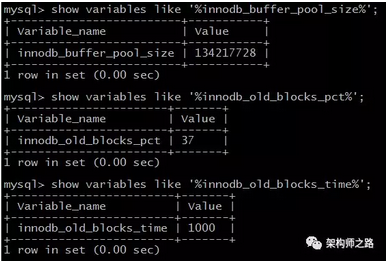
参数:innodb_buffer_pool_size
介绍:配置缓冲池的大小,在内存允许的情况下,DBA往往会建议调大这个参数,越多数据和索引放到内存里,数据库的性能会越好。
参数:innodb_old_blocks_pct
介绍:老生代占整个LRU链长度的比例,默认是37,即整个LRU中新生代与老生代长度比例是63:37。
画外音:如果把这个参数设为100,就退化为普通LRU了。
参数:innodb_old_blocks_time
介绍:老生代停留时间窗口,单位是毫秒,默认是1000,即同时满足“被访问”与“在老生代停留时间超过1秒”两个条件,才会被插入到新生代头部。
总结
(1)缓冲池(buffer pool)是一种常见的降低磁盘访问的机制;
(2)缓冲池通常以页(page)为单位缓存数据;
(3)缓冲池的常见管理算法是LRU,memcache,OS,InnoDB都使用了这种算法;
(4)InnoDB对普通LRU进行了优化:
将缓冲池分为老生代和新生代,入缓冲池的页,优先进入老生代,页被访问,才进入新生代,以解决预读失效的问题
页被访问,且在老生代停留时间超过配置阈值的,才进入新生代,以解决批量数据访问,大量热数据淘汰的问题
写缓存(change buffer)
对于读请求,缓冲池能够减少磁盘IO,提升性能。问题来了,那写请求呢?
情况一
假如要修改页号为4的索引页,而这个页正好在缓冲池内。
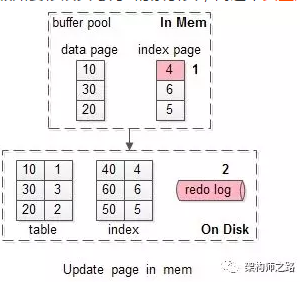
如上图序号1-2:
(1)直接修改缓冲池中的页,一次内存操作;
(2)写入redo log,一次磁盘顺序写操作;
这样的效率是最高的。
画外音:像写日志这种顺序写,每秒几万次没问题。
是否会出现一致性问题呢?
并不会。
(1)读取,会命中缓冲池的页;
(2)缓冲池LRU数据淘汰,会将“脏页”刷回磁盘;
(3)数据库异常奔溃,能够从redo log中恢复数据;
什么时候缓冲池中的页,会刷到磁盘上呢?
定期刷磁盘,而不是每次刷磁盘,能够降低磁盘IO,提升MySQL的性能。
画外音:批量写,是常见的优化手段。
情况二
假如要修改页号为40的索引页,而这个页正好不在缓冲池内。
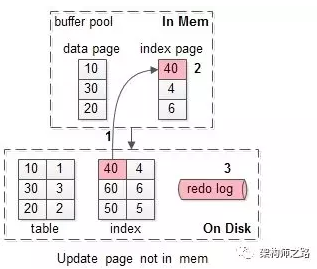
此时麻烦一点,如上图需要1-3:
(1)先把需要为40的索引页,从磁盘加载到缓冲池,一次磁盘随机读操作;
(2)修改缓冲池中的页,一次内存操作;
(3)写入redo log,一次磁盘顺序写操作;
没有命中缓冲池的时候,至少产生一次磁盘IO,对于写多读少的业务场景,是否还有优化的空间呢?
这即是InnoDB考虑的问题,又是本文将要讨论的写缓冲(change buffer)。
画外音:从名字容易看出,写缓冲是降低磁盘IO,提升数据库写性能的一种机制。
什么是InnoDB的写缓冲?
在MySQL5.5之前,叫插入缓冲(insert buffer),只针对insert做了优化;现在对delete和update也有效,叫做写缓冲(change buffer)。
它是一种应用在非唯一普通索引页(non-unique secondary index page)不在缓冲池中,对页进行了写操作,并不会立刻将磁盘页加载到缓冲池,而仅仅记录缓冲变更(buffer changes),等未来数据被读取时,再将数据合并(merge)恢复到缓冲池中的技术。写缓冲的目的是降低写操作的磁盘IO,提升数据库性能。
InnoDB加入写缓冲优化,上文“情况二”流程会有什么变化?
