Dubbo的集群容错与负载均衡策略
|
1
2
|
<dubbo:reference>[/size][/font][/color][/align] <dubbo:method name="sayHello" retries="2" /></dubbo:reference> |
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
public Result doInvoke(Invocation invocation,final List<Invoker<T>> invokers,LoadBalance loadbalance) throws RpcException{ // (1) 所有服务提供者 List<Invoker<T>> copyinvokers = invokers; checkInvokers(copyinvokers,invocation); // (2)获取重试次数 int len = getUrl().getMethodParameter(invocation.getMethodName(),Constants.RETRIES_KEY,Constants.DEFAULT_RETRIES) + 1; if(len <= 0){ len = 1; } // (3)使用循环,失败重试 RpcException le = null; // last exception List<Invoker<T>> invoked = new ArrayList<Invoker<T>>(copyinvokers.size()); Set<String> providers = new HashSet<String>(); for(int i=0;i<len;i++){ // 重试时,进行重新选择,避免重试时invoker列表已发生变化 // 注意:如果列表发生了变化,那么invoked判断会失效,因为invoker示例已经改变 if(i > 0){ // (3.1) checkWhetherDestroyed(); // 如果当前实例已经被销毁,则抛出异常 // (3.2) 重新获取所有服务提供者 copyinvokers = list(invocation); // (3.3) 重新检查一下 checkInvokers(copyinvokers,invocation); } // (3.4) 选择负载均衡策略 Invoker<T> invoker = select(loadbalance,invocation,copyinvokers,invoked); invoked.add(invoker); RpcContext.getContext().setInvokers((List)invoked); // (3.5) 具体发起远程调用 try{ Result result = invoker.invoke(invocation); if(le != null && logger.isWarnEnabled()){ ... } return result; }catch(RpcException e){ if(e.isBiz()){ // biz exception throw e; } le = e; }catch(Throwable e){ le = new RpcException(e.getMessage(),e); }finally{ providers.add(invoker.getUrl().getAddress()); } } throw new RpcException("抛出异常...");} |
- 如上代码(2)从url参数里面获取设置的重试次数,如果用户没有设置则取默认的值,默认是重试2,这里需要注意的是代码(2)是获取配置重试次数又+1了。这说明 总共调用次数=重试次数+1 (1是正常调用)。
- 代码(3)循环重复试用,如果第一次调用成功则直接跳出循环返回,否则循环重试。第一次调用时不会走代码(3.1)(3.2)(3.3)。如果第一次调用出现异常,则会循环,这时候i=1,所以会执行代码(3.1)检查是否有线程调用了当前ReferenceConfig的destroy()方法,销毁了当前消费者。如果当前消费者实例已经被消费,那么重试就没有意义了,所以会抛出RpcException异常。
- 如果当前消费者实例没被销毁,则执行代码(3.2)重新获取当前服务提供者列表,这是因为从第一次调开始到线程可能提供者列表已经变化了,获取列表后,然后执行(3.2)又一次进行了校验。校验通过则执行(3.4),根据负载均衡策略选择一个服务提供者,再次尝试调用。负载均衡策略的选择下节会讲解。
- Random LoadBalance:随机策略。按照概率设置权重,比较均匀,并且可以动态调节提供者的权重。
- RoundRobin LoadBalance:轮询策略。轮询,按公约后的权重设置轮询比率。会存在执行比较慢的服务提供者堆积请求的情况,比如一个机器执行的非常慢,但是机器没有挂调用(如果挂了,那么当前机器会从Zookeeper的服务列表删除),当很多新的请求到达该机器后,由于之前的请求还没有处理完毕,会导致新的请求被堆积,久而久之,所有消费者调用这台机器上的请求都被阻塞。
- LeastActive LoadBalance:最少活跃调用数。如果每个提供者的活跃数相同,则随机选择一个。在每个服务提供者里面维护者一个活跃数计数器,用来记录当前同时处理请求的个数,也就是并发处理任务的个数。所以如果这个值越小说明当前服务提供者处理的速度很快或者当前机器的负载比较低,所以路由选择时候就选择该活跃度最小的机器。如果一个服务提供者处理速度很慢,由于堆积,那么同时处理的请求就比较多,也就是活跃调用数目越大,这也使得慢的提供者收到更少请求,因为越慢的提供者的活跃度越来越大。