假如要修改页号为40的索引页,而这个页正好不在缓冲池内。
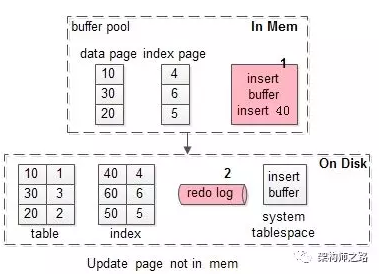
加入写缓冲优化后,流程优化为:
(1)在写缓冲中记录这个操作,一次内存操作;
(2)写入redo log,一次磁盘顺序写操作;
其性能与,这个索引页在缓冲池中,相近。
画外音:可以看到,40这一页,并没有加载到缓冲池中。
是否会出现一致性问题呢?
也不会。
(1)数据库异常奔溃,能够从redo log中恢复数据;
(2)写缓冲不只是一个内存结构,它也会被定期刷盘到写缓冲系统表空间;
(3)数据读取时,有另外的流程,将数据合并到缓冲池;
不妨设,稍后的一个时间,有请求查询索引页40的数据。

此时的流程如序号1-3:
(1)载入索引页,缓冲池未命中,这次磁盘IO不可避免;
(2)从写缓冲读取相关信息;
(3)恢复索引页,放到缓冲池LRU里;
画外音:可以看到,40这一页,在真正被读取时,才会被加载到缓冲池中。
还有一个遗漏问题,为什么写缓冲优化,仅适用于非唯一普通索引页呢?
InnoDB里,聚集索引(clustered index)和普通索引(secondary index)的异同,《1分钟了解MyISAM与InnoDB的索引差异》有详尽的叙述,不再展开。
如果索引设置了唯一(unique)属性,在进行修改操作时,InnoDB必须进行唯一性检查。也就是说,索引页即使不在缓冲池,磁盘上的页读取无法避免(否则怎么校验是否唯一?),此时就应该直接把相应的页放入缓冲池再进行修改,而不应该再整写缓冲这个幺蛾子。
除了数据页被访问,还有哪些场景会触发刷写缓冲中的数据呢?
还有这么几种情况,会刷写缓冲中的数据:
(1)有一个后台线程,会认为数据库空闲时;
(2)数据库缓冲池不够用时;
(3)数据库正常关闭时;
(4)redo log写满时;
画外音:几乎不会出现redo log写满,此时整个数据库处于无法写入的不可用状态。
什么业务场景,适合开启InnoDB的写缓冲机制?
先说什么时候不适合,如上文分析,当:
(1)数据库都是唯一索引;
(2)或者,写入一个数据后,会立刻读取它;
这两类场景,在写操作进行时(进行后),本来就要进行进行页读取,本来相应页面就要入缓冲池,此时写缓存反倒成了负担,增加了复杂度。
什么时候适合使用写缓冲,如果:
(1)数据库大部分是非唯一索引;
(2)业务是写多读少,或者不是写后立刻读取;
可以使用写缓冲,将原本每次写入都需要进行磁盘IO的SQL,优化定期批量写磁盘。
画外音:例如,账单流水业务。
上述原理,对应InnoDB里哪些参数?
有两个比较重要的参数。
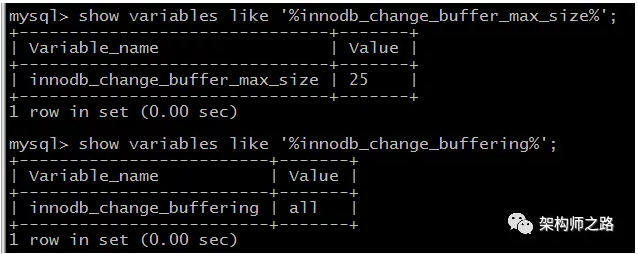
参数:innodb_change_buffer_max_size
介绍:配置写缓冲的大小,占整个缓冲池的比例,默认值是25%,最大值是50%。
画外音:写多读少的业务,才需要调大这个值,读多写少的业务,25%其实也多了。
参数:innodb_change_buffering
介绍:配置哪些写操作启用写缓冲,可以设置成all/none/inserts/deletes等。
出处:公众号 架构师之路
MySql 缓冲池(buffer pool) 和 写缓存(change buffer) 转的更多相关文章
- 14.4.3.2 Configuring Multiple Buffer Pool Instances 配置多个buffer pool 实例:
14.4.3.2 Configuring Multiple Buffer Pool Instances 配置多个buffer pool 实例: 对于系统 buffer pool 有多个G的范围, 把b ...
- 14.6.3.4 Configuring InnoDB Buffer Pool Prefetching (Read-Ahead) 配置InnoDB Buffer pool 预取
14.6.3.4 Configuring InnoDB Buffer Pool Prefetching (Read-Ahead) 配置InnoDB Buffer pool 预取 一个预读请求是一个I/ ...
- 14.6.3.2 Configuring Multiple Buffer Pool Instances 配置多个Buffer Poll 实例:
14.6.3.2 Configuring Multiple Buffer Pool Instances 配置多个Buffer Poll 实例: 对于系统有多个buffer pools 在多个字节范围, ...
- 14.4.3.4 Configuring InnoDB Buffer Pool Prefetching (Read-Ahead) 配置InnoDB Buffer pool 预读
14.4.3.4 Configuring InnoDB Buffer Pool Prefetching (Read-Ahead) 配置InnoDB Buffer pool 预读 一个预读请求 是一个I ...
- InnoDB 中的缓冲池(Buffer Pool)
本文主要说明 InnoDB Buffer Pool 的内部执行原理,其生效的前提是使用到了索引,如果没有用到索引会进行全表扫描. 结构 在 InnoDB 存储引擎层维护着一个缓冲池,通过其可以避免对磁 ...
- 【MySQL 5.7 Reference Manual】15.4.2 Change Buffer(变更缓冲)
15.4.2 Change Buffer(变更缓冲) The change buffer is a special data structure that caches changes to se ...
- MySQL 5.7 Reference Manual】15.4.2 Change Buffer(变更缓冲)
15.4.2 Change Buffer(变更缓冲) The change buffer is a special data structure that caches changes to se ...
- 【大白话系统】MySQL 学习总结 之 缓冲池(Buffer Pool) 的设计原理和管理机制
一.缓冲池(Buffer Pool)的地位 在<MySQL 学习总结 之 InnoDB 存储引擎的架构设计>中,我们就讲到,缓冲池是 InnoDB 存储引擎中最重要的组件.因为为了提高 M ...
- 【大白话系统】MySQL 学习总结 之 缓冲池(Buffer Pool) 如何支撑高并发和动态调整
如果大家对我的 [大白话系列]MySQL 学习总结系列 感兴趣的话,可以点击关注一波. 一.上节回顾 在上节< 缓冲池(Buffer Pool) 的设计原理和管理机制>中,介绍了缓冲池整体 ...
随机推荐
- Unity3D_(API)场景切换SceneManager
Unity场景切换SceneManager 官方文档:传送门 静态方法 创建场景 CreateScene Create an empty new Scene at runtime with the g ...
- BeanCopier对象复制学习
BeanCopier是Cglib包中的一个类,用于对象的复制. 注意:目标对象必须先实例化 而且对象必须要有setter方法 初始化例子: BeanCopier copier = BeanCop ...
- spring boot V部落 V人事项目
公司倒闭 1 年多了,而我在公司倒闭时候做的开源项目,最近却上了 GitHub Trending,看着这个数据,真是不胜唏嘘. 缘起 2017 年 11 月份的时候,松哥所在的公司因为经营不善要关门了 ...
- GC详解
GC,即就是Java垃圾回收机制.目前主流的JVM(HotSpot)采用的是分代收集算法.与C++不同的是,Java采用的是类似于树形结构的可达性分析法来判断对象是否还存在引用.即:从gcroot开始 ...
- C++入门经典-例2.14-使用移位运算
1:代码如下: // 2.14.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include <iostream> usin ...
- spark streaming 3: Receiver 到 submitJobSet
对于spark streaming来说,receiver是数据的源头.spark streaming的框架上,将receiver替换spark-core的以磁盘为数据源的做法,但是数据源(如监听某个 ...
- 七、创建UcRESTTemplate请求管理器
一.创建UcRESTTemplate管理器封装 import com.alibaba.fastjson.JSON; import org.apache.http.client.config.Reque ...
- matlab7与win7不兼容
移动鼠标到其打开图标,右键打开属性,选择兼容性,勾选"以兼容模式运行程序",选择Windows Vista
- 代码实现:一个数如果恰好等于它的因子之和,这个数就称为"完数"。例如6=1+2+3.第二个完全数是28, //它有约数1、2、4、7、14、28,除去它本身28外,其余5个数相加, //编程找出1000以内的所有完数。
import java.util.ArrayList; import java.util.List; //一个数如果恰好等于它的因子之和,这个数就称为"完数".例如6=1+2+3. ...
- json中loads()和dumps()的应用
import json s = {'name': 'jack'} #将dict转换成strl = json.dumps(s)print(type(l)) #将str转换成dictm = json.lo ...