- ConsistentHash LoadBalance:一致性Hash策略。一致性Hash,可以保证相同参数的请求总是发到同一提供者,当某一台提供者挂了时,原本发往该提供者的请求,基于虚拟节点,平摊到其他提供者,不会引起剧烈变动。
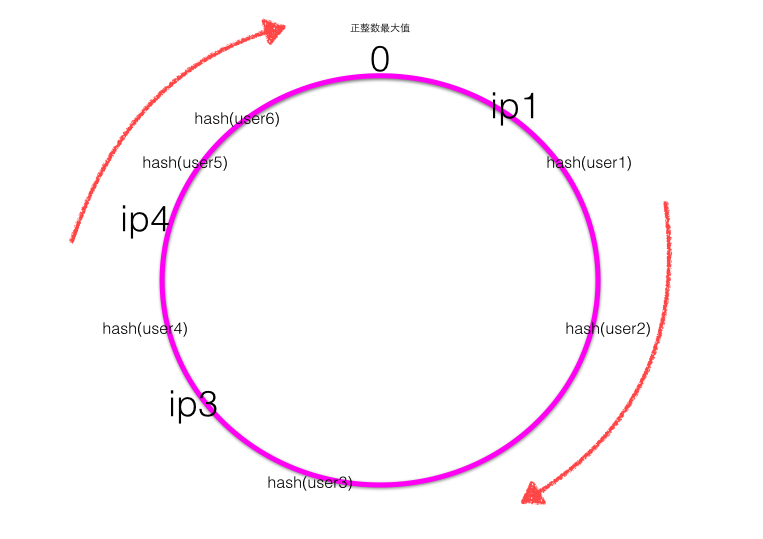
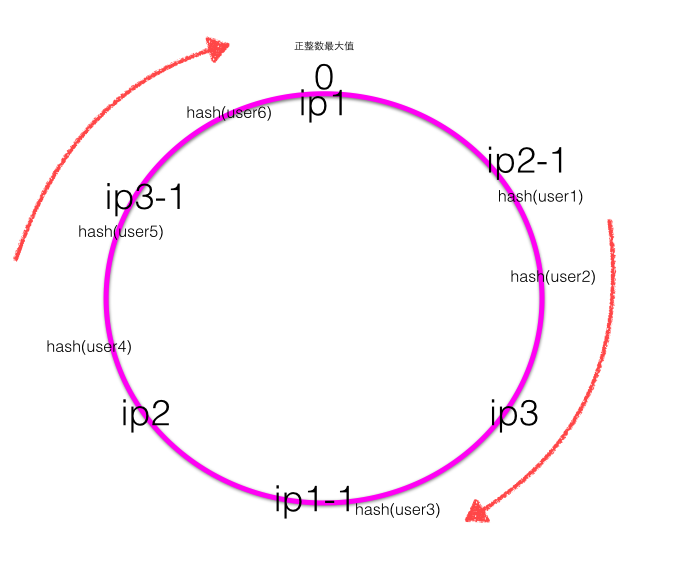
- 一致性Hash,首先计算四个ip地址对应的Hash值:hash(ip1) / hash(ip2) / hash(ip3) / hash(ip4) ,计算出来的Hash值是0~最大正整数之间的一个值,这四个值在一致性Hash环上呈现如下图:
- Hash环上顺时针从整数0开始,一直到最大正整数,我们根据四个ip计算的Hash值肯定会落到这个Hash环上的某一个点,至此我们把服务器的四个ip映射到了一致性Hash环。
- 当用户在客户端进行请求时候,首先根据Hash(用户id)计算路由规则(Hash值),然后看Hash值落到了Hash环的哪个地方,根据Hash值在Hash环上的位置顺时针找距离最近的ip作为路由ip。
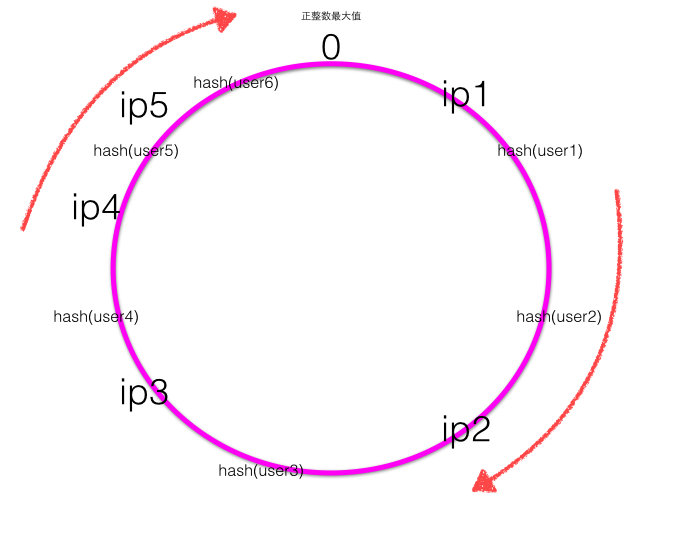
- 单调性(Monotonicity),单调性是指如果已经有一些请求通过哈希分派到了相应的服务器进行处理,又有新的服务器加入到系统中时,应保证原有的请求可以被映射到原有的或者新的服务器中去,而不会被映射到原来的其他服务器上去。这一点通过上面新增服务器ip5可以证明,新增ip5后,原来被ip1处理的user6现在还是被ip1处理的user5现在被新增的ip5处理。
- 分散性(Spread):分布式环境中,客户端请求时候可能不知道所有服务器的存在,可能只知道其中一部分服务器,在客户端看来它看到的部分服务器会形成一个完整的Hash环,那么可能会导致,同一个用户的请求被路由到不同的服务器进行处理。这种情况显然是应该避免的,因为它不能保证同一个用户的请求落到同一个服务器。所谓分散性是指上述情况发生的严重程度。
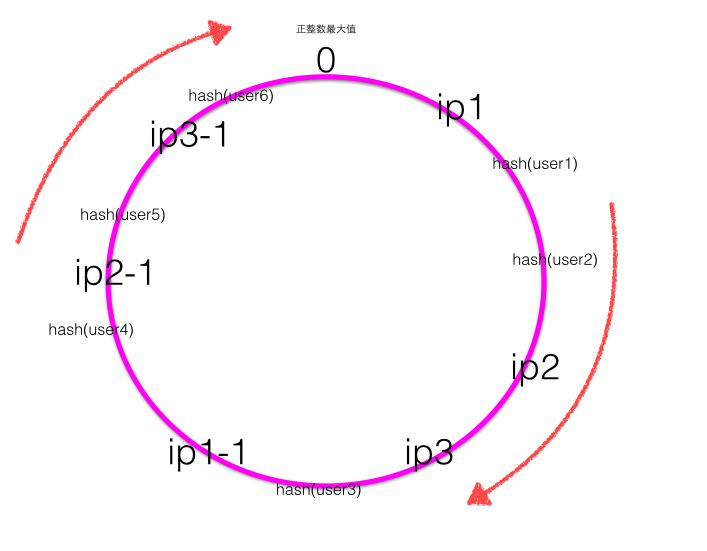
- 平衡性(Balance),平衡性也就是说负载均衡,是指客户端Hash后的请求应该能够分散到不同的服务器上去。一致性Hash可以做到每个服务器都进行处理请求,但是不能保证每个服务器处理的请求的数量大致相同,如下图:
<ignore_js_op>
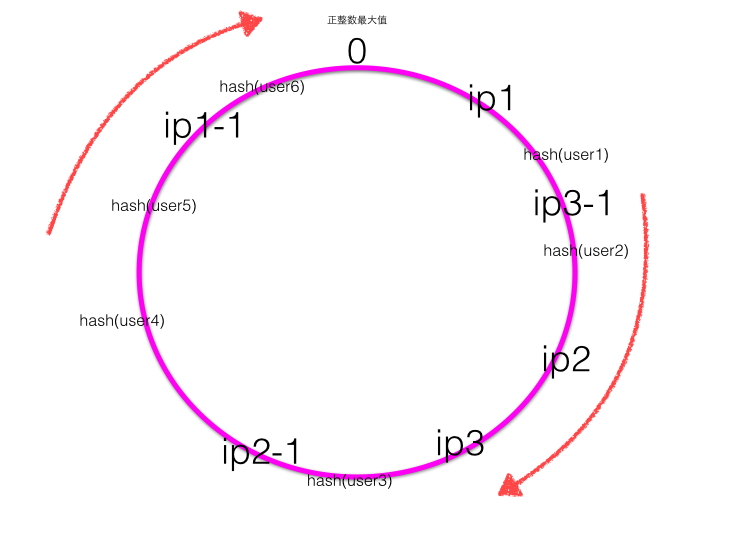
转载https://www.cnblogs.com/xhj123/p/9087532.html
Dubbo的集群容错与负载均衡策略的更多相关文章
- Dubbo学习笔记7:Dubbo的集群容错与负载均衡策略
Dubbo的集群容错策略 正常情况下,当我们进行系统设计时候,不仅要考虑正常逻辑下代码该如何走,还要考虑异常情况下代码逻辑应该怎么走.当服务消费方调用服务提供方的服务出现错误时候,Dubbo提供了多种 ...
- Dubbo的集群容错与负载均衡策略及自定义(一致性哈希路由的缺点及自定义)
Dubbo的集群容错策略 正常情况下,当我们进行系统设计时候,不仅要考虑正常逻辑下代码该如何走,还要考虑异常情况下代码逻辑应该怎么走.当服务消费方调用服务提供方的服务出现错误时候,Dubbo提供了多种 ...
- Dubbo工作原理,集群容错,负载均衡
Remoting:网络通信框架,实现了sync-over-async和request-response消息机制. RPC:一个远程过程调用的抽象,支持负载均衡.容灾和集群功能. Registry:服务 ...
- Dubbo之旅--集群容错和负载均衡
当我们的系统中用到Dubbo的集群环境,由于各种原因在集群调用失败时,Dubbo提供了多种容错方案,缺省为failover重试. Dubbo的集群容错在这里想说说他是由于我们实际的项目中出现了此类的问 ...
- 4.Dubbo2.5.3集群容错和负载均衡
转载请出自出处:http://www.cnblogs.com/hd3013779515/ 1.集群容错和负载均衡原理 各节点关系: 这里的Invoker是Provider的一个可调用Service的抽 ...
- Dubbo学习(二) Dubbo 集群容错模式-负载均衡模式
Dubbo是Alibaba开源的分布式服务框架,我们可以非常容易地通过Dubbo来构建分布式服务,并根据自己实际业务应用场景来选择合适的集群容错模式,这个对于很多应用都是迫切希望的,只需要通过简单的配 ...
- Dubbo中集群Cluster,负载均衡,容错,路由解析
Dubbo中的Cluster可以将多个服务提供方伪装成一个提供方,具体也就是将Directory中的多个Invoker伪装成一个Invoker,在伪装的过程中包含了容错的处理,负载均衡的处理和路由的处 ...
- Dubbo服务集群容错
Dubbo是Alibaba开源的分布式服务框架,我们可以非常容易地通过Dubbo来构建分布式服务,并根据自己实际业务应用场景来选择合适的集群容错模式,这个对于很多应用都是迫切希望的,只需要通过简单的配 ...
- Openfire 集群部署和负载均衡方案
Openfire 集群部署和负载均衡方案 一. 概述 Openfire是在即时通讯中广泛使用的XMPP协议通讯服务器,本方案采用Openfire的Hazelcast插件进行集群部署,采用Hapro ...
随机推荐
- delphi控制word 标题 字符和位置
unit Unit1; interface uses Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms ...
- c语言中指针和多维数组的理解
1.复习指针和数组之间的特殊关系:不带方括号的数组名是一个指针,指向该数组的第一个元素. 2.多维数组: ][];//声明一个二维数组作为举例 a.理解方式1:可以将数组看成行和列构成,即理解成2行4 ...
- Java中String常用方法总结
package cn.zhang.Array; /** * String类的一些常用方法 * @author 张涛 * */ public class TestString { public stat ...
- Java 实现 栈
package Test; import java.util.*; public class Stack_test { public static void main(String[] args) { ...
- 利用FastJson,拼接复杂嵌套json数据&&直接从json字符串中(不依赖实体类)解析出键值对
1.拼接复杂嵌套json FastJson工具包中有两主要的类: JSONObject和JSONArray ,前者表示json对象,后者表示json数组.他们两者都能添加Object类型的对象,但是J ...
- node 第三方库总结
app.post("/todo/add", (request, response) => { request.body //如何拿到前端ajax传来的JSON数据 }) 需要 ...
- springboot学习笔记:8. springboot+druid+mysql+mybatis+通用mapper+pagehelper+mybatis-generator+freemarker+layui
前言: 开发环境:IDEA+jdk1.8+windows10 目标:使用springboot整合druid数据源+mysql+mybatis+通用mapper插件+pagehelper插件+mybat ...
- BBS登录功能
BBS登录功能 一.后端实现 1.实现验证码 from PIL import Image, ImageDraw, ImageFont import random from io import Byte ...
- macbook 一些php相关操作
开启php: https://jingyan.baidu.com/article/67508eb434539f9cca1ce4da.html 配置多虚拟主机: https://jingyan.bai ...
- Android音视频处理之基于MediaCodec合并音视频
Android提供了一个MediaExtractor类,可以用来分离容器中的视频track和音频track,下面的例子展示了使用MediaExtractor和MediaMuxer来实现视频的换音: p ...